







作者前言
🎂 ✨✨✨✨✨✨🍧🍧🍧🍧🍧🍧🍧🎂
🎂 作者介绍: 🎂🎂
🎂 🎉🎉🎉🎉🎉🎉🎉 🎂
🎂作者id:老秦包你会, 🎂
简单介绍:🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂
喜欢学习C语言和python等编程语言,是一位爱分享的博主,有兴趣的小可爱可以来互讨 🎂🎂🎂🎂🎂🎂🎂🎂
🎂个人主页::小小页面🎂
🎂gitee页面:秦大大🎂
🎂🎂🎂🎂🎂🎂🎂🎂
🎂 一个爱分享的小博主 欢迎小可爱们前来借鉴🎂
字符函数和字符串函数的介绍和模拟
本章前言
C语言中对字符和字符串的处理很是频繁,但是C语言本身是没有字符串类型的,字符串通常放在
常量字符串 中或者 字符数组 中。
字符串常量 适用于那些对它不做修改的字符串函数.
函数介绍
在学习函数我们会见到很多陌生的函数,怎么去认识这些函数我推荐一个网站C语言函数,废话少说,开始正题
strlen
在前面中我们已经使用过这个函数,知道这个函数的作用是计算字符串的长度,计算的是‘\0’前面的长度,不包括’\0’
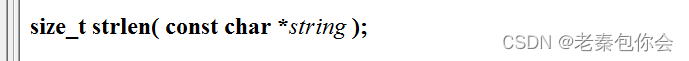
参数是字符串起始的地址,也就是要从哪里开始计算字符长度的地址,返回的类型是无符号整形
#include<stdio.h>
#include<string.h>
int main()
{
char arr[] = "abcd";
char arr1[] = { 'a','b','c','d' };//这里没有'\0';
printf("%d\n", strlen(arr));
printf("%d\n", strlen(arr1));
printf("%d\n", strlen("abcd"));
return 0;
}
其实我们还可以计算字符串常量的长度 strlen(“abcd”);传入的是a的地址
如果我们来分析一下对应的返回类型就会有另一个知识点
#include<stdio.h>
#include<string.h>
int main()
{
if (strlen("abc") - strlen("abcdef") > 0)
{
printf("大于");
}
else
{
printf("小于");
}
return 0;
}

如果看过前面我写过的博客就会明白,无符号数的在内存的存储 ,所有都是有效位,连符号符号位也计算进去了 ,范围是0~4,294,967,295 ,上面虽然我们通过数学方法计算得到-3,但是却是无符号数,在内存的存储是
1111 1111 1111 1111 1111 1111 1111 1101
最终计算出来的是一个很大的数.
或者我们可以把-3强转成int类型,就会是真正的-3了
如果我们要模拟实现有三种方法
方法1:递归
#include<stdio.h>
size_t my_strlen(char* arr)
{
if (!*arr)
{
return 0;
}
return 1 + my_strlen(arr + 1);
}
int main()
{
char arr[] = "abcdwe";
size_t a = my_strlen(arr);
return 0;
}
方法2:计数
#include<stdio.h>
int main()
{
char arr[] = "aaaaaaaaa";
int a = 0;
char* p = arr;
while (*p++)
{
a++;
}
return 0;
}
方法三:首元素的地址减去’\0’的地址
#include<stdio.h>
int main()
{
char arr[] = "aaaaaaaaa";
