






一.双写一致性:
含义:当数据库中的数据被修改了以后,我们也需要同时修改缓存,使缓存和数据库的数据保持一致

(1)读操作:当请求发来的时候,先去看redis里面是否有对应的数据,如果有直接返回,如果没有则去查看数据库,并把数据库里的结果存储到redis里面,然后再返回
(2)写操作:采用延迟双删
为啥要用延迟双删的策略?先删缓存,再修改数据库行不行?
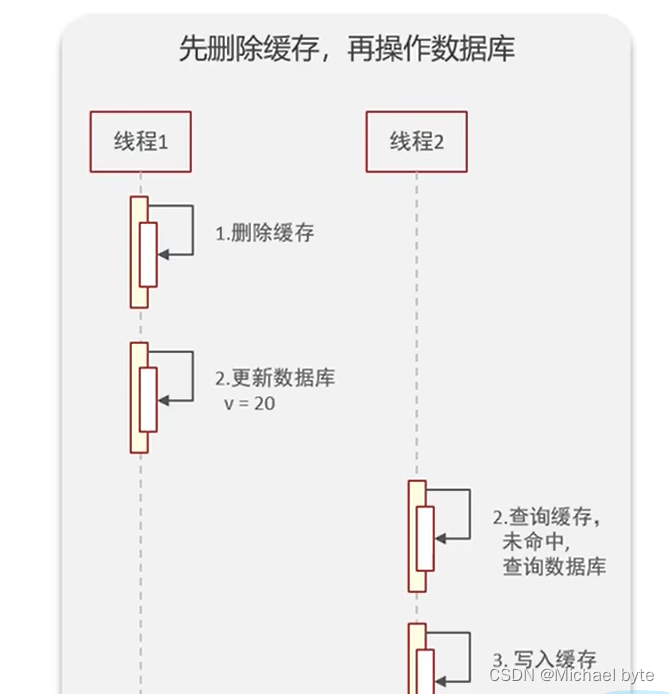
如果像这种情况,线程1先清空缓存,假设以前的缓存v=10,然后更新数据库 v=20,然后线程2去缓存里查v这条数据,发现没有就去数据库里查看,发现此时v=20,则把v=20写入了缓存

但是如果像这种情况,线程1先删除缓存,假设当前缓存中v的值为10,然后线程2去缓存中查看v,缓存中没有,则去看数据库,数据库当中v的值为10,读取出来以后写入到了缓存,然后线程1更新数据库当中v的值为20,这时就出现v的值在缓存中和数据中不一致的情况
那可不可以是先更新数据库,然后再删缓存呢?
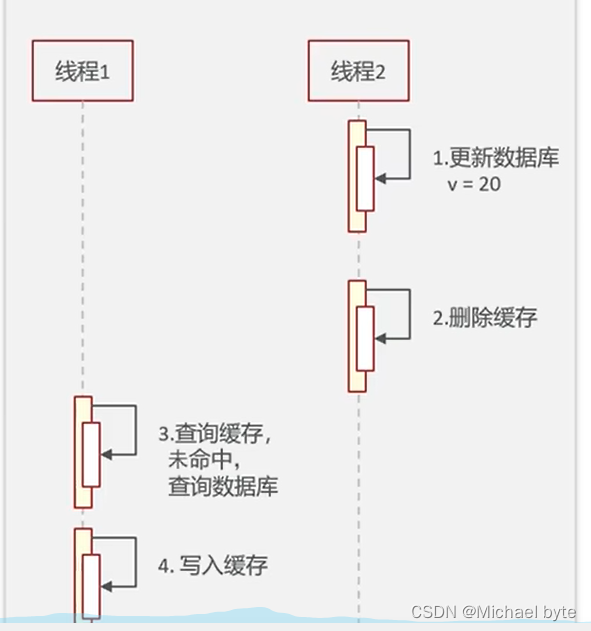
如果是这种情况是可以的,但是如果是下面这种情况
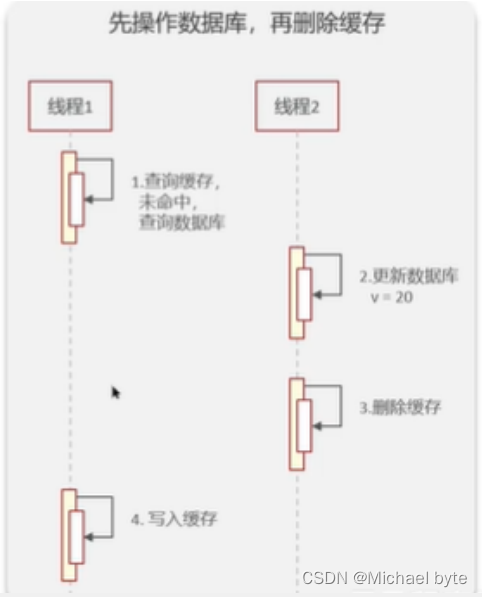
假设线程1在查找v的值的时候,此时缓存中的值恰好过期了,那么线程1就会去数据库里读取到v=10,这时线程2更新数据库把v的值改为20,然后删掉了缓存,此时线程1再去把它读到的v的值也就是10写入了缓存,这时这时就出现v的值在缓存中和数据中不一致的情况。
因此,我们采用了删除缓存-修改数据库-延时 删除缓存的策略

