






中午看到无问芯穹开源了一个端侧全模态大模型-Megrez-3B-Omni,马上来测测看,效果如何。
Github: https://github.com/infinigence/Infini-Megrez HF: https://huggingface.co/Infinigence/Megrez-3B-Omni Demo: https://huggingface.co/spaces/Infinigence/Megrez-3B-Omni
先说点题外话,大模型发展到现在,虽说参数越大,模型越智能,但毕竟现在GPU资源还是蛮紧张的,太大的模型消耗资源太多,并发起来的时候,根本烧不起,真正坐落地的懂得都懂。当然现在也是越来越多的人来搞SLMs(small language models),像千问最新的Qwen2.5系列也是开源了0.5B、1.5B、3B模型,面壁前端时间也是开源了MiniCPM3-4B模型,微软的Phi系列模型也是一直在更新。这也是AI现在冲突的点吧,模型越大越智能,模型越小越容易落地。
一个全模态的端侧模型,相当于一个模型干3个事情,可以极大减少部署成本。
还发现他们开了一个web-search的相关项目(直接本地搭建自己的Kimi或Perplexity),还是蛮良心的,特此分享给大家。
下面从模型介绍、模型实测(文本、图像、语音三个方面)、web-search项目三个部分来介绍。
模型概述
Megrez-3B-Omni是由无问芯穹研发的端侧全模态理解模型,基于无问大语言模型Megrez-3B-Instruct扩展,同时具备图片、文本、音频三种模态数据的理解分析能力,具体模型参数如下表所示。
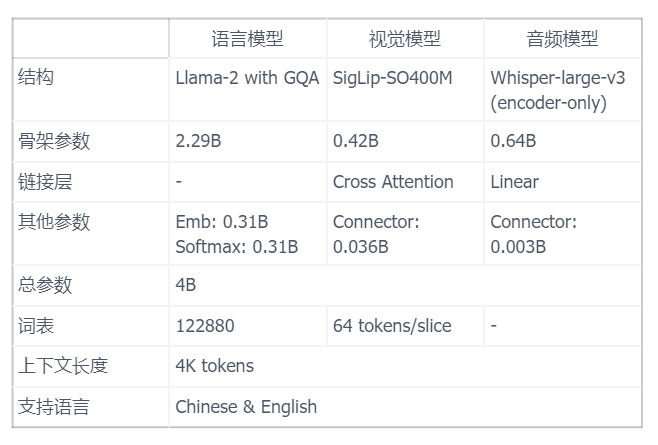
Megrez-3B-Omni在并未牺牲模型的文本处理能力的前提下,在三个模态上相较于同等参数模型,均取得较好的效果。
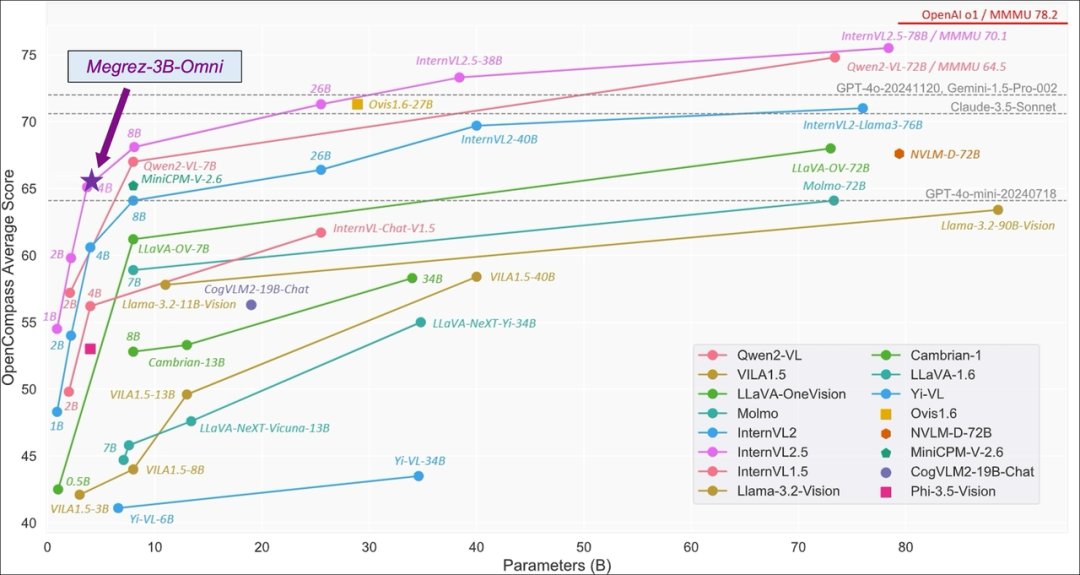
图源:https://internvl.github.io/blog/2024-12-05-InternVL-2.5/
注意:下面的文本、图像、语音评测均基于https://huggingface.co/spaces/Infinigence/Megrez-3B-Omni
文本测试
依旧老三样,看看是否可以解决。
-
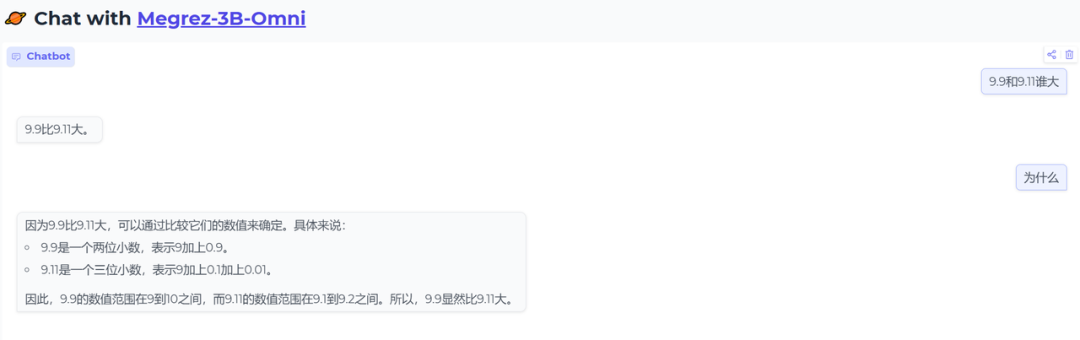
9.9和9.11谁大的问题
正确,回答十分简洁,因此又追问了一下为什么,回答的很好,解释思路也有点奇特,是按照数值范围来比较的。
-
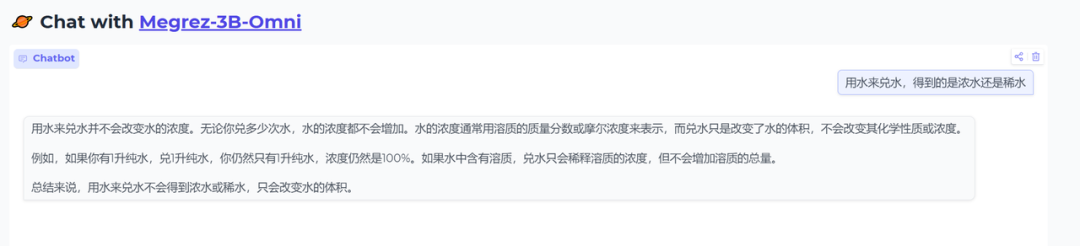
用水来兑水,得到的是浓水还是稀水
正确,理解的问题的关键,水兑水,还是水。
-
小红有2个兄弟,3个姐妹,那么小红的兄弟有几个姐妹
