







向前引入法(FORWARD)
- 开始时模型中只有常数项
- 自变量按照
对因变量的贡献从大到小依次进入方程直至方程外没有达到入选标准的变量 - 每选入一个变量进入方程,则
重新计算方程外各自变量(在扣除了已选入变量的影响后)对Y的贡献 - 变量一旦进入模型就不再剔除
代码
#首先读入数据
data <- read_excel("data.xlsx")
#创建模型
lm1 <- lm(Y ~ 1, data=data)
#使用AIC准则逐步回归
step1 <- step(lm1,scope=list(upper=~X1+X2+X3+X4+X5+X6+X7,lower=~1),direction="forward")
#查看结果
summary(step1)
一共有七个自变量X1~X7,一个因变量Y
首先创建初始线性回归模型,Y~1表示只有常数项
第二步使用step函数执行逐步回归,scope参数定义了搜索空间,upper表示最多能加入所有的自变量,lower部分表示最少的自变量个数(0)
direction="forward"表示使用向前引入法的回归策略
结果
图中表示没有变量加入时的AIC=43.25,而逐步回归的目标是选择一个具有最低AIC值的模型,可以看到除了X5,其他变量加入后都会使AIC的值减小

因此,第一次选择X3加入
X3加入之后需要重新计算其他变量对Y的影响,剩下X2、X1、X7
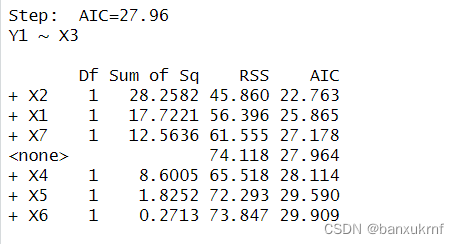
于是第二次选择X2加入,以此类推,第三次选择X7

第四次选择X5

第五次选择X4

X4加入之后,剩下的X1和X6的加入都会使AIC值增大,因此停止回归

最后查看回归结果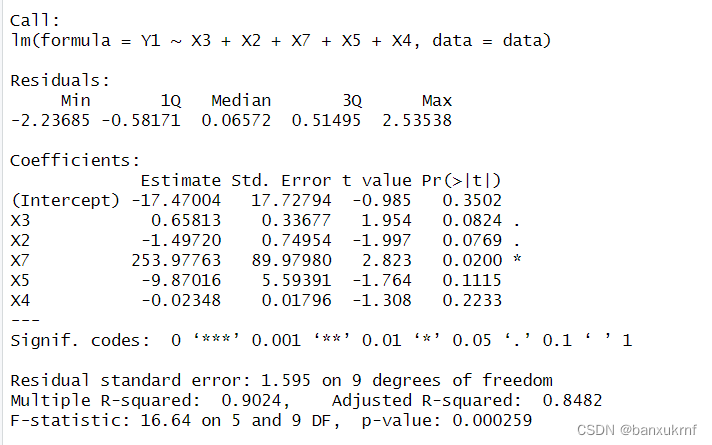
向后剔除法(BACKWORD)
向后剔除法和向前加入法正好相反
- 刚开始
全部自变量都在方程之中 - 按照自变量对因变量的贡献
由小到大依次剔除 - 每剔除一个变量,则
重新计算未被剔除的各自变量对因变量的贡献,直至没有自变量符合被剔除标准 - 自变量
一旦被剔除,不再考虑进入
代码
首先引入全部变量,direction="backward"表示使用向后法进行回归
#首先读入数据
data <- read_excel("data.xlsx")
#创建模型
lm2 <- lm(Y1 ~ X1+X2+X3+X4+X5+X6+X7, data=data)
#使用AIC准则逐步回归
step2 <- step(lm2,direction="backward")
#查看结果
summary(step2)
结果
全部变量都在的时AIC=21.52,接下来和上面类型,依次剔除自变量



