







Redis采用单线程模型,每条命令执行如果占用大量时间,会造成其他线程阻塞,对于Redis这种高性能服务是致命的,所以Redis是面向高速执行的数据库
一、Redis是非关系型数据库
NoSQL是基于键值对的,不需要经过sql层的解析,所以性能非常高
二、Redis是单线程:
避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,没有线程阻塞和锁竞争。没有加锁和释放锁的操作,不会出现死锁而导致的性能消耗;
三、Redis是纯内存操作:
完全基于内存,所有数据基本上都存在于内存当中,redis 自身是一个 Map,其中所有的数据都是采用 key : value 的形式存储 ,Map的优势就是查找和操作速度快。会定时以追加或者快照的方式刷新到硬盘中。由于redis是一个内存数据库, 所以读取写入的速度是非常快的, 所以经常被用来做数据, 页面等的缓存。
四、数据结构简单
Redis数据结构简单,对数据操作也简单。
| 类型 | |
| String |
通常使用字符串,如果字符串以整数的形式展示,可以作为数字操作使用
|
| List |
保存多个数据,底层使用双向链表存储结构实现
|
| Set |
与
hash
存储结构完全相同,仅存储键,不存储值(
nil
),并且值是不允许重复的
|
| Hash |
一个存储空间保存多个键值对数据
|
| sorted_set |
在
set
的存储结构基础上添加可排序字段
|
五、底层模型不同
Redis 直接自己构建了 VM 机制 ,不会像一般的系统会调用系统函数处理,会浪费一定的时间去 移动 和 请求。
Redis 的 VM (虚拟内存)机制就是暂时把不经常访问的数据(冷数据)从内存交换到磁盘中,从而腾出宝贵的内存空间用于其它需要访问的数据(热数据)。通过 VM 功能可以实现冷热数据分离,使热数据仍在内存中、冷数据保存到磁盘。这样就可以避免因为内存不足而造成访问速度下降的问题。
Redis 为了保证查找的速度,只会将 value 交换出去,而在内存中保留所有的 Key。所以它非常适合 Key 很小,Value 很大的存储结构。
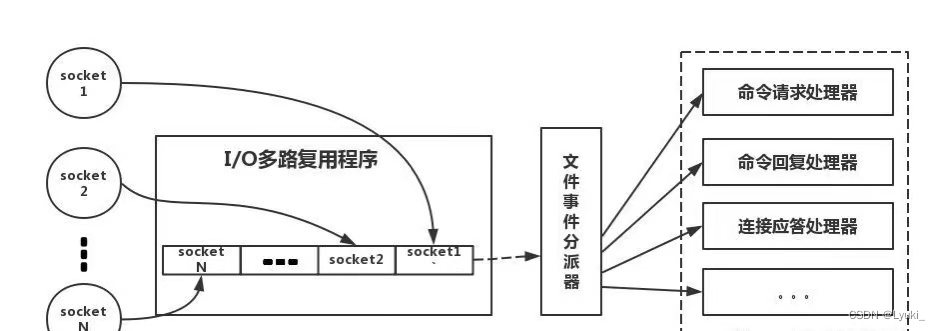
六、非阻塞I/O:
Redis采用epoll作为I/O多路复用技术的实现,再加上Redis自身的事件处理模型将epoll中的连接,读写,关闭都转换为了时间,不在I/O上浪费过多的时间。
I/O 多路复用机制是指一个线程处理多个 IO 流,select/epoll 机制。在 Redis 只运行单线程的情况下,该机制允许内核中,同时存在多个监听 Socket 和已连接 Socket。内核会一直监听这些 Socket 上的连接请求或数据请求。一旦有请求到达,就会交给 Redis 线程处理,这就实现了一个 Redis 线程处理多个 IO 流的效果。















 1714
1714











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









