






一.数据库的创建、删除、使用
数据库的创建:create database +数据库名
数据库的删除:drop database +数据库名;
数据库的使用:use+数据名;
所有数据库的查看:show databases;
建立数据时如何指定字符集: create database +数据库名+charset utf8;
二.数据库中常用的数据类型:
int 类型
date time表示时间的数据类型如:2011-11-12-15:42:09;
varchar(20) 用来表示字符串,括号里表示的是字符个数
decimal(m,n)精确的表示浮点数的,常用来表示价格,m表示有效数据位,n表示小数点后的位数。
三.表的使用
表的任何一个操作都要指定使用那一个数据库:
如 use java108;
表的建立:
create table +表名(变量/列名+数据类型,变量/列名+数据类型,变量/列名+数据类型............);
表结构的查看:
desc+表名:
查看所有表:
show tables;
表的插入:
1.全列插入:
insert +into +表名+values(数据,数据,数据);
2.指定列的插入:
insert+into +表名(列名,列名,列名)+values(数据,数据,数据);

3.多行数据的插入:insert into 表名 values(数据,数据,数据),(数据,数据,数据),(数据,数据,数据)
表中数据的查看:
1.全部列的查看
建议不要轻易查看如果数据量比较多,会把硬盘IO吃满,或者把网络带宽吃满。
select*from 表名

2.指定列的查看:
select 列名,列名,列名 .....from 表名

表的分页查看:
select*from +表名 limit +数字 offset+数字;(limit表示查看几行,offset表示从第几行开始)
select 列名,列名,列名......limit+数字 offset+数字

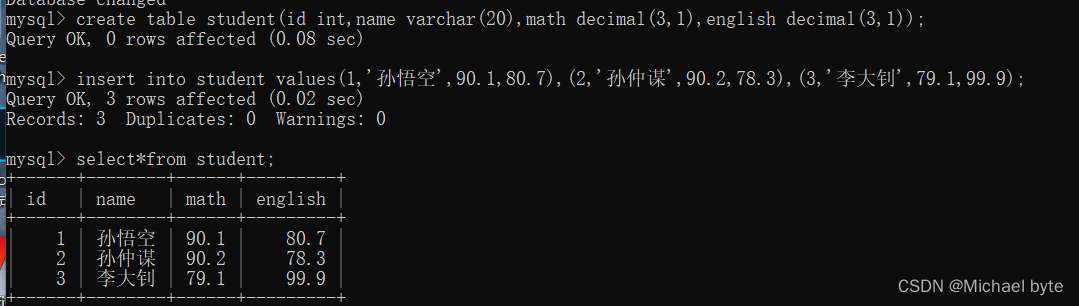
select 列名 ,表达式如(列名+列名+列名)as +别名+from +表名

针对列名的去重查询:
select +distinct+列名 +from +表名
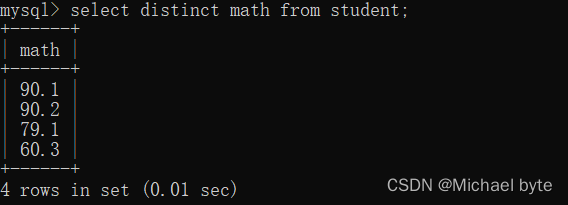
对所有行的数学成绩的数据进行去重查询
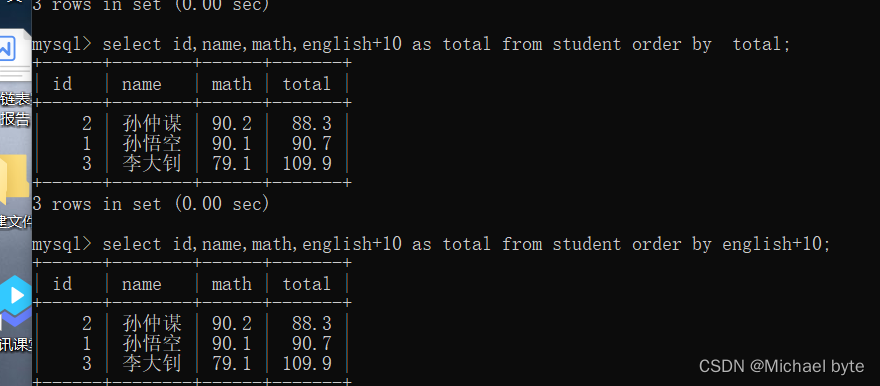
针对查询的结果进行排序
select*/列名、列名、列名/from +表名+order by+列名/表达式/别名 根据列名升序排序

