






目录
1.正则化
1.背景
在机器学习中(或深度学习)有些模型过于复杂导致模型训练阶段产生过拟合(训练集的损失和准确率与验证集的损失和准确率相差很大)。过拟合是指模型的学习能力太强了,将一些噪音点和数据的复杂规律都学到了,但这却降低了模型的泛化能力(鲁棒性)。为了避免过拟合,正则化是一种十分有效的手段。正则化即对参数进行削减,可以从参数量和参数大小两个角度出发。
2.常用的方法
1.L1与L2正则
正则化在损失函数中引入模型复杂度指标,利用给w加权值,弱化了训练数据的噪声(一般不正则化b)。数学形式为:
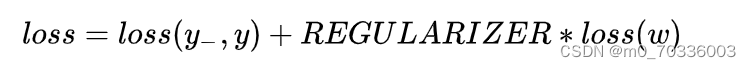 权值w的正则化一般有L1和L2正则化:
权值w的正则化一般有L1和L2正则化:
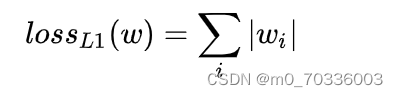
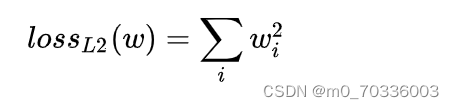
2.Dropout
只针对全连接层进行操作,训练阶段和测试阶段的操作不同,每轮的训练部分神经元失活,测试的时候神经元是全部处于激活态。
nn.Dropout( p):按照概率p随机将神经元失活.目的是缓解神经元之间的隐形的协同适应,从而降低模型复杂度。
3.提前终止
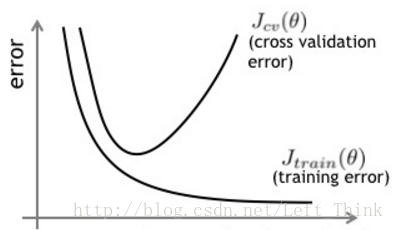
模型在验证集上的误差在一开始是随着训练集的误差的下降而下降的。当超过一定训练步数后,模型在训练集上的误差虽然还在下降,但是在验证集上的误差却不在下降了。此时我们的模型就过拟合了。因此我们可以观察我们训练模型在验证集上的误差,一旦当验证集的误差不再下降时,我们就可以提前终止我们训练的模型。
4.数据增强
数据增强是提升算法性能、满足深度学习模型对大量数据的需求的重要工具。数据增强通过向训练数据添加转换或扰动来人工增加训练数据集。数据增强技术如水平或垂直翻转图像、裁剪、色彩变换、扩展和旋转通常应用在视觉表象和图像分类中。
5.随机池化
按一定概率随机选中其中的一个元素,介于平均池化,受dropout启发,具有更好的正则化效果。
2.优化器
神经网络的优化器一般有一下步骤:
Step 1. 计算时刻t损失函数关于当前参数的梯度
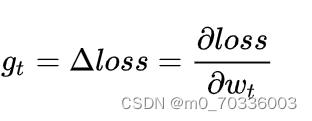
Step 2. 计算时刻t的一阶动量 Mt 和二阶动量 Vt
Step 3. 计算时刻t的下降梯度 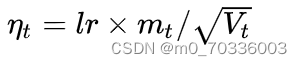
Step 4. 计算时刻t+1的参数 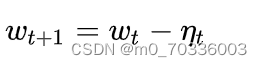