为啥要延时呢?因为数据库有主库和从库,主库同步到从库需要时间,但是即使采用双删的策略
也并不能完全解决会出现脏数据的风险。
那如何解决呢?
我们可以利用Redisson提供的读写锁
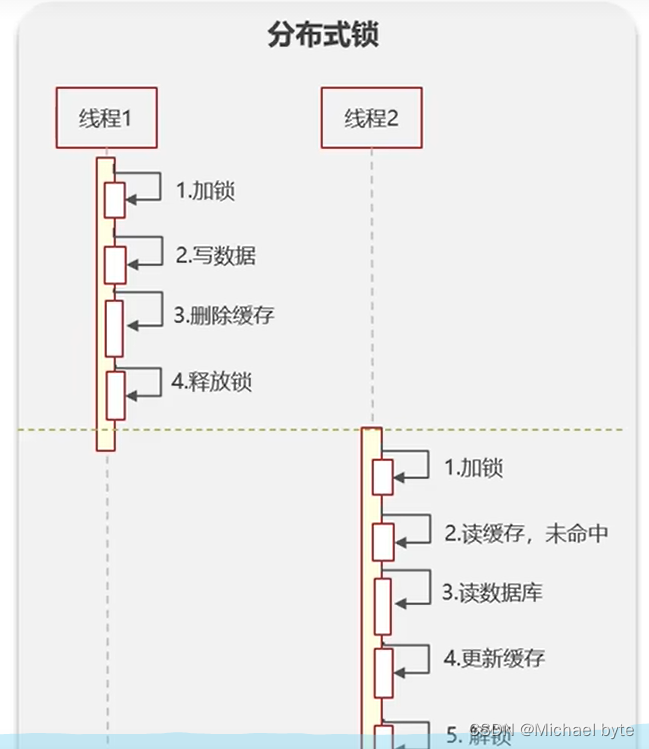
当线程去读取数据的时候会加读锁,加锁之后,其他线程可以共享读操作。当线程进行写的时候会加写锁,阻塞其他线程读写操作,因为缓存中的数据大都是读多写少的场景,采用读写锁,既可以保证数据的强一致性,也能提高并发的性能
加读写锁的适应于强一致性的业务,对于允许延时一致的业务,我们还可以用 异步通知的方式
异步通知的方式有两种:
一种是使用MQ 的中间件,更新数据之后,MQ通知缓存删除
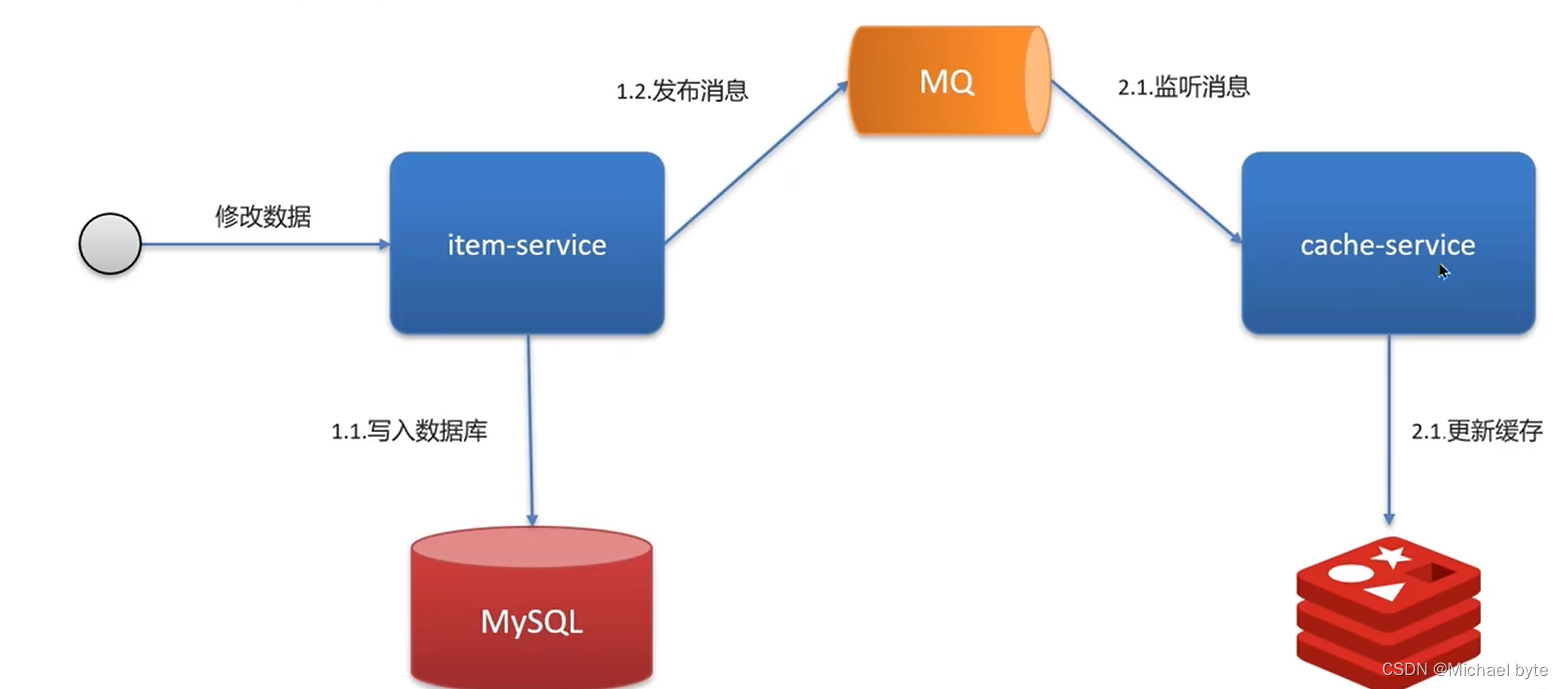
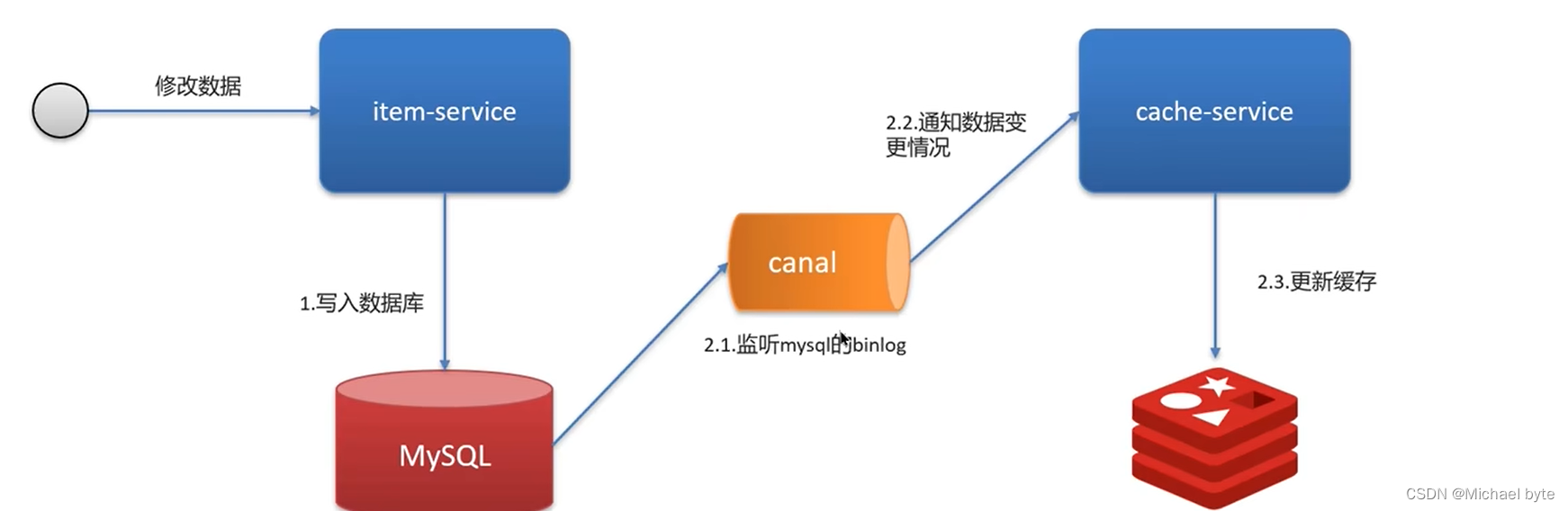
第二种是利用canal中间件,我们不需要修改业务代码,伪装为mysql的一个从节点,canal通过读取binlog数据更新缓存
二.Redis的持久化机制
Redis的持久化方式只要有两种:RDB和AOF
1.(1)含义:
RDB也叫做Redis的数据快照,简单来说就是把内存中的所有数据记录到磁盘当中,当Redis实例故障重启后,从磁盘读取快照文件,恢复数据。
(2)RDB的执行原理:

Redis内部有触发RDB的机制,可以在redis.conf文件中找到

bgsava开始时会fork进程得到子进程,子进程共享主进程的内存数据,完成fork后读取内存数据并写入RDB文件,fork采用的是copy-on-write技术
当主进程执行读操作的时候,访问共享内存
当主进程执行写操作的时候,则会拷贝一份数据,执行写操作
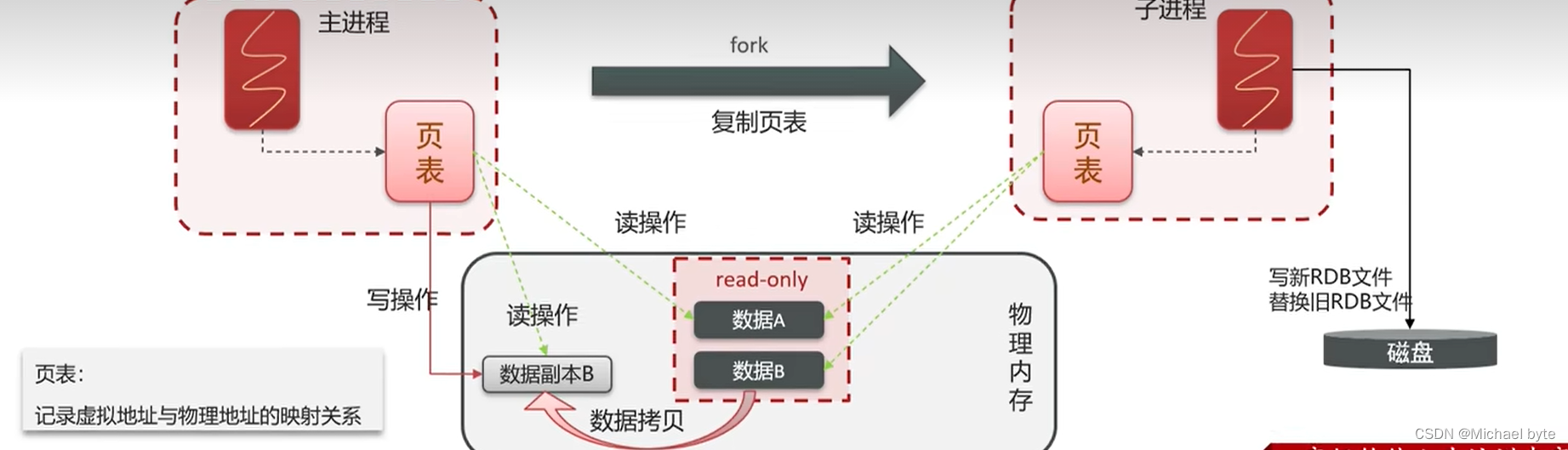
当我们直接去访问修改物理内存 数据的时候是没有办法直接修改的,需要通过虚拟地址映射到物理地址间接访问,而页表则是记录虚拟地址与物理地址的映射关系的,主进程会fork一个子进程并复制页表一份给子进程,当进行读操作的时候,会设置为read-only,当进行写操作的时候会拷贝数据的副本,然后再数据的副本进行修改,子进程也会写新的RDB文件,来替换磁盘当中旧的RDB文件。
2.AOF
(1)含义:
AOF也叫追加文件,Redis处理的每一个写命令都会记录在AOF文件,可以看做是命令日志文件
(2)执行流程
AOF 文件记录了 Redis 所有的写命令,当 Redis 宕机,会逐条执行redis中的写命令,也可以根据 AOF 文件恢复数据。
AOF默认是关闭的,需要修改redis.conf配置文件开启AOF

