







目录
一、课题任务与目的
甲骨文是中国迄今为止现存已知的最古老的成熟文字体系[1],通常在龟甲和兽骨上刻写以记录国家大事、气候、收成等。因此,作为中国最早的书写系统,甲骨文提供了关于古代中国政治、经济、文化和社会生活的直接资料,承载着深厚的历史文化价值。解读甲骨文的卜辞是研究中国古代历史的重要渠道,对考古学研究和语言学研究也具有重要意义。在数字化时代,将其高效准确识别转化为数字资源,精准识别甲骨文对文化传承意义深远。尽管近年来对甲骨文的识别研究备受关注,此类研究取得了较大进展,但其性能仍需进行改进以满足实际应用的要求,存在许多挑战性问题尚未解决。
由于甲骨文字符缺乏标准化规范,导致书写差异显著,如图1,具有相同含义的字符在不同地区和时期往往被写成不同的形式,故一个字符类别存在产生多个变体,类内差异大,传统识别算法力不从心。不同于现代汉字,甲骨文字符样本稀少,数据源稀缺,又因长期埋藏受岁月侵蚀及不适当的挖掘,甲骨文图像质量低,存在模糊、字形残缺、噪声严重等诸多问题,进一步加剧了数据源的稀缺,尽管专家可通过手工复制甲骨文字来获得高质量的图像,但此过程极其耗时且成本高昂。

图 1 类内变异(一个占卜字符对应多个字形)
同时,甲骨文识别还面临长尾分布困境。即少数头部类样本丰富、多数尾部类匮乏,致模型严重偏向头部类,过度拟合头部类特征,而对尾部类的表征学习严重不足,整体性能受限。这种数据不平衡致使模型训练严重失衡,偏向头部类,严重削弱对尾部类的识别效能,对尾部类甲骨文的识别准确率极低,整体识别性能难以提升。如图2所示,在OBC306[2]中,最大的类别有超过25,000个实例,而多数类实例仅一两个。不幸的是,甲骨文的字符识别中的所有数据集都存在这种类不平衡的长尾分布。如何攻克长尾难题、提升模型在不均衡数据下的泛化与识别能力,是推动甲骨文识别技术进阶的关键。
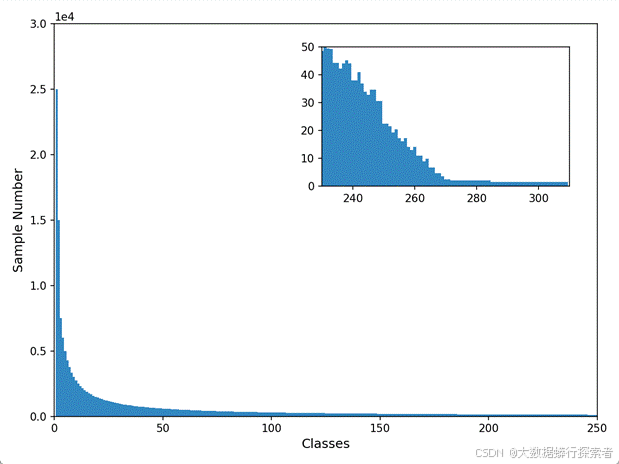
图 2 数据集OBC306的各类别样本数
早期的甲骨文字符识别主要依赖传统的模式识别技术,如基于手工设计特征(如边缘特征、纹理特征、结构特征等)的模板匹配[3]、统计分析[4]方法。此类方法在处理甲骨文复杂多样的字形变化、图像噪声干扰以及极不均衡的长尾数据分布时,由于特征提取过程中的主观性和局限性,加上泛化能力的不足,难以达到高精度的识别效果。
随着深度学习技术在视觉 识别领域的兴起,卷积神经网络(Convolutional Neural Networks, CNN)、循环神经网络(Recurrent Neural Networks, RNN)及其融合架构都被运用于甲骨文识别研究。尽管这些方法在一定程度上提升了甲骨文识别性能,却并未从根本上解决长尾分布的难题。常用的深度学习策略在处理甲骨文长尾数据时仍存有缺陷,例如,基于大规模数据预训练的模型在进行甲骨文数据集调整时,因尾部类样本匮乏而无法有效调整模型参数以使其适应尾部类特征学习;传统的数据增强技术难以生成既符合甲骨文语义也符合字形逻辑的有效样本,且易存在噪声干扰问题;现有的长尾分布处理方法也存在诸多问题,如重采样技术易产生头部类样本过拟合或尾部类样本噪声引入问题,重加权方法在面对复杂多变的甲骨文样本特征空间分布时无法精准衡量各类别难度从而导致类别学习失衡,基于生成对抗网络(Generative adversarial networks,GAN)[5]的数据增强方法在甲骨文识别场景下具有训练不稳定、生成样本质量差及难以保证语义合理性等问题。综上所述,现有的技术手段在解决甲骨文识别中极度不均衡的长尾分布问题时捉襟见肘,迫切需要研发针对性强、创新性高的识别算法架构,以满足考古研究与文化传承对甲骨文高精度识别的迫切诉求,开启甲骨文数字化识别与文化历史传承的新篇章。
综上,开展面向长尾分布的甲骨文识别算法设计与实现研究,极具理论价值与现实紧迫性。
主要任务如下:
- 数据集处理与分析:采用OBC306甲骨文数据集开展实验,对数据集噪声去除、增强优化预处理工作,提升样本图像质量和数据一致性,为后续实验中的模型训练奠基。
- 调研搜集长尾分布现有解决办法策略,为设计更为精准、高效且稳健的面向长尾分布下的甲骨文识别算法提供坚实理论支撑与实践指导,在此基础上完成神经网络架构的设计创新。
- 设计一套全新的算法框架。对比整体准确率及稳定性进行评估及相应模型的参数调整,确定最佳训练策略组合与超参数配置,提升模型的泛化能力和识别可靠性,使其能在保持高效的同时提高对少见字符(即尾部类别)的识别精度,实现长尾分布下精准高效的甲骨文识别目标。
二、调研资料情况
2.1 甲骨文识别
甲骨文字符识别侧重于从甲骨文中自动地识别出古汉字,这是考古学和文献研究的一项关键任务,然而其发展受到了数据集有限和图像质量退化等阻碍。目前的研究如Wang等[6]提出了一种新颖的甲骨文字符识别无监督域适应方法,引入了无监督的领域自适应技术,利用已标注的手写字符来有效弥补铭文注释不足地困境,提升识别准确率;毛亚菲等[7]采用创新的改进 ResNeSt 网络模型,以有效区分字符的结构与纹理特征,并结合注意力机制使模型能聚焦关键特征区域,来提升模型的鲁棒性和识别结果的可解释性。这些研究成果显著提高了对甲骨文字符识别的准确性,有利推动了对规模宏大且极具历史价值的文本语料库进行自动化分析地进程。
从手抄或扫描获取的甲骨文图像中精准识别字符长期以来一直被视为一项极具挑战性的难题,吸引了广泛关注并在不懈探索中取得了巨大进展[2,4,8]。在早期的研究阶段,研究者们大多会依赖传统的模式识别技术来完成对甲骨文字符的识别任务。例如,栗青生等[8]将甲骨文转化为无向标号图,并利用图同构算法来进行甲骨文字符匹配和识别,这种方法能捕捉字符内部结构的相似性,从而提高识别的准确性;Guo等[9]提出一种多特征融合的层次化表征方式,该方式结合了基于Gabor滤波器[10]的低级特征提取和基于稀疏自编码器[11]的中级特征表达,增强了模型对复杂模式的理解能力。
近年来,深度神经网络(Deep Neural Networks,DNN)方法逐渐在甲骨文字符识别领域得到应用。在初期的研究阶段,研究人员尝试将卷积神经网络架构模型与传统图像处理中的特征表示方法相结合以提升识别性能[5]。由于深度神经网络模型的有效训练通常依赖于大规模且已标注的带有标签的数据集样本,因此研究人员必须投入大量资源和精力来收集甲骨文数据样本。
2.1.1基于机器学习的甲骨文识别