select*/列名、列名、列名/from+表名+order by+列名/表达式/别名+desc 根据列名降序排序
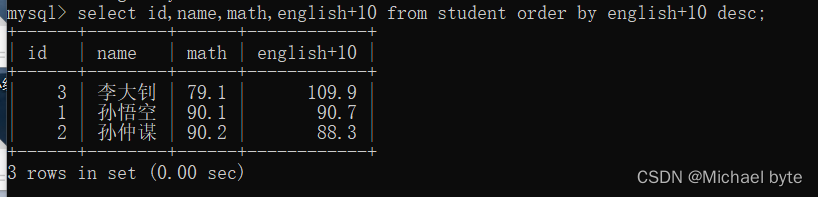
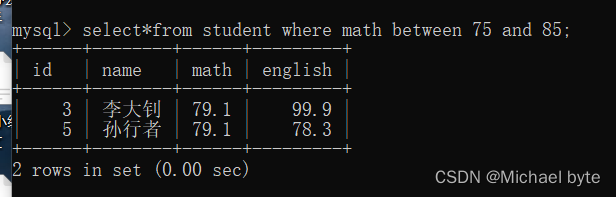
where 条件查询:
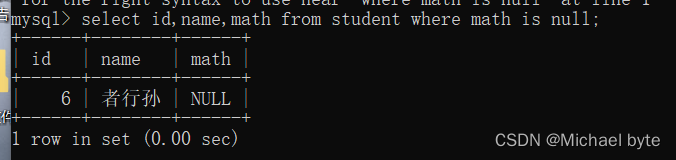

between ..... and ......表示数据范围
in(数据,数据,数据)

is null/is not null/


= 和<=>
使用=来比较某个值和null的相等关系,结果仍然是null,null又会被当成false,但是如果使用<=>例如
null<=>null其结果返回true

Like
模糊匹配:%表示任意多个包括0个字符,_表示任意一个字符,__表示任意两个字符
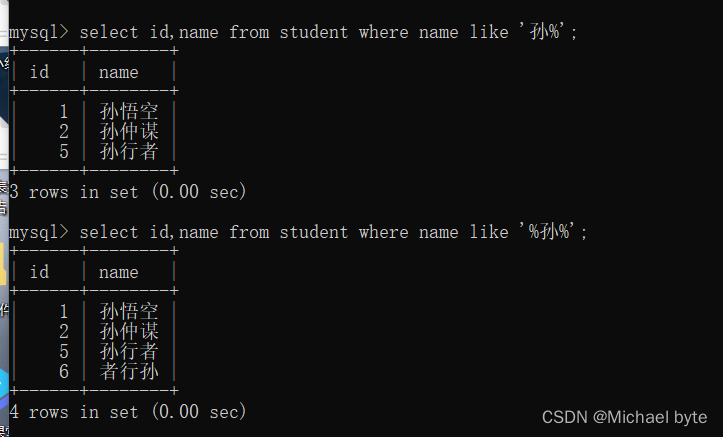
像第一个 where 语句则表示只要姓名的第一个字符 是孙,后面的是任意值都可以,而第二个where语句则表示只要名字里有一个孙字就可以。

‘孙_’ 则表示姓名里第一个是孙,第二个是任意字符。‘孙__’表示第一个字符时‘孙’,第二个和第三个字符是任意字符,第三个则表示姓名的第一个和第二个字符是任意字符,第三个字符是孙。
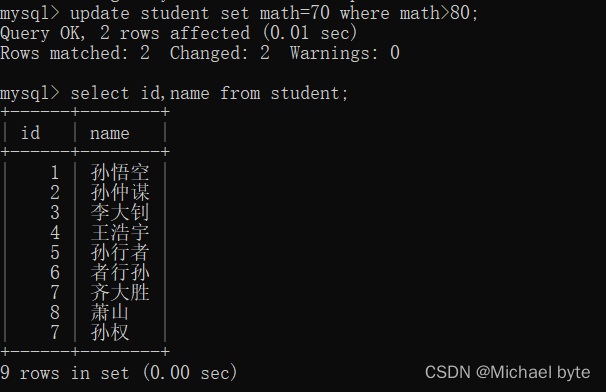
表的修改
update +表名+set +列名= ,列名=, where条件/order by/limit
表的某一行的删除:
delete from +表名+where 语句/order by/limit;
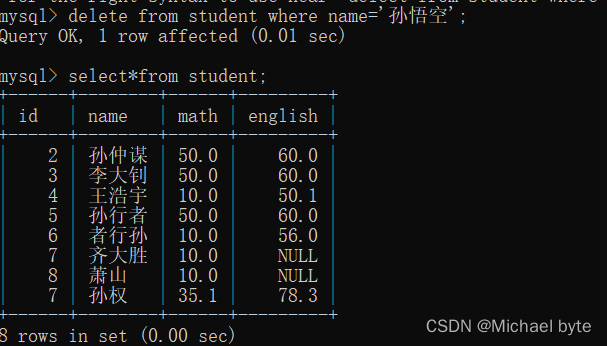
表的删除:drop +table+表名 ;
四.数据库约束
1.not null 指定列不能存储为空的数据