结果和向前法一样

逐步回归法(STEPWISE)
逐步回归法结合了向前法和向后法,既可加入变量也可剔除
代码
Y1~.表示引入所有变量,direction="both"表示即可加入也可剔除
#首先读入数据
data <- read_excel("data.xlsx")
#创建回归模型
lm3 <- lm(Y1 ~ ., data=data)
#使用AIC准则逐步回归
step3 <- step(lm3, direction="both")
#查看逐步回归结果
summary(step3)
结果



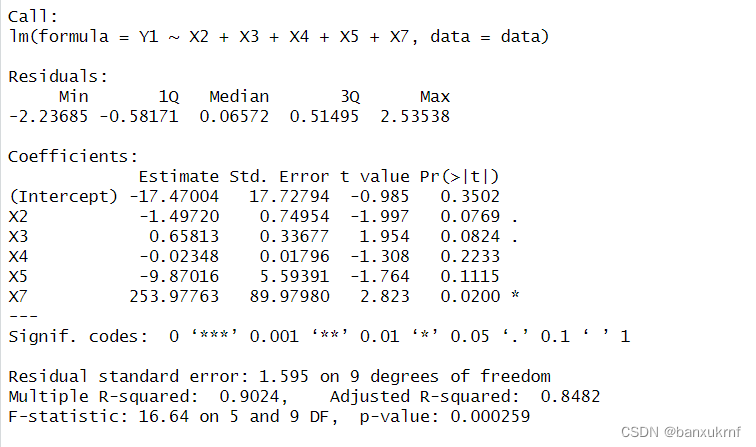
结果都是一样的,但是从右边结果可以看到回归效果并不显著(在显著水平为0.05时,X4和X5不显著),决定系数R²也只有0.9024,因此可以在此基础上进行优化

“Signif. codes: 0 ‘ *** ’ 0.001 ‘ ** ’ 0.01 ‘ * ’ 0.05 ‘ . ’ 0.1 ‘ ’ 1 表示:
“ *** ”(三个星号):0.001 水平的显著性
“ ** ”(两个星号):0.01 水平的显著性
“ * ”(一个星号):0.05 水平的显著性
‘ . ’(点):0.1 水平的显著性
’ ’ (空格):不显著(大于 0.1)
逐步回归的优化
使用drop1()查看剔除变量之后AIC的变化
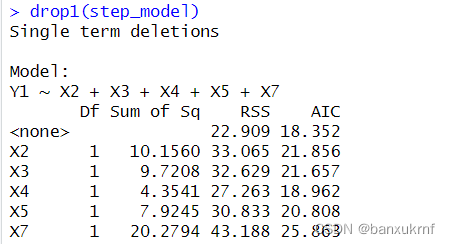
可以看到,剔除X4后AIC上升变化最小,且残差平方和RSS上升也最少(残差平方和越小拟合效果越好)
因此选择剔除X4,只留下X2、X3、X5、X7
drop1(lm3)
lm4 <- lm(Y1 ~ X2+X3+X5+X7, data=data)
step4 <- step(lm4, direction="both")
summary(step4)

从结果看到,除了X5,其他变量的拟合效果都较好,同理,如果把X5剔除掉,拟合效果如下
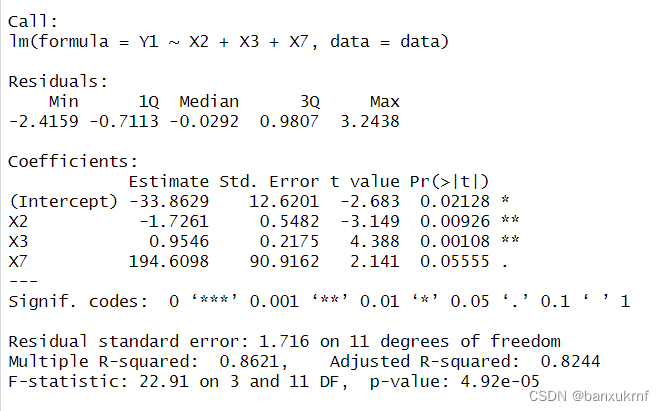
这样,每个变量的检验都是显著的,但是R²依然很低(甚至更低),这里暂不考虑R²的影响。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