char* p = arr;
while (*p++)
{
;
}
printf("%d", p - arr - 1);
return 0;
}
strcpy
字符串拷贝
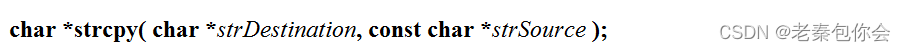
返回类型是char* ,返回strDestination,我们可以认为这是一个初始地址, 参数有两个,一个是目的地址,一个源头地址,strSource是被拷贝的起始地址,strDestination是粘贴到的起始地址
trcpy函数将strSource(包括终止的null字符)复制到strDestination指定的位置。复制或附加字符串时不执行溢出检查。如果源字符串和目标字符串重叠,则strcpy的行为是未定义的。
会把’\0’也会拷贝过去的,
#include<stdio.h>
#include<string.h>
int main()
{
char arr[10] = "xxxxxxxxx";
strcpy(arr, "aaaa");
return 0;
}
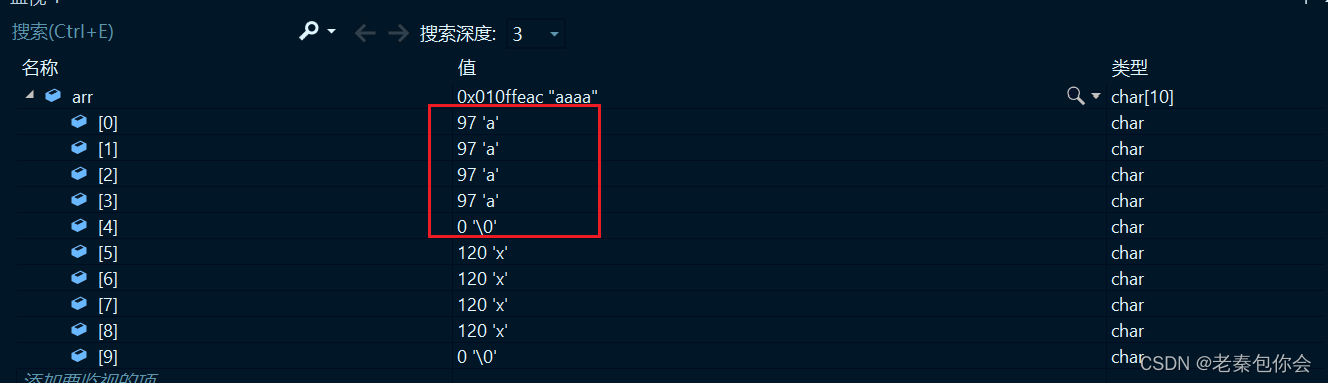
注意事项:
- 源字符串必须以 ‘\0’ 结束。
拷贝结束是要遇到源头的结束标志,如果源头没有结束标志,就会继续拷贝直到遇到结束标志
#include<string.h>
int main()
{
char arr[] = { 'a','b','c','d' };
char arr1[] = "xxxxxxxx";
strcpy(arr1, arr);
return 0;
}
运行这段代码就会发现程序会崩溃,原因是没有遇见’\0’会一直拷贝,直到拷贝的个数超过了arr1数组的长度,越界访问,程序崩溃,
2… 会将源字符串中的 ‘\0’ 拷贝到目标空间。
3. 目标空间必须足够大,以确保能存放源字符串。
#include<stdio.h>
#include<string.h>
int main()
{
char arr[2] = "a";
char arr1[5] = "asbd";
strcpy(arr, arr1);
return 0;
}
这里的情况和上面的情况是一样的,会越界访问,程序崩溃,这里是主要是拷贝的长度太长
- 目标空间必须可变。
- 学会模拟实现。
#include<stdio.h>
#include<string.h>
#include<assert.h>
char* my_strcpy(char* arr, const char* arr1)
{
assert(arr && arr1);
char* p = arr;
char* p1 = arr1;
while (*p++ = *p1++)
{
;
}
return arr;
}
int main()
{
char arr[] = "abcdhghgfg";
char arr1[] = "xxx";
my_strcpy(arr, arr1);
return 0;
}
strcat
字符串追加
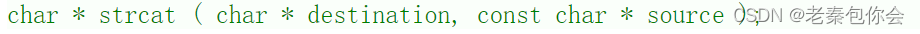
这里的参数和strcpy的参数是一样的,有目标地址和源头地址
将源字符串的副本追加到目标字符串。目的地中的终止空字符被源的第一个字符覆盖,并且空字符被包括在由目的地中两者的串联形成的新字符串的末尾。
简单的理解就是源字符串的第一个字符会覆盖目标字符串的’\0’,然后往后添加字符,这里也会把源字符串的’\0’追加过来
#include<stdio.h>
#include<string.h>
int main()
{
char arr[] = "asfd";