2.unique 表示同一列不能插入相同的数据

3.default 当不插入数据时的默认值

4.primary key 主健 相当于 not null 和 unique

在实际中,大部分的表一般会自带有一个主键往往是一个整数表示的id,一个表里只能有一个主键。
自增主键
primary key auto_increment
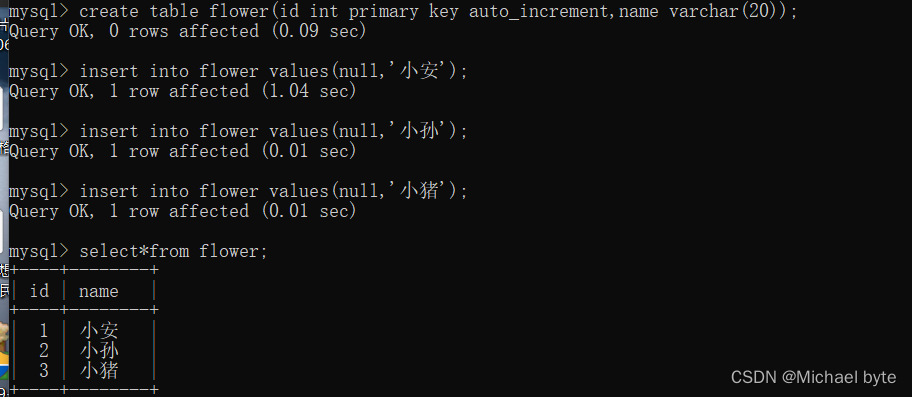
自增主键
可以手动指定,这样比较麻烦,也可以让mysql帮我们生成,写null,注意这里并不是给id赋值给null,而是交给数据库使用自增主键。
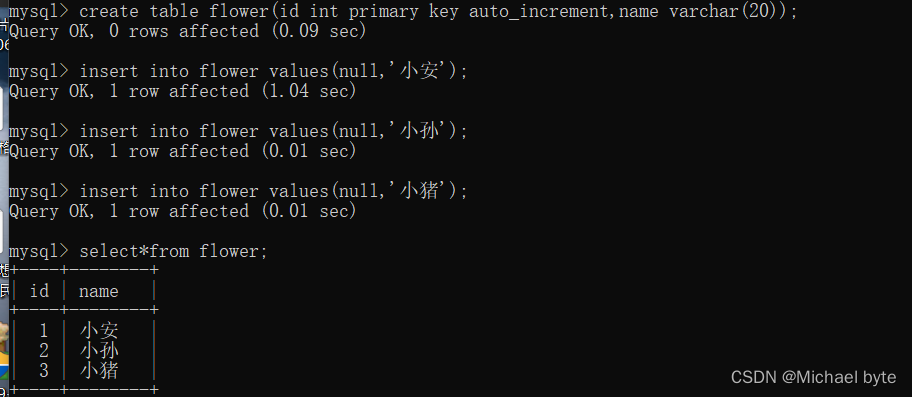
我们可以看到每次id的值都自动加1。
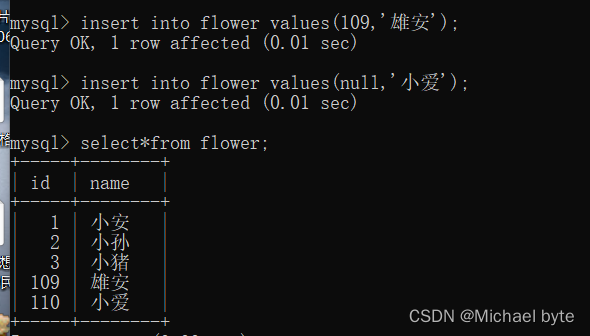
这时我们再添加一行数据,我们自己指定id为109 ,然后我们再插入一行数据,使用null,这时数据库会使用自动主键,自动加1,这时是在109的基础上加1,而不是在3的基础上加1.
5.foreign key
使表中的数据保证在另一个表中。

