






【菜鸟记录自己的学习心得】
文章案例与方法技巧大多来源与网络,以下是链接:
【Python数据预处理:彻底理解标准化和归一化】https://mbd.baidu.com/ma/s/0tI1VMDb
【python中subplot的用法_[小白系列][可视化基础]多个子图(
推荐其中一位作者大大的文章,大家可以加他微信学习深度学习,他人很好的
http://t.csdn.cn/nvqPa(本文案例及代码来源可以看这位作者更准确,我只是做学习记录)
>- **🍨 本文为[🔗365天深度学习训练营](https://mp.weixin.qq.com/s/k-vYaC8l7uxX51WoypLkTw)内部限免文章(版权归 *K同学啊* 所有)**
>- ** 参考文章地址: [🔗深度学习100例-循环神经网络(RNN)心脏病预测 | 第46天](https://blog.csdn.net/qq_38251616/article/details/126345651)**
>- **🍖 作者:[K同学啊 | 接辅导、程序定制](https://mp.weixin.qq.com/s/k-vYaC8l7uxX51WoypLkTw)**
再次说明,如果有资源冲突请联系我删除
好了终于可以开始小菜鸡记录了
1,导入必要的库
import tensorflow as tf
from tensorflow.keras import datasets, layers, models#数据库,模型层,模型
import matplotlib.pyplot as plt
import csv恶补基础(1):tensorflow简介:
【tensorflow是干什么的_-36氪企服点评】https://mbd.baidu.com/ma/s/nQkq9sAw

