






本文将浅入深出的分析DeepSeek新开源的FlashMLA原理、架构,解读FlashMLA的贡献。
2月24日,DeepSeek启动“开源周”,首个开源的代码库为FlashMLA。DeepSeek这种挤牙膏式的宣推手段也是很有意思,看来梁文锋团队不仅仅是技术派,也擅长玩技术流量IP。

1 FlashMLA简介
FlashMLA是由 depseek-ai (深度求索)开发的一个开源项目,针对Hopper架构GPU(例如H100或H800)的高效的MLA推断(Inference)解码内核,旨在加速MLA机制的计算,特别适用于DeepSeek 系列模型(如 DeepSeek-V2、V3 和 R1)。
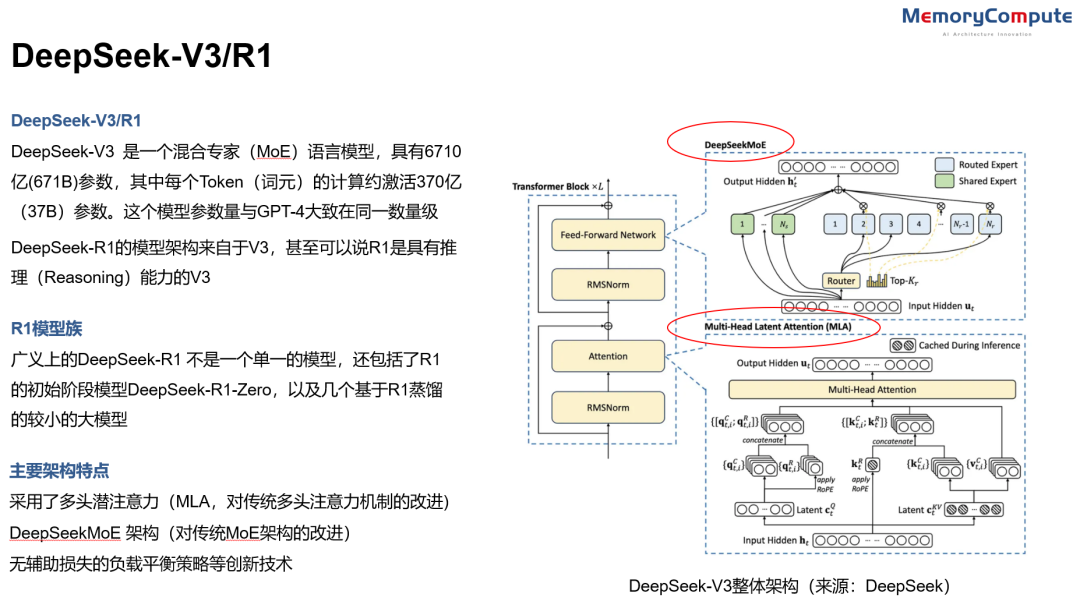
DeepSeek V3/R1介绍(来源:中存算半导体)
其中MLA是DeekSeek研发的多头潜注意力(Multi-head Latent Attention)机制。通过低秩矩阵压缩KV Cache(键值缓存),减少内存占用,同时提升模型性能。
FlashMLA借鉴FlashAttention分块tiling 和显存优化的思想。通过以算代存减少对于显存带宽的要求,提升计算性能。FlashMLA的构建基于Cutlass和CUDA体系。
Flash MLA 主要用于大模型推断/推理(Inference),特别是在需要处理长序列的场景中,如聊天机器人或代码生成工具。通过优化 GPU 利用率,解决大模型在推理阶段的显存瓶颈问题。
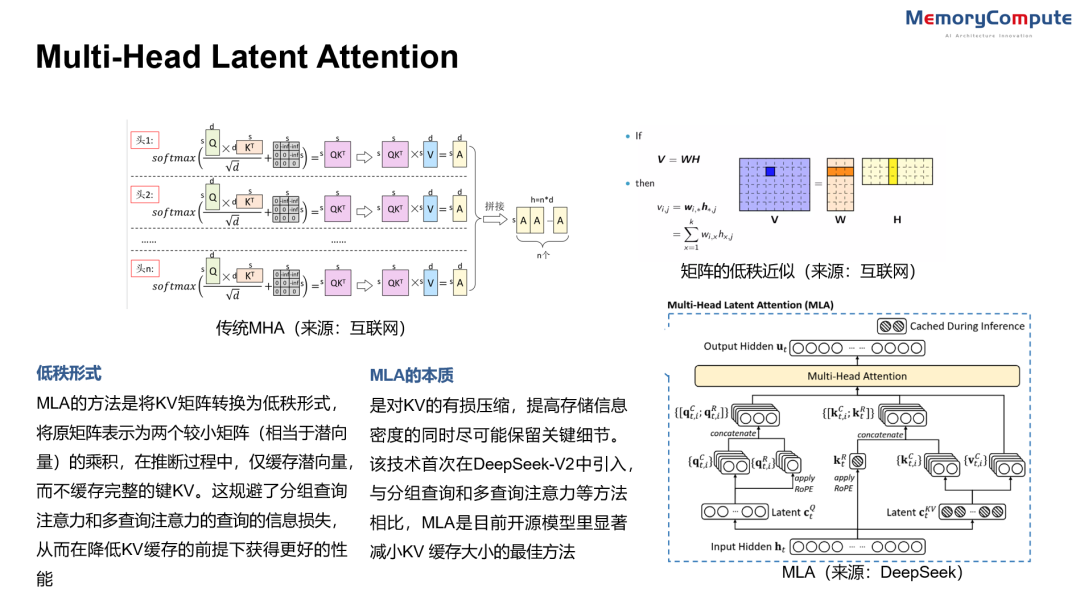
MLA(来源:中存算半导体)
2 FlashMLA的关键技术与未来优化
FlashMLA具有以下关键特征:
1)Flash MLA支持变长序列和分页KV缓存。
2)基于BF16格式和至少12.3以上的CUDA。
3)支持Hopper架构的TMA优化。
4)可显著提升KV Cache性能和GPU计算性能。在 H800 SXM5上,可达 3000 GB/s的计算带宽(接近3.35TB/s的理论峰值)。
5)开源版本暂不支持反向传播计算。
6)使用MIT 许可证便于社区协作。
FlashMLA未来可能的优化方向包括:
1)通过PTX编程进一步提高细粒度性能
2)探索FP8数据格式支持(需Hopper架构或更先进的TensorCore)
