






(下载资源在文末,还是建议使用手机客户端)
Deepseek,这个在2025年过年期间引爆整个社交网络的究竟是什么?
当然不只是中文互联网,连大洋彼岸的美国也都在问,这个Deepseek是何方神圣。
不知道大家还记不记得当年ChatGPT刚刚问世的时候,几乎所有人觉得,这就是AI的未来,甚至开始恐慌AI替代人类的时代已然到来。
如果我能穿越到过去,可能就有人会问了:博主博主,ChatGPT确实很厉害,但是需要翻墙充钱,有没有更加简单又好用的大语言模型。
有的朋友,想这么厉害的大语言模型还有个Deepseek,其名称直接翻译过来就是深度探索。
Deepseek爆火的其中一个原因就是在1月27日把英伟达的股价干暴跌了:
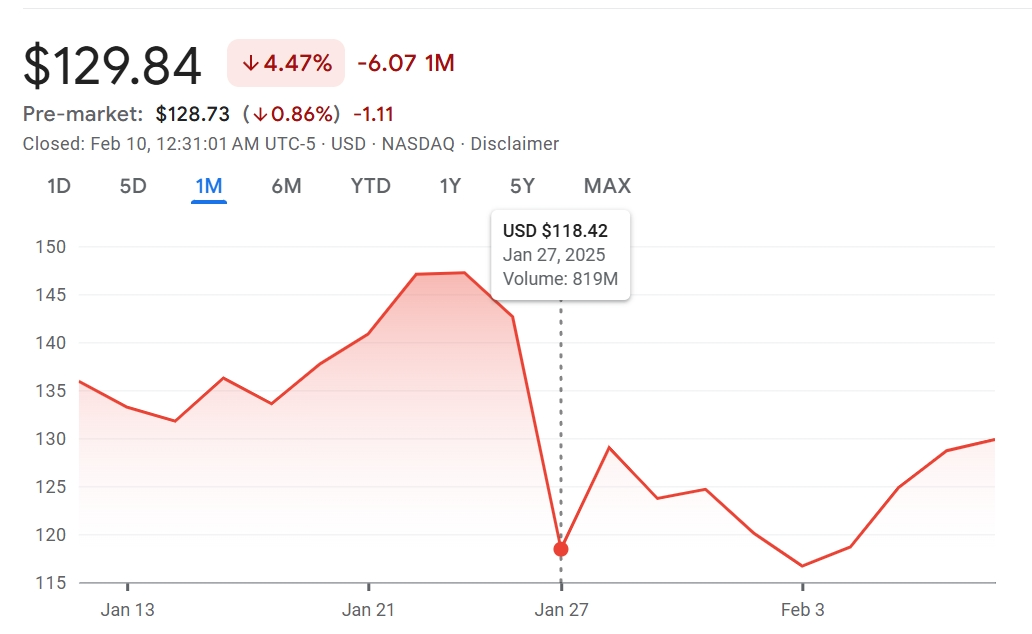
英伟达的市值一日蒸发近6000亿美金
Deepseek在2025年的世界经济论坛年会公布了最新的开源R1模型,R1模型用纯深度模型学习方法让AI自法涌现推理能力,在数学、代码、自然语言等推理任务上比肩OpenAI的01模型正式版。
R1模型的训练成本仅为560万美元,远低于美国科技巨头所耗费的数亿美元。简单来说就是Deepseek让很多人知道模型的训练不用花费那么多钱也能达到很不错的效果,并对美国科技公司耗费数亿乃至数十亿美金训练出来的模型的竞争力产生怀疑。
至于为啥一拳干在英伟达股票上,是因为现在英伟达的显卡及其AI芯片被广泛的认为是AI训练的必需品,也是英伟达在GPU(图形处理器)市场占有率高达90%的“护城河”。
由于英伟达早早就在AI方面进行布局,以至于现在所有的大科技公司都绕不开英伟达的芯片。而Deepseek的出现让人们发现,花小钱好像也能出奇迹。
这么厉害的语言模型在哪可以下载呢?
在手机应用商城直接搜索DeepSeek就可以啦!

