







一、课题意义
主要目标是在基于思维链(CoT)的背景下,设计和实现一种轻量级且高效的提示词生成与优化系统,旨在降低对庞大语言模型的依赖。
1.1作用
本课题来自于近年来大型语言模型(LLM)在自然语言处理领域的广泛应用,特别是生成式人工智能技术的迅速发展。随着这些模型的普及,思维链(CoT)提示使大语言模型能够按照具体推理步骤处理复杂的任务,让大语言模型在常识推理、数学逻辑推理和可解释性等方面表现出更强的能力。
然而,CoT方法的主要缺点在于其对庞大语言模型的依赖,这些模型通常拥有数百亿的参数,在大规模部署方面面临计算资源消耗大、响应时间长和成本高等挑战。
因此,主要目标是在基于思维链(CoT)的背景下,设计和实现一种轻量级且高效的提示词生成与优化系统,旨在降低对庞大语言模型的依赖。该系统将通过优化提示词的生成策略,使得较小规模的语言模型也能够在常识推理、逻辑推理等复杂任务中取得较好的表现,增强其在实际应用场景中的部署能力,例如对话系统、自动问答等,推动智能对话和文本生成技术的广泛应用。
1.2实用价值
1.2.1提高模型性能
通过优化思维链技术,未来的大型语言模型可以显著提升在回答复杂问题时的准确性和详细性。模型将具备更强的多步推理能力,能够处理涉及多个逻辑环节和知识领域的问题。同时,提示词生成和优化系统的改进将使模型在各种任务中表现出更高的鲁棒性,减少因输入数据的噪声或不规范而导致的错误。此外,多模态数据的融合将进一步丰富模型的上下文理解,使其在处理图像和视频相关的问题时也能生成高质量的答案,从而更好地满足用户的多样化需求。
1.2.2改善用户体验
未来的大型语言模型将更加擅长理解用户的问题背景和意图,通过自适应提示词生成方法,系统能够根据用户的输入自动调整提示词,生成更加自然、流畅和准确的答案。这种能力不仅提高了用户的交互体验,还增强了用户对AI聊天助手的信任和依赖。在对话系统中,模型将能够识别用户的语气和情感,提供更加人性化的回应,从而提升用户满意度。此外,模型的可解释性和透明度的提升将使用户更容易理解模型的决策过程,增强其对技术的信任感。
1.2.3实际应用广泛
未来的大型语言模型在实际应用中的范围将更加广泛,可以有效地应用于多个生活和工作场景。在AI客服领域,模型将能够更准确地识别用户的需求,提供个性化的解决方案,减少用户等待时间和提高问题解决率。在知识平台中,模型将能够生成详细、准确的知识内容,帮助用户快速获取所需信息,提升平台的用户黏性。在教育辅导方面,模型将具备更强的多模态数据处理能力,能够结合文本、图像和视频等多种资源,为学生提供更加丰富和个性化的学习材料。此外,模型在医疗咨询、法律顾问、内容创作等领域的应用也将更加广泛,为专业人士和普通用户提供高效、准确的支持。
1.3创新性
1.3.1生成提示词方面
1.基于问题类型生成提示词
设计的大型语言模型将采用先进的分类算法,自动识别用户问题的类型(如多步推理、知识查询、情感分析等),并根据问题类型生成相应的提示词。这种技术能够确保模型在处理不同类型的问题时,使用最合适的上下文信息和推理逻辑,从而显著提高回答的准确性和相关性。例如,对于数学问题,模型可以生成包含公式和步骤的提示词;对于文学分析,则生成包含背景知识和经典引用的提示词。
2.动态调整提示词长度技术
为了适应不同复杂度的问题,模型将具备动态调整提示词长度的能力。通过分析问题的具体内容和复杂度,模型能够智能地决定提示词的长度,从而在保证上下文信息充分的同时,避免冗余和计算资源的浪费。这种技术将使模型在处理简单问题时更加高效,在处理复杂问题时更加准确和详细。
