






k个action选择,对应k个reward分布或者value分布,初始并不知道哪个哪个value高,但可以有estimated value。由此你至少能够选择在当前情况下estimated value最大的action(greedy action),这时我们说你在exploit现有的知识,相反,如果你选择了另外的动作,我们说你在explore。如何平衡exploit和explore是强化学习的独特挑战。
ε-greedy methods:大部分时间内贪婪地选择动作,ε的小概率时间独立于动作值分布随机选择动作。优点让每个动作都采样无数次,从而确保所有Q收敛到q。
采用增量式更新估值,减少复杂度:
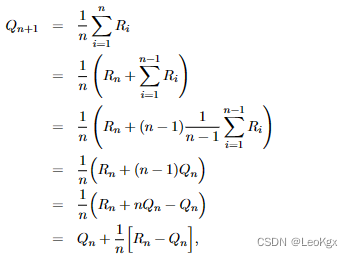
由此得到:
















 2255
2255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