不同的优化方法的主要区别在于Step 2。本文采用2种常见的优化器和它们的实现方法,其他优化方法可根据所需使用。
1. SGD – 随机梯度下降法(Stochastic Gradient Descent)
SGD的一阶动力和二阶动量分别为
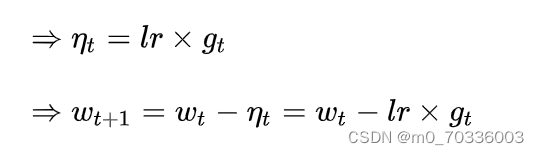
例子:
import tensorflow as tf
import numpy as np
from sklearn import datasets
from matplotlib import pyplot as plt
import time
# 读入数据
x_data=datasets.load_iris().data
y_data=datasets.load_iris().target
# 打乱数据
np.random.seed(116) #使用相同的seed,输出相同的随机数
np.random.shuffle(x_data)
np.random.seed(116)
np.random.shuffle(y_data)
tf.random.set_seed(116) #如果不设置seed,每一次运行结果都不一样
# 划分训练集和测试集
x_train=x_data[:-30]
y_train=y_data[:-30]
x_test=x_data[-30:]
y_test=y_data[-30:]
# 转换x的数据类型,否则后面矩阵相乘时会因数据类型不一致报错
x_train = tf.cast(x_train, tf.float32)
x_test = tf.cast(x_test, tf.float32)
# 数据集配对
train_db=tf.data.Dataset.from_tensor_slices((x_train,y_train)).batch(32)
test_db=tf.data.Dataset.from_tensor_slices((x_test,y_test)).batch(32)
# 生成神经网络的参数,4个输入特征故,输入层为4个输入节点;因为3分类,故输出层为3个神经元
# 用tf.Variable()标记参数可训练
# 使用seed使每次生成的随机数相同(方便教学,使大家结果都一致,在现实使用时不写seed)
w1=tf.Variable(tf.random.truncated_normal([4,3],stddev=0.1,seed=1))
b1=tf.Variable(tf.random.truncated_normal([3],stddev=0.1,seed=1))
# 训练神经网络
lr=0.1