1.3.2优化方面
1.结合用户反馈优化提示词
用户反馈是改进模型性能的重要依据。未来的提示词生成与优化系统将能够实时收集和分析用户的反馈信息,识别用户对答案的满意程度和改进需求。基于这些反馈,系统将自动调整提示词的生成策略,进一步提高生成答案的质量和用户满意度。例如,如果用户对某些类型的回答不满意,系统将自动优化相关提示词的生成方式,以减少此类错误。
2.基于用户偏好优化提示词
用户偏好对提升交互体验具有重要作用。模型将通过用户的历史交互记录,识别用户的语言习惯、信息需求和偏好风格,从而生成更加符合用户个人特点的提示词。这种个性化优化不仅能够提高用户的满意度,还能增强用户的使用黏性。例如,对于偏好简洁回答的用户,模型将生成简明扼要的提示词;对于需要详细解释的用户,则生成更加详细和全面的提示词。
3.基于历史反馈优化提示词
未来的提示词生成系统将利用用户长期的历史反馈数据,进行持续的模型训练和优化。通过分析大量的历史交互记录,系统能够识别常见的问题类型和答案模式,不断改进提示词生成的准确性。此外,基于历史反馈的优化还可以帮助模型在特定领域中积累更丰富的知识和经验,从而在处理相关问题时表现出更强的能力。例如,在法律咨询领域,模型将通过用户的历史反馈,逐步优化法律条文的引用和解释,提高其在法律问题上的专业性和可靠性。
1.4国内外研究现状与发展趋势
思维链(Chain-of-Thought, CoT)技术最初由谷歌提出,用于提高大型语言模型的推理能力。研究表明,通过显式地引导模型生成逐步推理的过程,可以显著提升其在复杂任务上的表现。国内的研究机构和企业也逐渐关注并应用思维链技术。一些知名的研究机构如阿里云、百度等已经在这方面进行了大量的研究,并在实际应用中取得了显著进展。
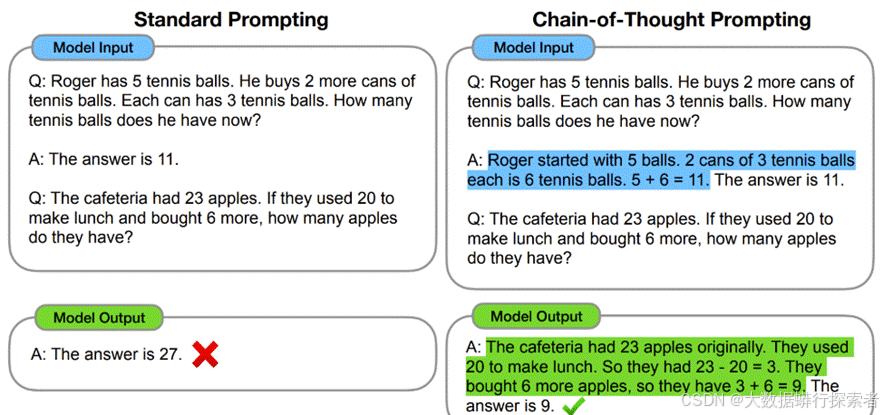
思维链提示最早由Wei et al. (2022)在《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》中提出。他们发现,通过向模型提供一系列逐步推理的示例,可以显著提高模型在数学推理、常识推理和逻辑推理等任务中的表现。
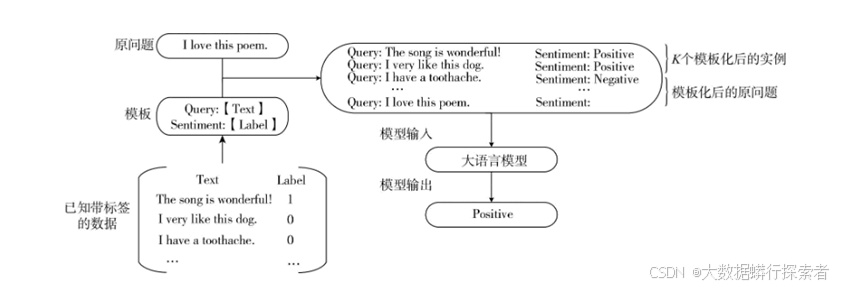
提示学习的概念最早兴起于自然语言处理(natural language processing,NLP)领域,弥补了预训练任务和微调任务之间的差距,在文本分类、信息抽取和逻辑推理等多种任务中取得很好的结果。受此影响,提示学习逐渐应用于计算机视觉(computer vision,CV)和多模态领域,在图像分类、视觉问答等任务中取得很大的进展。凭借其在效率、任务适应性和泛化能力等方面的优势,提示学习已广泛应用多种场景。如指导模型在数据匮乏的情况下学习有效知识,实现小样本学习和零样本学习;通过设计不同的提示引导模型同时学习多个任务,促进任务之间的知识共享和协同优化,实现多任务学习;帮助模型理解来自不同模态的数据,促进跨模态的信息融合和理解,实现跨模态学习;利用提示信息实现更加精准、个性化的推荐等。最近,提示学习还用于指导ChatGPT和GPT-4等大语言模型(large language models,LLMs)实现对话任务。利用提示学习可以帮助ChatGPT等LLMs更好地理解用户意图和上下文信息,提高其生成答案的准确性和可控性,同时也可以降低模型生成无意义或不相关答案的概率。传统的基于提示学习的方法可以将下游任务重新表述为完形填空任务,利用PLMs的文本生成能力来实现下游任务。其中涉及提示模板(prompt template)设计和语言表达器(language verbalizer)设计两个阶段,旨在搜索最佳提示模板和答案映射空间。传统的基于提示学习的方法将情感分析任务转换为完形填空任务。