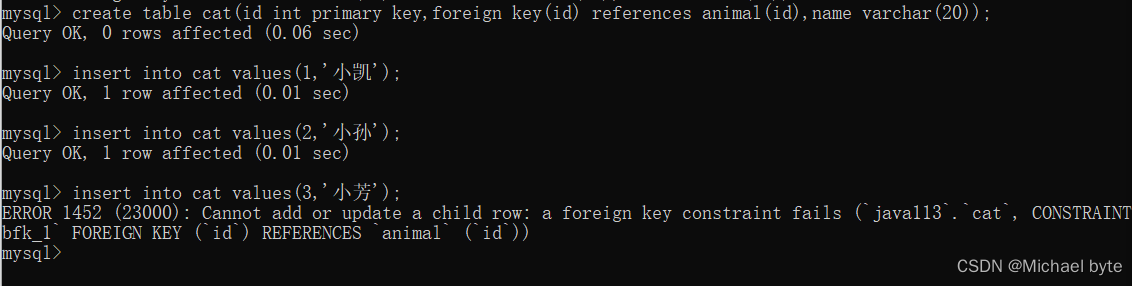
像我们再创建第二个表cat 时,在id 后面时我们增加了 foreign key(id) references animal(id),这句的意思是指 cat表里的id 值必须是animal 里面的id值,
因此我们往cat 表里增加id 的值是1,是2都可以但是不能为3.
外键(Foreign Key)是用于建立关系型数据库中表与表之间的关联关系的一种约束。外键定义了一个表中的一列(或多列),该列的值必须在另一表的主键(或唯一键)中存在。
外键的作用主要有以下几个方面:
-
维护数据完整性:外键可以确保表与表之间的关联数据的完整性。它定义了一个引用关系,确保在涉及两个表的操作中,只能插入、更新或删除相关联的数据,以避免数据不一致或冲突。
-
建立关系:外键用于建立表与表之间的关系,可以模拟现实世界中的各种关系,如一对一、一对多或多对多关系。通过外键,我们可以在不同的表之间建立联系,并使用这些关系进行数据查询和操作。
-
数据一致性:外键可以确保数据在相关联的表之间保持一致。当在主表中进行更新或删除操作时,外键会自动触发相应的操作来维护关联表中的数据一致性。
-
查询优化:外键可以提高查询性能。它允许数据库系统在处理查询时使用关联表之间的索引,从而加快查询速度。外键还可以帮助优化查询计划,以更有效地执行查询操作
如果一个表被其他表的外键关联,那么主表中的数据通常不能随意删除。这是因为外键约束确保了数据的引用完整性,即在关联表中存在引用主表数据的外键值。当试图从主表中删除一条记录时,数据库会检查是否有其他表中的外键引用了该记录。如果存在外键引用,数据库通常会拒绝删除操作,以避免数据不一致性。如果想要删除主表中的记录通常需要先删除引用该记录的其他表中的外键,或者通过指定外键的级联动作来自动更新或删除相关行。
MySQL 提供了几种级联操作选项,可以在创建外键约束时定义。常见的级联操作选项包括:
- CASCADE(级联删除或更新):当主表的记录被删除或更新时,MySQL 将自动删除或更新关联表中的相应行。
- SET NULL(设置为 NULL):当主表的记录被删除或更新时,MySQL 将自动将关联表中的外键设为 NULL。
- NO ACTION(无操作):如果存在关联的外键,MySQL 将拒绝对主表的删除或更新操作。
1.级联删除
-- 创建订单表
CREATE TABLE orders (
id INT PRIMARY KEY,
order_number VARCHAR(20)
);
-- 创建订单项表,并设置外键约束
CREATE TABLE order_items (
id INT PRIMARY KEY,
order_id INT,
item_name VARCHAR(100),
FOREIGN KEY (order_id) REFERENCES orders(id) ON DELETE CASCADE
);
-- 当删除订单时,关联的订单项将被自动删除
DELETE FROM orders WHERE id = 1;2.使用设置为null
- 创建订单表
CREATE TABLE orders (
id INT PRIMARY KEY,
order_number VARCHAR(20)
);
-- 创建订单项表,并设置外键约束
CREATE TABLE order_items (
id INT PRIMARY KEY,
order_id INT,
item_name VARCHAR(100),
FOREIGN KEY (order_id) REFERENCES orders(id) ON DELETE SET NULL
);
-- 当删除订单时,关联的订单项的外键将被设置为 NULL
DELETE FROM orders WHERE id = 1;3.使用 NO ACTION
- 创建订单表
CREATE TABLE orders (
id INT PRIMARY KEY,
order_number VARCHAR(20)
);
-- 创建订单项表,并设置外键约束
CREATE TABLE order_items (
id INT PRIMARY KEY,
order_id INT,
item_name VARCHAR(100),
FOREIGN KEY (order_id) REFERENCES orders(id) ON DELETE NO ACTION
);
-- 当删除订单时,如果有关联的订单项存在,将拒绝删除操作
DELETE FROM orders WHERE id = 1;五.聚合函数
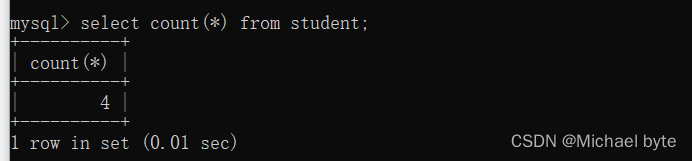
1.count
count( )返回查询到的数据的数量

计算全列时,列为空值也算一行
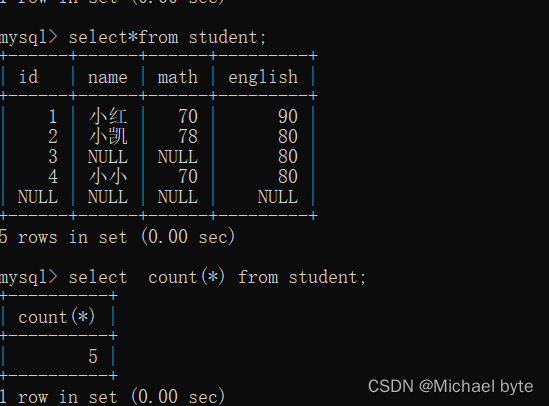
计算某一具体列时,null则不算

因为name 和math 这一列分别有一个null,所以为3.
sum() 返回查询到的数据的和

null的值不加上。
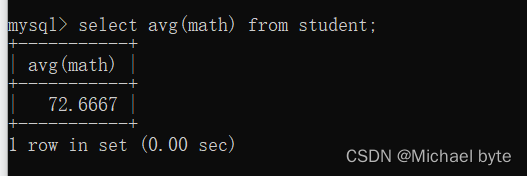
avg() 返回查询到的数据的平均值
max() min()返回查询到的数据的最大值、最小值

