






1.使用yolov4-pytorch-master进行模型训练
实验步骤:
将数据集准备好图片放在yolov4-pytorch-master\VOCdevkit\VOC2007\JPEGImages中
用labelimg打的标签放在yolov4-pytorch-master\VOCdevkit\VOC2007\Annotations中
在yolov4-pytorch-master\model_data添加自己的识别类
更改路径
运行voc_annotation.py得到如图文件

去train.py中修改classes_path(我这边是fruit_classes.txt)
classes_path = 'model_data/fruit_classes.txt'
运行train.py得到模型
修改yolo.py中的路径
model_path路径改成训练的模型路径
classes_path路径和前面改的路径相同
如果预测图片没出现框框就降低置信度(confidence)
.使用predict.py进行预测
输入图片路径
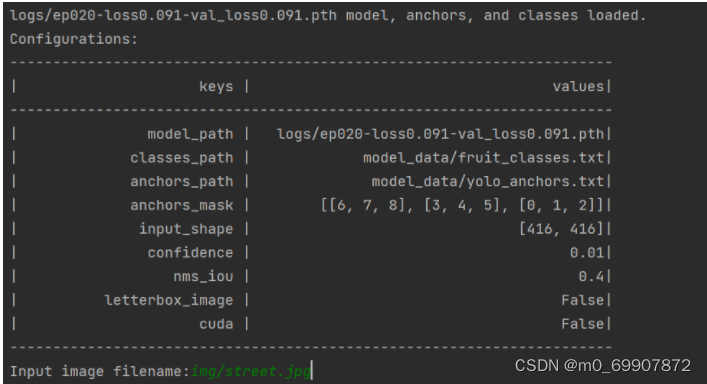
得到效果图

YOLOv4是一个高效且准确的目标检测模型,但它的训练过程需要一定的技巧和经验。在我使用YOLOv4进行训练的过程中,我学到了几个重要的经验教训:
1. 数据准备:数据的质量对模型的性能至关重要。确保训练集包含多样化的样本,并且标签准确无误。此外,对数据进行增强可以帮助提高模型的泛化能力。
2. 参数调整:YOLOv4有许多超参数需要调整,如学习率、批量大小、迭代次数等。通过反复尝试不同的参数组合,可以找到最优的训练配置。
3. 模型调优:除了训练参数外,模型的架构也可以进行调整以提高性能。尝试修改网络结构、添加额外的层或模块,可以使模型更适应特定的任务和数据集。
4. 硬件选择:YOLOv4的训练需要大量的计算资源,因此选择合适的硬件对训练效率至关重要。GPU是训练YOLOv4的最佳选择,而且要确保GPU内存足够大以容纳模型和数据。
5. 持续优化:训练模型并不是一次性的任务,持续监控模型性能并进行优化是必要的。通过定期评估模型在验证集上的表现,并进行调整和重新训练,可以不断提升模型的性能。















 488
488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