国外研究者们在后续的研究中进一步探索了思维链提示在大数据环境中的应用。例如,Zhong et al. (2022)在《Chain of Thought: A Path to Systematic Generalization》中,探讨了思维链提示在大规模数据集上的系统性泛化能力。他们提出了一套评估指标,用于衡量模型在未见过任务中的泛化能力,并通过大规模数据集验证了思维链提示的有效性。
Wei, J代表作Chain-of-Thought Prompting Elicits Reasoning in Large Language Models.在大规模预训练语言模型在复杂推理任务中的表现不够理想的研究背景下,通过向模型提供一系列逐步推理的示例,引导模型进行多步推理的方法,在多个推理任务中,思维链提示显著提高了模型的准确率。
Zhong, Z.的Chain of Thought: A Path to Systematic Generalization.探讨思维链提示在系统性泛化中的作用,通过多层次的提示策略,评估模型在未见过任务中的泛化能力,使得思维链提示有助于模型在大规模数据集上的表现,特别是在需要多步逻辑推理的场景中。
随着思维链提示技术的广泛应用,研究者开始关注如何利用大数据进行提示词的生成和优化。Shin et al. (2022)在《autoprompt: Eliciting Knowledge from Language Models with Automatic Soft Prompts》中,提出了一种自动化的提示词生成方法,通过优化隐式提示词来提高模型性能。他们利用大规模数据集来训练和验证该方法,结果显示在多个任务中表现良好。
此外,Kuck et al. (2022)在《Measures of Reasoning in Language Models》中,探讨了如何评估LLMs在多步推理任务中的表现,并提出了一套评估指标。他们利用大规模数据集验证了这些指标的有效性,特别是在系统性泛化能力的评估中。
Shin, J.的autoprompt: Eliciting Knowledge from Language Models with Automatic Soft Prompts.中提出了一种自动化的提示词生成方法,通过优化隐式提示词来提高模型性能,在手动设计提示词耗时且难以扩展情况下,实现了自动生成的提示词在多个任务中表现良好,尤其是在文本分类和情感分析任务中。
多步推理是思维链提示的核心,国外研究者在这一领域的研究也较为深入。特别是一些研究关注了如何利用大规模数据集来训练多步推理模型。例如,Lu et al. (2023)在《ODEformer: Neural Ordinary Differential Operators for Modeling Dynamical Systems》中,提出了基于神经常微分方程的多步推理框架,并利用大规模数据集进行了验证。