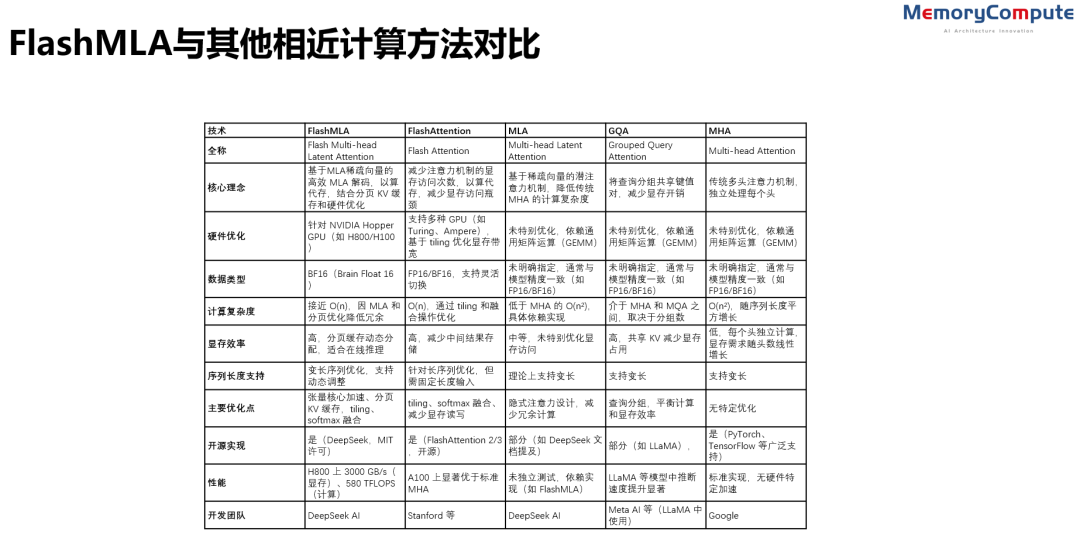
FlashMLA与其他相近计算方法对比(来源:中存算半导体)
3 从Memory Bound到Flash Attention和MLA
3.1 Memory Bound与I0-Awareness
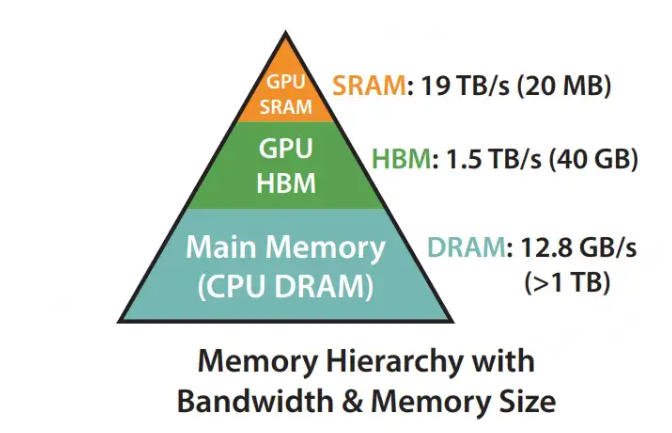
传统计算芯片的分层存储架构(来源:互联网)
在传统的GPU和AI芯片中,存储架构分为不同的层次。一般来说内部的SRAM最快,外部的HBM或DRAM速度比SRAM慢很多。
1)Die内存储:主要用于缓存(Cache)及少量特殊存储单元(例如texture),其特点是存储容量小但带宽大。SRAM就属于常见的Die(晶片)内存储,存储容量一般只有20-160MB,但是带宽可以达到甚至超过19TB/S。
2)Die外存储:主要用于全局存储,即我们常说的显存,其特点是存储容量大但带宽小。HBM就属于常见的Die(晶片)外存储,存储容量一般是40GB以上,但带宽相比于SRAM小得多。
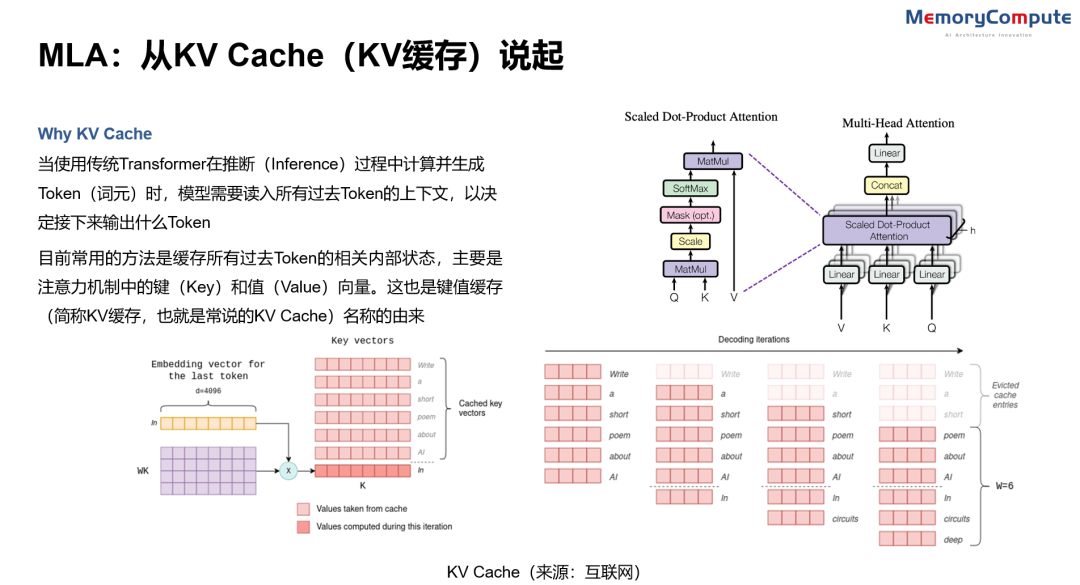
KV缓存(来源:中存算半导体)
对于Transformer类的大模型来说,由于KV Cache巨大,很难直接放在Cache里,需要放在HBM或GDDR上,并在计算过程中频繁挪动KV数据。(另外有一些Transformer Free的结构就不需要反复挪动KV数据,还未成为主流技术)这时就会出现Memory Bound(存储限制)的情况,极大影响了KV Cache的吞吐带宽和大模型的计算速度。
在Flash Attention之前,也出现过一些加速Transformer计算的方法,着眼点是减少计算量,例如稀疏Attention做近似计算。但对于Attention来说,GPU计算瓶颈不在运算能力,而是在存储的读写速度上。Flash Attention吸取了这些加速方法的教训,改为通过降低对显存(HBM或GDDR)的访问次数来加快整体性能,这类方法又被称为I0-Awareness(IO优先或存储优先)
3.2 Flash Attention