char arr1[20] = "abcde";
strcat(arr1, arr);
return 0;
}
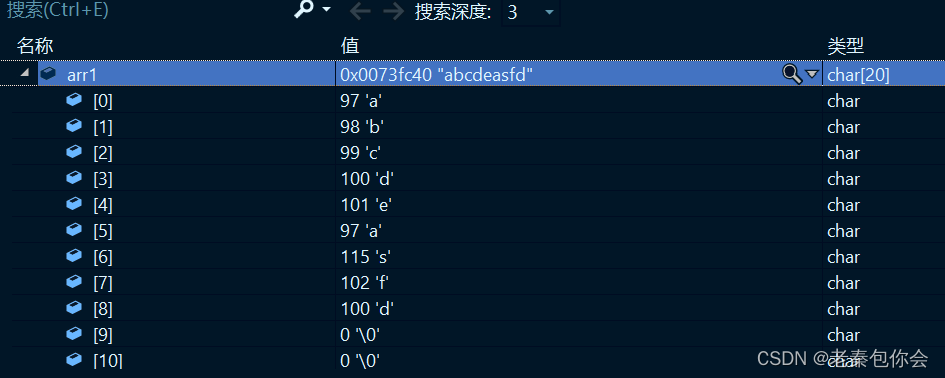
可以看到arr1的e后面原来是有结束标志的,因为字符串追加,会覆盖,
所以会有一些注意事项:
1.目标空间要足够大.可修改
#include<stdio.h>
#include<string.h>
#include<assert.h>
int main()
{
char arr[] = "asfd";
char arr1[20] = "abcde";
strcat(arr, arr1);
return 0;
}
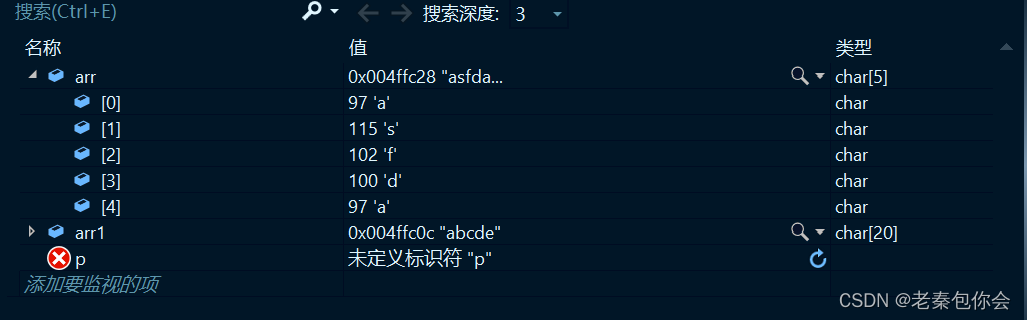
当我们运行出来就会发现当追加的字符串长度大于目标空间,就会追加就会发生越界访问,程序会崩溃
2. 目标字符串必须要有’\0’,源字符串也必须有’\0’
因为strcat追加是从目标字符串的’\0’开始追加的,如果没有就会无法追加,
如果源字符串没有’\0’就会一直追加
#include<stdio.h>
#include<string.h>
#include<assert.h>
int main()
{
char arr[] = { 'a','b' };
char arr1[10] = "qqq";
strcat(arr1, arr);
return 0;
}
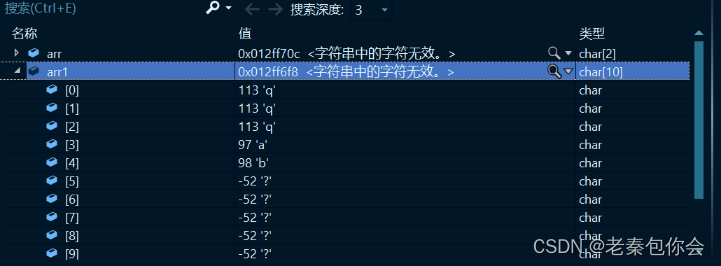
这里还是会发生越界访问,程序会崩溃
模拟实现
#include<stdio.h>
#include<string.h>
#include<assert.h>
char* my_strcat(char* arr1, const char* arr)
{
assert(arr1 && arr);
char *p = arr;
char* p1 = arr1;
int sz = strlen(arr1);
//找到目标的结束标志
p1 = p1 + sz;
//数据追加
while (*p1 = *p)
{
p1++;
p++;
}
return arr1;
}
int main()
{
char arr[] = "abc";
char arr1[10] = "xx\0x111";
my_strcat(arr1, arr);
return 0;
}
需要注意的是如果目标字符串的’\0’后面还有字符,会直接覆盖上去的,不会扩大字符长度,
到这里可能有些小可爱会像让字符串自己给自己追加,结果发现我们模拟出来的函数程序崩溃了
下面为例:

这里是长度位20的数组,数组里面有四个元素,我们追加是通过访问内存来获取对应的值,然后覆盖上去,当我们把‘\0’覆盖了,当源字符地址找到对应的内存,但是却不是\0’而是字符a, 下一个字符是b,如此往下,没有结束标记,一直追加,最终会发生越界访问,程序崩了
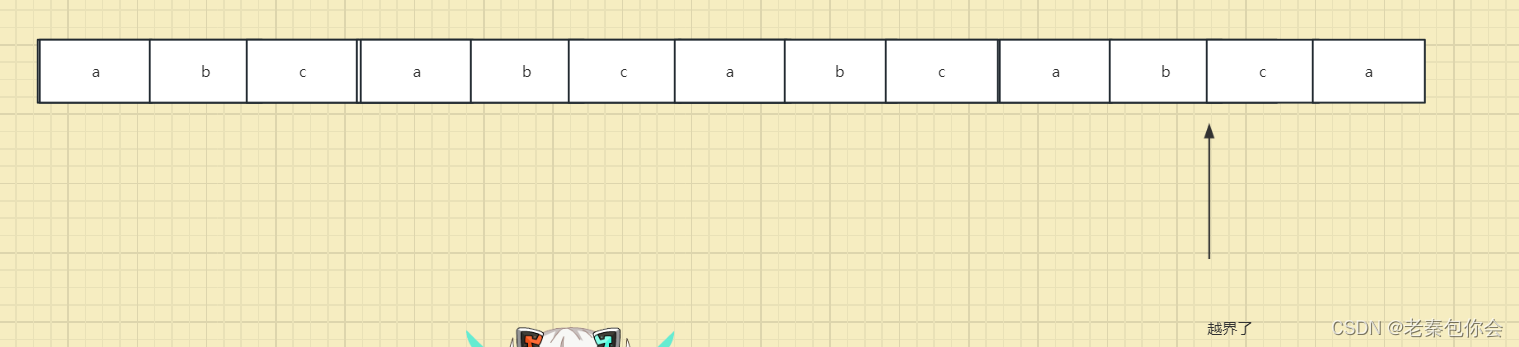
但是使用库函数strcat却可以,但是我们是不建议的,
strcmp
比较字符串的大小

将C字符串str1与C字符串str2进行比较。
此函数开始比较每个字符串的第一个字符。如果它们彼此相等,则继续使用以下对,直到字符不同或达到终止的null字符。
简单的说如果str1大于str2 返回大于0的数,如果小于就返回小于0的数,等于就返回0
这个函数的比较不是比较长度,而是比较对应位置上的字符ACSII值,
#include<stdio.h>
#include<string.h>
int main()
{
char arr[] = "abdcd";