AOF的命令记录的频率也可以通过redis.conf文件来配置:


因为是记录命令,AOF文件会比RDB文件大很多,而且AOF会记录对同一个key的多次写操作,但是最后一次写操作,通过执行bgrewritead命令。可以让AOF文件执行重写功能,用最少的命令达到相同结果。


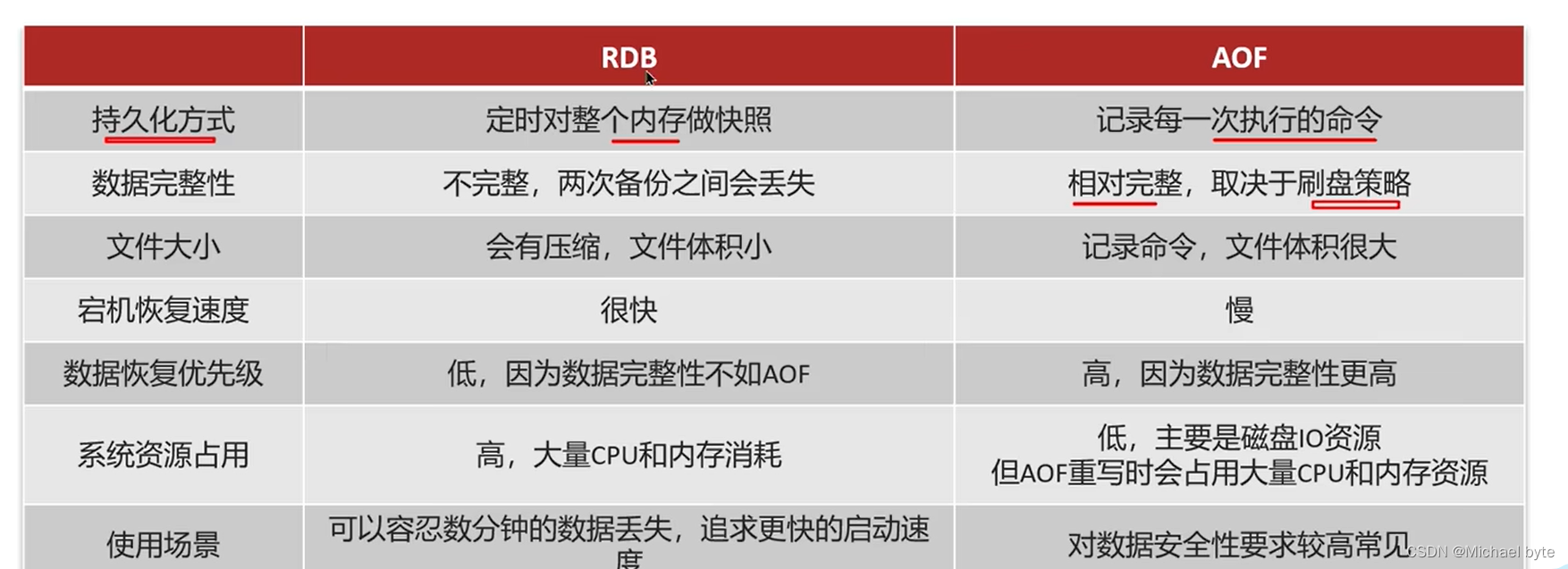
3.RDB和AOF的区别:
三.数据的淘汰策略
含义:
当Redis中的内存不够的时候,此时向redis添加新的key,那redis就会按照某一种规则将内存中的数据删除掉,这种数据的删除规则被称为内存的淘汰策略
Redis支持8种不同策略来选择要删除的key
(1)noeviction:不淘汰任何key,但是内存满时不允许写入新数据,默认就是策略
(2)volatile-ttl:对设置了TTL的key,比较剩余的TTL值,TTL越小越先被淘汰
(3)allkeys-random :对全体的key,随机进行淘汰
(4)volatile-random:对设置了TTL的key,随机进行淘汰
(5)allkeys-lru:对全体key,基于LRU算法进行淘汰
(6)volatile-lru:对设置了TTL的key,基于LRU算法进行淘汰
(7)allkeys-lfu:对全体key,基于LFU算法进行淘汰
(8)volatile-lfu:对设置TTL的key,基于LFU算法进行淘汰
LRU:最近最小使用,先淘汰最后一次访问的
LFU:最小频率使用,统计每个key的访问频率,值越小淘汰优先级越高
数据淘汰策略的面试问题:
(1)数据库有100万数据,Redis只能缓存20w数据,如何保证Redis中的数据都是热点数据?
使用allkeys-lru策略,淘汰最近最少使用的数据,留下的都是经常访问的热点数据
(2)Redis的内存用完了会发生什么
主要看数据淘汰策略是什么?如果是默认的配置会直接报错
四.Redis分布式锁
1.分布式锁的使用的场景:
集群情况下的定时任务、抢单、幂等性场景
Redis实现分布式锁主要是利用Redis的setnx命令