手机版本可以直接微信登录,然后绑定自己的手机号就好啦。

其使用方法就直接聊天一样,有啥问题问Deepseek即可。
当然这个手机版的不是今天的重点,因为之前Deepseek有过网络繁忙的情况,所以今天来讲的是如何在电脑上本地部署Deepseek。
Deepseek本地部署
在本地部署之前我有几个点得提一下。
本地部署的Deepseek没有官方版本那么“聪明”,因为本地部署的是蒸馏模型。所谓蒸馏模型(Model Distillation)是指将一个大型且复杂的模型里面的信息传递到一个较小、且更加轻量的模型中,其目的在于保持模型性能的同时降低计算和储存资源的消耗。
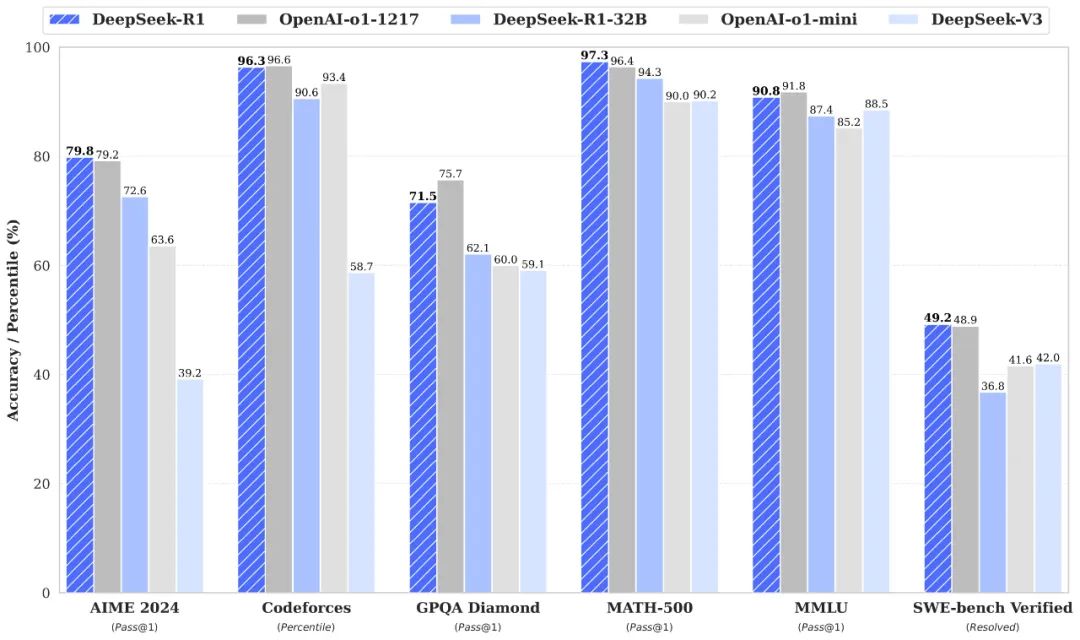
像是模型这个参数量差距是没什么能走捷径的办法的,差距就在那,能实现原本模型90%的功能就已经很厉害了。
那这里为什么还要选择本地部署呢?因为每次在线上跟Deepseek联网问问题的时候可能会涉及到一些比较隐私的信息数据等,而Deepseek的隐私协议提到了user input也就是聊天里所提到的任何信息都会被收集。