Lu, Y.在ODEformer: Neural Ordinary Differential Operators for Modeling Dynamical Systems.文中提到为了满足系统建模中的推理需求,使用一种基于神经常微分方程的多步推理框架,通过思维链提示引导模型进行多步推理,在大规模动态系统建模任务中,该框架显著提高了模型的推理能力。
国内学者对思维链提示的研究起步较晚,但近年来取得了显著进展。特别是在知识图谱和大数据背景下的应用较为突出。陈丹琦,《基于知识图谱的思维链提示生成方法》发现知识密集型任务中需要更准确的推理路径,利用知识图谱中的实体和关系信息,生成更丰富的思维链提示,实现在大规模知识密集型任务中,基于知识图谱的提示生成方法显著提高了模型的推理准确率和覆盖率。刘洋,《图神经网络在思维链提示生成中的应用》利用图神经网络(GNN)建模任务的依赖关系,生成更有效的思维链提示,在多步推理任务中的依赖关系建模研究背景下,在多个大规模多步推理任务中,基于GNN的提示生成方法显著提高了模型的推理能力。
国内研究者在提示词优化方面也进行了深入探索,提出了多种基于大数据和强化学习的优化方法。张鹏等(2023)在《基于强化学习的提示词优化方法》中,提出了一种基于强化学习的提示词优化方法,通过动态调整提示词参数来优化模型性能。他们利用大规模数据集进行训练和验证,结果显示在多个NLP任务中显著提升了模型的推理准确率和鲁棒性。
多模态任务中,思维链提示也得到了广泛的研究。陈磊等(2023)在《基于多模态信息的思维链提示生成方法》中,结合图像和文本信息,生成多模态的思维链提示。他们利用大规模多模态数据集进行实验,结果显示该方法在多个多模态任务中显著提高了模型的推理准确率。
大型预训练模型如BERT、GPT-3、T5等在自然语言处理(NLP)领域取得了巨大成功。这些模型在多种任务上表现出色,包括文本生成、翻译、问答等。国内的大模型研究也非常活跃。例如,阿里云的Qwen、百度的ERNIE、华为的Pangu等模型在多个NLP任务中都表现出色,并且逐渐应用于各种实际场景。
至今为止,基于思维链的大模型提示词生成与优化技术不断发展和丰富。除了基本的思维链提示外,已经发展出自动化的提示词生成方法、多层次的提示策略、基于知识图谱的提示生成、图神经网络建模和多模态提示等多种类型。这些不同类型的提示词生成与优化方法在各自的应用场景中都有其独特的优势,显著提高了模型在复杂推理任务中的表现。总的来说,该领域在国内外都受到了广泛的关注和研究,并在多个NLP任务中取得了显著的成果。
未来,随着大数据和深度学习技术的不断进步,基于思维链的提示词生成与优化系统有望在更多领域发挥重要作用。同时未来大型语言模型的发展将更加注重效率、准确性和鲁棒性。思维链技术将在更为复杂的任务中得到广泛应用,如多步推理、对话系统和生成任务。研究人员将开发更多方法来生成和优化思维链提示词,以进一步提升模型的推理能力。未来的提示词生成与优化系统将更加重视多模态数据的融合,例如将文本、图像和视频等多种类型的数据结合起来,提供更丰富和准确的提示信息。此外,将开发自适应提示词生成方法,使系统能够根据不同的任务和输入数据自动调整提示词,以达到最优性能。提高模型的可解释性和透明度也是重要的研究方向,旨在探索如何生成更具可解释性的提示词,以便于模型的理解和调试。
1.5尚未解决的问题
需要设计一种高效且准确的自动生成提示词的方法,使系统能够在不同任务和场景下自适应地生成提示词。
当前的思维链技术在某些特定任务上表现良好,但需要提高其泛化能力,使得在更多类型的任务中都能达到较高的性能。