char arr1[] = "abbb";
int a = strcmp(arr, arr1);
printf("%d", a);
return 0;
}

在一些编译器返回的值不一样,这个要看情况,vs 编译器返回的是-1 0 1 这三个
那我们来模拟一下这个函数
#include<stdio.h>
#include<string.h>
#include<assert.h>
int my_strcmp(const char* arr, const char* arr1)
{
assert(arr && arr1);
char* p = arr;
char* p1 = arr1;
while (*p == *p1)
{
if (!*p)
return 0;
p++;
p1++;
}
if (*p > *p1)
return 1;
else
return -1;
}
int main()
{
char arr[] = "abcd";
char arr1[] = "abcd";
int a = my_strcmp(arr, arr1);
printf("%d", a);
return 0;
}
strncpy
前面我们使用了strcpy,很方便但是我们想没想过,如果我只需要拷贝一对字符串的某一部分,结果就会很吃力,为例解决这个问题,这个函数就出来了

可以看出这个函数和strcpy的差别在于参数多了一个num
将源的第一个字符数复制到目标。如果在复制 num 个字符之前找到源 C 字符串的末尾(由 null 字符表示),则目标将填充零,直到总共写入 num 个字符为止。
如果源长度超过 num,则不会在目标末尾隐式附加空字符。因此,在这种情况下,不应将目标视为以空结尾的 C 字符串(这样读取它会溢出)。
#include<stdio.h>
#include<string.h>
#include<assert.h>
int main()
{
char arr[5] = "XXXX";
char arr1[] = "aAA";
strncpy(arr, arr1, 3);
return 0;
}
#include<stdio.h>
#include<string.h>
#include<assert.h>
int main()
{
char arr[10] = "XXXXXXXXX";
char arr1[] = "aAA";
strncpy(arr, arr1, 6);
return 0;
}
这里的注意事项和strcpy是一样的,
目标空间要足够大,且能修改
如果拷贝的长度小于源字符串,不会拷贝\0, 如果拷贝的长度大于源字符串,不够的就用’\0’补上
可以看出这个函数比较好用,适合才是最好的
我们来模拟实现一下
#include<stdio.h>
#include<string.h>
#include<assert.h>
char* my_strncpy(char* arr1, const char* arr, size_t num)
{
const char* p = arr;
char* p1 = arr1;
size_t i = 0;
for (i = 0; i < num ; i++)
{
*(p1) = *(p);
if (!*p)
break;
p1++;
p++;
}
size_t j = 0;
for (j = 0; j < num - i; j++)
{
*(p1) = '\0';
p1++;
}
return arr1;
}
int main()
{
char arr[] = "abcd";
char arr1[20] = "xxxxxxxxxxxx";
my_strncpy(arr1, arr, 10);