而本地部署基本上是断网运行,所有的聊天信息内容都由用户自己掌
本地部署其实也很简单,我是在B站一个叫做NathMath的up主那里下载的资源,这位UP提供了一个完整的包。大伙在文末的链接中下载安装后可以跟着我的步骤一起部署。
在下载完解压之后会得到这么些文件:
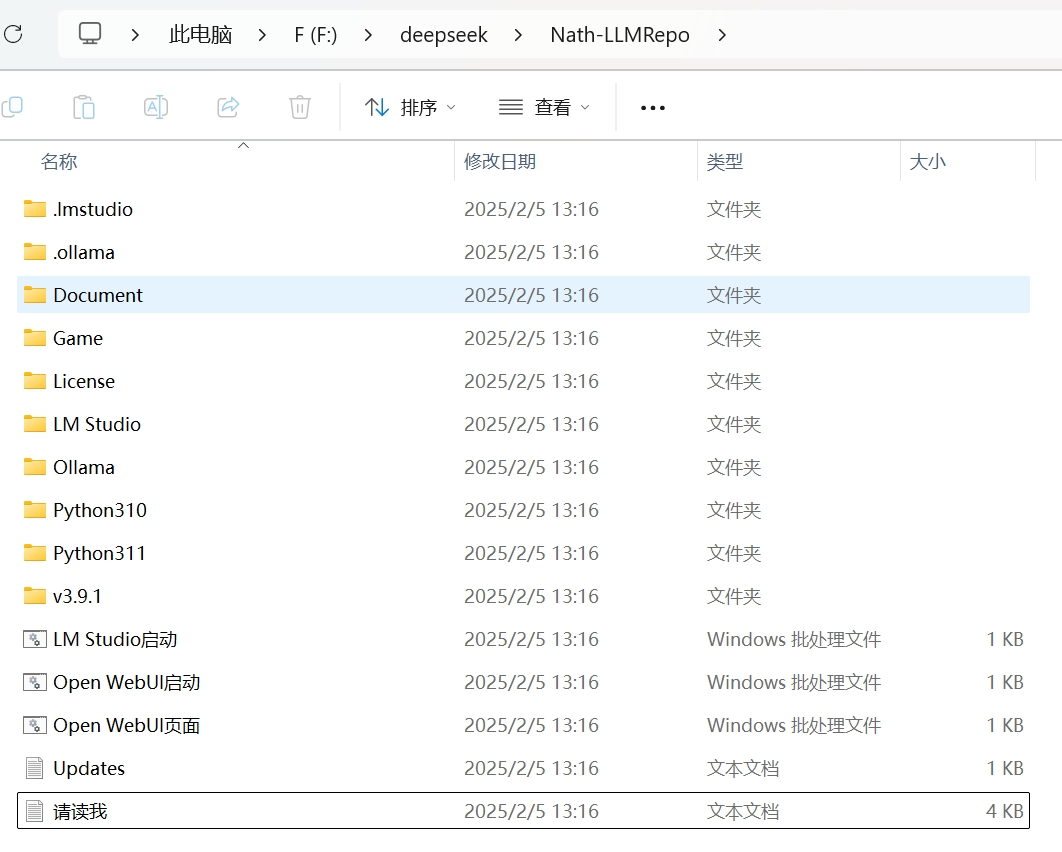
第一个文档.Imstudio就是运行时的环境,这个.Imstudio需要放到一个特殊的路径。
直接将.Imstudio剪切粘贴进电脑C盘-用户-用户名下方
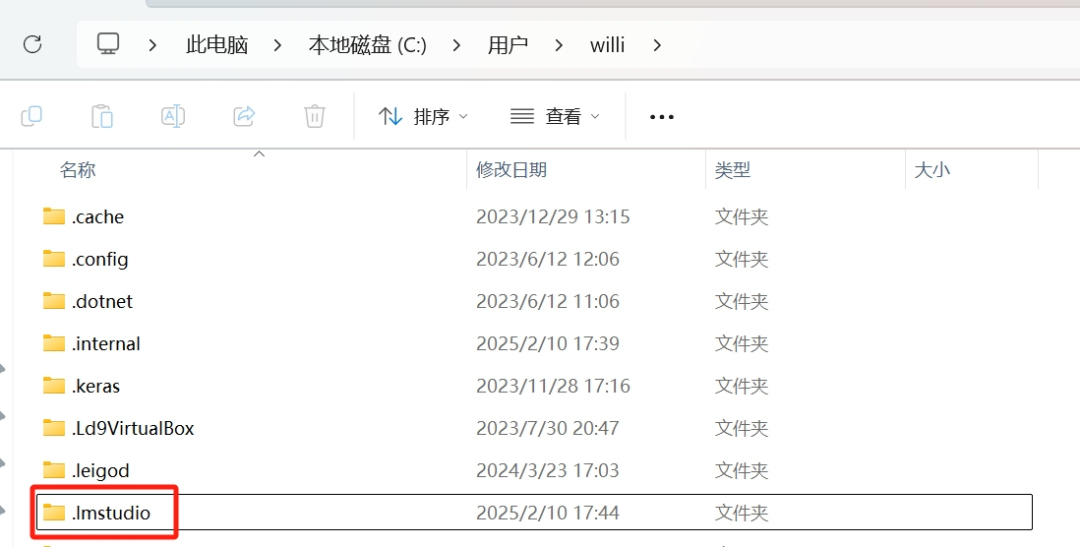
因为我的电脑名称是willi,所以我将.Imstudio粘贴进去。
接下来要转移的是LMStudio,将其剪切粘贴放到喜欢的位置,因为我AI相关的都是在F盘,所以我就将其复制放到F盘。

点开LM studio之后里面是这样的,差不多配置好了:
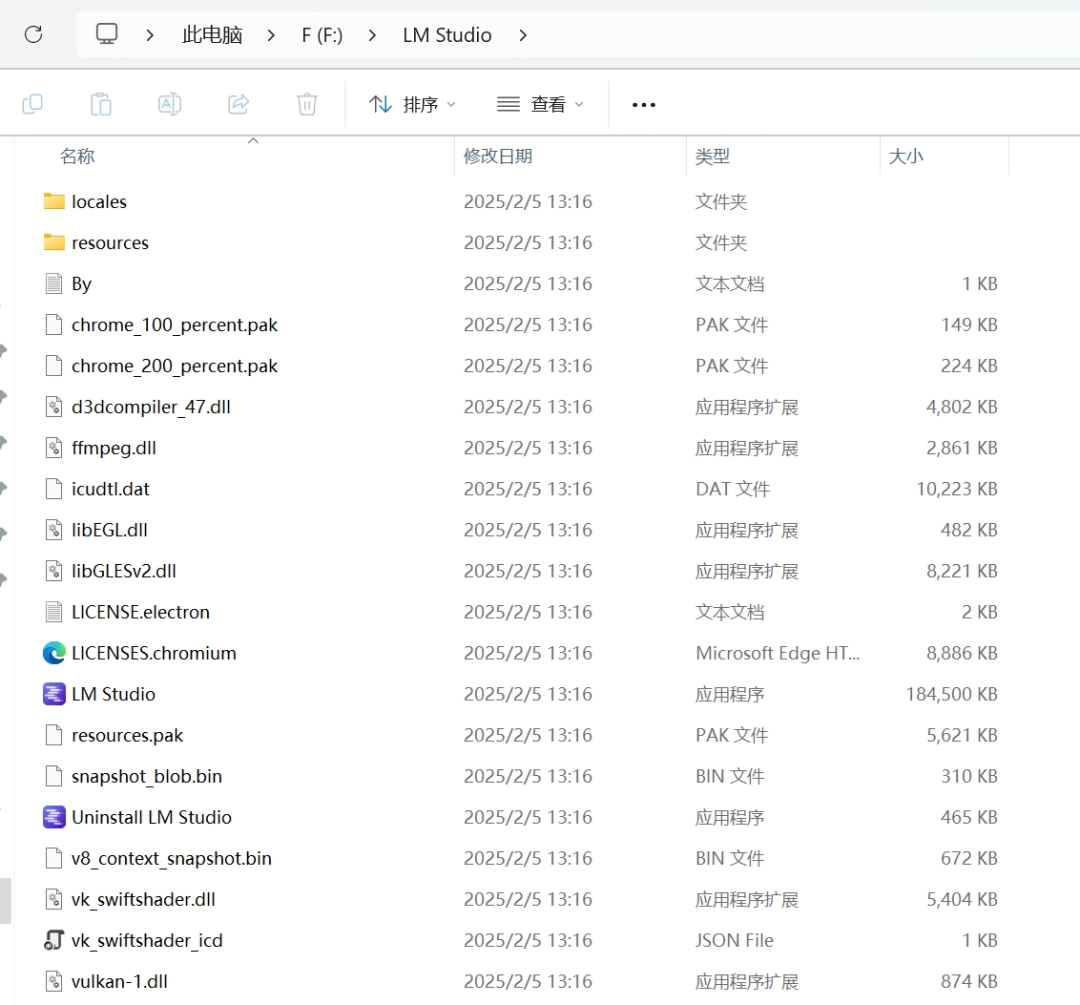
一会有些模型需要另外下载,我也会在后面演示并且在文末放链接。
接下来如何使用
打开刚刚放好的LM Studio文件夹,点击选择LM stuido:

点击之后等待片刻就能得到这样的一个界面:
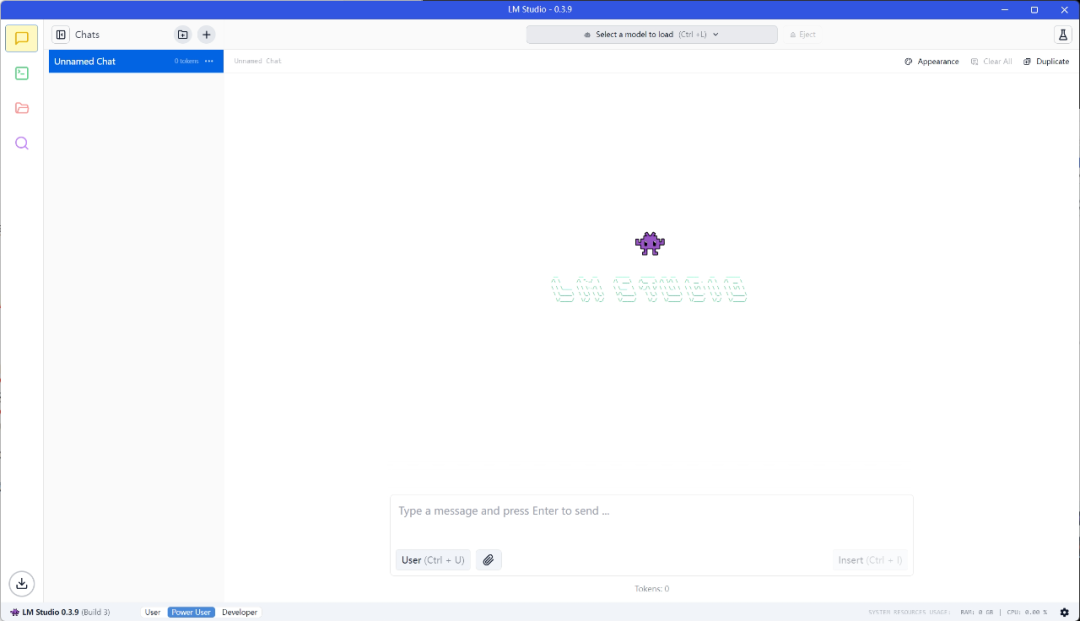
注意,此时我们还没进行断网的设置,如果时间充足我会在本篇末尾进行如何断网的讲解(不是直接拔网线哈)。
这个时候可能会没有模型加载出来,如果是这样的话请按照我接下来的步骤:
首先去文末的网盘地址下载Up主:NathMath提供的32B以及8B模型文件夹,以32B举例,在下载完之后会得到这样的几个文件和压缩包:
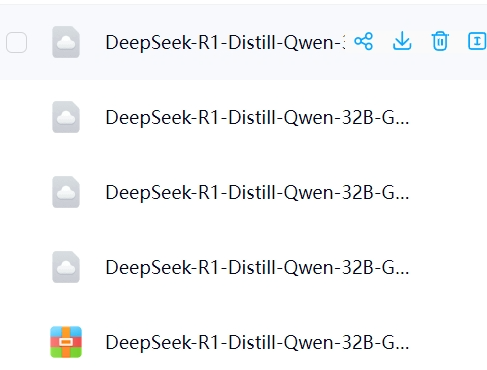
找到我们刚刚放在C盘的.Imstudio,然后选择models→nathmath-bilibili,这个路径:

先创建一个与文件同名的文件夹,这里直接复制我这个就行:DeepSeek-R1-Distill-Qwen-32B-GGUF
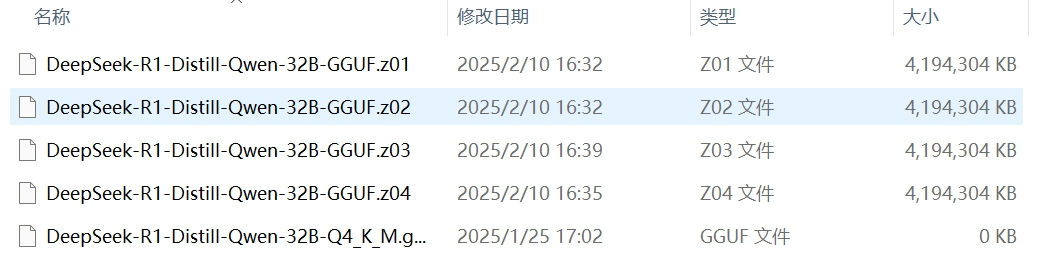
然后将上面图示的四个文件直接复制到这个新建的文件夹中,解压的文件中的文件夹也解压到这个新建文件夹中。
这样就能得到一共五个文件,其中4个是Z文件,一个是GGUF文件
8B文件夹的操作同理,在得到上述文件之后就可以回到LM Studio中
点击最上方的模型加载部分就可以看到我们刚刚放置好的模型:

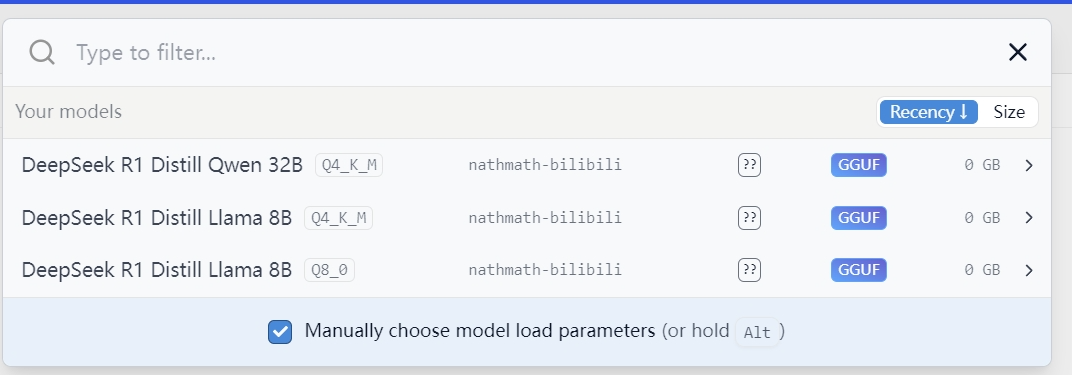
如果在模型旁边显示的是0GB的话,将之前下载的文件和解压包删除重新进行下载即可。

接下来点击该模型,会显示一些参数界面:
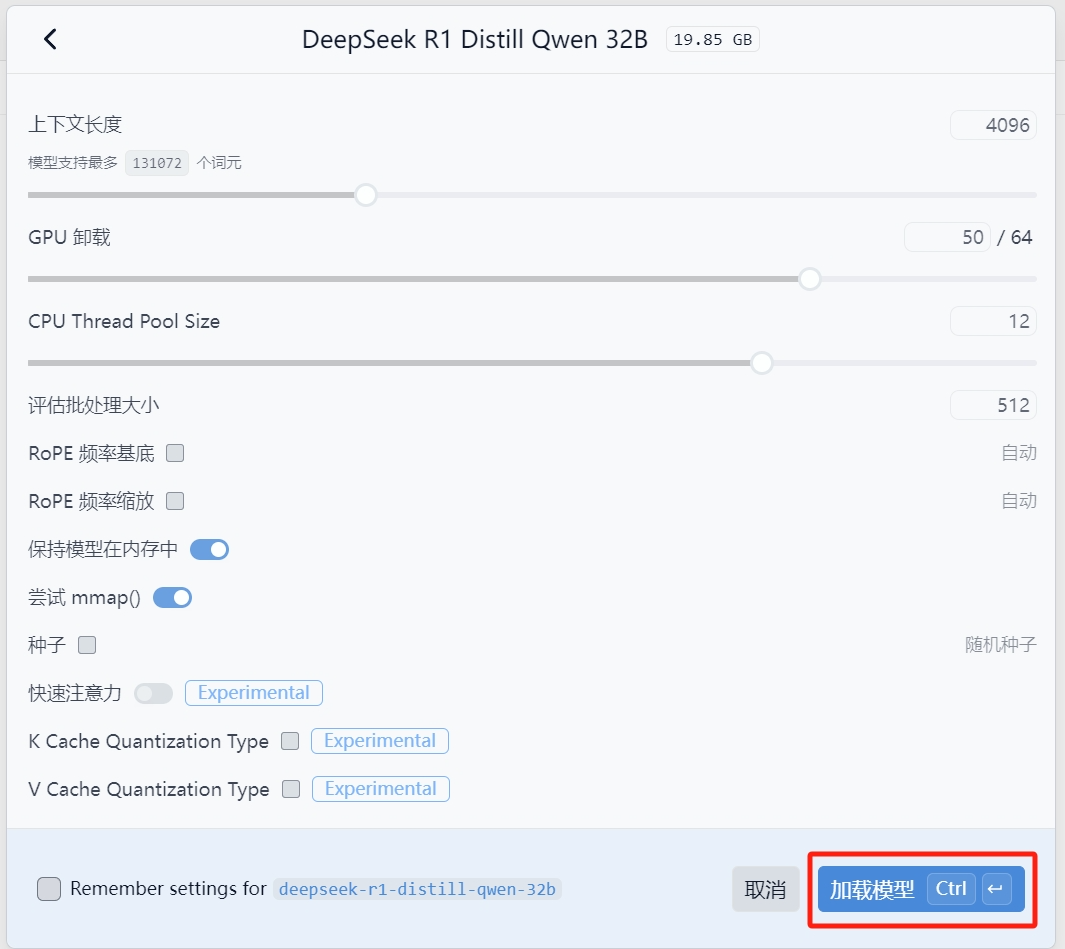
在这里我由于使用的是32B模型且我的GPU内存足够,所以在这里我保持默认参数并直接加载模型。
关于模型选择部分:
-
