










目录
1. 前言
在强化学习领域,深度Q网络(DQN)开启了利用深度学习解决复杂决策问题的新篇章。然而,标准DQN存在一个显著问题:Q值的过估计。为解决这一问题,Double DQN应运而生,它通过引入两个网络来减少Q值的过估计,从而提高策略学习的稳定性和性能。本文将深入浅出地介绍Double DQN的核心思想,并通过一个完整python实现案例,帮助大家全面理解强化这一学习算法。
2. Double DQN的核心思想
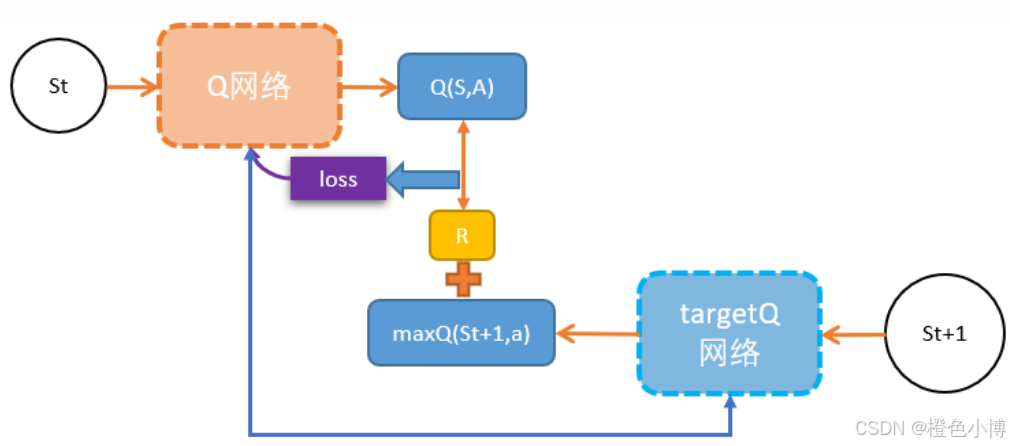
标准DQN使用同一个网络同时选择动作和评估动作价值,这容易导致Q值的过估计。Double DQN通过将动作选择和价值评估分离到两个不同的网络来解决这个问题:
-
一个网络(在线网络)用于选择当前状态下的最佳动作
-
另一个网络(目标网络)用于评估这个动作的价值
这种分离减少了自举过程中动作选择和价值评估的关联性,从而有效降低了Q值的过估计。
结构如下:
3. Double DQN 实例:倒立摆
接下来,我们将实现一个完整的Double DQN,解决CartPole平衡问题。这个例子包含了所有关键组件:
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import gym
import random
from collections import deque
# 1. 定义DQN网络结构
class DQN(nn.Module):
def __init__(self, state_dim, action_dim):
super(DQN, self).__init__()
self.fc1 = nn.Linear(state_dim, 128)
self.fc2 = nn.Linear(128, 128)
self.fc3 = nn.Linear(128, action_dim)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
# 2. 经验回放缓冲区
class ReplayBuffer:
def __init__(self, capacity):
self.buffer = deque(maxlen=capacity)
def add(self, state, action, reward, next_state, done):
self.buffer.append((state, action, reward, next_state, done))
def sample(self, batch_size):
samples = random.sample(self.buffer, batch_size)
states, actions, rewards, next_states, dones = zip(*samples)
return states, actions, rewards, next_states, dones
def __len__(self):
return len(self.buffer)
# 3. Double DQN代理
class DoubleDQNAgent:
def __init__(self, state_dim, action_dim):
self.policy_net = DQN(state_dim, action_dim)
self.target_net = DQN(state_dim, action_dim)
self.target_net.load_state_dict(self.policy_net.state_dict())
self.target_net.eval()
self.optimizer = optim.Adam(self.policy_net.parameters(), lr=0.001)
self.replay_buffer = ReplayBuffer(10000)
self.batch_size = 64
self.gamma = 0.99 # 折扣因子
self.epsilon = 1.0 # 探索率
self.epsilon_decay = 0.995
self.min_epsilon = 0.01
self.action_dim = action_dim
# 根据ε-greedy策略选择动作
def select_action(self, state):
if random.random() < self.epsilon:
return random.randint(0, self.action_dim - 1)
else:
with torch.no_grad():
return self.policy_net(torch.FloatTensor(state)).argmax().item()
# 存储经验
def store_transition(self, state, action, reward, next_state, done):
self.replay_buffer.add(state, action, reward, next_state, done)
# 更新网络
def update(self):
if len(self.replay_buffer) < self.batch_size:
return
# 从经验回放中采样
states, actions, rewards, next_states, dones = self.replay_buffer.sample(self.batch_size)
# 转换为PyTorch张量
states = torch.FloatTensor(states)
actions = torch.LongTensor(actions)
rewards = torch.FloatTensor(rewards)
next_states = torch.FloatTensor(next_states)