return 0;
}
strncat

这里的字符串追加相对于strcat的参数是多了一个参数num
从字符串追加字符
将源的第一个数字字符追加到目标,外加一个终止空字符。
如果源中 C 字符串的长度小于 num,则仅复制终止空字符之前的内容。
int main()
{
char arr[10] = "abcd\0sdss";
char arr1[] = "111";
strncat(arr, arr1, 2);
return 0;
}
这里的注意事项:
目标空间要足够大
如果追加的长度小于源字符串,则不会拷贝’\0’,如果长度大于源字符串的长度,则按原字符串长度来拷贝,不会去补上字符
我们来模拟这个函数
#include<stdio.h>
#include<string.h>
#include<assert.h>
char* my_strncat(char* arr, const char* arr1, size_t num)
{
char* p = arr;
char* p1 = arr1;
while (*p)
{
p++;
}
size_t i = 0;
for (i = 0; i < num; i++)
{
*p = *p1;
if (!*p1)
break;
p++;
p1++;
}
return arr;
}
int main()
{
char arr[22] = "xxx";
char arr1[] = "222";
my_strncat(arr, arr1, 5);
return 0;
}
strencmp
字符串比较

将 C 字符串 str1 的字符数与 C 字符串 str2 的字符数进行比较。
此函数开始比较每个字符串的第一个字符。如果它们彼此相等,则继续使用以下对,直到字符不同,直到达到终止的空字符,或者直到两个字符串中的 num 字符匹配,以先发生者为准。
#include<stdio.h>
#include<string.h>
#include<assert.h>
int main()
{
char arr[] = "abcde";
char arr1[] = "abcde";
int a = strncmp(arr, arr1, 10);
printf("%d", a);
return 0;
}
这里我们来模拟一下
#include<stdio.h>
#include<string.h>
#include<assert.h>
int my_strncmp(char* arr, char* arr1, size_t num)
{
char* p = arr;
char* p1 = arr1;
size_t i = 0;
for (i = 0; i < num; i++)
{
if (*p != *p1)
{
break;
}
if (!*p)
return 0;
p++;
p1++;
}
return *p - *p1;
}
int main()
{
char arr[] = "safdf";
char arr1[] = "srffg";
int a = my_strncmp(arr, arr1, 4);
printf("%d", a);
return 0;
}
strstr
字符串中找字符串

这个函数有两个参数,第一个函数是C语言的,第二个函数是c++的,函数的意思就是在str1中找出str2第一次出现的位置
查找子字符串
返回指向 str2 中第一次出现的 str1 的指针,如果 str2 不是 str1 的一部分,则返回一个空指针。
匹配过程不包括终止空字符,但它到此为止。
#include<stdio.h>
#include<string.h>