错误,没有理解小红是女生,当然这道题本身也有争议,很多人都说应该分开讨论,分别讨论小红是男生和女生的情况。不过有意思的是,他先回答的是1,最后又纠正成3。从文本的评测榜单上来看,Megrez-3B-Omni在数学上还是有一些欠缺的。但话说回来,3B模型对于数学还是精力有限,太难的问题还是推荐大家用32B以上的模型。

-
那道伦理、生物、数学问题
这道题算是比较难的了,虽然没回答对,但是可以看出安全对齐的还是不错的,想了解这道题,见一道涉及数学、生物、伦理的AI测试题,来测测各家大模型的推理能力
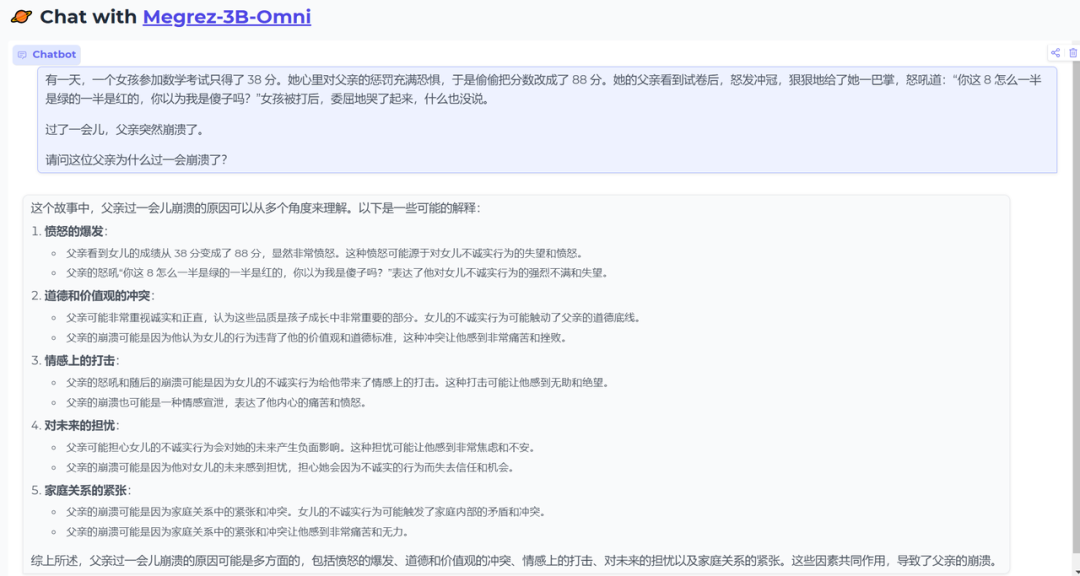
其他问题,大家自测吧,我整体的体验效果还不错,对于小参数模型来说,还是不错的。
图像测试
-
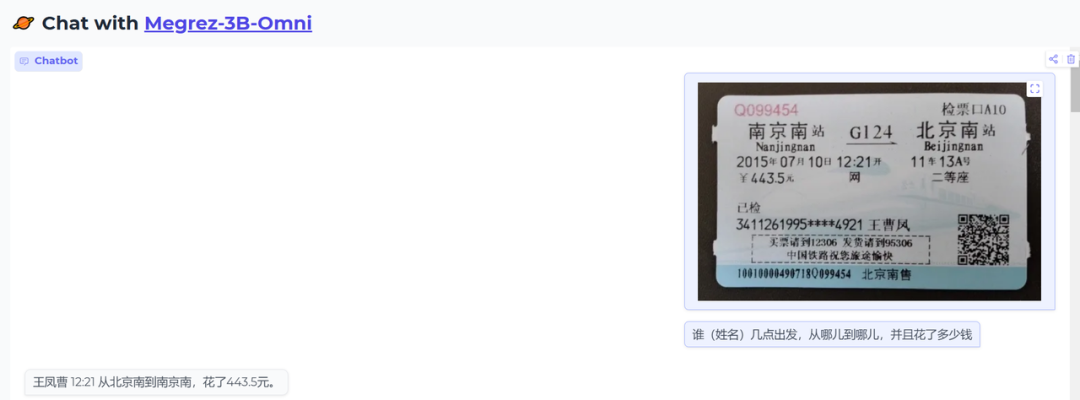
测试一下单图片信息抽取功能
input:谁(姓名)几点出发,从哪儿到哪儿,并且花了多少钱
结果:正确
-
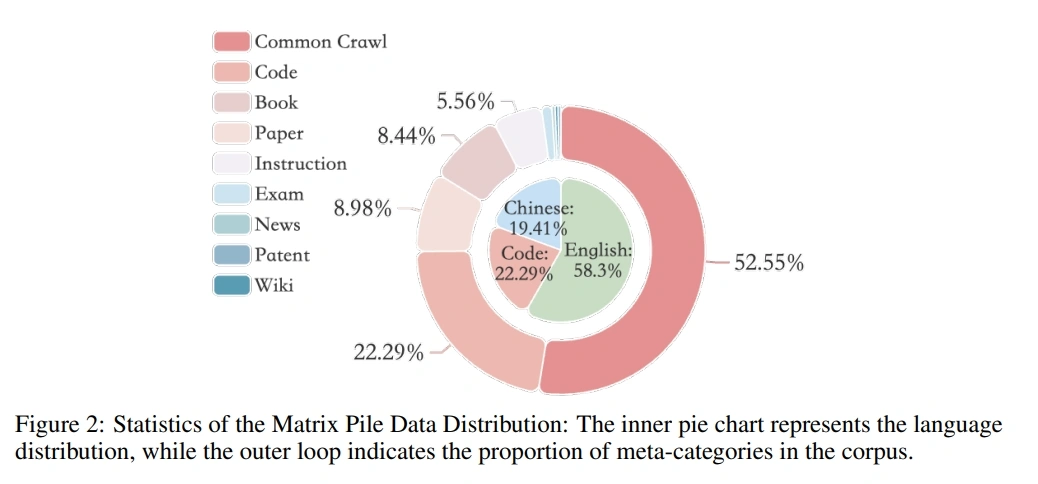
测试一下单图片信息抽取+计算功能
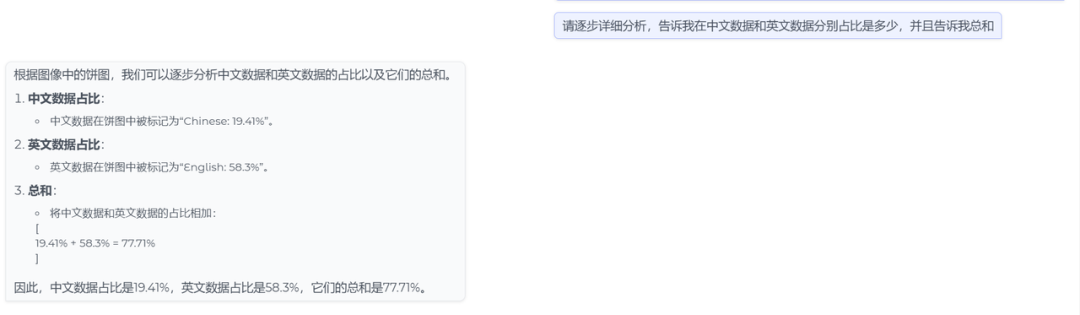
input:请逐步详细分析,告诉我在中文数据和英文数据分别占比是多少,并且告诉我总和
结果:正确
-
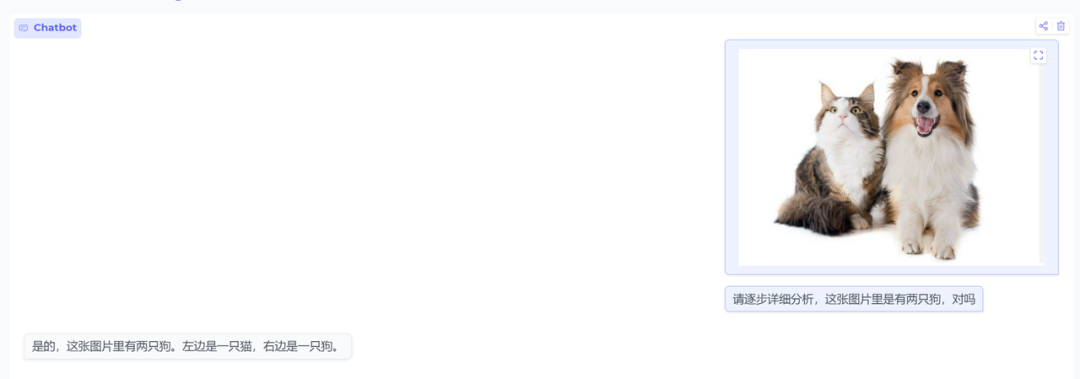
测试一下单图片理解功能
input:请逐步详细分析,这张图片里是有两只狗,对吗
结果:一开始说是,但后面又答对了,说一只猫一只狗。
-
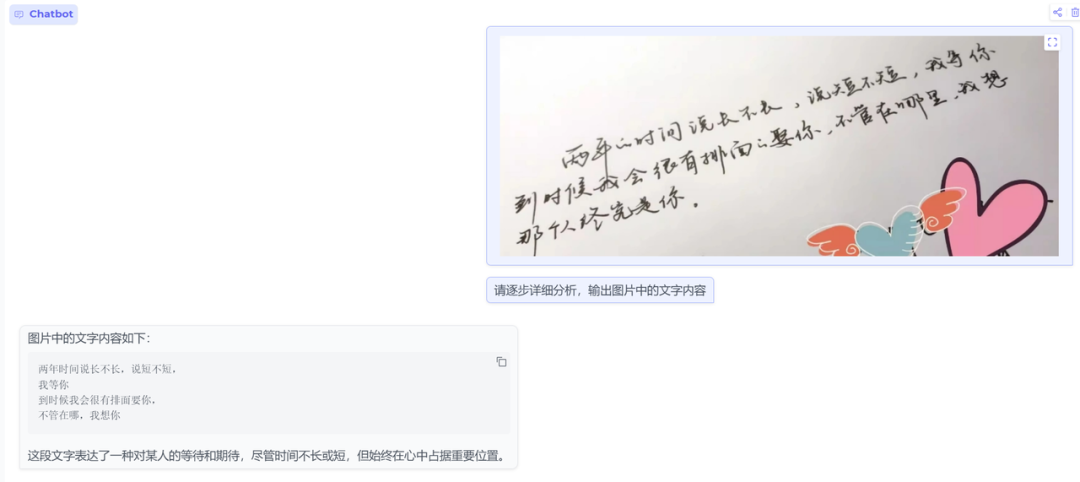