 下面是获取锁的具体流程图:
下面是获取锁的具体流程图:
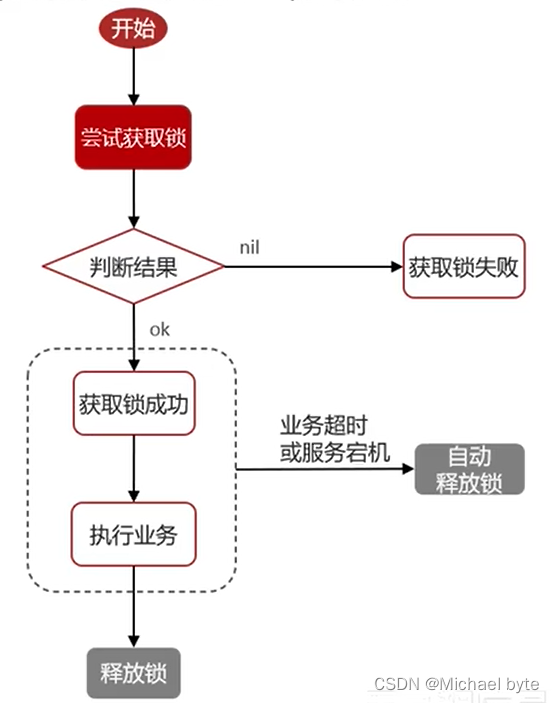
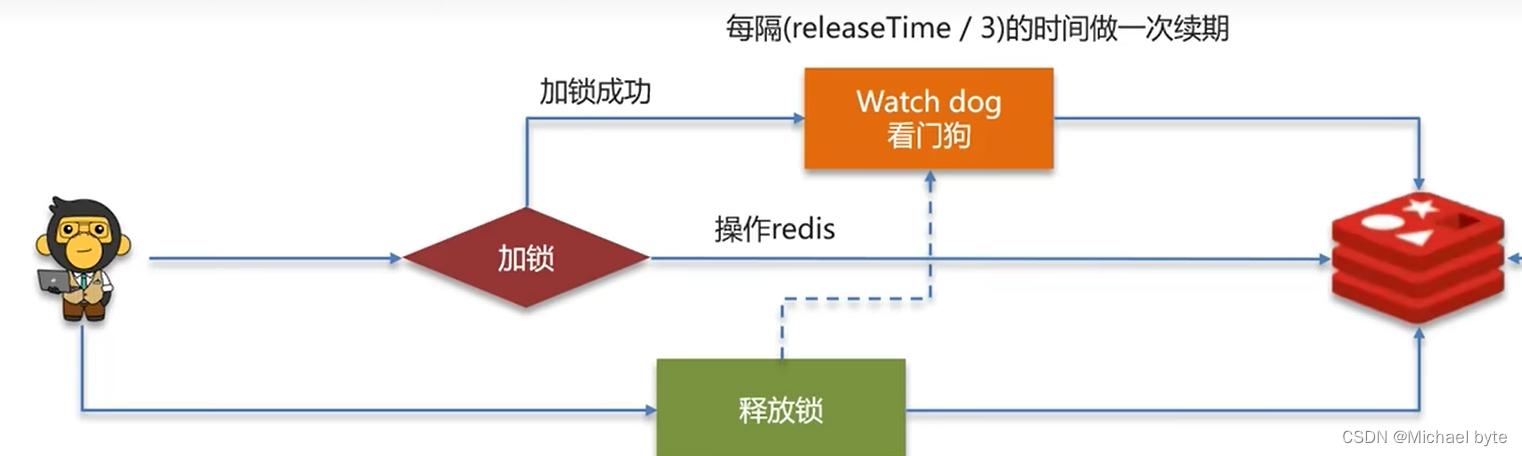
这里存在一个问题:当服务宕机的时候会自动释放锁,但是如果我们的业务还没有执行完咋办?我们还得重新加锁
为了解决这个问题,我们引入了“看门狗”对锁进行续期


