







CSDN的朋友们好~
What|重排序(Re-ranking)
重排序(Re-ranking)是指在信息检索或生成式问答(RAG)系统中,对初步检索得到的候选文档集合,通过更精细的相关性评估模型进行二次排序,以优化最终返回结果的顺序和质量。其核心在于利用更高精度的排序模型(如交叉编码器、对比学习模型)对初始检索结果进行重新评分和筛选,从而提升上下文与查询的语义匹配度。
打个比方
想象你在图书馆找书:
- 第一步(检索):图书管理员快速从书架上抱来20本可能相关的书(基于书名/关键词的粗略匹配)。
- 第二步(重排序):你翻开每本书的目录,仔细对比哪几本真正解答你的问题,留下3本最相关的(高精度筛选)。
重排序就是那个“仔细翻目录”的过程,确保最终交给大脑(LLM)的书是精华。
Why|为什么要引入重排序
[!NOTE] 重排序为什么能提高RAG质量?
- 我觉得,重排序模型比检索使用的嵌入模型精度更高,能够再次排序文本相关性,过滤掉弱相关的内容,提高了质量
- 重排序带来了过滤机制,那么检索的条数不再拘束,可以放开一点,调高20条,扩大检索范围,带来更多信息。
- 看看DeepSeek怎么说
[!NOTE] Title
你的理解完全正确!重排序(Re-ranking)在 RAG(Retrieval-Augmented Generation)中确实能显著提升结果质量,核心原因正是你提到的两点:1. 精度差异:重排序模型 > 检索模型
- 检索阶段:通常使用轻量级嵌入模型(如
text-embedding-3-small)快速召回 Top-K 文档,牺牲部分精度换取速度。- 重排序阶段:采用更复杂的模型(如
Cohere Rerank、bge-reranker)对召回结果二次评分,精准判断相关性。
效果:过滤低质量片段,确保最终输入 LLM 的上下文高度相关。
2. 动态检索范围:先“广撒网”,后“精准筛选”
- 检索时放宽数量(如从 Top-5 扩大到 Top-20):
- 避免因初始检索模型误差遗漏关键文档。
- 覆盖更多潜在相关片段(尤其是长尾问题)。
- 重排序后保留 Top-N(如 Top-3):
- 既扩大信息池,又通过高精度模型剔除噪声。
优势:平衡召回率(Recall)和精确率(Precision)。
3. 补充:重排序的其他价值
- 解决嵌入模型的“语义盲区”:
某些查询需要复杂语义匹配(如否定、多跳推理),嵌入模型可能失效,而重排序模型能捕捉这类细微差异。- 适配业务需求:
可通过定制重排序模型(如加入点击率、人工反馈数据)优化垂直领域效果。你的思路完全符合业界最佳实践,这也是为什么 RAG 系统通常采用 “检索 → 重排序 → 生成” 的三段式流水线设计。
ok,明白这事值得做,接下来上实战↓
How|实战细节
先前的 RAG 知识库问答系统原先采用本地模型进行重排序,而这非常吃性能,2H2G 的 CPU 服务器压根带不动。
- 于是
siliconflow提供的免费的 rerank 服务真香~
- 还没有账号的朋友们可以在这里注册:https://cloud.siliconflow.cn, 比起直接注册,这可以得 14 元赠送额度,能用很久。还可以用最新的
Qwen3!