train_loss_results = [] # 将每轮的loss记录在此列表中,为后续画loss曲线提供数据
test_acc = [] # 将每轮的acc记录在此列表中,为后续画acc曲线提供数据
epoch = 500 # 循环500轮
loss_all = 0 # 每轮分4个step,loss_all记录四个step生成的4个loss的和
now_time=time.time()
for epoch in range(epoch):
#训练部分
for step,(x_train,y_train) in enumerate(train_db):
with tf.GradientTape() as tape:
y=tf.linalg.matmul(x_train,w1)+b1
y=tf.nn.softmax(y) # 使输出y符合概率分布
y_=tf.one_hot(y_train,depth=3) # 将标签值转换为独热码格式,方便计算loss和accuracy
loss=tf.math.reduce_mean(tf.math.square(y-y_)) # 采用均方误差损失函数mse = mean(sum(y-out)^2)
loss_all+=loss.numpy() # 将每个step计算出的loss累加,为后续求loss平均值提供数据,这样计算的loss更准确
# 计算loss对各个参数的梯度
grads=tape.gradient(loss,[w1,b1])
# 实现梯度更新 w1 = w1 - lr * w1_grad b = b - lr * b_grad
w1.assign_sub(lr*grads[0])
b1.assign_sub(lr*grads[1])
print("Epoch {},loss:{}".format(epoch,loss_all/4)) # 训练集有120个数据,每个batch有32个数据
train_loss_results.append(loss_all / 4) # 将4个step的loss求平均记录在此变量中
loss_all = 0 # loss_all归零,为记录下一个epoch的loss做准备
# 测试部分
total_correct, total_number = 0, 0
for x_test,y_test in test_db:
# 使用更新后的参数进行预测
y=tf.linalg.matmul(x_test,w1)+b1
y=tf.nn.softmax(y)
pred=tf.math.argmax(y,1) #返回y中最大值的索引,即预测的分类