2.Redisson的可重入锁
可重入锁是如何实现的呢?
我们先来看一段代码

当线程1调用add1()获取名称为heimalock的锁 ,然后又调用add2()方法,再次加heimalock,能成功加上,说明是可重入锁,那是如何实现的呢?其实是利用hash结构来实现的,key是锁,value的field是线程,value是加锁的次数,当是同一个线程进行加锁,就行将value值加1,当不是同一个线程加锁的时候,则会互斥

3.Redisson实现的分布式锁可以保证主从一致性吗?
答案是:不可以
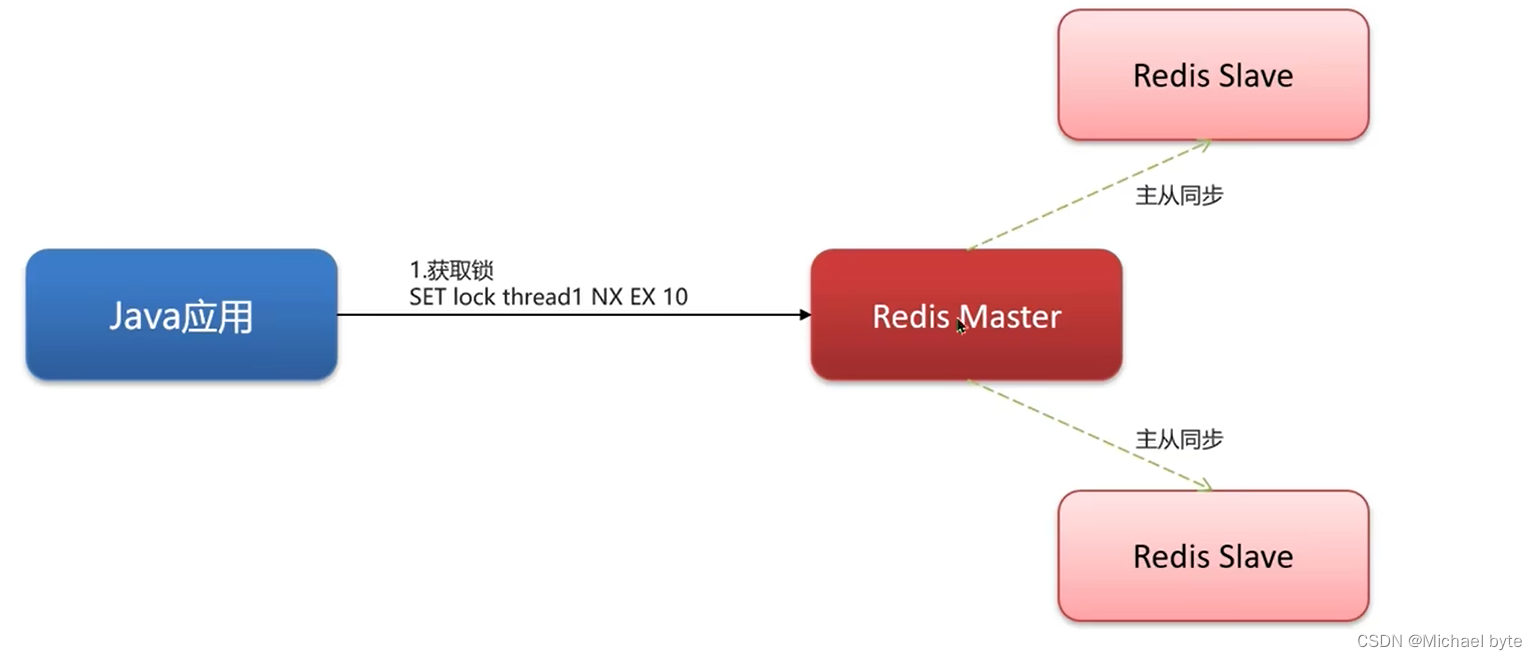
如图线程1加了锁,然后进行主从同步,但是如果主节点一旦挂了,那么根据哨兵模式从节点有一个会成为主节点,但是因为数据还没有同步过来,另一个线程再去获取锁,就会成功的加到锁,这时就会出现两个线程同时持有一把锁的情况。