由于机器学习算法在计算机视觉领域取得了显著成功,除了传统的图论方法中依赖人工编码进行匹配之外,部分甲骨文字形识别的研究也逐渐引入了先进的机器学习算法[12]。支持向量机(Support Vector Machine,SVM)[13]作为机器学习领域的一种重要工具,泛化能力强,能够有效处理高维空间的数据,尤其适用于小样本数据的分类处理任务,因而被广泛应用于图像分类、手写字符识别等多个领域,对于数据源稀缺且标注困难的甲骨文识别任务来说,SVM展现出了极大优势。研究学者们运用语料库技术构建了一个简单的甲骨文数据库,并在此基础上展开数据挖掘工作,采用支持向量机模型进行从字形结构角度出发的数据分析,实现了基于部首的分类操作,从而达到促进知识共享的目的,并为甲骨文学者的考证和研究工作提供有利辅助。刘永革等[14]通过块状直方图提取图像特征,并输入至SVM模型中进行甲骨文识别的训练与测试,最终使得识别精度达到了88%,展示了SVM在处理有限数据集时的强大性能,进一步证明了SVM在甲骨文识别中的有效性。
2.1.2基于深度学习的甲骨文识别
基于深度学习的甲骨文识别技术整合了传统方法中的特征提取与多种处理步骤,依赖大量的甲骨文字形数据和强大的计算性能自动从图像中提取复杂的拓扑特征,无需人为定义具体的特征,交由计算机独立识别图像,并基于给定的数据图像进行自我迭代训练,从而显著提升了甲骨文识别的准确性和效率,在甲骨文识别领域中发挥着日益重要的作用[12]。张恒等[15]通过使用对比损失及三元组损失并采样难样本(Hard Examples)来强化学习过程以更好学习少数类特征,提升模型的鲁棒性和泛化能力;张颐康等[16]提出了一种基于跨模态深度度量学习的甲骨文字识别方法,这种方法通过将拓片甲骨文字与临摹甲骨文字映射到相同维度的特征空间,并利用对抗学习算法使相同类别的拓片甲骨文字和临摹甲骨文字具有相似的特征分布,从而提高了对已知类别的识别性能并实现了对新类别的增量识别,将识别精确度从66.6%提升至88.4%;刘芳等[17]采用Mask R-CNN模型进行甲骨文拓片识别,成功将识别准确率提升至95%;闫升等[18]在此基础上进一步优化了Mask R-CNN算法,引入了类别屏蔽(category masking)与自动识别校正相结合的方法,实现了甲骨文拓片图像中字符检测与识别的一体化流程,首次解决了拓片图像中字符间的复杂关系问题;林小渝等[19][20]在深度学习模型的基础上提出了一种零样本学习策略,创新型的从甲骨文单个偏旁的角度出发,通过使用不同的现代汉字书写风格来提高模型对结构的理解,这一策略有助于解决多对一训练方法导致的结构变形问题,使得模型能够更好地捕捉字符演化中的细微差别;白翔等[21]提出一种扩散模型OBSD,该模型利用甲骨文图像作为条件输入生成对应现代汉字图像,通过局部分析采样技术增强模型对字符复杂模式进行区分和解释的能力,并引入局部结构采样(LSS)以增强模型在甲骨文和现代汉字之间的连接能力。为了克服甲骨文样本数据源稀缺的问题,研究人员还探索了各种数据增强方法,如通过生成对抗网络(GAN)或其他图像生成模型来创建额外的训练样本。
2.2 长尾分布识别——长尾学习
在当今世界的真实数据集中,长尾分布(Long-tailed Distribution)现象普遍存在, 即少数头部类占据数据集的大部分数据样本量, 而大量尾部类数据样本量极低。在模型训练的过程中,头部类别由于样本数量庞大,在参数优化过程中占据了主导地位,导致模型对这些常见类别表现出过度偏好。与此同时,尾部类别因为样本稀少,使得模型对其学习不足,难以捕捉到充分且有效的特征表示。
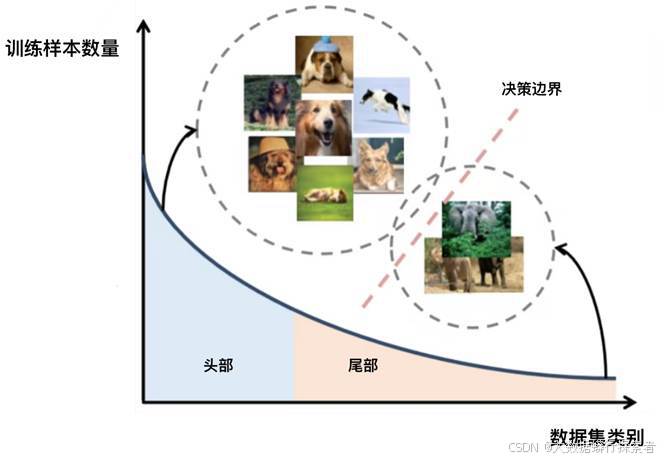
图 3 长尾数据集的标签分布(例如 iNaturalist 物种数据集)[22]
长尾学习作为机器学习的一个研究领域,目标便是处理数据分布不均衡问题。被广泛应用于长尾分布识别任务中,有效提升模型在长尾分布下对所有类别的识别性能,能在保持头部类别识别精度的同时显著改善尾部类别的识别效果。传统长尾学习算法通常假设训练集服从长尾分布, 并假设测试集服从类平衡分布, 这种分布上的差异也是造成长尾学习模型泛化能力与鲁棒性下降的原因之一。
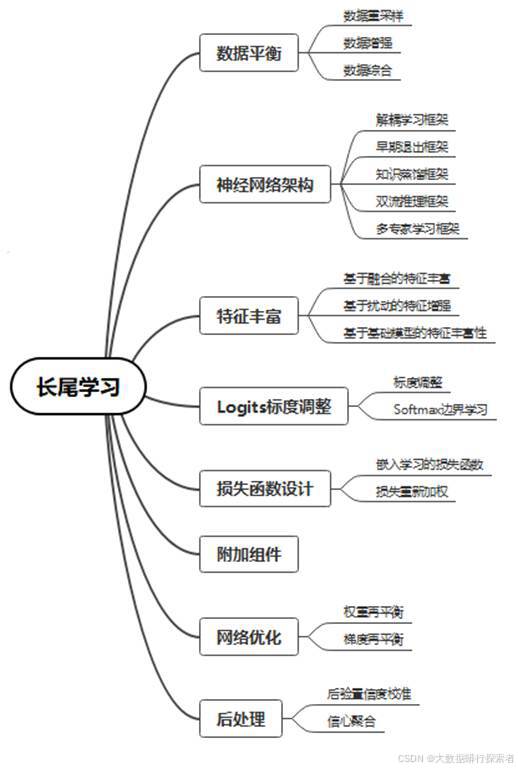
图 4 长尾学习
现有的长尾学习技术可以分为八类:(1)数据平衡;(2)神经网络架构;(3)特征丰富;(4)logits标度调整;(5)损失函数设计;(6)附加组件;(7)网络优化;以及(8)后处理[22]。数据平衡方法通过数据重采样、数据增强或合成技术调整训练集的类别分布来进行神经网络模型训练,确保神经网络模型在训练过程中能够接触到更均衡的数据。神经架构方法设计特定的网络结构,旨在提高模型对尾部类别的敏感性和识别能力,从而改善LTL性能。特征丰富方法利用记忆库、扰动策略或其他技术来扩充尾部样本的特征表示,或者从预训练的基础模型中提取附加特征或多模态特征,以此增强尾部类别的表征学习。Logits标度调整方法通过调整logit值或扩大不同类别之间的分类边界以使模型对尾部类别的更敏感,继而提升其识别准确性。损失函数设计方法则通过修改损失函数以加重尾部类别样本或困难样本的权重,或引入综合损失函数作为优化目标以促进更有效的嵌入和表示学习。附加组件包含一系列用于网络训练和性能提升的技术细节以及各种辅助模块的设计。网络优化专注于内部网络优化的权重和梯度更新技术,确保模型训练稳定高效。最后,后处理方法则是在模型预测阶段进行校准,调整输出概率分布,使长尾模型的信心分数更符合实际场景的需求。
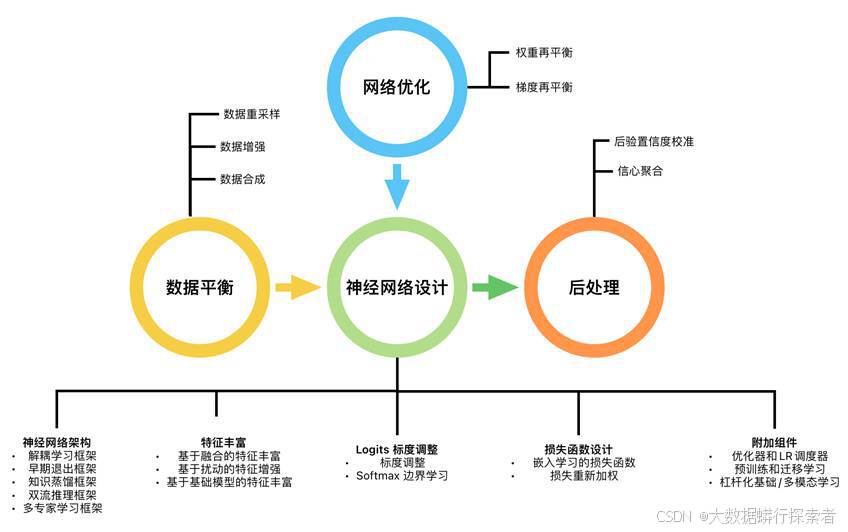
图 5 长尾学习分类及各类别典型代表方法[23]
2.2.1数据平衡
数据平衡旨在通过增加少数类(即尾部类别)的训练样本的数量和多样性,以使训练样本在各类别间均衡分布,从而模型得以在所有类别上的表现更加均衡。基于这一目的,主要有三种典型的子方法来达到数据平衡(见表1):1)数据重采样,它通过调整训练集中不同类别的样本数量来解决类别不平衡的问题;2)数据扩充,通过对现有数据采用进行一系列变换操作来拓展训练数据集的规模;3)数据合成,通过更为复杂的技术生成合成样本,以扩充少数类别的样本数量。如基于生成对抗网络(GAN)、分布估计/转移方法、以及基础模型(例如GPT-4V、DALL-E等),来生成合成样本。
| 数据平衡 子方法 | 代表性方法 | 再平衡策略 | 共同特点 |
| 数据重采样 | 类平衡重采样 | 按类别抽样或按实例抽样 | 在模型训练中人工平衡数据:
|
| 五元组重采样 | |||
| 数据增强 | RandAugment |
|
|
| Mixup | |||
| CutMix | |||
| CUDA | |||
| 数据合成 | GAN |
| 估计特征空间中不同类别数据的方差/协方差或数据分布的几何形状,则: 1) 强制尾部类的方差/协方差与头类的平均方差/协方差。 2) 将头部类的几何图形转移到尾部类或使用基础模型进行图像生成。 |
表1 长尾学习数据平衡方法概述
1.数据重采样