# 将pred转换为y_test的数据类型
pred=tf.cast(pred,dtype=y_test.dtype)
# 若分类正确,则correct=1,否则为0,将bool型的结果转换为int型
correct=tf.cast(tf.math.equal(pred,y_test),dtype=tf.int32)
# 将每个batch的correct数加起来
correct=tf.math.reduce_sum(correct)
# 将所有batch中的correct数加起来
total_correct+=int(correct)
# total_number为测试的总样本数,也就是x_test的行数,shape[0]返回变量的行数
total_number+=x_test.shape[0]
acc=total_correct/total_number
test_acc.append(acc)
print("Test_acc:", acc)
print("--------------------------")
total_time=time.time()-now_time
print('total time',total_time)
# 绘制 loss 曲线
plt.title('Loss Function Curve') # 图片标题
plt.xlabel('Epoch') # x轴变量名称
plt.ylabel('Loss') # y轴变量名称
plt.plot(train_loss_results, label="$Loss$") # 逐点画出trian_loss_results值并连线,连线图标是Loss
plt.legend() # 画出曲线图标
plt.show() # 画出图像
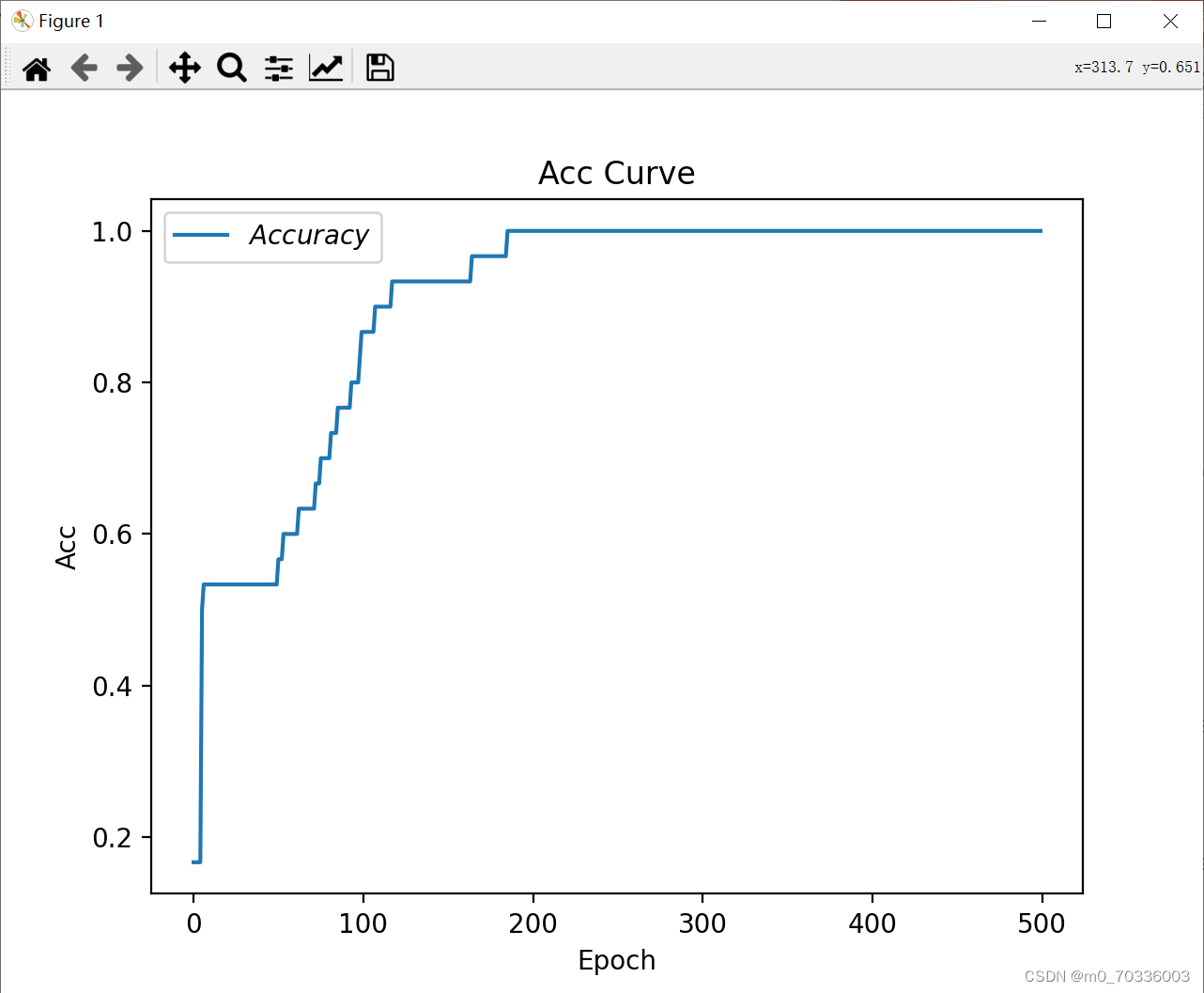
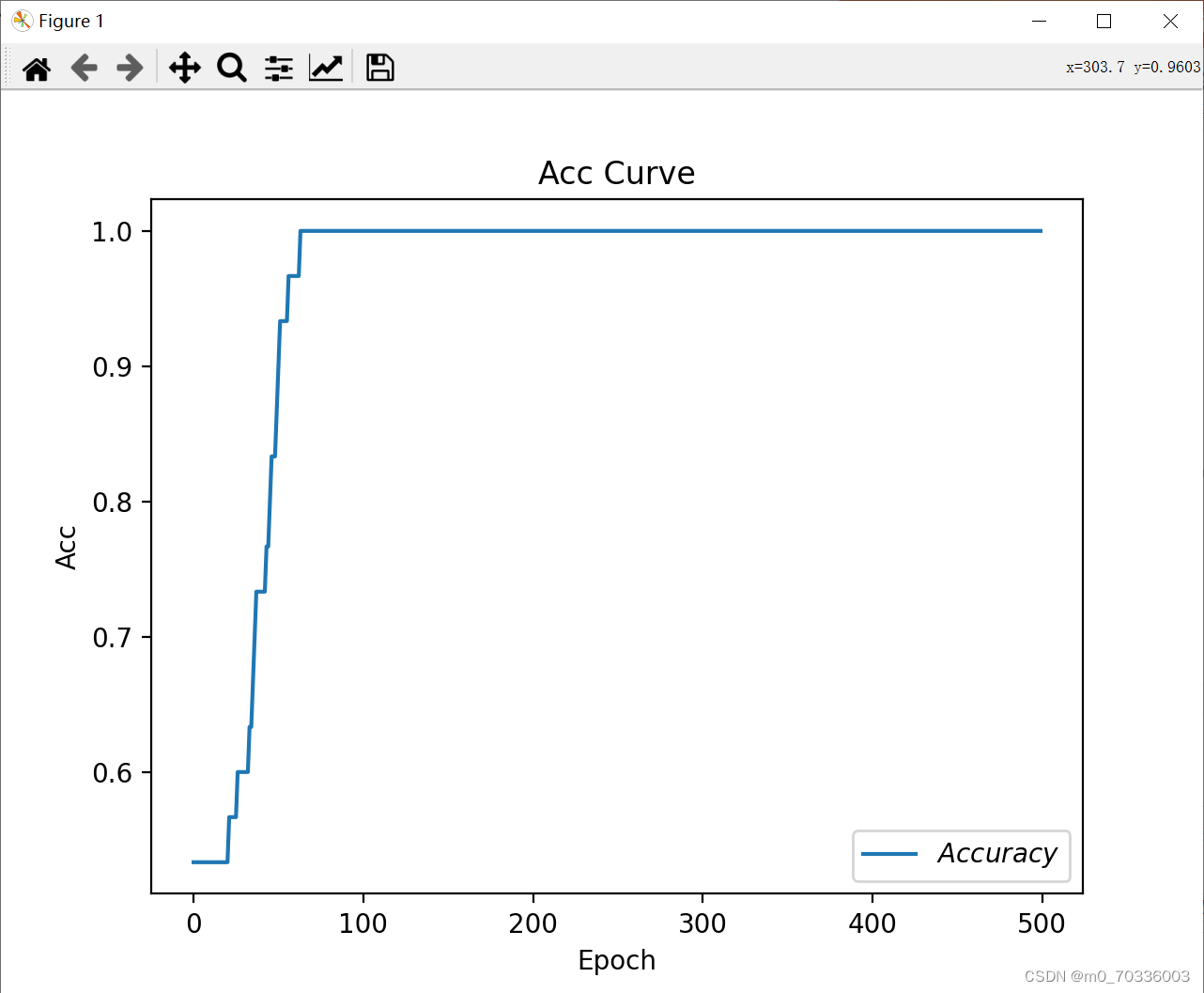
# 绘制 Accuracy 曲线
plt.title('Acc Curve') # 图片标题
plt.xlabel('Epoch') # x轴变量名称
plt.ylabel('Acc') # y轴变量名称
plt.plot(test_acc, label="$Accuracy$") # 逐点画出test_acc值并连线,连线图标是Accuracy
plt.legend()
plt.show()结果: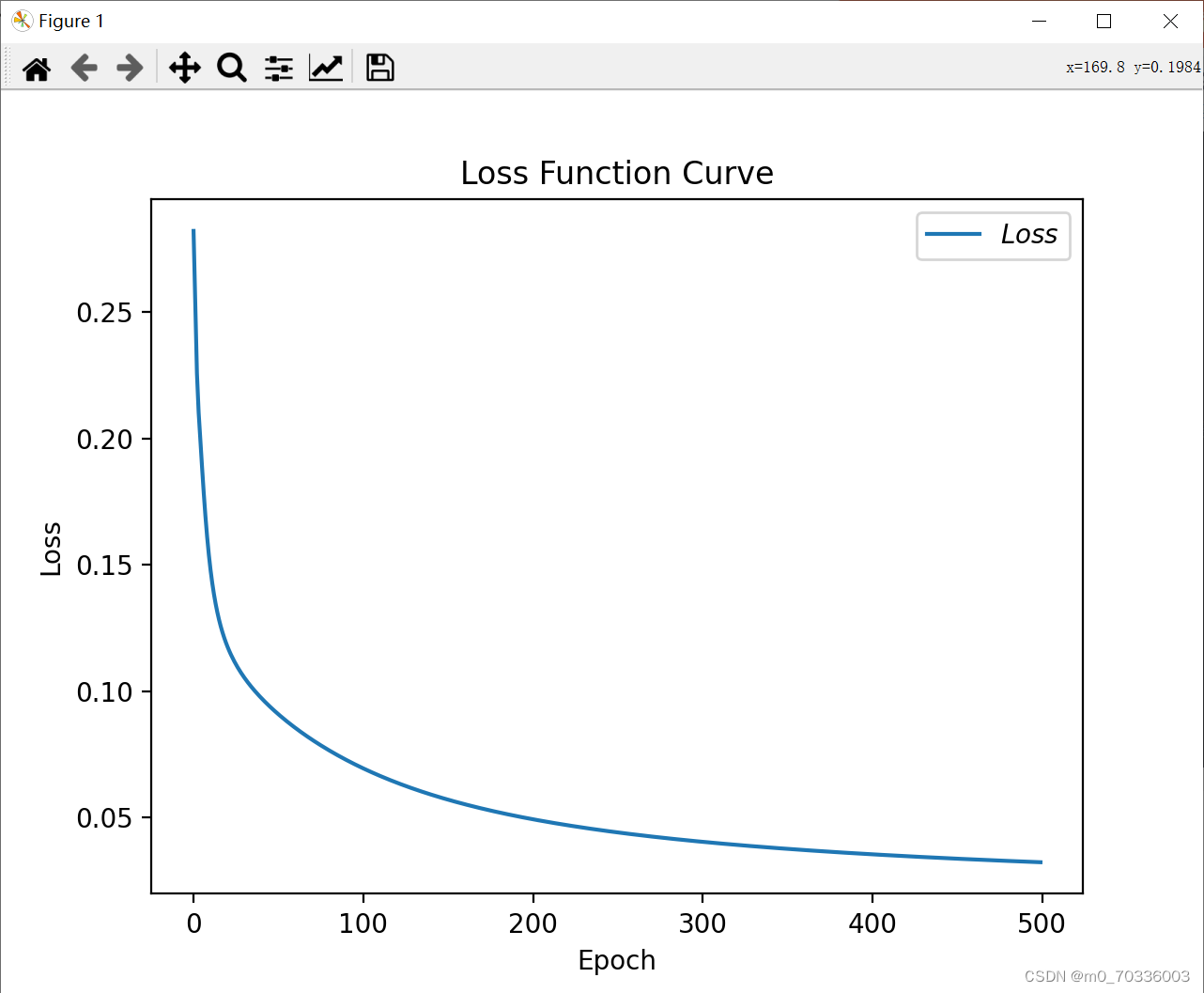
2 AdaGrad
Adagrad在SGD的基础上分配二阶动量,可以对模型中的每一个参数分配自适应学习率。Adagrad的一阶动量和二阶动量分别为: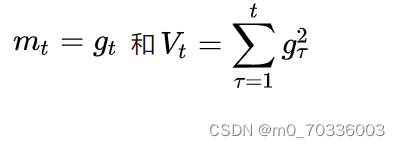