FlashAttention 是一种高效的注意力机制优化技术,由斯坦福等大学的研究团队开发,最早于 2022 年提出,并在后续版本(如 FlashAttention-2、FlashAttention-3)中不断完善。FlashAttention旨在解决传统 Transformer 模型中多头注意力(Multi-head Attention, MHA)的计算和显存瓶颈,尤其是在处理长序列时。FlashAttention通过重新设计注意力计算方式,显著提升性能,同时保持与标准注意力机制相同的数学输出,使其成为近年来生成式AI和大模型领域的重要技术。FlashAttention拥有比PyTorch(当时的版本)标准注意力快24倍的运行速度,所需内存还减少了520倍。
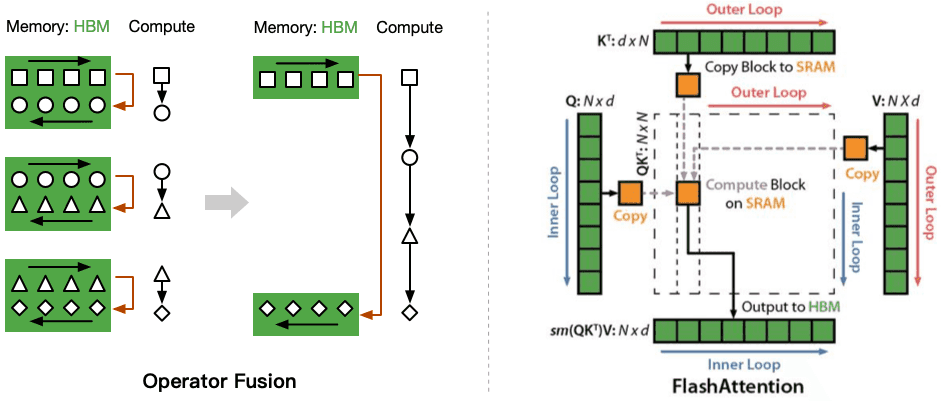
Flash Attention技术(来源:互联网)
Flash Attention专注于标准多头注意力的高效实现,通过减少访问显存次数,优化并行度提升计算性能,但并不直接兼容MLA。
传统MHA 的计算复杂度为 O(n²)(n 为序列长度),并且需要存储大量的中间结果,这在长序列任务中会导致严重的显存压力和计算延迟。FlashAttention 的核心理念是避免显式计算和存储完整的注意力矩阵,而是通过分块计算(tiling) 和融合操作,将注意力计算优化为接近O(n)的复杂度,同时大幅减少GPU内存访问。
1)分块处理: 将输入序列分割成小块(tiles),逐块计算注意力,避免一次性加载整个矩阵。
2)显存优化: 通过在线计算 softmax 和融合操作,减少中间结果的存储需求。
3)硬件架构友好: 充分利用GPU高速内存(如共享缓存)和并行计算能力。
3.3 MLA
DeepSeek使用的Multi-Head Latent Attention技术可大大节省KV缓存,从而显著降低了计算成本。
MLA的本质是对KV的有损压缩,提高存储信息密度的同时尽可能保留关键细节。该技术首次在DeepSeek-V2中引入,与分组查询和多查询注意力等方法相比,MLA是目前开源模型里显著减小KV 缓存大小的最佳方法。
MLA的方法是将KV矩阵转换为低秩形式:将原矩阵表示为两个较小矩阵(相当于潜向量)的乘积,在推断过程中,仅缓存潜向量,而不缓存完整的键KV。这规避了分组查询注意力和多查询注意力的查询的信息损失,从而在降低KV缓存的前提下获得更好的性能。