本文的卷积过程就是一个数据流图(我是这样理解的)
2,导入数据(mnist数据集,老师文章有介绍)
# 导入mnist数据,依次分别为训练集图片、训练集标签、测试集图片、测试集标签,保证网络通畅
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()#加载
# 将像素的值标准化至0到1的区间内。(对于灰度图片来说,每个像素最大值是255,每个像素最小值是0,也就是直接除以255就可以完成归一化。用最大-最小规范化)
train_images, test_images = train_images / 255.0, test_images / 255.0
# 查看数据维数信息
print(train_images.shape,test_images.shape,train_labels.shape,test_labels.shape)恶补基础2:1,dataset.数据库名.load_data()这种语句见了挺多的,应该就是一种加载方式吧,并将加载结果赋予训练集,测试集。
2,归一化,标准化学习
归一化的两种方法:【python中subplot的用法_[小白系列][可视化基础]多个子图(Axes), 使用 subplot() 快速绘制...】https://mbd.baidu.com/ma/s/mvPYxUwX
(1),最大最小规范化:映射到[0.,1]区间
上述代码就是这种方式
(2),z-score标准化
(3)为什么要标准化,归一化
提升模型精度:标准化/归一化后,不同维度之间的特征在数值上有一定比较性,可以大大提高分类器的准确性。
加速模型收敛:标准化/归一化后,最优解的寻优过程明显会变得平缓,更容易正确的收敛到最优解