在机器学习中,处理类别不平衡问题的两种主要策略是对少数类进行过采样(也称为上采样)和对多数类进行下采样(也称为欠采样),这两种方法旨在通过调整训练集中的样本分布来改善模型性能。在深度学习框架内,按类别抽样与按实例抽样的方法被用来平衡迷你批次中的每个类别的训练样本数量。过采样/上采样方法通常通过复制现有样本或生成合成样本实现少数类样本的数量的增加。下采样/欠采样方法常见的做法是从多数类中随机选择一部分样本从而减少多数类样本的数量,以使其与少数类样本数量相匹配。按类别重采样方法旨在确保每个小批量(mini-batch)中各类别样本数量的比例相对均衡,可能包括对少数类的过度采样以及对多数类的下采样。侍蒋鑫等[24]通过研究表明,在训练样本与目标标签高度语义相关的情况下,类平衡重采样有助于模型学习有区分性的特征表示;而在其他情况下,均匀采样甚至可能优于类平衡重采样。按实例重采样方法则是基于实例的重要性或难度来进行采样,而不仅仅是基于其类别标签。例如,Li等[25]提出了一种五元组采样方案,首先对每个类进行聚类,然后选择那些能够强制执行簇间和类间间隔的样本,以此缓解随机下采样带来的信息损失。这种策略可以更好地保持数据的多样性,并且更有效地利用有限的数据资源。
2.数据增强
数据增强是一项在深度学习领域广泛应用的技术,旨在通过对现有训练数据实施一系列变换来人工扩充数据集,以此提升模型的泛化能力和准确性,并有效减少过拟合现象的发生。该技术不仅涵盖基础的图像处理操作如裁剪、颜色调整等,还包括更为复杂的图像混合方法。
RandAugment[26]及其变体是近年来在数据增强领域中取得显著进展的方法之一。RandAugment的核心在于它采用了一种更为直接的方式来选择数据增强操作。它定义了一个包含多种图像变换的操作集合(如旋转、缩放、颜色调整等),并通过两个主要参数N和M来控制增强的程度:N表示每次应用多少个随机选择的操作;M则是所有操作共享的一个幅度参数,决定了每个操作的应用强度。这种方法不仅极大地简化了超参数调优的过程,而且使得RandAugment能够在不同的任务和数据集上达到最先进的性能水平。
Mixup[27]是一种创新的数据增强技术,它通过在线性插值输入空间和标签空间之间创建合成图像,从而生成带有软标签的新样本。这种方式不同于传统的基于几何或颜色变换的数据增强手段,因为Mixup同时改变了输入和输出(标签)的空间。具体来说,给定两个训练样本及其对应的标签,Mixup会按照一定的比例将这两个样本及其标签混合在一起,形成一个新的训练实例。Manifold Mixup[28]是Mixup的一种扩展形式,它不是在输入层面上执行插值,而是在神经网络的中间层(潜在特征空间)中进行。这样做可以让模型学习到更加抽象且通用的特征表示。Remix[29]是专门为处理长尾分布的数据集设计,Remix通过给予少数类更高的标签混合系数,确保它们得到足够的关注。这有助于改善模型对稀有类别的预测性能。UniMix[30]则进一步推进了Mixup的思想,通过引入尾部偏好的Mixup因子以及逆采样策略,鼓励更多地生成头-尾类别的组合。这种方法特别适用于解决类别不平衡的问题。Perrett,Toby[31]等提出了Long-Tail Mixed Reconstruction(LMR)算法,专门用来针对长尾分布数据集,其通过对批次中的头部类别样本进行加权组合,重建少量样本视频,从而减轻对少数类别的过拟合现象。
3.数据合成
数据增强技术通常指通过应用各种图像变换来生成合成图像,以扩充训练集并提高模型的泛化能力。而数据合成方法则涉及更为复杂的图像生成技术,例如生成对抗网络(GAN)、分布估计或转移学习、以及预训练的视觉或视觉-语言模型等。
基于生成对抗网络(GAN)的数据生成技术在处理长尾分布数据集时展现出了独特优势。Jiang等[32]通过研究表明,低分辨率的信息通常与类别无关,因此可以在所有类别间共享,而特定于类别的特征则往往在高分辨率图像中显现出来。基于这一发现,研究者建议采用一种分层次的方法来进行长尾数据下的基于GAN的图像合成:首先计算低分辨率图像的无条件(即类无关)目标,然后将有条件的(即类相关)信息注入到高分辨率图像中。此方法不仅提高了生成效率,还确保了生成图像的质量和类别特性的一致性。
研究者们还开发了基于分布的数据合成方法来应对长尾分布数据集中的稀有类别样本不足问题。Wang等[33]提出了稀有类样本生成器(RSG)数据合成方案,旨在使尾部类别的内部变化信息与头部类别相匹配。RSG通过从频繁出现的类别中减去最接近聚类中心的特征向量来获取特征偏移值,以此去除类别相关信息并获得差异值,随后将这些差异值被直接添加到每个稀有类样本的特征向量以创造出新的合成少数样本。Liu等[34]提出LEAP,首先使用特征向量与对应类中心之间的余弦相似度角度为每个类别建模一个高斯分布,其次强制尾部类别的高斯分布方差等于头部类别的平均方差,最后随机选择新分布中的特征向量。此方法扩大了尾部类别的特征分布,使其与其他类别更为分离有效地扩大了尾部类别的特征分布方差,从而使它们与其他类别更加分离。
随着大型预训练模型(如CLIP、GPT-4V 和 DALL-E)的兴起,研究者们开始尝试利用这些基础模型来生成合成数据,旨在解决长尾分布问题。张帆等[35]提出了一种生成式微调框架LTGC,采用文本到图像(Text-to-Image, T2I[36])模型来为稀有类别创建多样化的图像样本,通过计算由CLIP提取的文本特征与生成图像之间的余弦相似度来进行筛选和优化以确保生成图像的质量和相关性。这种方法不仅增加了尾部类别的数据量,还保证了新生成的数据点在语义上的一致性和准确性,从而有助于提升视觉大模型在处理长尾数数据下识别任务的识别率和泛化性。
2.2.2神经网络架构
神经网络架构设计与损失函数的选择是提升模型性能的两大关键因素。神经网络架构设计是指为特定任务设计有效的神经网络结构或模型,损失函数设计则涉及定义一个能够指导模型学习过程的目标函数。通过涉及这两部分,可以显著提高神经网络的整体表现。其相关的方法可分为解耦学习框架、早期退出框架、知识蒸馏框架、双流推理框架和多专家学习框架等子类别。
1.解耦学习框架
解耦学习框架逐渐成为处理长尾识别问题的一个重要方向。康兵义等[37]提出的将表示学习和分类解耦的方法是一次开创性工作,即将模型的学习过程拆分为表示学习和分类两个独立的部分分开进行(即解耦),从而得以更有效地应对数据分布不平衡带来的挑战。
2.早期退出框架
Duggal, Rahul等[38]研究指出,在处理长尾识别问题时,现有的方法往往只依赖于类别大小来进行样本权重调整,但这却可能导致少数类里的简单样本被不当加重以及多数类里复杂样本被误减权的问题。为了解决这一问题,他们提出采用ELF(Early Exiting Framework)框架来改进模型的学习机制,通过在网络浅层添加辅助分类器分支的方式,允许简单样本在早期就提前退出,从而使得模型能够更好地关注那些真正困难的样本。
