






陆陆续续学了两个月python,当初磕磕绊绊,现在也跌跌撞撞,不过多谢平台各位博主的分享,跨过了最难的阶段,谢谢各位!本片也是参考多位博主博客而来,感谢他们分享!
一、归一化
1、最大值和最小值(min -max normalization):数值范围[0,1]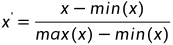
def normalization(data):
data_range = np.max(data) - np.min(data)
return (data - np.min(data)) / data_range
# 一维数组归一化
arr = np.array([137.97, 104.5, 100, 124.32, 79.2, 99, 124, 114, 106.69, 138.05, 53.75, 46.91, 68, 63.02, 81.26, 86.21])
arr_normal = normalization(arr)
print(arr_normal)
# 多维数组归一化,某行某列归一化
df = arr.reshape(2,8)
print(df)
df_row_normal = normalization(df[0:,:])
print(df_row_normal)
# 多维数组整体归一化
arr_normal = normalization(df)
print(arr_normal)可以用公式
优点:保留源数据存在的关系,消除取值范围最简单的方法;
缺点:极易受个别离群值影响,如果数据集中某个数值很大,其他各值归一化后会接近0;比如属性取值大部分接近在最大值周围,那么归一化后数据集中在1附近。
2均值归一化(mean normalization):将数值范围缩放到 [-1, 1] 区间里,且数据的均值变为0。
代码部分和第一种基本一样。
3标准化 / z值归一化(standardization / z-score normalization):将数值缩放到0附近,且数据的分布变为均值为0,标准差为1的标准正态分布
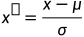
# 数据标准化
def standardization(data):
mu = np.mean(data)
sigma = np.std(data)
return (data - mu) / sigma
arr = np.array([137.97, 104.5, 100, 124.32, 79.2, 99, 124, 114, 106.69, 138.05, 53.75, 46.91, 68, 63.02, 81.26, 86.21])
arr_stand = standardization(arr)
print(arr_stand)
df = arr.reshape(2,8)
print(df)
df_stand = standardization(df)
print(df_stand)
df_rowstand = standardization(df[0])
print(df_row_stand) # 大家可以试试看运行结果也可以调用函数
from sklearn.preprocessing import StandardScaler # sklearn的预处理模块导入标准化模块
arr_stand = StandardScaler().fit_transform(arr.reshape(-1,1))# 加上一列,必须二维
print(arr_stand)














 2020
2020











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