为了解决这个问题:
引入了红锁:
RedLock(红锁):不只在一个redis实例上创建锁,要在多个redis实例上创建锁(n/2+1),避免
在一个redis实例上创建锁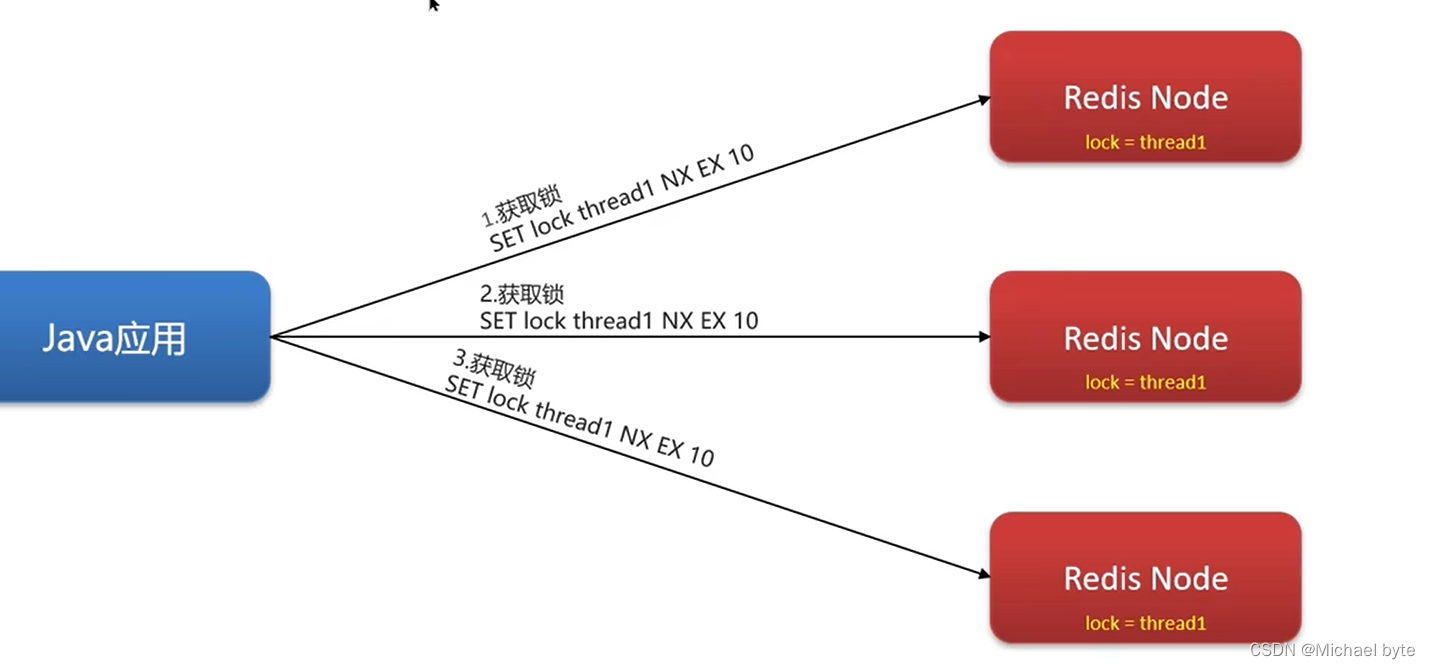
但是这种方式实现复杂,性能差,运维繁琐,如果要保证主从强一致性需要使用zookeeper

















 1934
1934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