#include<assert.h>
int main()
{
char arr[] = "safdf";
char arr1[] = "ad";
char *ret = strstr(arr, arr1);
if (!ret)
{
printf("NO");
}
else
{
printf(ret);
}
return 0;
}
可以看出这里的大概使用情况,当在str1中找到str2就会返回找到的那个位置的地址
那我们来模拟实现一下
#include<stdio.h>
#include<string.h>
#include<assert.h>
const char* my_strstr(const char* arr, const char* arr1)
{
assert(arr && arr1);
const char* p = arr;
const char* p1 = arr1;
const char* start = arr;
while (*start)
{
p = start;
p1 = arr1;
while (*p == *p1 && *p1 && *p)
{
p++;
p1++;
}
if (!*p1)
return start;
start++;
}
return NULL;
}
int main()
{
char arr[] = "ddddfa";
char arr1[] = "a";
const char *ret = my_strstr(arr, arr1);
if (!ret)
{
printf("NO");
}
else
{
printf(ret);
}
return 0;
}
strtok

这个函数是用来切割字符串的
就拿我们的邮箱来说123456789@163.com
或者我们的IP地址 192.168.101.12 (点分十进制)本来是一个无符号的整数,这种整数不方便记忆,所以将在这个整数转换成点分10进制的表示形式
废话少说,我们回归正题,如果我们要把 . 分开
str就是这个字符串,而delimiters就是分割字符串(分割字符组成的集合)
delimiters参数是个字符串,定义了用作分隔符的字符集合
第一个参数指定一个字符串,它包含了0个或者多个由delimiters字符串中一个或者多个分隔符分割的标记。
strtok函数找到str中的下一个标记,并将其用 \0 结尾,返回一个指向这个标记的指针。(注:strtok函数会改变被操作的字符串,所以在使用strtok函数切分的字符串一般都是临时拷贝的内容并且可修改。)
strtok函数的第一个参数不为 NULL ,函数将找到str中第一个标记,strtok函数将保存它在字符串中的位置。
strtok函数的第一个参数为 NULL ,函数将在同一个字符串中被保存的位置开始,查找下一个标记。
如果字符串中不存在更多的标记,则返回 NULL 指针。
简单的理解就是strtok函数会在str字符串中找到第一个匹配到的字符(delimiters中的任意一个)更改为’\0’,并返回起始位置,
#include<stdio.h>
#include<string.h>
#include<assert.h>
int main()
{
char arr[] = "192.168.45.123";
/*printf(strtok(arr, ".9"));
printf("\n");
printf(strtok(NULL, "."));
printf("\n");
printf(strtok(NULL, "."));
printf("\n");
printf(strtok(NULL, "."));
if (!strtok(NULL, "."))