大模型和思维链技术的计算资源需求较高,需要一种在保证性能的同时降低计算成本,还能提高资源利用效率方案。
二、课题方案
2.1任务定义
设计并实现一个基于思维链(Chain of Thought, CoT)的提示词生成与优化系统,提高AI聊天助手在处理复杂问题时的准确性和详细性。
应用场景:知识问答系统。

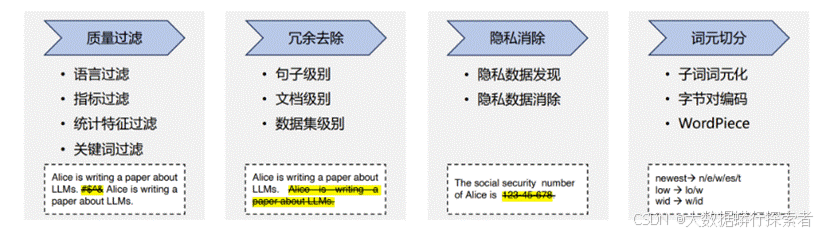
2.2数据收集与预处理
数据来源:收集多样化的用户对话数据,可以从开源数据集、众包平台或自定义场景中获取。
数据预处理:清洗和整理数据,去除无关信息和噪声。
标注数据,包括问题类型、中间步骤和最终答案。
2.3模型选择与训练
模型选择:
预训练模型:选择已经预训练的大型语言模型,如BERT、GPT等。
使用预处理后的数据集进行微调。
采用多任务学习,同时优化提示词生成和答案生成。
2.4提示词生成算法设计
2.4.1静态提示词算法设计
基于模板的方法:预定义一组提示词模板,根据问题类型和内容选择合适的模板。
规则引擎:设计规则引擎,根据预定义的规则生成提示词。
2.4.2动态提示词算法设计
基于上下文理解:使用Transformer模型理解用户输入和对话历史。
问题类型识别:使用分类算法(BERT、LSTM)识别问题类型。
中间步骤生成:利用多步骤推理算法生成中间步骤提示词。
2.4.3提示词优化算法设计
多步骤优化机制:使用强化学习算法,在生成和优化过程中引入奖励机制,持续改善提示词的生成和优化效果。
混合模型方法:结合小型模型和大型预训练模型的优势,优化推理过程,从而减少庞大模型的计算负担。
2.5前端框架设计
框架:Vue.js
状态管理:Vue.js
样式:CSS-in-JS
路由:Vue Router
实现功能:用户输入功能、提示词显示功能、答案显示功能、反馈机制功能、历史记录展示功能。
2.6后端框架设计
框架:Flask
数据库:MySQL
模型服务:TorchServe
实现功能:处理用户输入功能、提示词生成优化功能、生成答案功能、接受反馈处理功能、数据存储功能。
2.7模型评估
评估指标:
准确率:使用BLEU、ROUGE等指标评估生成答案的准确性。
连贯性:评估生成对话的连贯性和自然性。
多样性:评估生成提示词的多样性和丰富性。
评估方法:
自动评估:使用上述指标进行量化评估。
人工评估:通过问卷调查和用户满意度测评,收集主观反馈。
对比实验:与现有方法进行对比,验证性能提升。
2.8实际应用测试
测试环境:搭建一个AI聊天助手的知识测试平台,模拟实际应用场景。
用户测试:邀请用户进行测试,收集实际使用中的数据和反馈。
迭代优化:根据测试结果,不断优化模型和算法。
三、需要条件
3.1硬件条件
高性能计算服务器:需要高性能GPU用于训练和推理大型语言模型。
存储设备:需要足够的存储空间,用于存储大规模的训练数据和模型参数。
3.2软件条件
Python:主编程语言,用于模型训练和后端开发。
Node.js:用于前端开发的JavaScript运行环境。
开发和调试工具:PyTorch、TensorFlow等深度学习框架,以及相关的调试工具和库。
专用软件和算法库:自然语言处理工具包(如NLTK、spaCy)、优化算法库(如Adam、RMSprop)等。
4.主要参考文献
[1]李志东, 罗琪彬, 乔思龙. 基于句粒度提示的大语言模型时序知识问答方法[J]. 网络安全与数据治理, 2023, 第42卷(12):7-13.
