







 调整运行时maxmemory时同时调整配置文件maxmemory保持一致--。将配置文件maxmemory设置为0--表示不限制内存使用。正是因为对redis的认识和经验不足,没有想过到运行时配置与静态配置不一致可能导致的问题,这次不可避免的踩坑了。但是,作为一个本职RD,半路接手基本靠自学的兼职运维,要考虑到maxmemory的运行配置与静态配置一致性问题好像也确实不是那么的理所当然🤔。
调整运行时maxmemory时同时调整配置文件maxmemory保持一致--。将配置文件maxmemory设置为0--表示不限制内存使用。正是因为对redis的认识和经验不足,没有想过到运行时配置与静态配置不一致可能导致的问题,这次不可避免的踩坑了。但是,作为一个本职RD,半路接手基本靠自学的兼职运维,要考虑到maxmemory的运行配置与静态配置一致性问题好像也确实不是那么的理所当然🤔。
背景
最近一组业务redis数据不断增长需要扩容内存,而扩容内存则需要重启云主机,在按计划扩容升级执行主从切换时意外发生了数据丢失与master进入只读状态的故障,这里记录分享一下。
业务redis高可用架构
该组业务redis使用的是一主一从,通过sentinel集群实现故障时的自动主从切换,这套架构已经平稳运行数年,经历住了多次实战的考验。
高可用架构大体如下图所示:
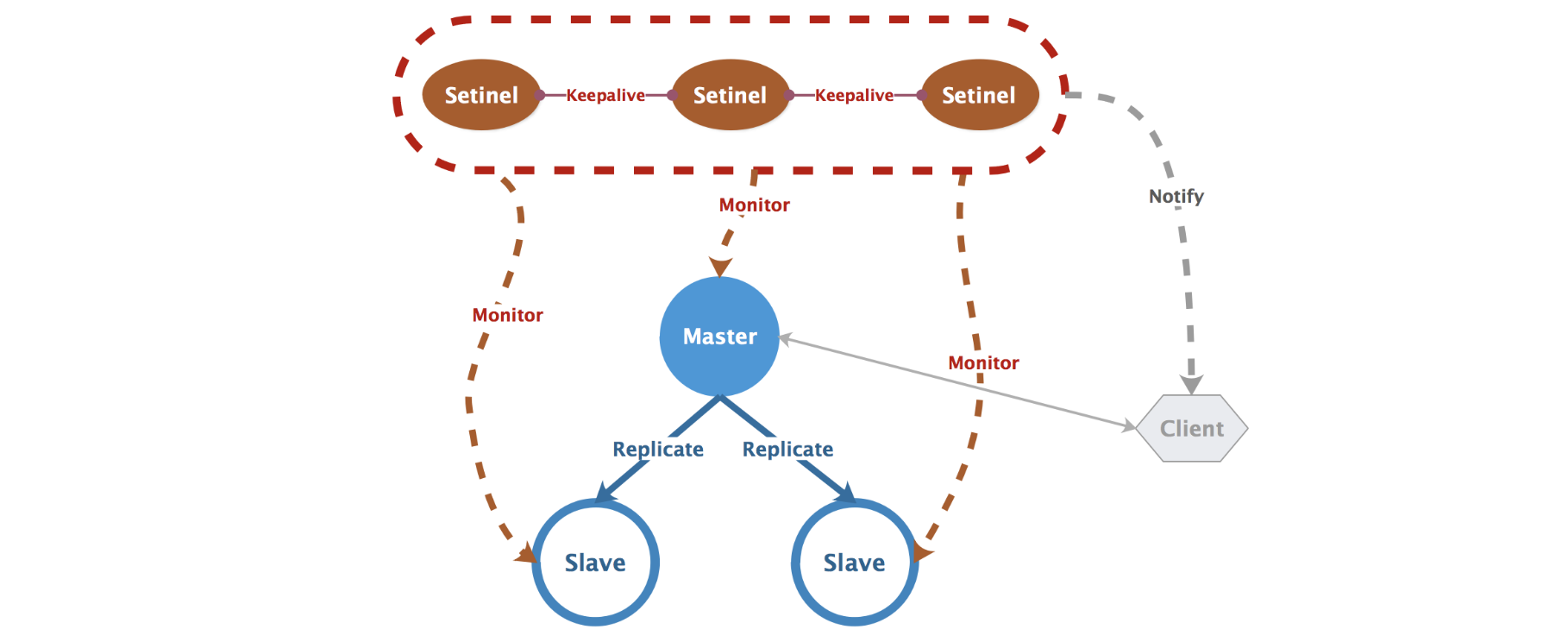
简单说一下sentinel实现高可用的原理:
集群的多个(2n+1,N>1)哨兵会定期轮询redis的所有master/slave节点,如果sentinel集群中超过一半的哨兵判定redis某个节点已经主观下线,就会将其判定为客观下线进行相应处理:
- 如果下线节点是master,选定一个正常work的slave将其选定为新的master节点。
- 如果下线节点是slave,将其从slave节点中移除。
如果已经被客观下线的节点恢复了正常,sentinel中超过一半哨兵确认后则将其加回可用的slave节点。
所有需要读写redis的server并不需要直接写死redis 主从配置,而是通过访问sentinel获取当前redis的主从可用状态,具体实现方式可以定时查询sentinel询问更新,也可以通过订阅机制让sentinel在主从变动时主动通知订阅方更新。
sentinel实现高可用的详细原理这里不做过多赘述,有兴趣的小伙伴可以移步参考文献中的相关资料。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 426
426











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