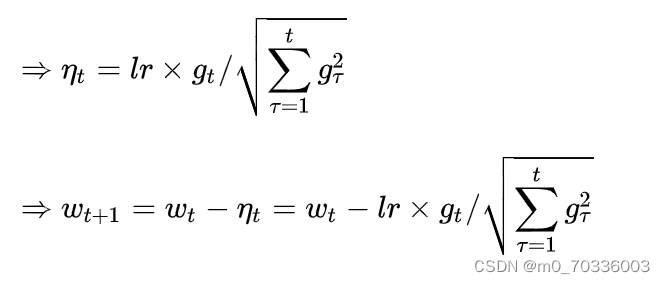
例子:
import tensorflow as tf
import numpy as np
from sklearn import datasets
from matplotlib import pyplot as plt
import time
# 读入数据
x_data=datasets.load_iris().data
y_data=datasets.load_iris().target
# 打乱数据
np.random.seed(116) #使用相同的seed,输出相同的随机数
np.random.shuffle(x_data)
np.random.seed(116)
np.random.shuffle(y_data)
tf.random.set_seed(116) #如果不设置seed,每一次运行结果都不一样
# 划分训练集和测试集
x_train=x_data[:-30]
y_train=y_data[:-30]
x_test=x_data[-30:]
y_test=y_data[-30:]
# 转换x的数据类型,否则后面矩阵相乘时会因数据类型不一致报错
x_train = tf.cast(x_train, tf.float32)
x_test = tf.cast(x_test, tf.float32)
# 数据集配对
train_db=tf.data.Dataset.from_tensor_slices((x_train,y_train)).batch(32)
test_db=tf.data.Dataset.from_tensor_slices((x_test,y_test)).batch(32)
# 生成神经网络的参数,4个输入特征故,输入层为4个输入节点;因为3分类,故输出层为3个神经元
# 用tf.Variable()标记参数可训练
# 使用seed使每次生成的随机数相同(方便教学,使大家结果都一致,在现实使用时不写seed)
w1=tf.Variable(tf.random.truncated_normal([4,3],stddev=0.1,seed=1))
b1=tf.Variable(tf.random.truncated_normal([3],stddev=0.1,seed=1))
# 训练神经网络
lr=0.1
train_loss_results = [] # 将每轮的loss记录在此列表中,为后续画loss曲线提供数据
test_acc = [] # 将每轮的acc记录在此列表中,为后续画acc曲线提供数据