3.知识蒸馏框架
知识蒸馏框架旨在通过从教师模型到学生模型的知识迁移,来克服数据分布不平衡带来的挑战。这些框架通常利用软标签、自监督学习以及特定的训练策略,以确保学生模型能够更好地泛化到尾部类别。Tang等[39]提出了名为Knowledge Rectification Distillation (KRDistill)的新框架,该框架解决了传统知识蒸馏方法在数据不平衡情况下对尾部类别性能严重下降的问题。通过引入平衡的类别先验和纠正教师网络对尾部类别的偏见,使教师网络能够提供平衡准确的知识来训练可靠的学生网络,这种方法不仅提高了尾部类别的识别精度,还保证了整体模型的轻量化和高效性。Pradipto Mondal等[40]探索了如何将ViT (Vision Transformer) 应用于长尾视觉识别任务,提出DeiT-LT,通过知识蒸馏将CNN教师模型中的知识转移到 ViT 学生模型中以增强其对尾部类别的泛化能力,并使用非分布图像生成及重新加权策略优化蒸馏损失使其更加强调尾部类别,为了提高 ViT 对长尾分布数据的适应性,DeiT-LT 还采用了重新加权策略,使得尾部类别的贡献在整个训练过程中得以保持。
4.双流推理框架
双流推理框架是一种旨在通过设计特定的架构来改善模型对少数类别(即尾部类别)泛化能力的方法。这类框架通常会采用两个并行或互补的工作流,以分别处理不同类型的样本或特征,从而更有效地应对数据集内类别不平衡的问题。
5.多专家学习框架
多专家框架(Multi-Expert Framework)是一种旨在通过集成多个模型来提升对稀有类别(即尾部类别)识别能力的方法。通常结合了多个不同的专家模型,每个专家可能专注于特定子集的数据或特征,集成学习方法可做出更准确的预预测,从而能够在不牺牲头部类别性能的情况下显著改善尾部类别的识别效果。代表性的LTL集成学习方法包括RIDE[41]、LFME[42]和TLC等,每种方法都有其独特之处,如RIDE专注于减少方差和偏差,LFME强调自适应知识转移,而TLC则关注于可信度估计。
2.2.3特征丰富
特征丰富是指通过一系列方法和技术来增强或改进模型对尾部类别样本的表征能力,以克服由于数据不平衡导致的识别困难。这一过程不仅涉及如何更好地捕捉尾部类别的特征信息,还包括探索新的方式来增加这些特征的信息量,从而提高模型的整体性能。
1.基于融合的特征丰富
基于融合的特征丰富旨在通过结合不同来源或类型的特征来增强模型对尾部类别样本的学习能力。这种方法不仅有助于改善尾部类别的表示,还能促进模型整体性能的提升。
2.基于扰动的特征增强
基于扰动的特征增强是一种在长尾分布学习中用于改善模型对尾部类别样本表示的有效技术。这种方法通过引入轻微的变化或噪声到原始特征空间,从而生成新的、多样化的样本,帮助模型更好地理解和泛化尾部类别的特性。
3.基于基础模型的特征丰富性
基于基础模型的特征丰富性是指利用预训练的基础模型来增强对尾部类别样本的学习能力。这种方法通常涉及迁移学习、知识蒸馏以及多模态信息融合等策略,旨在通过引入额外的知识或信息来源,帮助模型更好地捕捉尾部类别的特征表示。
2.2.4标度调整
在神经网络的输出层中,logits代表的是模型对于每个类别的原始预测值。这些未经处理的数值随后作为输入传递给softmax激活函数,后者负责将logit值转换成一个概率分布,使得每个类别对应的概率值都在0到1之间,并且所有类别的概率之和等于1。这种转换不仅让模型的输出更易于解释,还为多分类问题提供了决策的基础。Logits调整方法主要分为两大类:一类是在训练过程中优化从logit值衍生出来的固有过程;另一类则是在后处理阶段对logit值进行校准。前者旨在通过改变模型内部机制来改善分类性能,而后者则是通过对已有的logit输出做额外处理,以达到更好的分类效果,还包括限制logit值的范围,从而影响Softmax分类器使分类边界增加[43]。
1.标度校准
logits校准指在处理类别不平衡问题时,通过对神经网络输出层的logits(即未经过激活函数转换的原始预测值)进行调整,以改善模型对少数类别的识别性能。这类方法旨在通过改变logits来补偿训练数据中类别分布的不均匀性,从而使得模型能够更加公平地对待所有类别,尤其是在那些样本量较少的尾部类别上表现更好。
2.Softmax边界学习
softmax边界学习(或称为分类边界学习)是一个关键概念,指的是通过调整模型输出层的logits来优化分类器的表现,特别是针对那些样本数量较少的尾部类别。这类方法旨在创建更清晰的决策边界,使得即使是少数类也能获得较高的识别精度。以下是几种主要的softmax边界学习策略及其工作机制。Li等[44]提出了一种新颖的边界学习方法Balanced Group Softmax(BAGS)。BAGS模块通过逐组训练来平衡检测框架内的分类器,隐式地调整了头和尾类的训练过程。具体而言,其将训练实例数量相似的目标对象类别放在同一组中,并分别计算分组的softmax交叉熵损失。这不仅减轻了头部类对尾部类的压制,还防止了背景和其他类别的误报。
2.2.5损失函数设计
嵌入空间,亦称潜在空间或潜在特征空间,是指通过学习算法构建的一种新的表示形式。损失函数的设计与神经网络架构的选择是实现高效嵌入学习和优化的核心要素。损失函数对于嵌入学习至关重要,因为它定义了模型预测值与真实标签之间的差异,并指导着模型参数的更新方向以最小化这种差异,不同的任务可能需要不同类型或组合的损失函数来确保模型能够捕捉到数据的本质特征并做出准确预测。同时,神经网络架构则决定了如何对输入数据进行变换以生成有用的嵌入表示。
1.嵌入学习的损失函数
嵌入学习的损失函数设计对于模型的有效性和公平性至关重要。由于数据集中存在类别不平衡的问题,传统的损失函数如标准的交叉熵损失(Cross-Entropy Loss)可能会导致模型偏向于频繁出现的头部类别,而忽视了稀有的尾部类别。
2.损失重新加权
旨在通过调整不同类别样本的损失权重来缓解类别不平衡带来的负面影响。这一策略的核心思想是为尾部类别分配更大的权重,使得模型在训练过程中更加关注这些稀有类别的样本,从而平衡训练过程中各类别之间的影响力,改善其学习效果。例如,尹长青等[45]提出了一种等量化损失(Equalization Loss),通过调整每个类别的logits来缓解长尾效应,确保尾部类别不会被头部类别压制。具体来说,该方法会根据类别频率为每个类别分配一个偏移量,然后将其加到对应的logits上,从而扩大尾部类别与其他类别之间的间隔。
2.2.6附加组件
长尾学习中,附加组件指的是超越神经架构和损失函数的各种技术、训练策略和实践,这些对提升模型性能同样也至关重要。常见的附加组件包括网络训练与优化策略的选择。
2.2.7网络优化