3,print(train_images.shape,test_images.shape,train_labels.shape,test_labels.shape)
可以查看训练集,测试集的样本构成
输出:((60000, 28, 28), (10000, 28, 28), (60000,), (10000,)) 训练集60000样本,测试集10000个样本,2828单通道灰度图 """ # 将数据集前20个图片数据可视化显示 # 进行图像大小为宽10、长20的绘图(单位为英寸inch)
3,可视化前20张图片
# 将数据集前20个图片数据可视化显示
# 进行图像大小为宽10、长20的绘图(单位为英寸inch)
plt.figure(figsize=(20,10))
# 遍历MNIST数据集下标数值0~49
for i in range(20):#需要绘制20张子图用了for in循环
# 将整个figure分成2行10列,绘制第i+1个子图。
plt.subplot(2,10,i+1)#表示大的画布被切分为两行十列,i+1表示对第i+1个子图作图
# 设置不显示x轴刻度
plt.xticks([])
# 设置不显示y轴刻度
plt.yticks([])
# 设置不显示子图网格线
plt.grid(False)
# 图像展示,cmap为颜色图谱,"plt.cm.binary"为matplotlib.cm中的色表
plt.imshow(train_images[i], cmap=plt.cm.binary)
# 设置x轴标签显示为图片对应的数字
plt.xlabel(train_labels[i])#x轴的标签即为子图对应的数字
# 显示图片
plt.show()基础恶补3:
1,subplot用法(这里有一篇好文,不再赘述)【Python3 matplotlib的绘图函数subplot()简介 - 走看看】http://t.zoukankan.com/lizm166-p-9667923.html
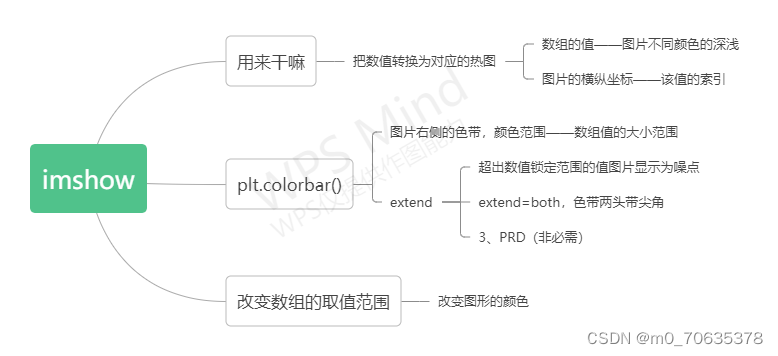
2,imshow()看了该文章【plt.imshow()函数小总结】https://mbd.baidu.com/ma/s/trYZ5vWK
大概总结了以下几点:
4,调整数据格式(转换维度)
#调整数据到我们需要的格式(转换维度)
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))
print(train_images.shape,test_images.shape,train_labels.shape,test_labels.shape)
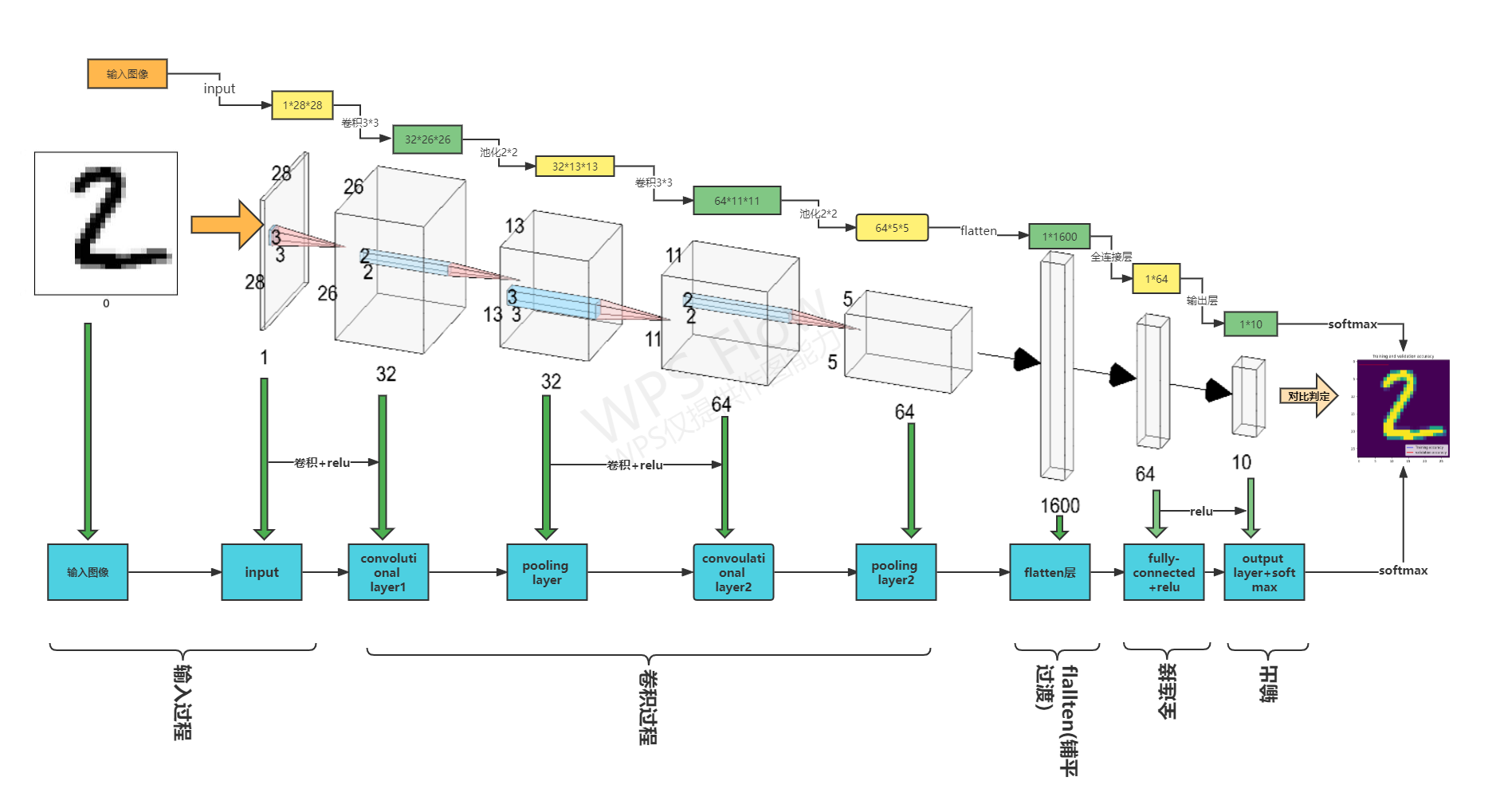
"""5,搭建神经网络结构
# 创建并设置卷积神经网络
# 卷积层:通过卷积操作对输入图像进行降维和特征抽取
# 池化层:是一种非线性形式的下采样。主要用于特征降维,压缩数据和参数的数量,减小过拟合,同时提高模型的鲁棒性。
# 全连接层:在经过几个卷积和池化层之后,神经网络中的高级推理通过全连接层来完成。
model = models.Sequential([
# models.Sequential模型顺序,设置二维卷积层1,设置32个3*3卷积核,activation参数将激活函数设置为ReLu函数,input_shape参数将图层的输入形状设置为(28, 28, 1)
# ReLu函数作为激活励函数可以增强判定函数和整个神经网络的非线性特性,而本身并不会改变卷积层
# 相比其它函数来说,ReLU函数更受青睐,这是因为它可以将神经网络的训练速度提升数倍,而并不会对模型的泛化准确度造成显著影响。