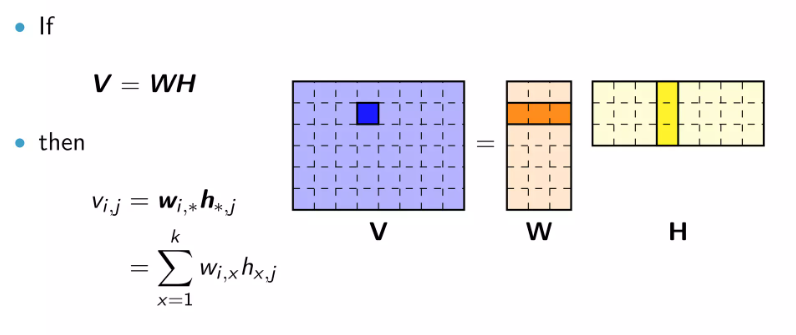
矩阵的低秩近似(来源:互联网)
MLA随好,但明显没有针对现代加速框架的FlashAttention或PageAttention解决方案。这也使得DeepSeek R1在实际部署时需要单独优化KV吞吐性能。
4 FlashMLA微架构分析
4.1 FlashMLA核心技术
Flash MLA 的核心是高效的 MLA 解码内核,关键技术包括:
1)低秩矩阵压缩:MLA 使用低秩矩阵,将KV缓存压缩为潜向量,减少内存占用。通过解压潜向量生成独特的KV头(KV Head)。
2)针对GPU 优化:FlashMLA针对Hopper GPU 的Tensor Core进行youh优化,实现了可达3000 GB/s 的显存带宽和 580 TFLOPS 的计算性能(H800 SXM5 配置)。
3)变长序列支持:通过 tile_scheduler_metadata 和 num_splits 参数,FlashMLA 支持变长序列的并行处理,以缓解负载不均衡问题。
4.2 FlashMLA代码结构
FlashMLA 提供了Python 接口,如 get_mla_metadata 获取 MLA(Multi-Head Linear Attention)的meta数据;flash_mla_with_kvcache,用于获取键值缓存(KV Cache)和执行注意力(FlashMLA)计算。
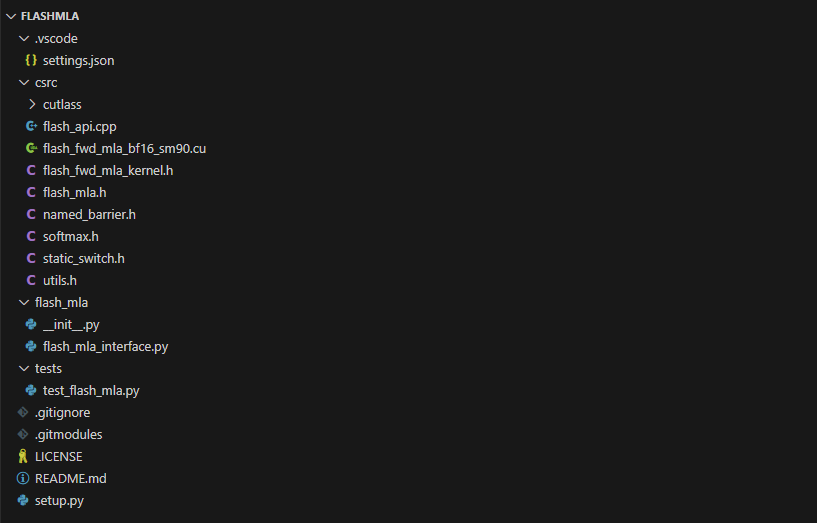
主要代码结构如下:
1)flash_mla/ 目录
·文件: flash_mla_interface.py
·作用: Python 接口层,封装了底层 C++/CUDA实现,以便将 FlashMLA 集成到 PyTorch 工作流中。
这部分代码定义了flash_mla_with_kvcache等函数,用于执行带 KV 缓存的MLA 前向计算。
参数包括查询向量(q)、键值缓存(kvcache)、块表(block_table)、序列长度(cache_seqlens)等。
2)setup.py
·作用: 构建脚本,用于编译和安装 FlashMLA 模块。
3)csrc/ 目录
·文件:
oflash_api.cpp: C++ 接口,连接 Python 和 CUDA。