网络优化是指针对类别分布不平衡的数据集,通过一系列技术手段来改进深度神经网络的性能,使得模型不仅能够很好地识别多数类(头部类),还能有效处理少数类(尾部类)。这些优化方法涵盖了从数据预处理、损失函数设计到模型架构调整等多个方面。
1.权重再平衡
权重再平衡侧重于调整损失函数以增加尾部类别的关注度,主要是通过重新定义损失函数中的权重分配,使得模型能够更加关注尾部类别的样本。如Class-Balanced Loss根据每个类别的有效样本数而非简单样本数量来计算损失权重,避免了因样本重复而导致的过拟合问题;Focal Loss引入了一个调节因子,使损失函数能够根据预测准确度自适应地调整样本对总损失的贡献程度,特别适合处理难分类的尾部类别[46]。
2.梯度再平衡
梯度再平衡致力于修正梯度传播过程中的偏差,确保各类别间的梯度信息得以公正传递,直接作用于梯度本身,通过调整权重和梯度来改善模型性能。尹长青等[47]提出了一种新颖的梯度调整机制EQLv2 (Equalization Loss v2),通过动态调整尾部类别的梯度来增强类别的表示能力。
2.2.8后处理
后处理是指在模型训练完成后,在推理阶段对预测结果进行调整或优化的过程。这种策略不同于直接改进特征表示能力或调整决策边界的方法,而是专注于确保模型输出的概率分布更加贴近真实情况,从而提高模型对于不平衡数据集中少数类别的识别精度和可靠性。预期校准误差(ECE) 是一种常用的指标,用来评估模型预测概率与实际发生概率之间的匹配程度。
1.后验置信度校准
后验置信度校准旨在确保模型预测的概率分数能够准确反映真实的事件发生概率。这对于提升模型在类别不平衡数据集上的表现至关重要,尤其是对于那些样本量较少的尾部类别。常用的后验置信度校准方法有温度缩放、直方图二值化和Logit 调整等。张松阳等[48]提出了一种自适应校准函数,用于调整各个数据点的分类概率。这种函数为分类配备了与输入有关的、可学习的幅度和余量,使每个数据点都能依据相关的置信度得分实现灵活的分布对齐。
2.信心聚合
信心聚合是指通过结合多个预测结果或模型输出来提高对尾部类别预测的信心和准确性。这种策略不仅能够增强模型对于少数类别的识别能力,还可以帮助缓解由于数据不平衡导致的预测偏差。
2.3面向长尾分布的甲骨文识别
甲骨文作为中国最早的象形文字,其识别面临着严重的长尾分布问题,即某些类别的样本数量远多于其他类别。这种不平衡性导致了现有模型在处理稀有类别时表现不佳。为了解决这一挑战,研究者们展开了研究。
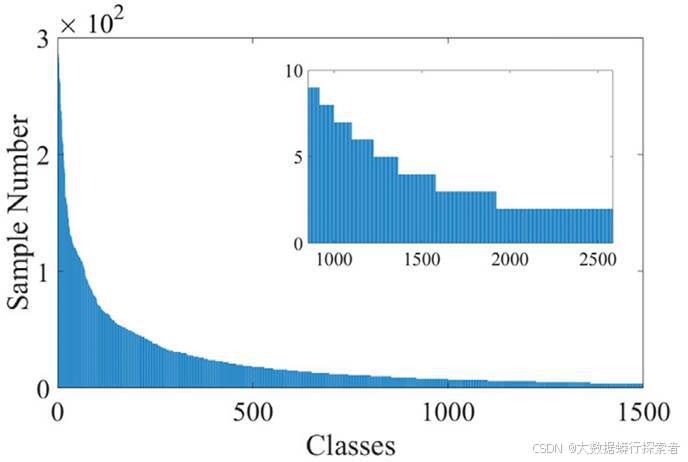
图 6 甲骨文数据集长尾分布(例如Oracle-AYNU[51])
Zhang等[49]提出了一种基于CycleGAN的数据增强方法, 通过学习字形图像数据域和真实样本数据域之间的映射,生成高质量的甲骨文字符图像以增加尾部类别的样本数量来缓解现有数据集中的类别不平衡问题,有效改善甲骨文识别效果。
王秋锋等[50]提出了一种两阶段解耦学习策略,旨在同时提升所有类别(尤其是那些样本稀缺的类别)的识别性能,其核心思想是将特征表示与分类器分离,允许每个部分独立优化,从而确保少数类(尾部类)也能获得更高质量的特征表达。最终,这种新型解耦学习方式不仅提高了整体识别率,而且特别提升了尾部类别的表现。
Li等[51]提出了一种对抗数据增强(Adversarial Data Augmentation, ADA)方法,研究指出,在实际应用中,由于某些类别样本量非常少,传统模型往往难以对这些类别进行有效学习,导致性能不佳。为了解决这个问题,他们引入了ADA技术,利用生成对抗网络中的生成器来增加训练集中小类别的样本数量,又通过引入对抗损失函数来确保新生成的数据点既能够增加目标域内的多样性,又不会偏离原始分布太远。这种方法不仅提高了整体分类精度,而且特别增强了对长尾类别(即样本较少的类别)的识别能力。
上述研究成果利用各种深度学习模型和数据增强的方法及策略使甲骨文字符识别准确率获得了提升,为解决甲骨文字符识别长尾分布问题提供了有效的解决思路方法。CycleGAN方法侧重于通过数据增强来弥补样本量不足;两阶段解耦学习则试图从根本上改变训练方式,以达到更加均衡的数据获取;而ADA方案则是利用对抗性技术和数据增强相结合的方式来增强模型的能力。每种方法都有其独特之处,同时也存在一定的局限性。CycleGAN方法的效果很大程度上依赖于输入数据的质量,如果原始数据集中存在噪音或标注错误,生成的样本也可能继承这些问题,进而影响模型的学习效果,且虽然CDA(CycleGAN-based Data Augmentation)能够在一定程度上保证生成样本的质量,但由于甲骨文字符的独特性和复杂性,生成样本可能会丢失某些细微特征或引入噪声,影响最终模型的表现;两阶段解耦学习侧重于分离头部和尾部类别的特征表示,但这可能导致模型在面对未见过的新字符时,无法很好地泛化其学到的知识,尤其是在新字符属于尾部类别的情况下,泛化能力有限;ADA方案的有效性高度依赖于生成对抗网络(GAN)的质量。如果GAN未能准确捕捉到源域与目标域之间的映射关系,则生成的样本可能不具代表性,甚至会引入误导信息。
三、初步设计方法与实施方案
3.1 数据集预处理
3.1.1 数据集选择及划分
本实验选用OBC306数据集进行甲骨文图像识别,该数据集是首个大型公开的拥有大量拓片单字符的数据集,被广泛使用于甲骨文字符识别研究中,其规模宏大,共包含309,551 个甲骨字符图像样本,覆盖306个不同类的甲骨文字,且每一张图片都被仔细地进行了类别标注,确保了数据集的质量与可靠性。OBC306数据集长尾分布特质显著,是进行长尾分布甲骨文字符识别研究的理想选择,此数据集中少数高频字符(72类,1000多幅图像)占图像总数的83.74%,但仅占类别总数的27.5%,此外,29个类中只有一个图像[7]。在本实验中将删除上述提到的仅有一个样本图像的29个类别,保留了 277 个类,共包含309,522个样本图像。在实验过程中,将把剩余的数据集按3:1的比例随机分为训练和测试集,最终,训练集和测试集的最大类别与最小类别的不平衡比分别为19,424:1 和 6,474:1 。

图 7 OBC306数据集示例
3.1.2数据集预处理
对数据集图片进行预处理,使数据集中的数据质量提高且更适用于训练深度学习模型,从而提高后续模型的训练效果。首先,我们需对数据集原始图像进行图像去噪处理,使用注意力生成对抗网络,构造去噪网络模型对数据集中的甲骨文图片进行噪声去除,然后我们需使用双线性插值法进行图像尺寸标准化处理,由于本实验所选用的OBC306数据集中的图像因分割处理导致分辨率不一致,故需对所有原始图像进行尺寸标准化,使得每一张输入图像都具有相同的尺寸规格,从而使得数据的可靠性增强,同时也使其符合模型输入层的要求。