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
# 池化层1,2*2采样
layers.MaxPooling2D((2, 2)),
# 设置二维卷积层2,设置64个3*3卷积核,activation参数将激活函数设置为ReLu函数
layers.Conv2D(64, (3, 3), activation='relu'),
# 池化层2,2*2采样
layers.MaxPooling2D((2, 2)),
layers.Flatten(), # Flatten层,连接卷积层与全连接层
layers.Dense(64, activation='relu'), # 全连接层,特征进一步提取,64为输出空间的维数,activation参数将激活函数设置为ReLu函数
layers.Dense(10) # 输出层,输出预期结果,10为输出空间的维数
])
# 打印网络结构
model.summary()#model.summary()对应网络结构显示各个参数
"""恶补开始:
基础恶补4:
1,sequential函数
省去挨个实例化神经元,依次传参的麻烦,直接输入每个神经元的名字还有参数,该函数会将各个神经元自动依次连接,就是一条龙的感觉嘿嘿嘿。
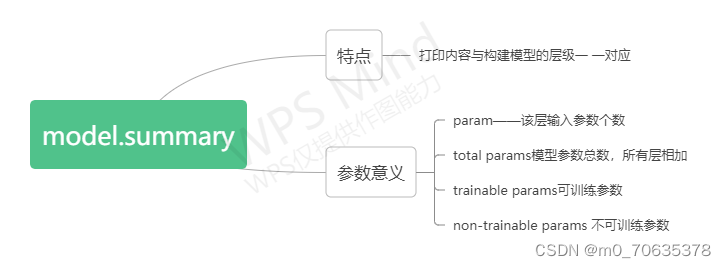
2,model.summary()
【【深度学习21天学习挑战赛】备忘篇:我们的神经网模型到底长啥样?——model.summary()详解】https://mbd.baidu.com/ma/s/eytsx0lm