如果是CPU进行运行的话,则选择1.5B Q8推理 或者 8B Q4推理
-
如果是4G显存 GPU的话:选择8B Q4推理
-
8G显存 GPU:32B Q4推理 或者 8B Q4推理
-
16G显存 GPU: 32B Q4推理 或者 32B Q8推理
-
24G显存 GPU:32B Q8推理 或者 70B Q2推理
8B Q4推理

32B-Q4推理:
在加载完模型就可以对AI进行询问了,我就随便问了个问题:
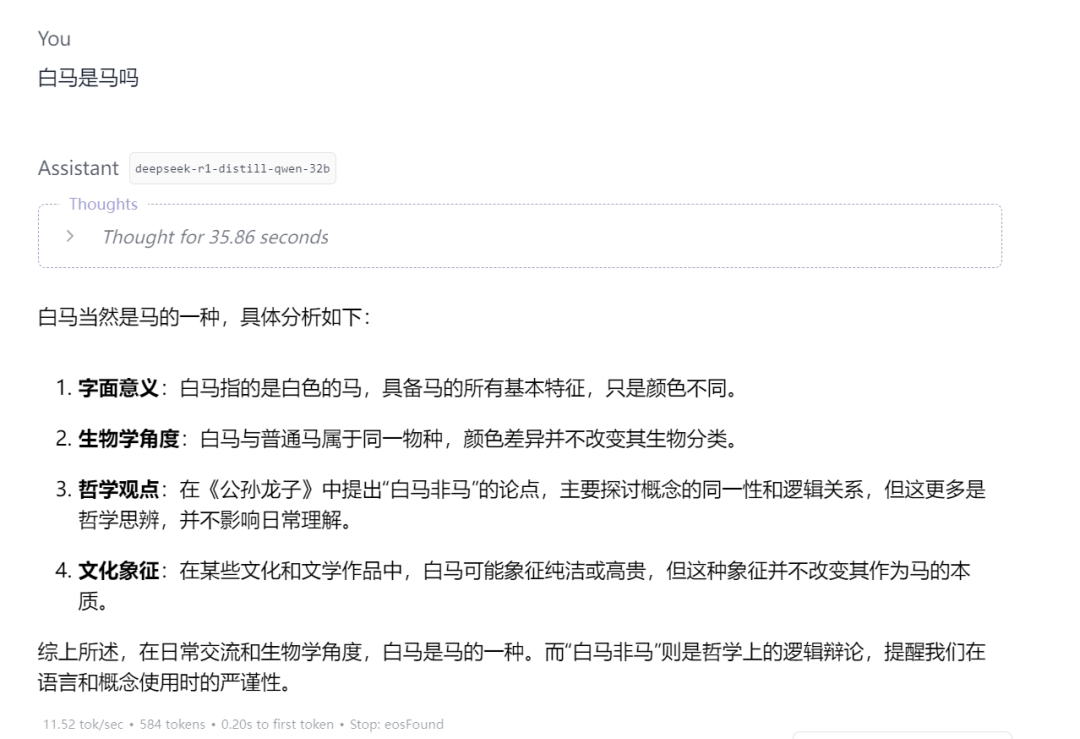
在问问题的时候,如果是32B的模型有些是可以直接回答出来的。
如果是1.5B或者8B的模型,有些问题可能在进行中文询问的时候会回答说“对不起,我还没有学会回答这个问题,如果你有其他问题,我非常乐意为你提供帮助。”
但是,这个时候用英文提问同样的问题的话,这个问题可能会绕过Deepseek R1的审查机制。
如果连英文都绕不过审查机制的话,那就得考虑更换一个模型了。