oflash_fwd_mla_bf16_sm90.cu: 核心 CUDA 内核,针对 Hopper 架构(SM90)优化。
oflash_mla.h, softmax.h, utils.h 等: 提供辅助函数和数据结构。
·作用: 实现了FlashMLA底层的CUDA实现和性能优化。
这部分代码使用 BF16(Brain Float 16)数据类型,以保障Attention计算精度。同时结合FlashAttention 2/3和Cutlass库,以实现高效注意力机制。
flash_mla.cu:实现内核函数:
·KV 缓存的压缩和解码逻辑,使用低秩矩阵保存KV
·注意力计算,利用Tensor Core加速矩阵乘法。
·分页缓存管理,处理变长序列的显存分配。
flash_mla.h:定义接口函数:
·get_mla_metadata(num_heads, head_dim, num_kv_heads, kv_head_dim, block_size, dtype):获取 MLA meta数据。
·flash_mla_with_kvcache(q, k, v, kvcache, seqlen, metadata, causal=True):执行注意力计算。
Paged KV Cache 实现:
显存分块:以64为单位(block_size = 64),通过block_table维护逻辑块到物理显存的映射。
流水线:分离数据加载与计算阶段,通过cp.async实现异步数据预取。
flash_fwd_splitkv_mla_kernel:用于并行计算Flash Attention的前向传播。
flash_fwd_splitkv_mla_combine_kernel:用于合并多个分割的计算结果。
5 FlashMLA的价值与意义
FlashMLA 是 DeepSeek 团队在 AI 性能优化领域的重要成果,实现了在英伟达Hopper架构GPU的高效Inference。其价值在于:
1)通过开源鼓励开发者优化或适配其他硬件(如AMD GPU和其他AI芯片)。
2)鼓励开发者实现与现有加速框架(如 vLLM、SGLang等)的集成。
强烈建议OpenAI把域名送给DeepSeek。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