作用及参数意义总结:
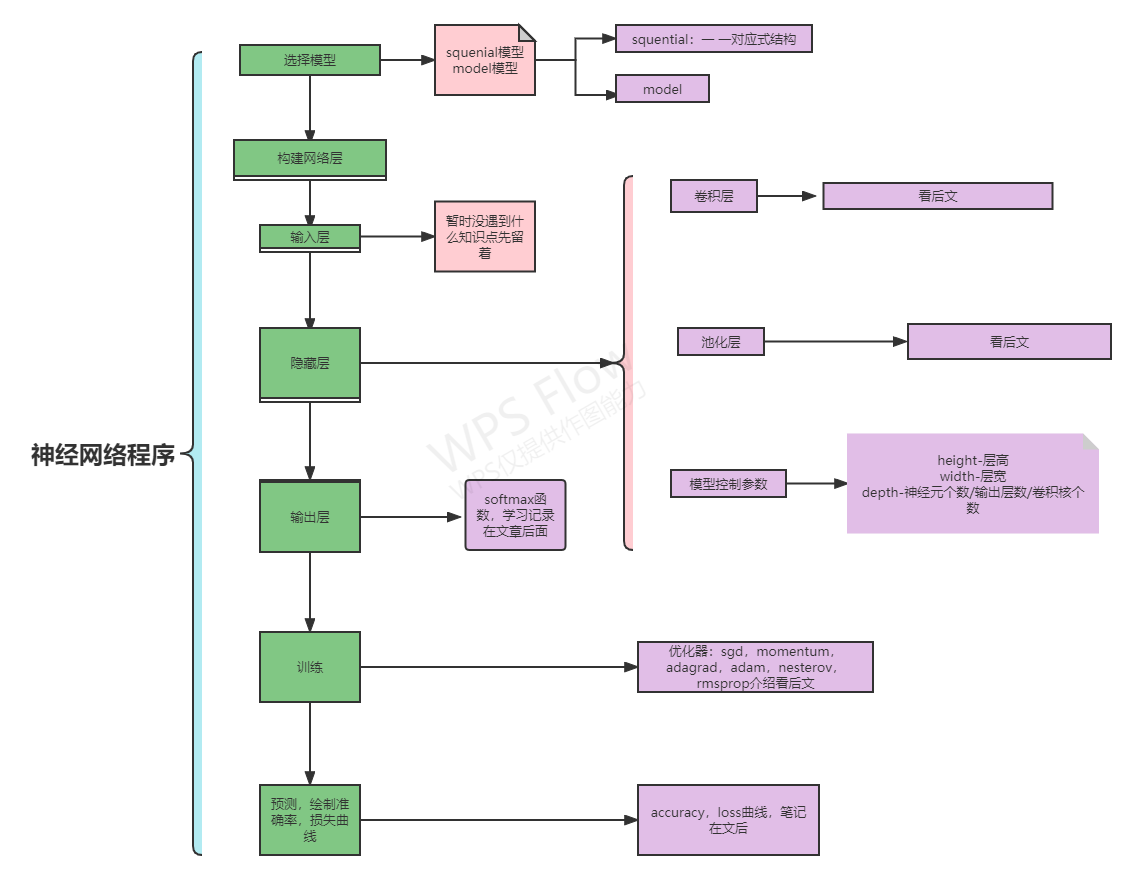
3,下图是我按神经网络结构搭建模型做的卷积过程示意图,也许有错,大家有看出来错误的话可以批评指正。
基于原作者的总结,对我的学习掌握情况与心得做个总结
原作者总结:
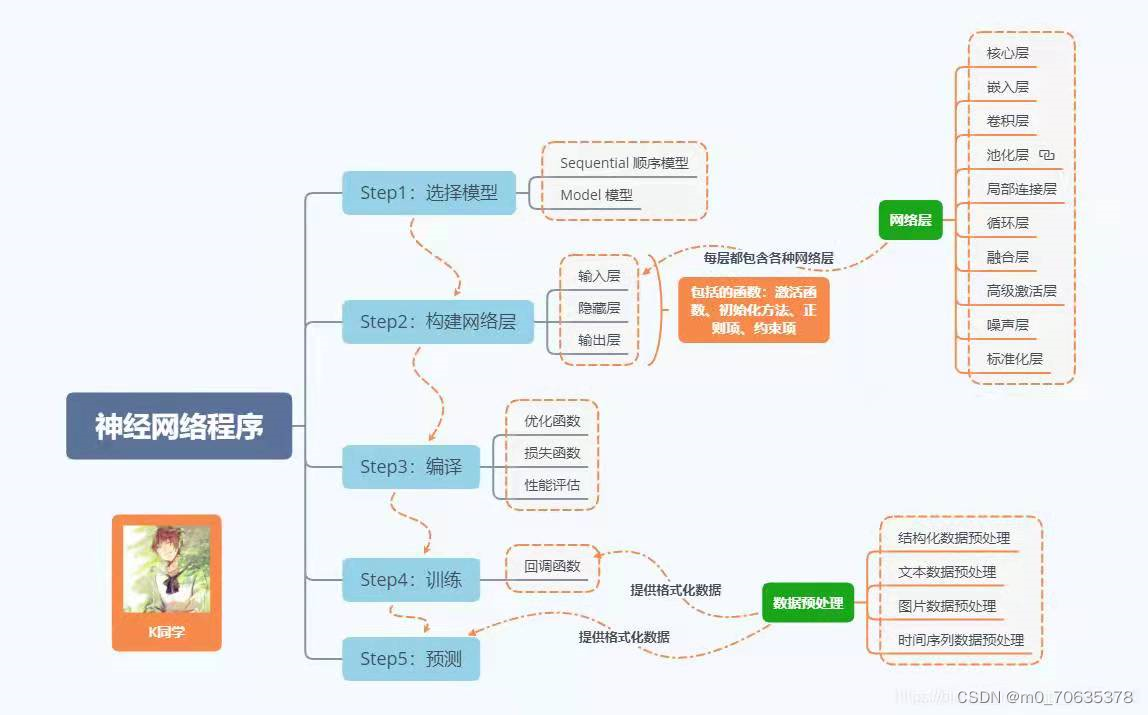
我的总结(因为我基础薄弱更多以记录知识点为目的所以比较细化零碎):
四种激活函数: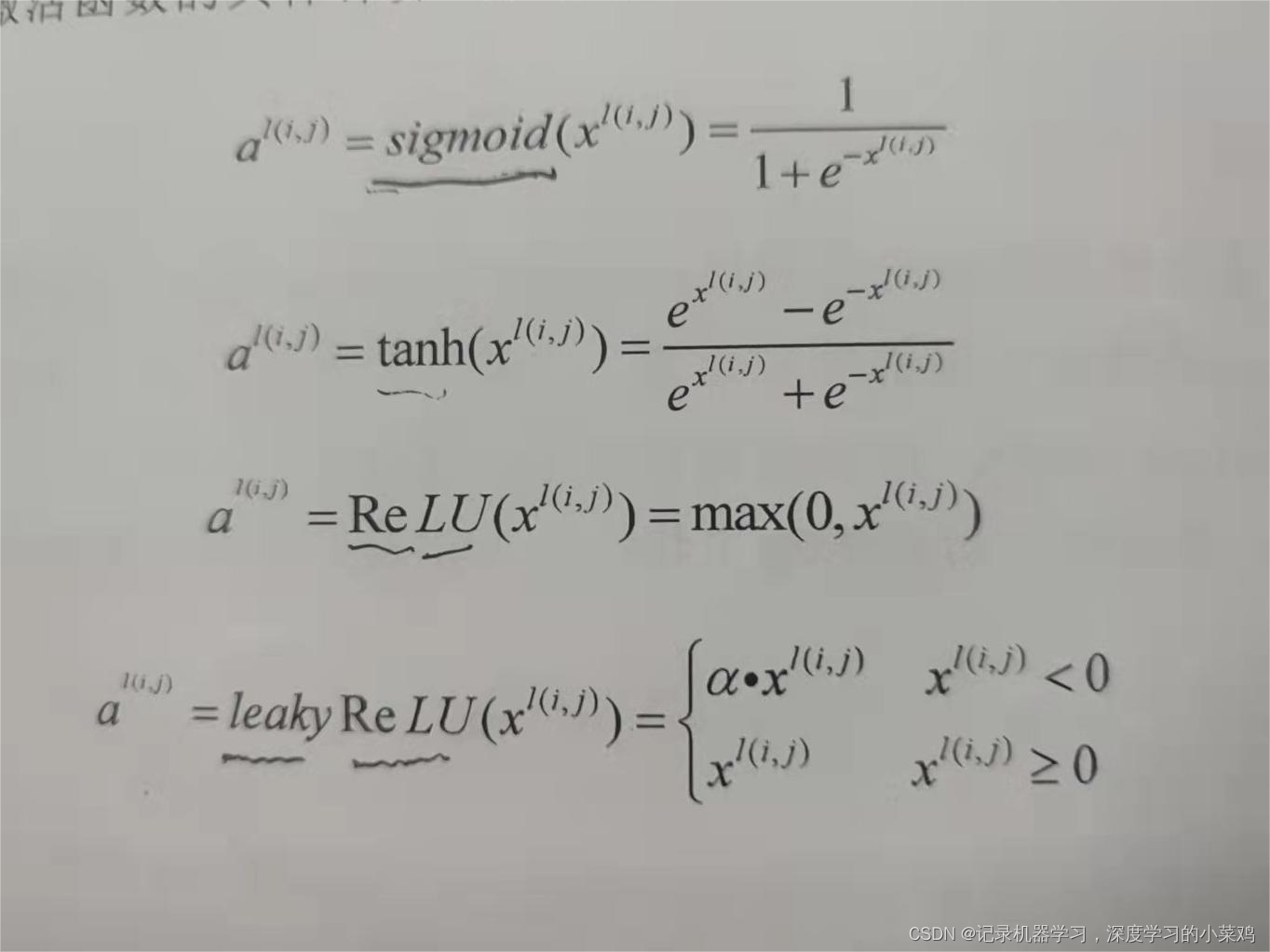
图像如下
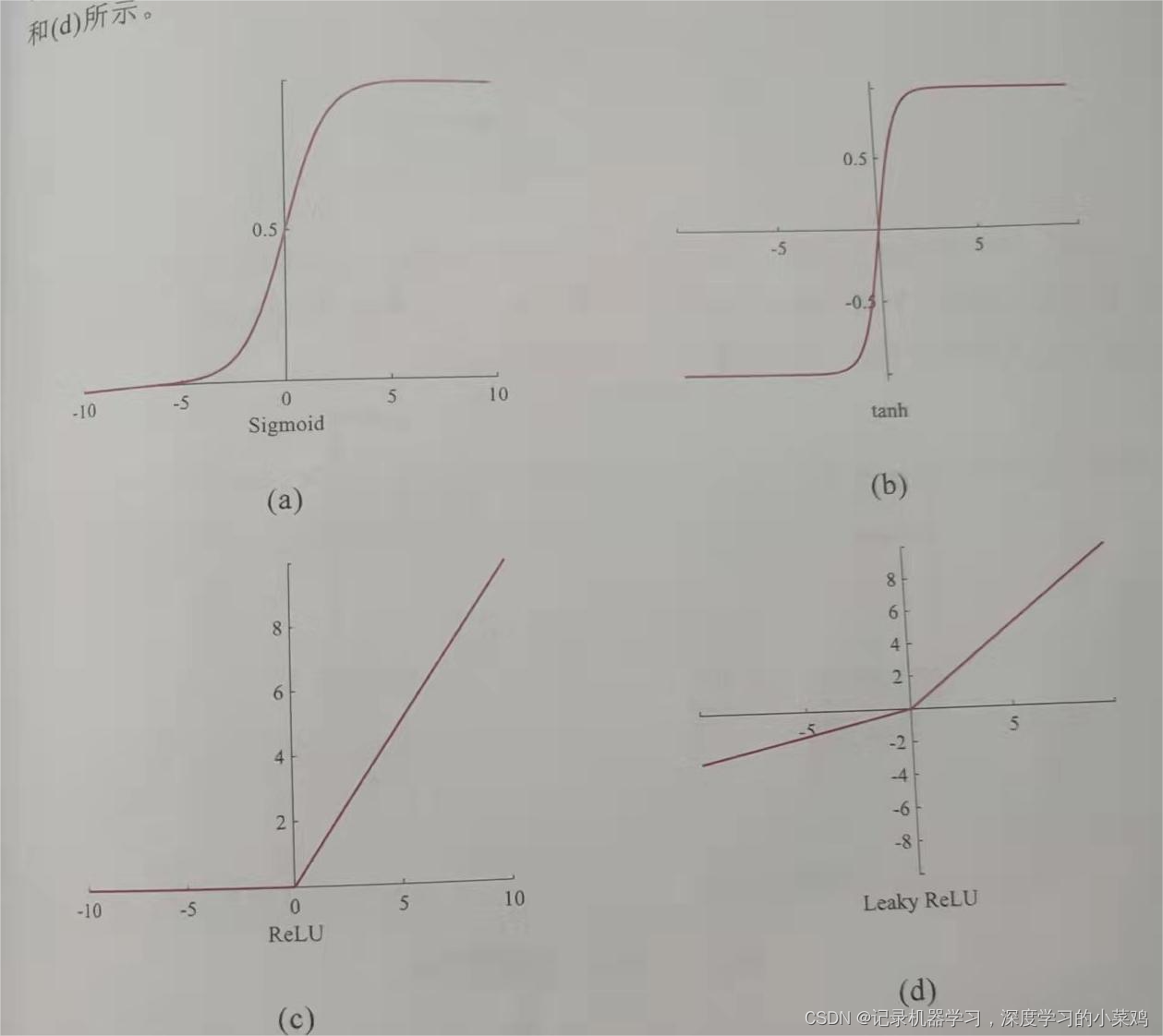
对于激活函数的理解:
可以看sigmoid与tanh函数在输入特征绝对值较大时函数很平缓,求导几乎为0导致梯度下降弥散的问题,于是在卷积过程中选用有利于梯度下降(对权重求偏导),收敛性好,leaky relu函数可以解决被激活的值小于0时激活函数不学习的问题。
对于卷积层与池化层:
http://t.csdn.cn/BAg8c该文章介绍的很好
卷积公式: (w/h为输出层宽或高,W/H为输入层的宽或高,s为步长f为卷积核大小,p为padding大小)小数向上取整
池化公式 (w为输出层宽,W为输入层的宽,s为步长f为卷积核大小,池化层一般无padding步骤)得数为小数时向下取整
优化器:暂时感觉这部分还没有太了解总结不出来什么好东西,后面专门出一期吧
神经网络优化方面这里有一篇好文章记录一下http://t.csdn.cn/lDX9b
本文优化器代码分享
# model.compile()方法用于在配置训练方法时,告知训练时用的优化器、损失函数和准确率评测标准
model.compile(