当然还有些奇怪的情况,例如本篇文章我们是在没有断网的情况下进行提问测试,这个时候开梯子的话有些问题AI就会直接回答,没有梯子的话就回答不出来。
目前如果有条件的话最好还是使用8B Q4或者32B Q4模型,这两个模型相对稳定且思考速度较快。
部分疑难解决
1.有些小伙伴可能会好奇,在哪里可以选择CPU进行运行,因为有些小伙伴可能GPU性能不是很好或者没装在GPU:
在整个界面的最右下角有一个小齿轮一样的图标,那个就是LM studio的设置
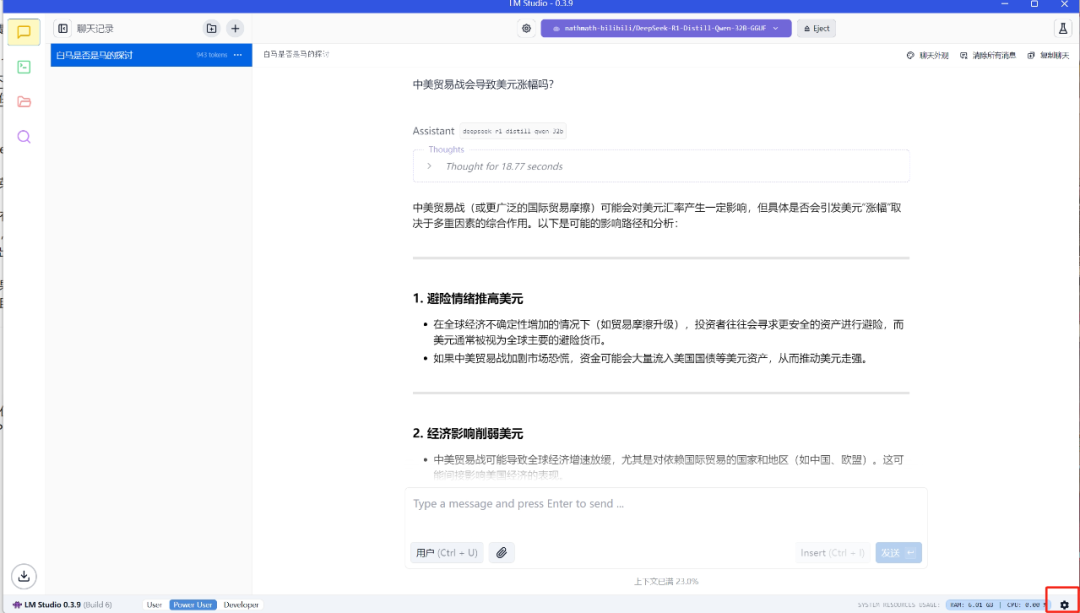
点击之后在右侧有一个Runtimes
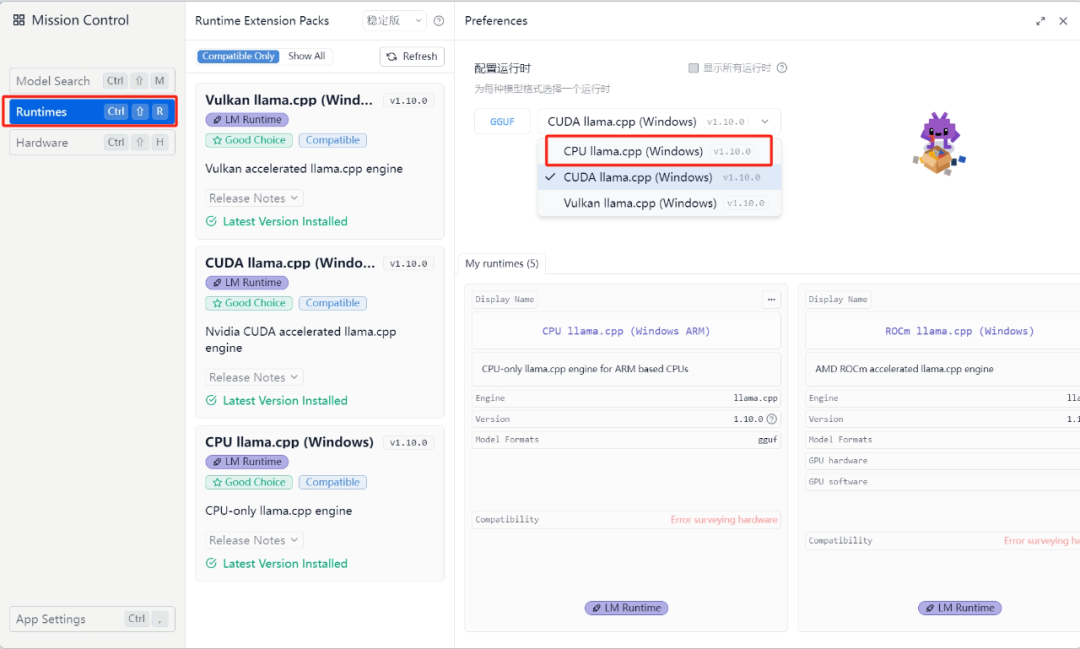
在右侧的配置运行时可以选择CPU或者其他运行,一般情况下是英伟达显卡(N卡)默认CUDA运行。
2.如果有的时候发现AI思考的时间太长的话可以适当个更换模型,思考时间太长一般是显存较小。
最好的情况下还是选择的模型小于显存才可以更好地使用