六.group by 子句,先分组然后 进行聚合函数运算

where+条件 表示的时候先将不符合条件的数据剔除,然后再分组进行聚合运算
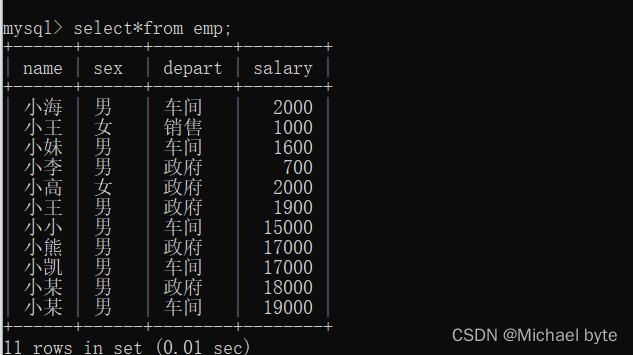
例如 我们求一个性别为男的每个车间的薪资总额
像这个我们就需要先用where语句将女性剔除,然后分部门求每个部门的薪资总额

having +条件 先分组进行聚合运算,然后再将不符合条件的组去除
例如:我们求一下部门的薪资总额大于37600的部门,这样的话我们先分组求每个部门的薪资总额然后将薪资总额低于37600的部门去除