{
printf("\n");
printf("空了");
}*/
char* a;
for (a = strtok(arr, "."); a != NULL; a = strtok(NULL, "."))
{
printf(a);
printf("\n");
}
return 0;
}
那我们来模拟一下
#include<stdio.h>
#include<string.h>
#include<assert.h>
char* my_strtok(char* arr, char* arr1)
{
static char* a = NULL;
//判断arr是否为NULL
if (arr)
a = arr;
//切割
char* pos = a;
while (a && * a)
{
char *pos1 = arr1;
while (*a != *pos1 && *pos1 )
{
pos1++;
}
if (*a == *pos1)
{
*a = '\0';
a++;
return pos;
}
a++;
}
a = NULL;
return pos;
}
int main()
{
char arr[] = "192.a168.45.123";
char arr1[] = "a.";
for (char *a = my_strtok(arr, ".a"); a != NULL; a = my_strtok(NULL, "0"))
{
printf("%s", a);
printf("\n");
}
return 0;
}
这个是我模拟出来出来的,如果有啥要更正的可以评论
strerror

返回错误码对应的错误信息
在我们编译过程中一定会有错误,我们在vs编译器可以看到,但是如果是一些错误我们想知道是,该如何查看,那我们可以使用这个strerror函数来解读
C语言中使用库函数的时候,如果发生错误,就会将错误码放在errno的变量中,errno是一个全局变量,可以直接使用
#include<stdio.h>
#include<string.h>
#include<assert.h>
int main()
{
printf("%d", errno);
return 0;
}
我们可以理解是这个全局变量是头文件string.h的全局变量,就跟我们前面学过 的全局变量要想在其他源文件里面使用就要声明,使用extern进行声明,只是声明放在头文件里面声明了
