






 该文展示了如何使用Python的statsmodels库来训练广义加性模型(GAM)。数据集来源于NYCHousing2015,通过GLMGam类的两种方法创建模型,利用B-splines进行特征平滑处理,特别是对BOROUGH和LANDSQUAREFEET两个特征进行了平滑。模型训练后,打印了模型的总结信息。
该文展示了如何使用Python的statsmodels库来训练广义加性模型(GAM)。数据集来源于NYCHousing2015,通过GLMGam类的两种方法创建模型,利用B-splines进行特征平滑处理,特别是对BOROUGH和LANDSQUAREFEET两个特征进行了平滑。模型训练后,打印了模型的总结信息。
先准备数据
import pandas as pd
import os
import statsmodels.api as sm
from statsmodels.gam.api import GLMGam, BSplines
current_dir = os.getcwd()
file_path = os.path.join(current_dir, 'NYCHousing2015.csv')
# Load the data
data = pd.read_csv(file_path)
print(data)
这个数据集是从matlab拔下来的,NYCHousing2015。
在statsmodels中有两种用法可以训练gam模型,
一种是:
gam_model = GLMGam.from_formula(formula, data=data, smoother=bs)还有一种是:
gam_model = GLMGam(y, sm.add_constant(x), smoother=bs,family = sm.families.Gaussian(),alpha=0.0)就我研究来看,基本上statsmodels的模型基本都是这两种训练模式,
可以看一下这个bs,平滑函数,我的理解是定义分类函数特征,我理解的gam模型就是由一个或者多个线性模型和分类模型组合成的模型,那么这里的平滑函数就是做一个这种处理,
x_spline = data[['BOROUGH',"LANDSQUAREFEET"]]
# Create the B-splines
bs = BSplines(x_spline, df=[3, 3], degree=[2,2])我们可以看到我们选择数据里面的'BOROUGH',"LANDSQUAREFEET"这两个特征作为平滑处理的对象,df,选择的特征的自由度,degree理解为poly的极值点,df需要大于degree。
# Train the model
res = gam_model.fit()
# Step 7: Print the summary of the trained model
print(res.summary())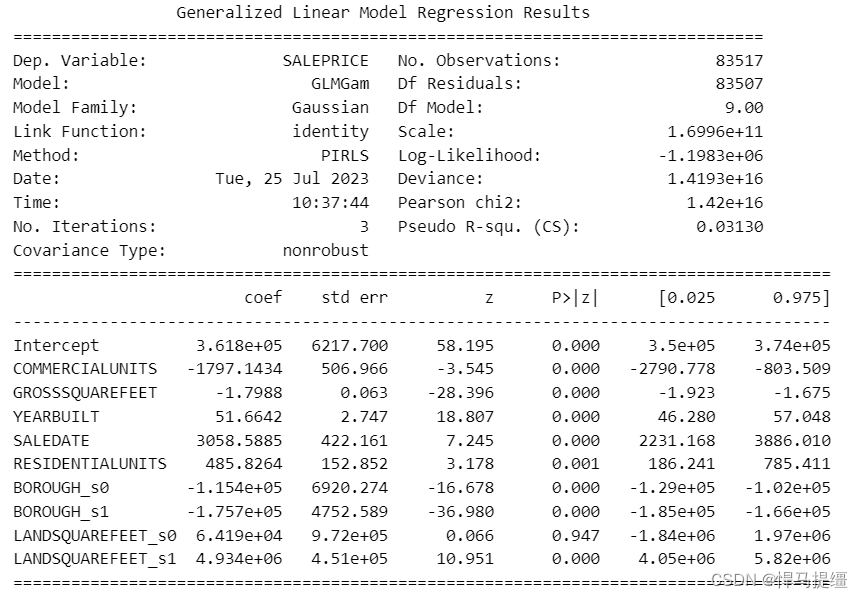


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