模型在加载期间会一直占用显存,如果同时电脑想要跑其他深度学习模型的话最好还是再组一个服务器远程跑。
3.加载模型失败
Failed to load model
error loading model:tensor ‘blk.27.ffn_down.weight’ data is not within the file bounds, model is corrupted or incomplete
这个是我在B站评论区看到的一个问题,在下面也有很多小伙伴分享了解决办法(我自己没碰到这个问题)。
其处理方法可以先将CUDA改为CPU,也就是我第一个点提到的。
还可以将LM studio卸载后重新安装
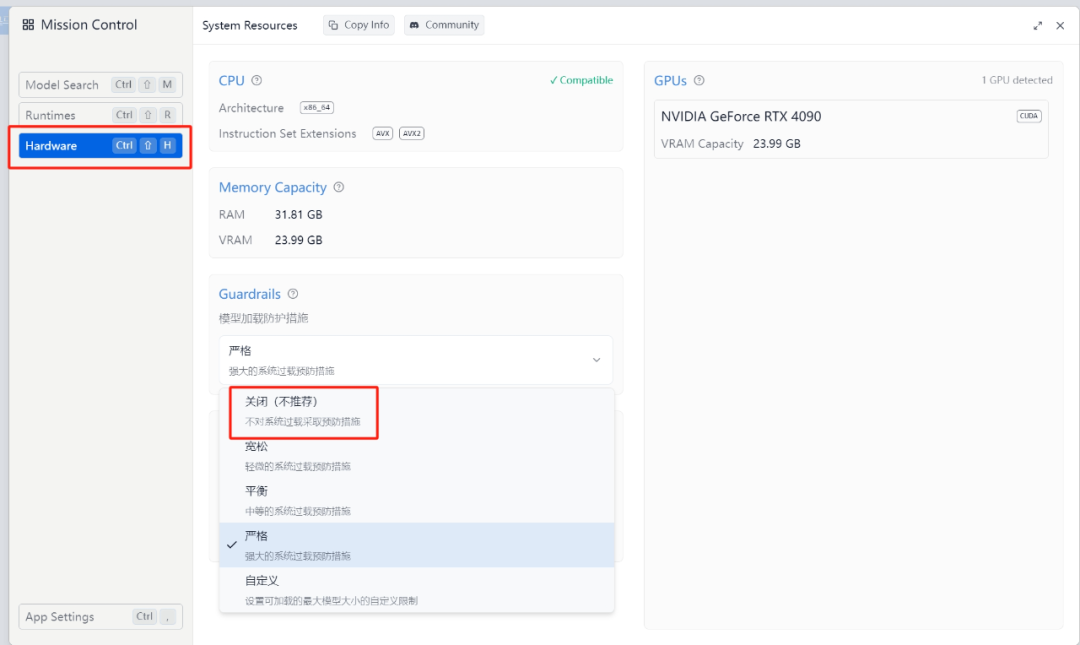
亦或者将模型加载防护措施关闭,但是这一点不提倡,因为模型太大且电脑配置不足的情况下可能会把电脑卡死!
今天的内容就到这里啦!
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









