







【版权声明】未经博主同意,谢绝转载!(请尊重原创,博主保留追究权)
https://blog.csdn.net/m0_69908381/article/details/131040299
出自【进步*于辰的博客】
1、知识点扩展
2、伪列
2.1 rownum
参考笔记一,P18.3/4、P19.5。
2.1.1 介绍
rownum是虚拟字段,不真实存储,在返回结果集时生成,宏观作用类似序号。在每次查询时,从1开始给结果集编号。常与<、<=连用。
在与>、>=连用时,由于rownum是在查询记录时逐个生成,并迭代。因此,若rownum的判断在第1行记录时就不满足,则无法返回记录,即未迭代,rownum始终为1,最终结果集中无任何记录,与between...and...连用时同理。
注意
\color{red}{注意}
注意:所有SQL语句的执行顺序都是:from → where → group by → having → select → order by。
由于rownum是伴随select生成,故与order by连用时,会导致rownum混乱。因此,通常是多层嵌套,先进行排序,再使用rownum进行筛选。(见示例)
扩展
\color{green}{扩展}
扩展:在Oracle中,常言的top-n查询其实是在rownum编号后,使用rownum进行判断,从而获取前n条记录的查询方法。(见示例)
2.1.2 示例
数据表:emp(no, ..., sal)。
需求:查询工资6 ~ 10名的员工的所有信息。
写法一:
select e2.*
from (select e1.*, rownum rn
from (select * from emp order by sal desc) e1) e2
where rn between 6 and 10
前2层仅对结果集进行一次排序,不做筛选,在第3层时,才进行筛选。rn是rownum的别名,由于rn属于第2层的结果集,非rownum,故已固定,因此可以直接使用rn between 6 and 10筛选出第6 ~ 10名。
写法二。
select e2.*
from (select e1.*, rownum rn
from (select * from emp order by sal desc) e1
where rownum <= 10) e2
where rn > 5
在第2层时就进行结果集筛选,rownum初始为1,满足rownum <= 10,则返回记录,同时rownum迭代,如此反复直到条件不满足,这样就查询出前10条记录(工资最高的前10名员工)。此时rownum固定,别名是rn,第3层可以直接使用rn筛选出第6 ~ 10名。
补充说明:
\color{red}{补充说明:}
补充说明:
两种写法在第1层时,都得到根据工资降序排序后的所有员工信息。
写法二较写法一,效率高很多。
因为写法一是在第3层才进行结果集筛选,由于条件是rn between 6 and 10,使用的是rn,rn属于结果集,已固定。因此在筛选时,会遍历根据工资降序排序后的所有员工信息。
而写法二,在第2层时,是通过rownum <= 10进行筛选,由于rownum的生成机制,第2层仅遍历前10条记录(工资最高的前10名员工)。因此,第3层仅遍历10条员工信息。
2.2 nextval、currval
参考笔记一,P23.18。
2.2.1 序列
这两个伪列皆基于 序列 \color{green}{序列} 序列,我暂未对序列的相关理论进行整理,大家可以查阅这篇博文《Oracle数据库序列》(转发)。
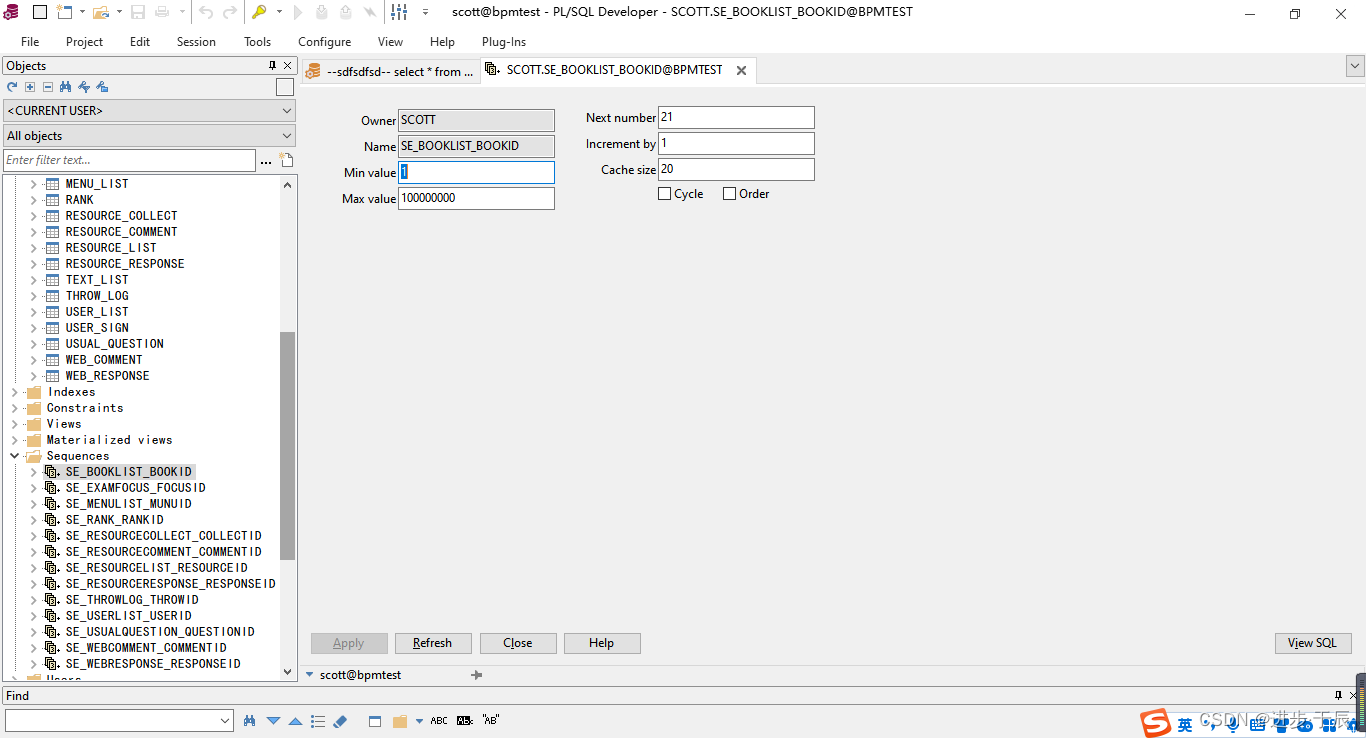
“序列”是一种按照一定规则自动增加或减少数字的数据库对象,主要用于主键(新增时填充主键)。创建示例:
create sequence swq_emp_empId
increment by 1
start with 1000
nocycle
cache 20
seq_emp是序列名;increment是递增值,默认值为1;start是初始值;nocycle表示不循环;cache 20表示进行缓存,缓存大小为20。
大家也可以使用图形化界面操作:
2.2.2 概述
nextval是序列的下一个值,currval是序列的当前值。
使用位置:
select子句中,不包括子查询的select子句;- insert 语句的
select子句或values子句中; - update 语句的
set子句中。
不能使用位置:
- 包含
distinct、group by、having或order by的视图SQL语句的select子句中; - select、update、delete的子查询中;
- 包含
default的create table、alter table语句中。
操作,
--修改序列--
alter sequence 序列名 ...;// 后面格式与创建语句相同
// 注:后面语句中没有start with,并且修改的值不能少于当前值
2.2.3 示例
insert into emps values(swq_emp_empId.nextval, '张三', 7500.00, 10);
update emps
set sal = 10000.00
where emp_id = swq_emp_empId.currval;
必须先获取nextval,才能使用currval。
4、约束
参考笔记一,P22.18~22。
4.1 介绍
“约束”是一种对数据表字段存储数据的限制,分为主键(primary key)、唯一键(unique)、外键(foreign key)、check约束、not null约束。
操作命令:
--添加约束--
alter table 表名 add constraint 约束名 约束类型(字段);
--删除约束--