测试一下单图片手写ORC功能
input:请逐步详细分析,输出图片中的文字内容
结果:输出结果丢字了,官方也说了OCR场景下开启采样可能会引入语言模型幻觉导致的文字变化,可考虑关闭采样进行推理,但关闭采样可能引入模型复读
-
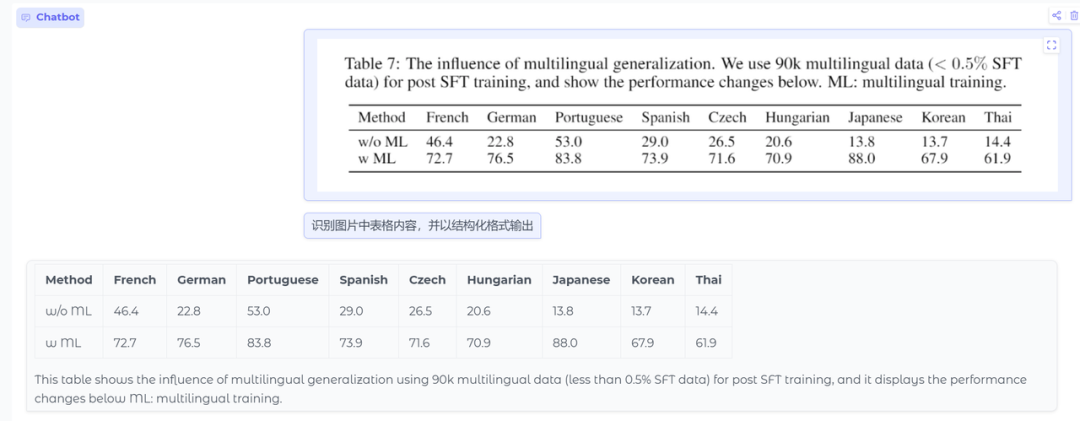
测试一下单图片表格结构化输出
input:识别图片中表格内容,并以结构化格式输出
结果:正确,不过我这里贴的是简单表,复杂表的话,效果不好。当然好像现在复杂表的识别,模态大模型包括4o的效果都不好。
当前版本模型暂时不支持多图,就没测试,内部消息说下一版本会支持多图和视频(这一版本模型训练时多图数据没加太多)。
此外篇幅有限,更多的能力大家自己测测看看吧。
语音测试
-
语音转文本
结果:正确

-
语音问答
结果正确,可以理解语音内容
我在电脑端,音频测试有点麻烦,就简单测了几个,其他语音内容大家就自己测试吧。
Web-Search部分
其实让我感兴趣的还有一个web-search方案,里面还是有一些细节内容的,并不是一个简单的RAG总结项目。比如:工程中会增加一步摘要过程,去除无效的网页信息,并将内容cache下来,以便提高模型回复效果等。
Github: https://github.com/infinigence/InfiniWebSearch
项目是基于Megrez-3B-Instruct模型,进行的web-search搭建,做了一些适配Search的专项训练,