七.联合查询
将多个表合在一起:
例如:我们查一下许仙同学的成绩,那我们需要将学生表合成绩表合在一起

将这两个表组合在一起,相当于全排列,一共有8*9=72条数据。这是部分截图

但我们知道这样存在很多无效的数据,我们需要加条件,将有小效数据筛选出来。
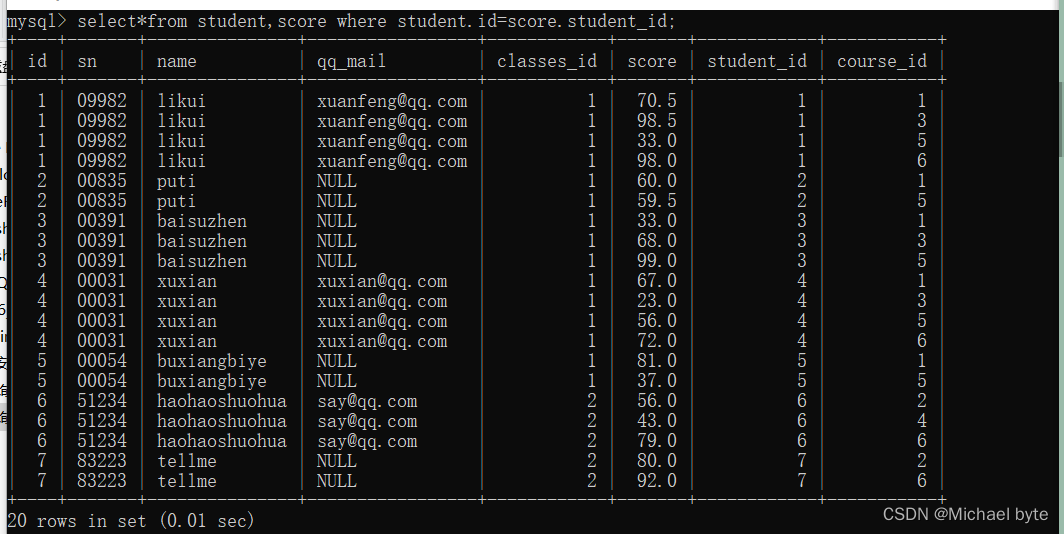

例如我们求一下每个同学的成绩

第二种写法和第一种写法相同。
以上的连接属于内连接。
外连接:
1.左外连接--- select 字段+表名+left+join+表名+ on+连接条件
1.右外连接----select 字段+表名+right+join+表名+on+连接条件
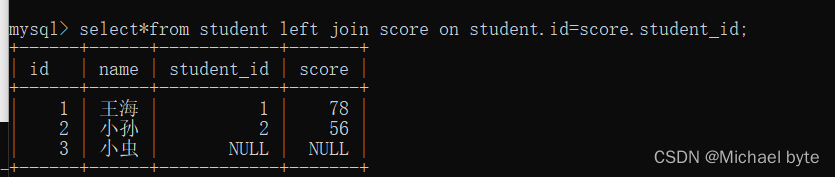
而如果数据之间不存在一 一对应的关系 ,如
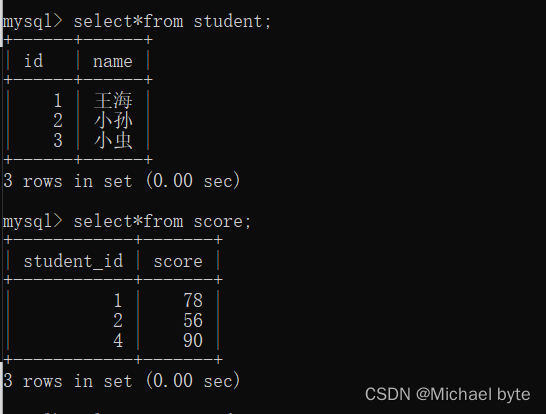
像这两张表中,学生表中id=3的学生在分数表中不存在,而分数表中student_id=4的学生在学生表中不存在,两张表并不是一一对应的关系。将两张表里联合找有效数据只会展现一一对应的数据。
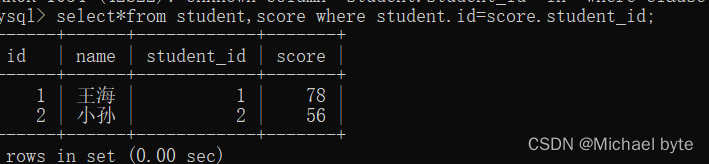
但是如果我们想在这张表中将student中的信息全部展现出来,这时我们可以用左外连接的方式,
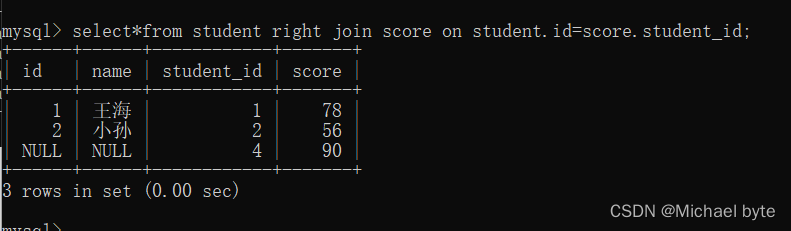
如果我们想将score表中的信息全部展现出来,我们用右外连接的方式
内外连接的区别:
内连接(Inner Join):
- 内连接返回匹配两个表之间关联条件的行。
- 只有当连接条件匹配时,才会返回结果。
- 结果集中只包含符合连接条件的行。
- 如果其中一个表中的行没有匹配的对应行,它将被排除在结果集之外。
外连接(Outer Join):
- 外连接返回匹配关联条件的行以及未匹配的行。
- 当连接条件匹配时,返回匹配的行;当连接条件不匹配时,对于左外连接(Left Outer Join),返回左表的行,并在右表中使用 NULL 值填充; 对于右外连接(Right Outer Join),则返回右表的行,并在左表中使用 NULL 值填充。
- 结果集中可能包含 NULL 值,表示没有匹配到的数据
六.自连接
自己和自己进行笛卡尔积,自连接的效果是把行转成列。
例如我们查询一下java成绩比计算机原理成绩高的学生信息,行与行之间没法进行比较。
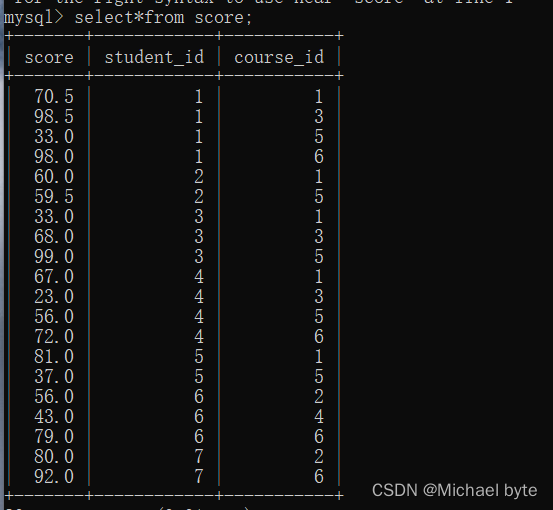
我们需要进行自连接
注意在进行自连接时我们需要对 表名起个别名,否则会报错。

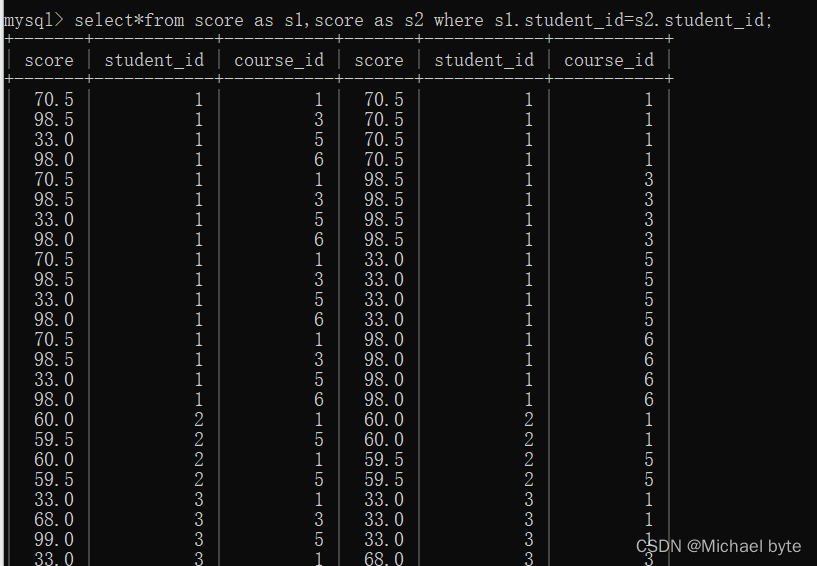
java为course_id=3,计算机原理为course_id为1,因此我们再加上条件进行筛选就可以了。