3.2 模型选择和优化
3.2.1模型选择
本文选用预训练的ResNet-50模型作为基线模型,ResNet(Residual Network,残差神经网络)[52]是由何凯明等人于2015年提出的一种深度卷积神经网络,它通过引入残差学习结构(见图8)的思想解决了深层网络训练过程中容易出现的梯度消失或爆炸问题,这种创新性设计允许构建更深的网络结构,从而显著提升了模型的表达能力和泛化性能。ResNet-50模型已经在ImageNet上取得了良好的泛化能力,可以作为强大的特征提取器。
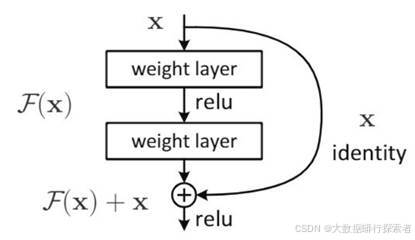
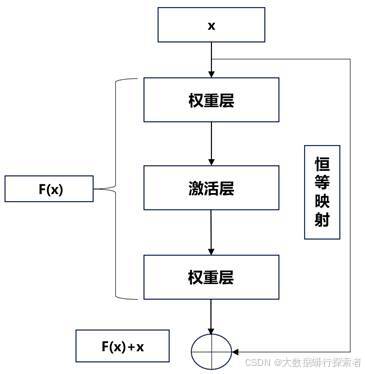
图 8 残差学习
3.2.2 算法引入
在ResNet50 模型的基础上,引入ProCo[53]算法,ProCo 不仅能在小批量训练时保持良好的性能,还能够有效防止模型过拟合,这对于甲骨文这样数据量有限的任务尤为重要。通过对每个类别在特征空间中的样本数据分布进行建模与参数估计,并据此从中采样以构建对比对(contrastive pairs),以确保即使是样本量极少的尾部类别也能得到充分的学习,改善对尾部类别的表征能力从而能够覆盖到所有的类别。具体来说,利用von Mises-Fisher (vMF) 分布来描述特征分布,并推导出期望对比损失函数的解析解。
1.ProCo算法
ProCo(Probabilistic Contrastive Learning for Long-Tailed Visual Recognition)是杜超群等提出的一种新颖的概率对比学习算法,旨在解决长尾分布识别任务中监督对比学习(Supervised Contrastive Learning, SCL)对大批量数据的依赖问题。该算法通过估计每个类别在特征空间中的样本分布,动态生成正负样本对用于对比学习,强化模型对尾部类别的表征能力从而实现对长尾分布数据集中所有类别的有效覆盖,提高了在处理不平衡数据集时模型的表现力并有效防止模型过拟合。
2.特征分布建模及参数估计
对于每个类别,ProCo 采用 von Mises-Fisher (vMF) 分布来建模特征分布。这是因为对比学习中的特征通常分布在单位超球面上,而 vMF 分布是正态分布在超球面上的自然扩展。此vMF分布建模的两个主要参数为均值方向μ和集中度 κ,利用最大似然估计高效地估计分布参数,并计算出期望对比损失的解析解。此外,ProCo 采用在线估计的方法,能够有效地对尾部类别的参数进行估计。
3.无限对比对生成
利用估计得到的vMF分布参数,可以从理论上构造出无限数量的对比对。具体做法是从每个类别的分布中随机抽取正样本,并从其他类别中选取负样本形成一对。当采样数趋于无穷大时,ProCo 可以严格推导出预期损失的封闭形式,从而避免显式地从大量对比对中进行低效采样。这不仅减少了计算资源的需求,还确保了模型可以充分学习到尾部类别的信息。
4.vMF分布建模
将提取到的特征映射到单位超球面上。接着,假设这些特征服从的分布为 von Mises-Fisher (vMF) 分布,其概率密度函数表示见公式3-1:
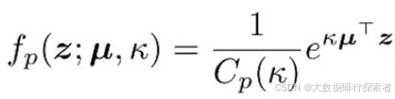
公式 3-1 vMF概率密度函数[53]
其中, z 是 p 维特征的单位向量,Cp (κ) 是归一化常数(见公式3-2),μ是分布的均值方向,κ 是集中参数,控制分布的集中程度,当 κ 越大时,样本聚集在均值附近的程度越高;当 κ =0 时,vMF 分布退化为球面上的均匀分布
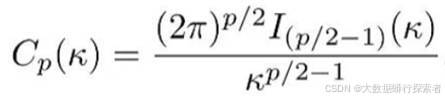
公式 3-2 归一化常数[53]
其中,I (p−1)/2 (κ) (见公式3-3)是第一类修正贝塞尔函数,用于保证整个分布的积分等于1。
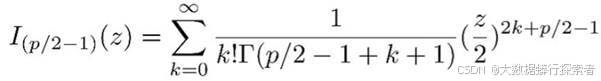
公式 3-3 第一类修正贝塞尔函数[53]
1.参数估计
数据特征的总体分布为混合 vMF 分布,其中每个类别对应一个 vMF 分布。其每个类别y对应的特征向量z遵循的vMF分布表示见公式3-4:
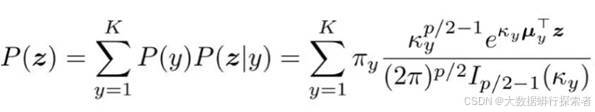 (公式3-4)
(公式3-4)
公式 3-4 每个类别对应的vMF分布[53]
其中,参数Πy表示每个类别的先验概率,对应于训练集中类别 y 的频率;特征分布的均值向量μy和集中参数κy通过最大似然估计来估计。
2.设计期望对比损失函数
定义封闭形式的期望对比损失函数LProCo,旨在最大化正样本之间的相似度同时最小化负样本间的距离,使在模型学习过程中更加关注尾部类别的样本。具体来说,结合了两部分损失项实现,交叉熵损失项来确保模型能够准确地预测每个样本的标签,KL散度损失项来通过对比学习以确保模型能够更好地捕捉不同类别之间的差异,特别是对于尾部类别(稀有字符)的识别。具体公式见公式3-5:
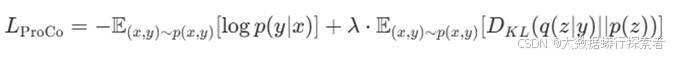
公式 3-5期望对比损失函数
其中,p(x,y) 表示数据的真实分布;q(z∣y) 是给定标签y 的条件下特征 z 的分布;p(z) 是先验分布;D KL是Kullback-Leibler散度;λ是正则化项系数。
引入对比学习损失项,帮助模型更好地捕捉不同字符之间的差异。通过对比学习,模型得以更有效地学习稀有类别的特征,从而提高整体识别精度。对比学习损失可以定义为公式3-6:
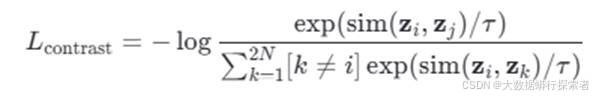
公式 3-6对比学习损失函数
其中,z i和z j分别是来自相同类别的两个样本的特征表示;sim(⋅,⋅)是一个相似度度量函数。
3.类别平衡机制
通过对不同类别的样本数进行加权,使得模型更加关注尾部类别。类别平衡损失可以表示为公式3-7:
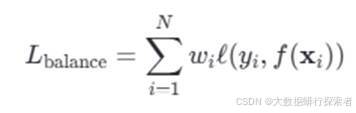
公式 3-7 类别平衡函数
其中,wi是根据类别频率计算得到的权重因子,ℓ(⋅,⋅)是常用的交叉熵损失函数,f(⋅)是预测函数,y i是真实标签。
3.3 模型训练
3.3.1评估指标
大多数长尾作品的测试集是平衡的,但在甲骨文字符识别中,由于可用样本的限制,测试集不平衡。故本实验为了反映对尾部类别的有效性,我们基于两个指标评估在长尾分布数据集上的识别性能:总类准确率和平均类准确率,这两个度量标准表示如下[54]:
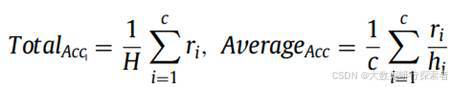
公式 3-8评估指标
其中,H表示测试集都图像总数,c代表了测试集图像的类别数,ri表示类i正确分类的测试图像数,hi表示类i的测试图像总数。
四、预期结果