epoch = 500 # 循环500轮
loss_all = 0 # 每轮分4个step,loss_all记录四个step生成的4个loss的和
# adagrad
v_w=tf.constant(0,shape=[4,3],dtype=tf.float32)
v_b=tf.constant(0,shape=[3],dtype=tf.float32)
now_time=time.time()
for epoch in range(epoch):
#训练部分
for step,(x_train,y_train) in enumerate(train_db):
with tf.GradientTape() as tape:
y=tf.linalg.matmul(x_train,w1)+b1
y=tf.nn.softmax(y) # 使输出y符合概率分布
y_=tf.one_hot(y_train,depth=3) # 将标签值转换为独热码格式,方便计算loss和accuracy
loss=tf.math.reduce_mean(tf.math.square(y-y_)) # 采用均方误差损失函数mse = mean(sum(y-out)^2)
loss_all+=loss.numpy() # 将每个step计算出的loss累加,为后续求loss平均值提供数据,这样计算的loss更准确
# 计算loss对各个参数的梯度
grads=tape.gradient(loss,[w1,b1])
# adagrad
v_w+=tf.math.square(grads[0])
v_b+=tf.math.square(grads[1])
w1.assign_sub(lr*grads[0]/tf.math.sqrt(v_w))
b1.assign_sub(lr*grads[1]/tf.math.sqrt(v_b))
print("Epoch {},loss:{}".format(epoch,loss_all/4)) # 训练集有120个数据,每个batch有32个数据
train_loss_results.append(loss_all / 4) # 将4个step的loss求平均记录在此变量中
loss_all = 0 # loss_all归零,为记录下一个epoch的loss做准备
# 测试部分
total_correct, total_number = 0, 0
for x_test,y_test in test_db:
# 使用更新后的参数进行预测
y=tf.linalg.matmul(x_test,w1)+b1
y=tf.nn.softmax(y)