dones = torch.FloatTensor(dones)
# 计算当前Q值
current_q = self.policy_net(states).gather(1, actions.unsqueeze(1)).squeeze(1)
# 计算目标Q值(使用Double DQN方法)
# 使用策略网络选择动作,目标网络评估价值
with torch.no_grad():
# 从策略网络中选择最佳动作
policy_actions = self.policy_net(next_states).argmax(dim=1)
# 从目标网络中评估这些动作的值
next_q = self.target_net(next_states).gather(1, policy_actions.unsqueeze(1)).squeeze(1)
target_q = rewards + self.gamma * next_q * (1 - dones)
# 计算损失并优化
loss = nn.MSELoss()(current_q, target_q)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
# 更新目标网络(软更新)
for target_param, policy_param in zip(self.target_net.parameters(), self.policy_net.parameters()):
target_param.data.copy_(0.001 * policy_param.data + 0.999 * target_param.data)
# 减少探索率
self.epsilon = max(self.min_epsilon, self.epsilon * self.epsilon_decay)
# 训练过程
def train_double_dqn():
# 创建环境
env = gym.make('CartPole-v1')
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
# 创建代理
agent = DoubleDQNAgent(state_dim, action_dim)
# 训练参数
episodes = 500
max_steps = 500
# 训练循环
for episode in range(episodes):
state, _ = env.reset()
total_reward = 0
for step in range(max_steps):
action = agent.select_action(state)
next_state, reward, done, _, _ = env.step(action)
# 修改奖励以加速学习
reward = reward if not done else -10
agent.store_transition(state, action, reward, next_state, done)
agent.update()
total_reward += reward
state = next_state
if done:
break
# 每10个episodes更新一次目标网络
if episode % 10 == 0:
agent.target_net.load_state_dict(agent.policy_net.state_dict())
print(f"Episode: {episode + 1}, Total Reward: {total_reward}, Epsilon: {agent.epsilon:.2f}")
env.close()
# 执行训练
if __name__ == "__main__":
train_double_dqn()
4. Double DQN的关键改进点
-
双网络结构:通过将动作选择(策略网络)和价值评估(目标网络)分离,减少了Q值的过估计。
-
经验回放:通过存储和随机采样历史经验,打破了数据的相关性,提高了学习稳定性。
-
ε-greedy策略:平衡探索与利用,随着训练进行逐渐减少探索概率。
目标网络在Double DQN中扮演着非常重要的角色:
-
它为策略网络提供稳定的目标Q值
-
通过延迟更新,减少了目标Q值的波动
-
与策略网络共同工作,实现了动作选择和价值评估的分离
5. 双重网络更新策略
在Double DQN中,我们使用了软更新(soft update)策略来更新目标网络:
for target_param, policy_param in zip(self.target_net.parameters(), self.policy_net.parameters()):
target_param.data.copy_(0.001 * policy_param.data + 0.999 * target_param.data)这种软更新方式比传统的目标网络定期硬更新(hard update)更平滑,有助于训练过程的稳定。
6. 总结
本文通过详细讲解Double DQN的原理,并提供了完整的python实现代码,展示了如何应用这一先进强化学习算法解决实际问题。与标准DQN相比,Double DQN通过引入双网络结构,有效解决了Q值过估计问题,提高了策略学习的稳定性和最终性能。Double DQN是强化学习领域的一个重要进步,为后续更高级的算法(如Dueling DQN、C51、Rainbow DQN等)奠定了基础。通过理解Double DQN的原理和实现,读者可以为进一步探索复杂强化学习算法打下坚实基础。在实际应用中,可以根据具体任务调整网络结构、超参数(如学习率、折扣因子、经验回放缓冲区大小等)以及探索策略,以获得最佳性能。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