本研究旨在将ResNet与ProCo(Probabilistic Contrastive Learning)方法相结合,开发出一种能够有效应对长尾分布问题的甲骨文识别系统,该系统能在保持整体性能的同时显著提高对长尾分布中尾部类别的识别精度。预期结果目标具体如下:
- 选择合适的深度学习模型,并对模型进行参数调优,模型性能提高;
- 引入算法后,模型对甲骨文长尾分布数据集尾部类别的识别精度显著提高;
- 识别模型在OBC306数据集上表现良好,识别准确率大于83%。
五、参考资料
- 刘乾先, 董莲池, 张玉春, 等.中华文明实录[M].哈尔滨: 黑龙江人民出版社, 2002
- S. Huang, H. Wang, Y. Liu, X. Shi and L. Jin, "OBC306: A Large-Scale Oracle Bone Character Recognition Dataset," 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, NSW, Australia, 2019, pp. 681-688, doi: 10.1109/ICDAR.2019.00114.
- 高亮,吴建国,卢英,等.书写文字识别算法研究[J].现代计算机(专业版), 2008(7): 23-25.
- 顾绍通.基于拓扑配准的甲骨文字形识别方法[J].计算机与数字工程, 2016, 44(10): 2001-2006.
- Goodfellow I J, Pouget-Abadie J, Mirza M, et al. Generative adversarial networks. Advances in Neural Information Processing Systems, 2014, 3: 2672−2680
- Mei Wang, Weihong Deng, and Sen Su. 2024. Oracle character recognition using unsupervised discriminative consistency network. Pattern Recogn. 148, C (Apr 2024). Redirecting
- 毛亚菲, 毕晓君. 改进 ResNeSt 网络的拓片甲骨文字识别 [J]. 智能系统学报, 2023, 18(3): 450–458.
- 栗青生, 杨玉星, 王爱民. 甲骨文识别的图同构方法[J]. 计算机工程与应用, 2011, 47(8):112–114.
- J. Guo, C. Wang, E. Roman-Rangel, H. Chao and Y. Rui, "Building Hierarchical Representations for Oracle Character and Sketch Recognition," in IEEE Transactions on Image Processing, vol. 25, no. 1, pp. 104-118, Jan. 2016, doi: 10.1109/TIP.2015.2500019.
- Hamamoto, Y., Uchimura, S., Watanabe, M., Yasuda, T., Mitani, Y., & Tomita, S. (1998). A gabor filter-based method for recognizing handwritten numerals. Pattern Recognit., 31, 395-400.
- Bengio Y, Lamblin P, Popovici D, Larochelle H. Greedy layer-wise training of deep networks. NIPS 2006: 153−160
- 刘洋, 陆逸, 魏钰驰, 等. 甲骨文识别技术研究现状与展望[J/OL]. 知识管理论坛, 2022, 8(2): 115-125
- Evgeniou T, Pontil M. Support vector machines: Theory and applications[C]. Advanced Course on Artificial Intelligence. Springer, Berlin, Heidelberg, 1999: 249-257.
- 刘永革, 刘国英. 基于SVM的甲骨文字识别[J]. 安阳师范学院学报, 2017(2): 54-56.
- Y. -K. Zhang, H. Zhang, Y. -G. Liu, Q. Yang and C. -L. Liu, "Oracle Character Recognition by Nearest Neighbor Classification with Deep Metric Learning," 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, NSW, Australia, 2019, pp. 309-314, doi: 10.1109/ICDAR.2019.00057.
- 张颐康, 张恒, 刘永革, 刘成林. 基于跨模态深度度量学习的甲骨文字识别. 自动化学报, 2021, 47(4): 791−800 doi: 10.16383/j.aas.c200443
- 刘芳, 李华飙, 马晋, 等.基于Mask R-CNN的甲骨文拓片的自动检测与识别研究[J].数据分析与知识发现, 2021, 5(12): 88-97.
- 闫升, 刘芳, 孙岱萌, 等.博物馆基于人工智能的甲骨文知识普及与活化传承[J].中国博物馆, 2021(3): 110116, 144.
- 林小渝, 陈善雄, 高未泽, 等.基于深度学习的甲骨文偏旁与合体字的识别研究[J].南京师大学报(自然科学版), 2021, 44(2): 104-116
- 林小渝. 基于深度学习的甲骨文偏旁与合体字识别的研究与实现[D]. 重庆: 西南大学, 2021
- Haisu Guan, Huanxin Yang, Xinyu Wang, Shengwei Han, Yongge Liu, Lianwen Jin, Xiang Bai, and Yuliang Liu. 2024. Deciphering Oracle Bone Language with Diffusion Models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15554–15567, Bangkok, Thailand. Association for Computational Linguistics.