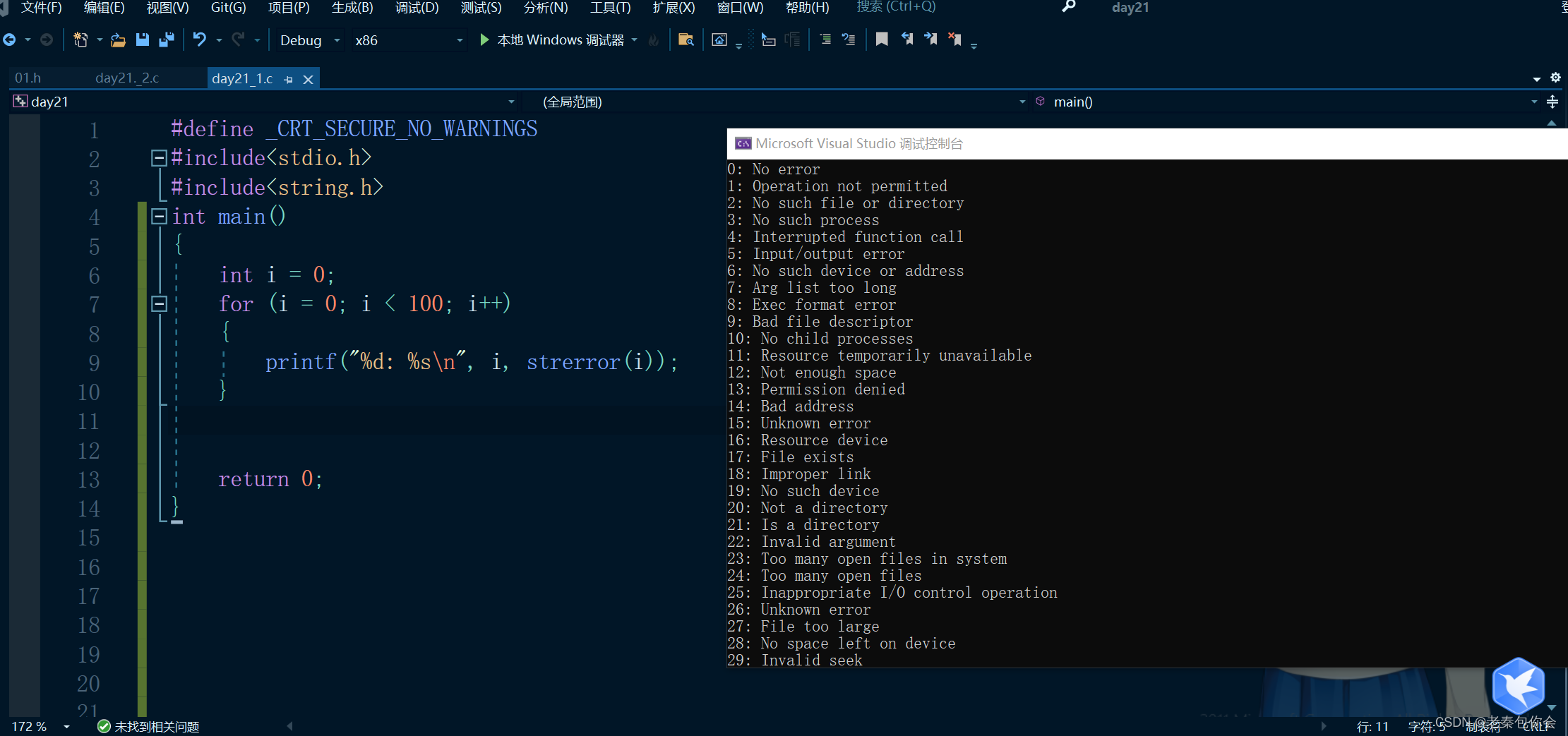
可以看到每个错误码对应的错误信息,错误码是C语言本身的,错误信息是库函数翻译的
我们就以一个例子为例
#include<stdio.h>
#include<string.h>
int main()
{
FILE* pf = fopen("test.txt", "r");
if (!pf)
{
printf("%s", strerror(errno));
}
else
printf("打开了");
return 0;
}
这个是打开文件的例子的,FILE*这个类型是一个结构体类型,后面会慢慢介绍
如果没有该文件,就会打印出错误信息
还有一个函数就是perror这个函数,直接打印出错误信息**perror() == printf(“%s”, strerror(errno))**这个函数很简便,如果我们只想要错误码就不要使用这个函数,这个函数直接会打印出错误信息

打印错误消息
将 errno 的值解释为错误消息,并将其打印到 stderr(标准错误输出流,通常是控制台),可以选择在其前面加上 str 中指定的自定义消息。
errno 是一个全局变量,其值描述调用库函数生成的错误条件或诊断信息(C 标准库的任何函数都可以为 errno 设置值,即使未在此参考中显式指定,即使未发生错误)
打印错误消息
将 errno 的值解释为错误消息,并将其打印到 stderr(标准错误输出流,通常是控制台),可以选择在其前面加上 str 中指定的自定义消息。
#include<stdio.h>
#include<string.h>
int main()
{
FILE* pf = fopen("tes.txt", "r");
if (!pf)
{
perror("原因是");
}
return 0;
}
errno 是一个整数变量,其值描述调用库函数生成的错误条件或诊断信息(C 标准库的任何函数都可以为 errno 设置值,即使未在此参考中显式指定,即使未发生错误)
总结
关于字符函数的讲到这里了,有不懂的可以私聊















 933
933











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