pred=tf.math.argmax(y,1) #返回y中最大值的索引,即预测的分类
# 将pred转换为y_test的数据类型
pred=tf.cast(pred,dtype=y_test.dtype)
# 若分类正确,则correct=1,否则为0,将bool型的结果转换为int型
correct=tf.cast(tf.math.equal(pred,y_test),dtype=tf.int32)
# 将每个batch的correct数加起来
correct=tf.math.reduce_sum(correct)
# 将所有batch中的correct数加起来
total_correct+=int(correct)
# total_number为测试的总样本数,也就是x_test的行数,shape[0]返回变量的行数
total_number+=x_test.shape[0]
acc=total_correct/total_number
test_acc.append(acc)
print("Test_acc:", acc)
print("--------------------------")
total_time=time.time()-now_time
print('total time',total_time)
# 绘制 loss 曲线
plt.title('Loss Function Curve') # 图片标题
plt.xlabel('Epoch') # x轴变量名称
plt.ylabel('Loss') # y轴变量名称
plt.plot(train_loss_results, label="$Loss$") # 逐点画出trian_loss_results值并连线,连线图标是Loss
plt.legend() # 画出曲线图标
plt.show() # 画出图像
# 绘制 Accuracy 曲线
plt.title('Acc Curve') # 图片标题
plt.xlabel('Epoch') # x轴变量名称
plt.ylabel('Acc') # y轴变量名称
plt.plot(test_acc, label="$Accuracy$") # 逐点画出test_acc值并连线,连线图标是Accuracy
plt.legend()
plt.show() 结果: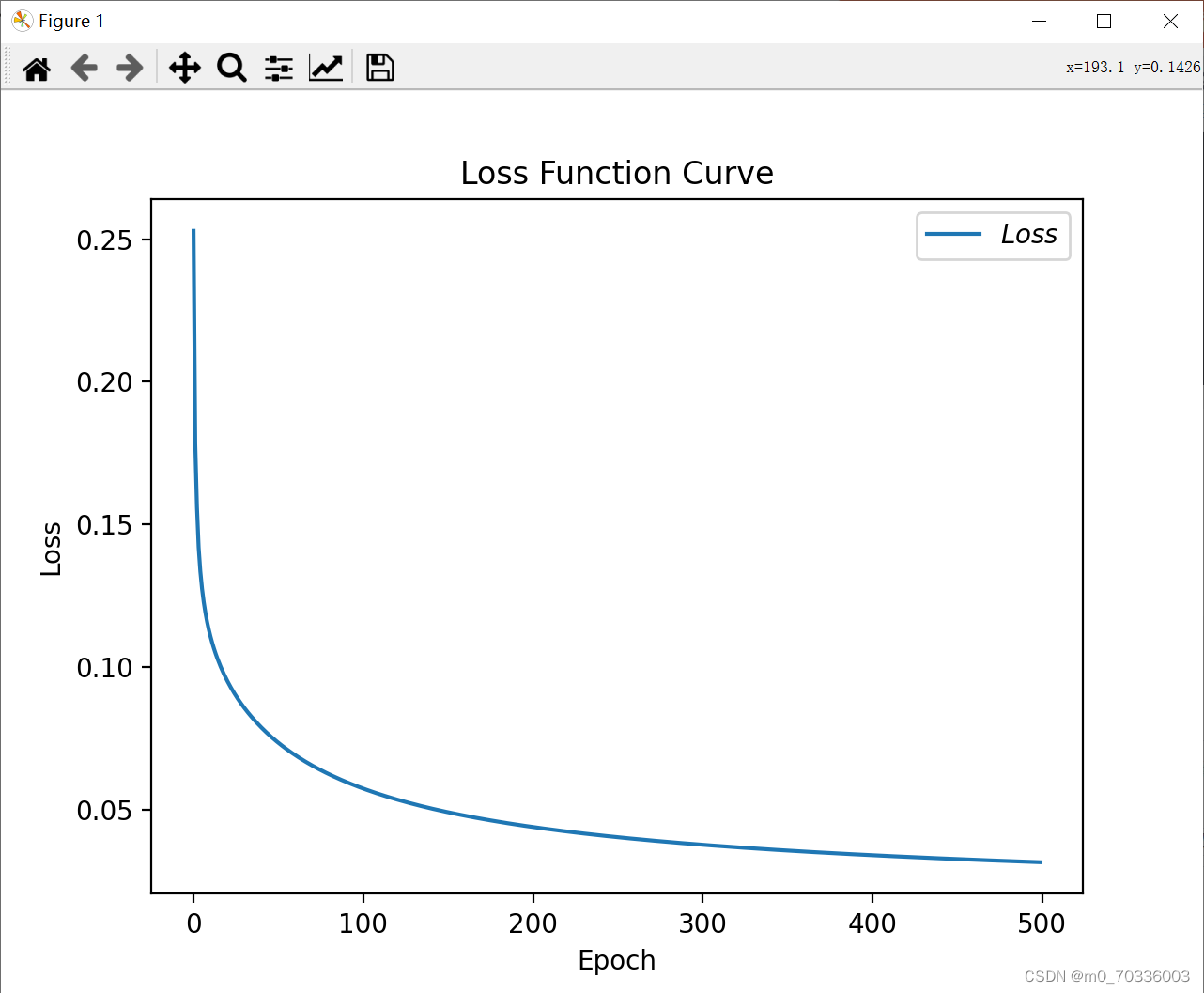















 211
211











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