七.子查询
子查询本质就是套娃
单行子查询 :返回一条记录 用=
例如:查询与"不想毕业''同学的同班同学;

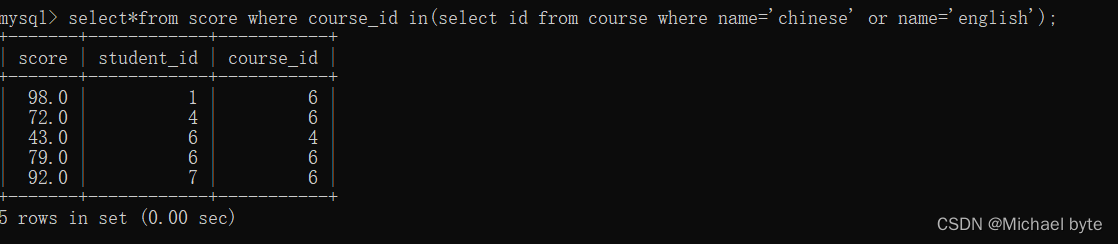
多行子查询:返回多行记录的子查询 用 in
例如查询'语文'或英文的课程的成绩信息
八. 合并查询:将两个查询的结果集合并成一个,要求这两结果集的列相同。可以是两个相同的表,也可以是两个不同的表
两个表用union 或union连接
union 会对结果去重(重复的只保留一行)
union all 不去重
例题:查询i课程d 小于3,或者名字为‘java’或者‘math’的课程。

九. Mysql如何分库分表
分库分表的时机:
1.前提:项目业务数据逐渐增多,或业务数据发展比较迅速,单表数据量达1000w或20G以后
2.优化已经解决不了性能问题
3.IO瓶颈(磁盘IO、网络IO)、CPU瓶颈(聚合查询、连接数太多)
Mysql分库策有四种:
1.水平分库:将一个库的数据拆分到多个库中,解决海量数据存储和高并发问题
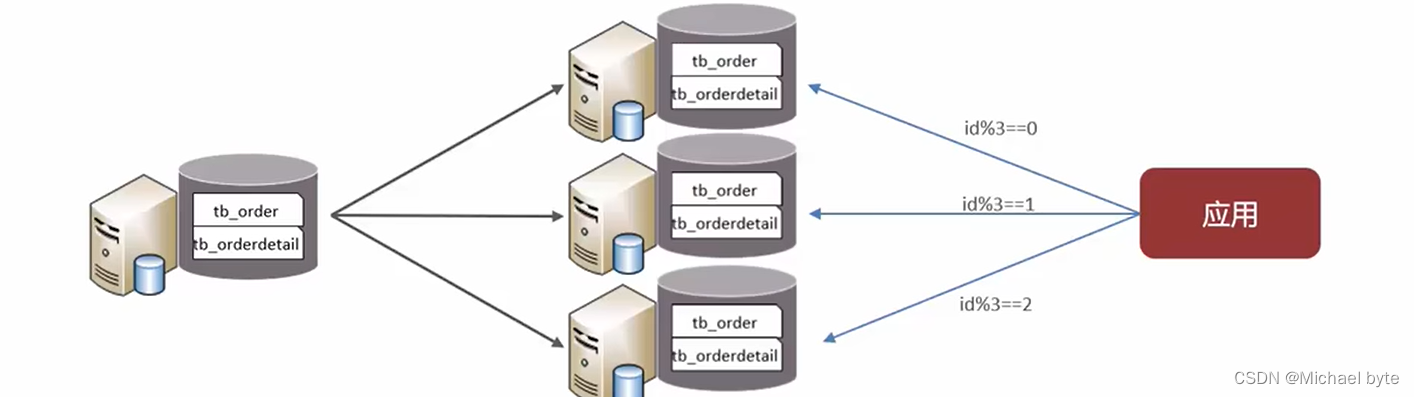
特点:
(1)解决了单库大数量、高并发的性能瓶颈问题
(2 提高了系统的稳定性和可用性
2.水平分表:解决单表存储和性能的问题