# 设置优化器为Adam优化器
optimizer='adam',
# 设置损失函数为交叉熵损失函数(tf.keras.losses.SparseCategoricalCrossentropy())
# from_logits为True时,会将y_pred转化为概率(用softmax),否则不进行转换,通常情况下用True结果更稳定
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
# 设置性能指标列表,将在模型训练时监控列表中的指标
metrics=['accuracy'])
"""
这里设置输入训练数据集(图片及标签)、验证数据集(图片及标签)以及迭代次数epochs训练模型:这里的history我理解成为记录训练过程的这样一个名词,validation表示验证
history = model.fit(
# 输入训练集图片
train_images,
# 输入训练集标签
train_labels,
# 设置10个epoch,每一个epoch都将会把所有的数据输入模型完成一次训练。
epochs=10,
# 设置验证集
validation_data=(test_images, test_labels))通过imshow方法输出预测集索引为1的图像
plt.imshow(test_images[1].reshape(28,28))test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)verbose:
1,当verbose=0时,简单说就是不输出日志信息 ,进度条、loss、acc这些都不输出。
2,当verbose=1时,带进度条的输出日志信息。
3. 当verbose=2时,为每个epoch输出一行记录,和1的区别就是没有进度条。
model.evaluate与model.predict:参考文献(【model.evaluate 和 model.predict 的区别】https://mbd.baidu.com/ma/s/HNoGXUKr)
Accuracy曲线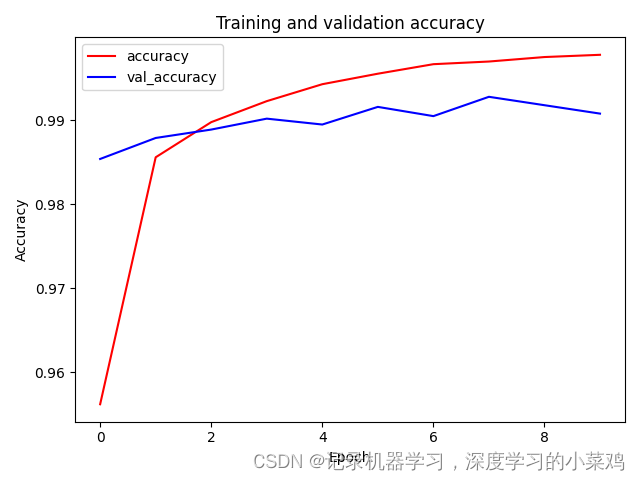
代码分享
#准确率曲线
plt.plot(history.history['accuracy'],'r', label='accuracy')
plt.plot(history.history['val_accuracy'],'b', label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.title('Training and validation accuracy')
plt.legend()
plt.show()Loss曲线
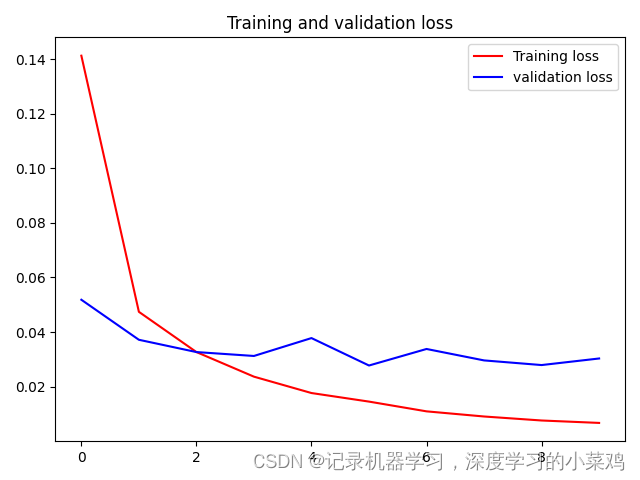
#损失曲线
plt.plot(history.history['loss'], 'r', label='Training loss')
plt.plot(history.history['val_loss'], 'b', label='validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()好了,这次到这里啦。















 197
197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