- Zhang, Y., Kang, B., Hooi, B., Yan, S., & Feng, J. (2021). Deep Long-Tailed Learning: A Survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45, 10795-10816.
- Zhang, C., Almpanidis, G., Fan, G., Deng, B., Zhang, Y., Liu, J., Kamel, A., Soda, P., & Gama, J. (2024). A Systematic Review on Long-Tailed Learning. ArXiv, abs/2408.00483.
- Shi, J., Wei, T., Xiang, Y., & Li, Y. (2023). How Re-sampling Helps for Long-Tail Learning? ArXiv, abs/2310.18236.
- C. Huang, Y. Li, C. C. Loy and X. Tang, "Learning Deep Representation for Imbalanced Classification," 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 2016, pp. 5375-5384, doi: 10.1109/CVPR.2016.580.
- E. D. Cubuk, B. Zoph, J. Shlens, and Q. Le, “Randaugment:Practical automated data augmentation with a reduced search space,” in Annual Conference on Neural Information Processing Systems, 2020, pp. 18613–18624.
- H.Zhang, M. Cissé, Y. N. Dauphin, and D. Lopez-Paz, “mixup:Beyond empirical risk minimization,” in The 6th International Conference on Learning Representations, 2018.
- Verma,V., Lamb, A., Beckham, C., Najafi, A., Mitliagkas, I., Lopez-Paz, D., & Bengio, Y. (2018). Manifold Mixup: Better Representations by Interpolating Hidden States. International Conference on Machine Learning.
- Chou, H., Chang, S., Pan, J., Wei, W., & Juan, D. (2020). Remix: Rebalanced Mixup. ArXiv, abs/2007.03943.
- Xu, Z., Chai, Z., & Yuan, C. (2021). Towards Calibrated Model for Long-Tailed Visual Recognition from Prior Perspective. Neural Information Processing Systems.
- Perrett, Toby, Saptarshi Sinha, Tilo Burghardt, Majid Mirmehdi and Dima Damen. “Use Your Head: Improving Long-Tail Video Recognition.” 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2023): 2415-2425.
- S. Khorram, M. Jiang, M. Shahbazi, M. H. Danesh and L. Fuxin, "Taming the Tail in Class-Conditional GANs: Knowledge Sharing via Unconditional Training at Lower Resolutions," 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 2024, pp. 7580-7590, doi: 10.1109/CVPR52733.2024.00724.
- Wang, Jianfeng et al. “RSG: A Simple but Effective Module for Learning Imbalanced Datasets.” 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2021): 3783-3792.
- J. Liu, Y. Sun, C. Han, Z. Dou, and W. Li, “Deep representation learning on long-tailed data: A learnable embedding augmentation perspective,” in IEEE Conference on Computer Vision and Pattern Recognition, 2020, pp. 2970–2979.
- Zhao, Q., Dai, Y., Li, H., Hu, W., Zhang, F., & Liu, J. (2024). LTGC: Long-Tail Recognition via Leveraging LLMs-Driven Generated Content. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 19510-19520.
- Zhang, C., Zhang, C., Zhang, M., & Kweon, I. (2023). Text-to-image Diffusion Models in Generative AI: A Survey. ArXiv, abs/2303.07909.
- Kang, Bingyi, Saining Xie, Marcus Rohrbach, Zhicheng Yan, Albert Gordo, Jiashi Feng and Yannis Kalantidis. “Decoupling Representation and Classifier for Long-Tailed Recognition.” ArXiv abs/1910.09217 (2019): n. pag.
- Duggal, Rahul et al. “ELF: An Early-Exiting Framework for Long-Tailed Classification.” ArXiv abs/2006.11979 (2020): n. pag.
- Huang, Xinlei, Jialiang Tang, Xubin Zheng, Jinjia Zhou, Wenxin Yu and Ning Jiang. “Learn from Balance: Rectifying Knowledge Transfer for Long-Tailed Scenarios.” ArXiv abs/2409.07694 (2024): n. pag.
- Rangwani, Harsh, Pradipto Mondal, Mayank Mishra, Ashish Ramayee Asokan and R. Venkatesh Babu. “DeiT-LT: Distillation Strikes Back for Vision Transformer Training on Long-Tailed Datasets.” 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024): 23396-23406.
- Wang, X., Lian, L., Miao, Z., Liu, Z., & Yu, S.X. (2020). Long-tailed Recognition by Routing Diverse Distribution-Aware Experts. ArXiv, abs/2010.01809.
- Chen, L., Zhang, Y., Song, Y., Shen, Z., & Liu, L. (2024). LFME: A Simple Framework for Learning from Multiple Experts in Domain Generalization. ArXiv, abs/2410.17020.
- Guo, Y., & Zhang, C. (2021). Recent Advances in Large Margin Learning. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44, 7167-7174.
- Y. Li et al., "Overcoming Classifier Imbalance for Long-Tail Object Detection With Balanced Group Softmax," 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 2020, pp. 10988-10997, doi: 10.1109/CVPR42600.2020.01100.
- Tan, Jingru, Changbao Wang, Buyu Li, Quanquan Li, Wanli Ouyang, Changqing Yin and Junjie Yan. “Equalization Loss for Long-Tailed Object Recognition.” 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2020): 11659-11668.
- 苏剑林. (Aug. 31, 2020). 《再谈类别不平衡问题:调节权重与魔改Loss的对比联系 》[Blog post]. Retrieved from https://kexue.fm/archives/7708
- J. Tan, X. Lu, G. Zhang, C. Yin and Q. Li, "Equalization Loss v2: A New Gradient Balance Approach for Long-tailed Object Detection," 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 2021, pp. 1685-1694, doi: 10.1109/CVPR46437.2021.00173.
- S. Zhang, Z. Li, S. Yan, X. He and J. Sun, "Distribution Alignment: A Unified Framework for Long-tail Visual Recognition," 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 2021, pp. 2361-2370, doi: 10.1109/CVPR46437.2021.00239.
- Wang, W., Zhang, T., Zhao, Y., Jin, X., Mouchere, H., Yu, X. (2023). Improving Oracle Bone Characters Recognition via A CycleGAN-Based Data Augmentation Method. In: Tanveer, M., Agarwal, S., Ozawa, S., Ekbal, A., Jatowt, A. (eds) Neural Information Processing. ICONIP 2022. Communications in Computer and Information Science, vol 1793. Springer, Singapore. https://doi.org/10.1007/978-981-99-1645-0_8
- Li, J., Dong, B., Wang, QF., Ding, L., Zhang, R., Huang, K. (2023). Decoupled Learning for Long-Tailed Oracle Character Recognition. In: Fink, G.A., Jain, R., Kise, K., Zanibbi, R. (eds) Document Analysis and Recognition - ICDAR 2023. ICDAR 2023. Lecture Notes in Computer Science, vol 14190. Springer, Cham. Decoupled Learning for Long-Tailed Oracle Character Recognition | SpringerLink
- Li, J., Wang, Q. F., Huang, K., Yang, X., Zhang, R., & Goulermas, J. Y. (2023). Towards better long-tailed oracle character recognition with adversarial data augmentation. Pattern Recognition, 140, Article 109534. Redirecting
- K. He, X. Zhang, S. Ren and J. Sun, "Deep Residual Learning for Image Recognition," 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 2016, pp. 770-778, doi: 10.1109/CVPR.2016.90.
- Du, C., Wang, Y., Song, S., & Huang, G. (2024). Probabilistic Contrastive Learning for Long-Tailed Visual Recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 46, 5890-5904.
- Li, J., Wang, Q., Zhang, R., & Huang, K. (2021). Mix-Up Augmentation for Oracle Character Recognition with Imbalanced Data Distribution. IEEE International Conference on Document Analysis and Recognition.




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