[2]李荣涵1, 浦荣成1, 沈佳楠2等. 基于思维链的大语言模型知识蒸馏[J]. 数据采集与处理, 2024, 第39卷(3):547-558.
[3]黄峻1,2, 林飞1, 杨静3,4,5等. 生成式AI的大模型提示工程:方法、现状与展望.智能科学与技术学报, 2024, 第6卷(2):115-133.
[4]陶江垚,奚雪峰,盛胜利,等.结构化思维提示增强大语言模型推理能力综述[J/OL].计算机工程与应用,1-21[2024-12-14]
[5]胡钇.基于多模态思维链推理的视觉问答方法研究[D].电子科技大学
[6]方海光,王显闯,洪心,等.面向AIGC的教育提示工程学习提示单设计及应用[J].现代远距离教育,2024,(02):62-70.DOI:10.13927/j.cnki.yuan.20240509.002.
[7]王智悦,于清,王楠,等. 基于知识图谱的智能问答研究综述[J]. 计算机工程与应用,2020,56(23):1-11.
[8]王东清,芦飞,张炳会,等.大语言模型中提示词工程综述[J/OL].计算机系统应用,1-10[2024-12-15].https://doi.org/10.15888/j.cnki.csa.009782.
[9]陶江垚,奚雪峰,盛胜利,等.结构化思维提示增强大语言模型推理能力综述[J/OL].计算机工程与应用,1-21.http://kns.cnki.net/kcms/detail/11.2127.TP.20241025.1528.013.html.
[10]MACIEJ B,NILS B,ALES K,et al.Graph of Thoughts:Solving Elaborate Problems with Large Language Models[C]∥Proceedings of the AAAI Conference on Artificial Intelligence,2024:17682-17690.
[11]MICHIHIRO Y,XIN Y C,YU J L,et al.Large Language Models as Analogical Reasoners[J].ArXivabs,2023:17825-17850
[12]BROWN T B,MANN B,RYDER N,et al.Language Models are Few-Shot Learners[J].Association for Computational Linguistics,2021(10):1-15
[13]孙斐.大模型提示词工程的进展、综述及展望[J].计算机应用文摘,2024,40(18):179-182
[14]郭子浩,孙由之,张梦林,王欣然,陈雨洁.大语言模型背景下提示词工程赋能英语口语学习研究[J].教育进展,2023,13(11):8213-8224
[15]方海光,王显闯,洪心,舒丽丽.面向AIGC的教育提示工程学习提示单设计及应用[J].现代远距离教育,2024(2):62-70
[16]沈君凤,周星辰,汤灿.基于改进的提示学习方法的双通道情感分析模型[J].计算机应用,2024,44(6):1796-1806
[17]KALCHBRENNER N,GREFENSTETTE E, BLUNSOM P. A convolutional neural network for modelling sentences [EB/OL].(2014-04-08)[2023-05-30].
[18]PETRONI F, ROCKTÄSCHEL T, LEWIS P,et al. Language models as knowledge bases[EB/OL].(2019-09-03)[2023-05-30].
[19]张心月,刘蓉,魏驰宇,等.融合提示知识的方面级情感分析[J].计算机应用,2023,43(9):2753-2759.
[20]江洋洋,金伯,张宝昌.深度学习在自然语言处理领域的研究进展[J].计算机工程与应用,2021,57(22)
[21]WEISS K, KHOSHGOFTAAR T M, WANG D D. A survey of transfer learning [J]. Journal of Big Data,2016,3
[22]VASWANI A,SHAZEER N,PARMAR N,et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc,2017:6000-6010.
[23]RÜCKLÉ A, GEIGLE G, GLOCKNER M, et al. AdapterDrop:on the efficiency of adapters in transformers [EB/OL].(2020-10-22)[2023-05-30].




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