特点:
(1)优化单一表数据量过大而产生的性能问题
(2)避免IO争抢并减少锁表的概率
3.垂直分库:根据业务进行拆分,高并发下提高cipanIO和网络连接数
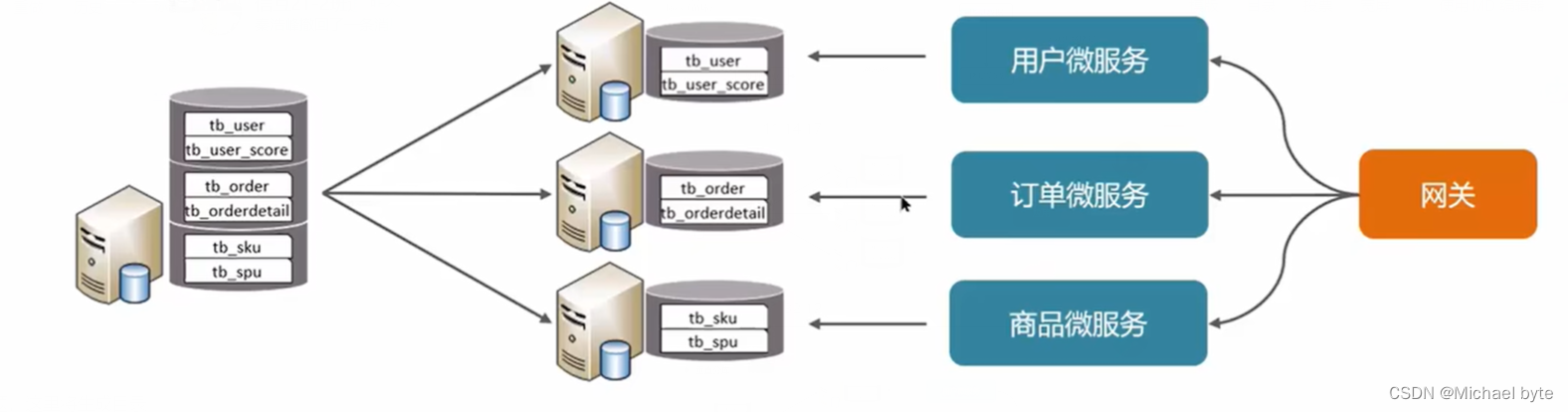
特点:
(1) 按业务对数据分级管理、维护、监控、扩展
(2)在高并发情况下,提高磁盘IO和数据量连接数
4.垂直分表
拆分规则:把不常用的字段单独放在一张表中

特点:(1)冷热数据分离
(2)减少IO过渡争抢,两表互不影响
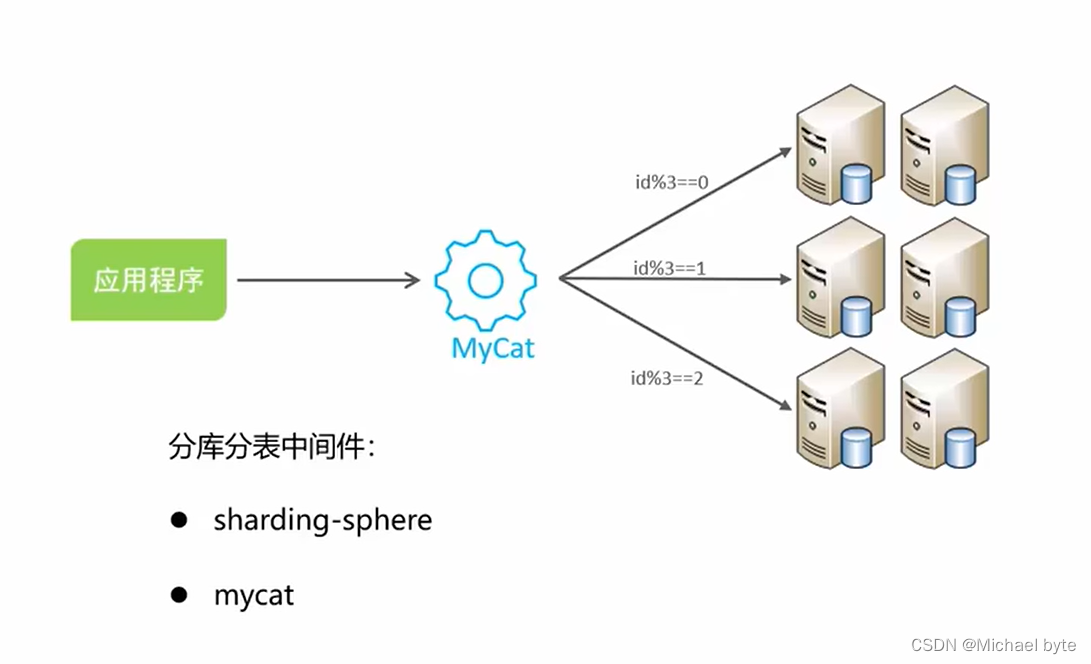
分库之后带来的问题:
(1)分布式事务一致性的问题
(2)跨节点关联查询
(3)跨节点分页、排序函数
(4)主键避重
为了解决问题,可以用一些中间件来处理















 962
962











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