alter table 表名 drop constraint 约束名;
--启用/禁用约束--
alter table 表名 enable/disable constraint 约束名;
数据字典:
--当前用户旗下所有数据表的所有约束--
user_constraints
--当前用户旗下所有数据表的所有约束所属的字段名--
user_cons_columns
4.2 外键约束
外键会将两个数据表进行关联(子表字段数据来源主表,注:子表相应字段可为 null),进而对子表相应字段的数据进行限制。
创建命令:
alter table 子表 add constraint 外键名 foreign key(字段1) references 主表(字段2);
这里就有个问题:若主表记录被删除,那么子表中相应数据该何去何从?
可在上述命令后增加一条子句,可以决定这些数据的去向,4种定义:
on delete cascade:表示子表中相应数据将连同删除;on delete set null:表示子表中相应数据将被置空(null);Restrict:表示若子表中存在相应数据,则提示主表记录不能删除;on delete no action:表示子表不受影响。
这种机制也称为“级联删除”。必然的,另一种是“级联更新”,即on update,其取值也是以上4种。
4.3 check 约束
此约束用于限制数据范围,其内不允许使用伪列,如:rownum。
创建命令:
alter table 表名 add constraint 约束名 check(条件);
示例:(注:创建命令是固定的,故示例中仅展示“条件”部分)
# 限制取值
sex in (0, 1)
# 限制范围
1、age > 0 and age < 120
2、age between 0 and 120
# 这样仅能用于限制整数,如“工资”此类的小数无法如此添加限制
# 限制模式
regexp_like(phone, '192\d{8}'); // 中国广电手机号
regexp_like(email, '\w+@[\w&&[^_]]+\.com'); // 邮箱
regexp_like(id_card, '^[1-9]\d{5}(18|19|([23]\d))\d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)\d{3}[0-9Xx]$'); // 十八位身份证号
# 条件中可以使用函数,如sysdate、uid()、user()、userenv()
关于regexp_like(),见下文【正则表达式相关函数】。
4.4 not null 约束
添加约束命令:
alter table 表名 modify(字段 constraint 约束名 not null)
因为not null约束仅能定义于字段,即列约束,故不能使用...add constraint...命令添加。
5、数据类型
5.1 char族
Oracle中char族数据类型与MySQL中相同,大家可查阅博文《MySQL知识点锦集》的第3项,在此不作赘述。
5.2 number(a, b)
参考笔记一,P20.13。
此数据类型为数字,可存储小数。其中,a 是数字位数(包括小数),b 是精确小数位数。
规则:
- 若
b > 0,表示精确b位小数,并四舍五入; - 若
b < 0,表示精确到小数点左b位,并四舍五入,故只能存储整数。如:number(5, 3),可存储五位数整数,个位和十位都为0; - 若
b = 0,则只能存储整数; - 若
a < b,则只能存储-1 ~ 0或0 ~ 1的小数,且小数点右b - a位及其后都必须是0(前后四舍五入都要满足),即精确b位小数。
6、内置函数
注:字符串前有一个' '(空字符),故首字母的位置是1,不是0(下文“开始位置”)。
6.1 单行函数
参考笔记一,P15.3、P39.1。
| 摘要 | 参数说明 | 返回值类型/返回值 | 说明 |
|---|---|---|---|
substr(str, pos[, len]) | pos-开始位置,可为负值 | 截取。截取方向始终向右 | |
round(a, b) | b-精确位数 | 四舍五入。若b < 0,则向左精确,故round(a)等价于round(a, 0) | |
upper(str) | 转大写 | ||
lower(str) | 转小写 | ||
initcap(str) | 首字母大写 | ||
length(str) | 返回长度 | ||
concat(a, b) | 拼接,类似|| | ||
trunc(a, b) | b-精确位数 | 数值取整(以10为整) | |
sysdate | 获取系统时间 | ||
instr(str1, str2[, pos][, n]) | str2-查找字符,pos-开始位置,n-第几个 | 位置 | 查找,找不到返回0。其中,instr(str1, str2)等价于instr(str1, str2, 1, 1) |
lpad/rpad(str1, len, str2) | 左 / 右填充。表示将str1用str2向左 / 向右填充成长度为len的字符串 | ||
replace(str1, str2, str3) | 替换。表示将str1中的str2用str3替换 | ||
trim(str) | 去除前后空格 | ||
trim(leading/trailing/both/无 a from b) | 去除 b 中开头 / 结尾 / 开头和结尾 / 开头以及结尾的 a | ||
mod(a, b) | 等同于a%b,余数符号跟 a |
6.1.1 lpad/rpad(str1, n, str2)
示例。
select lpad(rpad('csdn', 7, '#'), 10, '*') result from dual
结果:

若n < s1.length,则无论lpad/rpad(),结果都只显示s1的前n个字符(从左往右)。
6.1.2 instr(str1, str2[, pos][, n])
示例。
select instr(s1, s2, -2, 3) from dual;
表示在str1中,从倒数第2个开始,向左查找第3个str2的位置。注:无论a的正负,返回的都是绝对位置。
6.2 非空判断函数
参考笔记一,P18.1。
| 摘要 | 参数说明 | 返回值类型 / 返回值 | 说明 |
|---|---|---|---|
nvl(a, b) | 若a为null,返回 b,否则返回 a | ||
nvl2(a, b, c) | 若a不为null,返回 b,否则返回 c | ||
nullif(a, b) | 比较 a、b,若a = b,返回null,否则返回 a | ||
case xx when w1 then c1 when w2 then c2 else c3 end | 若xx = w1或w1为true,返回 c1;若xx = w2或w2为true,返回 c2;否则返回 c3 | ||
decode(xx, w1, c1, w2, c2, c3) | 作用同case() |
6.3 日期函数
参考笔记一,P15.5。
| 摘要 | 参数说明 | 返回值类型 / 返回值 | 说明 |
|---|---|---|---|
months_between(d1, d2) | 返回d1与d2相差的自然月数 | ||
add_months(d, n) | 增加月数 | ||
next_day(d, '星期一') | 返回 d 后的第1个星期一 | ||
last_day(d) | 返回 d 当月的最后1天 | ||
round(d, 'dd') | 以day四舍五入。'dd'是格式码,其他格式码:'CC'→ 世纪,'YY'→ 年,'mm'→ 月,'hh24'→ 小时,'mi'→ 分钟,'ss'→ 秒。其中,round(d, 'dd')等价于round(d) | ||
trunc(d, 'dd') | 同round()。trunc(d, 'dd')等价于trunc(d) | ||
extract(day from d) | 获取 d 的天数。day是标识符,表示“天”。其他标识符:'year'→ 年,'month'→ 月, |
6.4 正则表达式相关函数
参考笔记三,P55.1。
| 摘要 | 参数说明 | 返回值类型 / 返回值 | 说明 |
|---|---|---|---|
regexp_like(a, pattern) | boolean | 类似like,判断是否包含匹配模式pattern的字符串,故仅能用于进行判断的位置,如:where、check() | |
regexp_substr(a, pattern, pos, n) | n-第几个 | 类似substr() | |
regexp_instr(a, pattern, pos, n) | 位置 | 类似instr() | |
regexp_count(a, pattern) | 统计匹配模式的字符串个数 | ||
regexp_replace(a, pattern, str3) | str3-用于替换的字符串 | 类似replace() |
注:
- 一般将正则表达式称为“模式”。
- 以下函数的参数列表是“必须”部分,考虑到实用性,一些可选参数未列举出。如果大家有兴趣,需另行查找。
- 以下“模式”函数与相应单行函数功能相同,可参照上文【单行函数】学习。
- 出于篇幅考虑,以下函数的示例数据来源于下文【视图-示例】,不便之处请谅解。
- 如果大家不了解“模式”,可查阅博文《正则表达式全解析+常用示例》(转发);若要深入了解,可查阅Pattern类中的【正则表达式的构造摘要】。
6.4.1 regexp_like(a, pattern)
示例:
select * from v where regexp_like(data, '#');
结果:

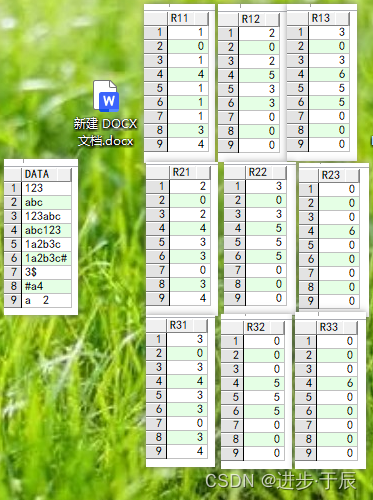
6.4.2 regexp_substr(a, pattern, pos, n)
示例:
select regexp_substr(data,'\d',1,1) as r11 from v;
select regexp_substr(data,'\d',1,2) as r12 from v;
select regexp_substr(data,'\d',1,3) as r13 from v;
select regexp_substr(data,'\d',2,1) as r21 from v;
select regexp_substr(data,'\d',2,2) as r22 from v;
select regexp_substr(data,'\d',2,3) as r23 from v;
select regexp_substr(data,'\d',3,1) as r31 from v;
select regexp_substr(data,'\d',3,2) as r32 from v;
select regexp_substr(data,'\d',3,3) as r33 from v;
结果:

6.4.3 regexp_instr(a, pattern, pos, n)
示例:
select regexp_instr(data,'\d',1,1) as r11 from v;
select regexp_instr(data,'\d',1,2) as r12 from v;
select regexp_instr(data,'\d',1,3) as r13 from v;
select regexp_instr(data,'\d',2,1) as r21 from v;
select regexp_instr(data,'\d',2,2) as r22 from v;
select regexp_instr(data,'\d',2,3) as r23 from v;
select regexp_instr(data,'\d',3,1) as r31 from v;
select regexp_instr(data,'\d',3,2) as r32 from v;
select regexp_instr(data,'\d',3,3) as r33 from v;
结果:
6.4.4 regexp_count(a, pattern)
示例:
select regexp_count(data, '\d') as count from v;
结果:

6.4.5 regexp_replace(a, pattern, str3)
示例:
select regexp_replace(data, '\d','?') as result from v;
结果:

7、视图(view)
推荐一篇博文《Oracle视图详解》(转发)。
参考笔记一,P22.24、P23.15~17。
7.1 介绍
view可认为是一种绑定了SQL语句的原表“副本”,故当查询视图时,都会重新执行一次SQL语句查询原表,且修改视图记录等同于修改原表记录。
不过,若视图记录是由原表记录经处理后生成,即SQL语句中包含“数据处理”子句或条件时,不允许变动视图记录。“数据处理”子句或条件有:
group函数;- group by;
- distinct;
- 使用表达式定义的字段;
- 伪列
rownum; - 原表在视图中未选择(未
select)的字段的所有数据为非空且无默认值。
当然,并非只要SQL语句中包含了这6种子句或条件,就无法对视图进行全部DML。规则如下:
- 删除视图记录。要求SQL语句中不能包含前3个子句或条件。
- 修改视图记录。要求SQL语句中不能包含前5个子句或条件。
- 新增视图记录。要求SQL语句中不能包含所有子句或条件。
我们也可以干脆在SQL语句末添加with read only子句禁用视图DML。
7.2 数据字典
--当前用户旗下所有视图--
user_views
--显示视图中哪些字段允许DML--
user_updatable_columns
7.3 一个问题
假若SQL语句是:
create view v_emp_1(id, name, sal)
as
select emp_id, emp_name, sal
from emps
where dept_no = 10;
这里dept_no是外键,该视图记录为员工表中隶属部门10的所有员工信息。
现在,我把10改成20。前言道,查询视图是对原表的再次查询,这样修改后,该视图记录就变为部门20的所有员工信息。可是,view是原表的“副本”,既然创建视图时部门编号为10,说明当时我设定该视图的作用是用于快速查询部门10的所有员工信息,那么又怎能允许后续随意修改查询条件(dept_no = 10)。
因此,可以在SQL语句末添加with check option constraint 约束名子句,设置一个约束限制这种修改。
7.4 示例
创建:
create or replace view v as
select '123' as data from dual union all
select 'abc' from dual union all
select '123abc' from dual union all
select 'abc123' from dual union all
select '1a2b3c' from dual union all
select '1a2b3c#' from dual union all
select '3$' from dual union all
select '#a4' from dual union all
select 'a 2 ' from dual ;
数据:

最后
本文中的例子是为了方便大家理解、以及阐述相关知识点而简单举出的,不一定有实用性,仅是抛砖引玉,
本文持续更新中。。。

















 4232
4232











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