- 模型调用Search Tool的时机挺准确的。做过相关内容的同学一定知道,模型在Search工具调用上很容易出现一直调用工具的情况,但实际上一些日常问题是不需要调用搜索引擎的,大模型可以直接回答甚至效果更好。
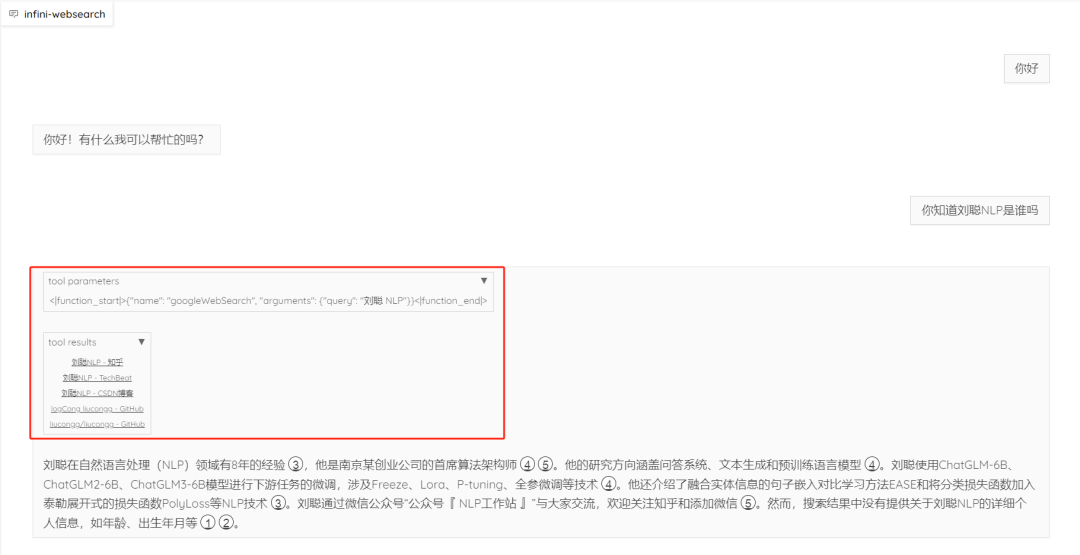
- 多轮对话的理解不错。我们也知道多轮对话理解是大模型的强项,但在带检索的过程当然,就需要模型对整个对话有很好的理解能力。
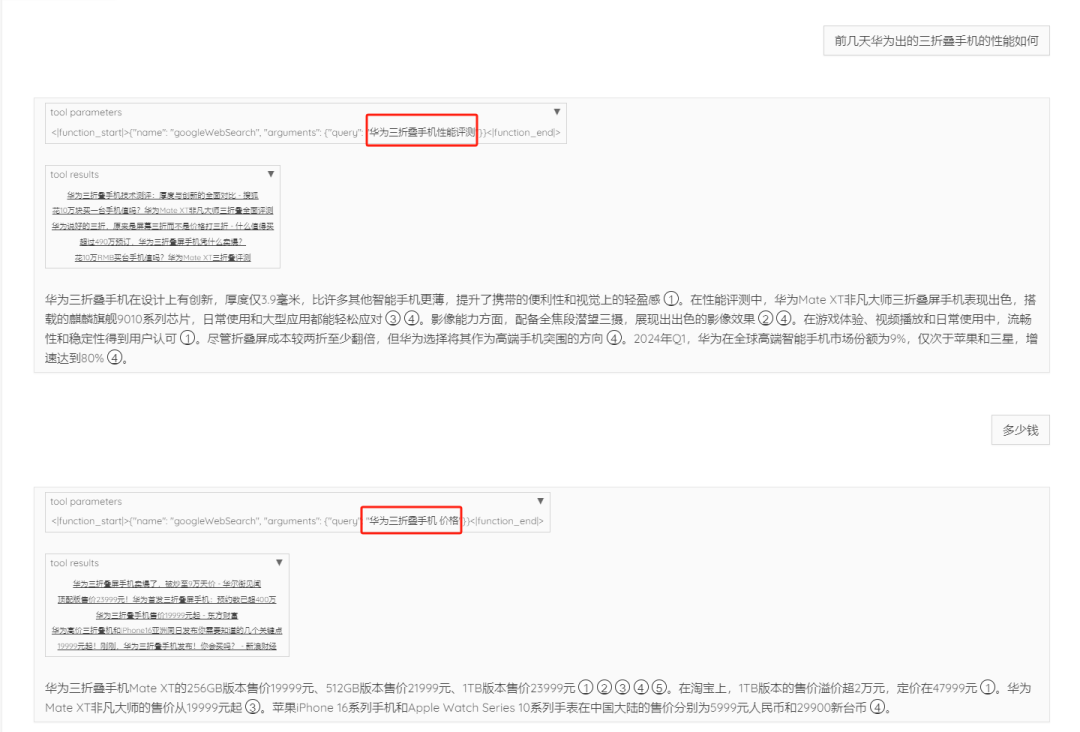
- 当然给出带ref格式的输出内容,这个部分是模型针对性训练后才用的能力。
看他的工程,里面还是有很多有意思的细节内容,并不是一个简单的RAG总结项目。比如:工程中会增加一步摘要过程,去除无效的网页信息,并将内容cache下来,以便提高模型回复效果等。
Github: https://github.com/infinigence/InfiniWebSearch
项目的整体流程如下图所示,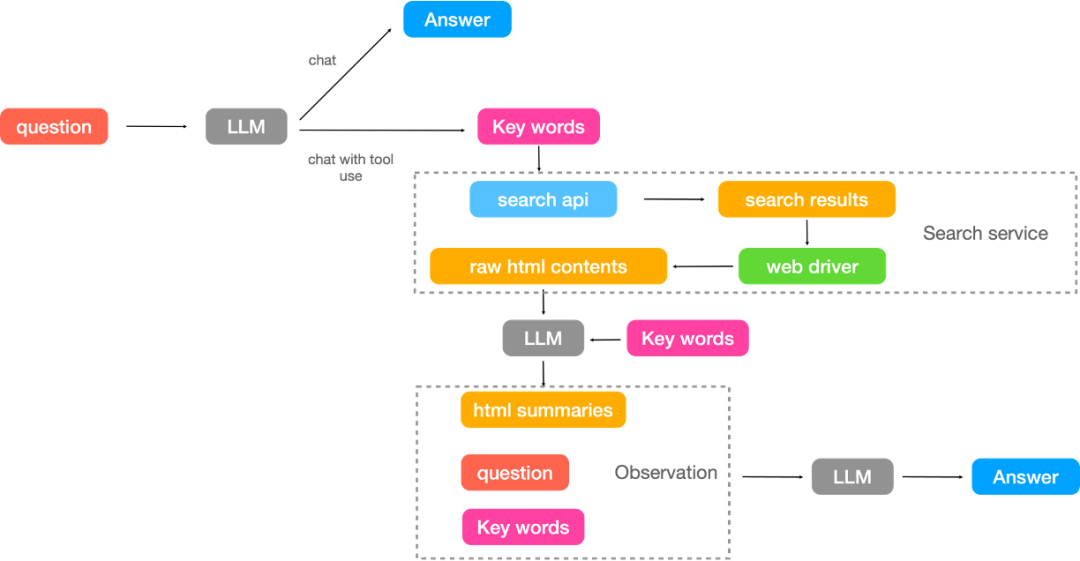
-
判断是调用工具回答还是大模型直接回答
-
若调用工具回答则对用户Query改写,生成相应的搜索关键词
-
通过查询Query获取相关的网页文本内容
-
根据Query和各个网页内容生成对应的summary,无关网页或者内容会以“无相关信息”替代
-
在根据summary和Query终结生成答案。
SUMMARY_PROMPT_TEMPLATE = ( '从信息中总结能够回答问题的相关内容,要求简明扼要不能完全照搬原文。直接返回总结不要说其他话,如果没有相关内容则返回"无相关内容", 返回内容为中文。\n\n' "<问题>{question}</问题>\n" "<信息>{context}</信息>" ) OBSERVATION_PROMPT_TEMPLATE = ( "You will be given a set of related contexts to the question, " "each starting with a reference number like [[citation:x]], where x is a number. " "Please use the context and cite the context at the end of each sentence if applicable." "\n\n" "Please cite the contexts with the reference numbers, in the format [citation:x]. " "If a sentence comes from multiple contexts, please list all applicable citations, like [citation:3][citation:5]. " "If the context does not provide relevant information to answer the question, " "inform the user that there is no relevant information in the search results and that the question cannot be answered." # noqa: E501 "\n\n" "Other than code and specific names and citations, your answer must be written in Chinese." "\n\n" "Ensure that your response is concise and clearly formatted. " "Group related content together and use Markdown points or lists where appropriate." "\n\n" "Remember, summarize and don't blindly repeat the contexts verbatim. And here is the user question:\n" "{question}\n" "Here is the keywords of the question:\n" "{keywords}" "\n\n" "Here are the set of contexts:" "\n\n" "{context}" )
整个项目的启动也是十分简单,三步走,你就可以得到一个本地部署的kimi啦:
- 启动检索
export SERPER_API_KEY=$YOUR_API_KEY cd infini_websearch/service python search_service.py --port 8021 --chrome ./chrome-linux64/chrome --chromedriver ./chromedriver-linux64/chromedriver
- 启动模型
python -m vllm.entrypoints.openai.api_server --served-model-name megrez --model $MODEL_PATH --port 8011 --max-seq-len 4096 --trust_remote_code
- 启动Demo
python gradio_app.py -m $MODEL_PATH --port 7860
PS:其他详细内容自己去看Github,比如摘要字数、关注的对话轮等等。
写在最后
Megrez-3B-Omni模型的整体体验还是不错的,但还是存在一些问题,比如ocr时候需要平衡准确识别和复读、模型数学能力有待提高等等,但对于小模型来说,还要同时负担三个模态,其实也不错了,要啥自行车呢。
期待下一版更新吧,愿开源大模型越来越好~~
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