↓
↓
Rerank
阅读 API DOC
- API -> 创建 batch 任务 - SiliconFlow
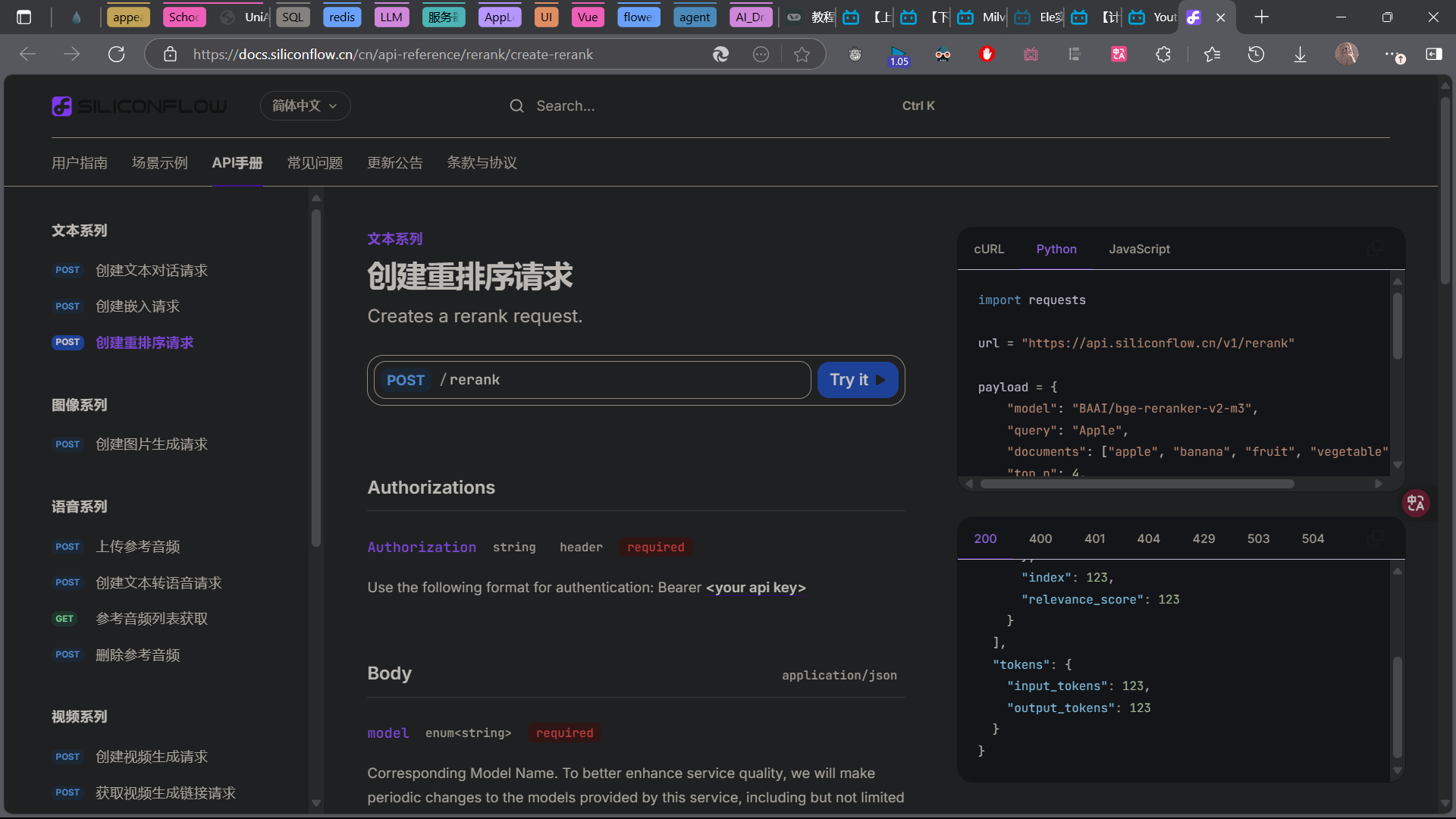
编写 http 请求
- src\utils\remote_rerank.py
import asyncio
import logging
import os
from typing import Any, Dict, List, Optional
import httpx
from dotenv import load_dotenv
# 配置日志记录器
logger = logging.getLogger(__name__)
# SiliconFlow API 的基础 URL
SILICONFLOW_API_URL = "https://api.siliconflow.cn/v1/rerank"
async def call_siliconflow_rerank(
api_key: str,
query: str,
documents: List[str],
model: str = "BAAI/bge-reranker-v2-m3",
top_n: Optional[int] = None,
) -> Optional[List[Dict[str, Any]]]:
"""
异步调用 SiliconFlow 的 Rerank API。
Args:
api_key (str): SiliconFlow 的 API 密钥。
query (str): 用户的查询语句。
documents (List[str]): 需要重排序的文档内容列表。
model (str): 使用的 Rerank 模型名称。默认为 "BAAI/bge-reranker-v2-m3"。
根据 SiliconFlow 文档,可选: "BAAI/bge-reranker-v2-m3",
"Pro/BAAI/bge-reranker-v2-m3", "netease-youdao/bce-reranker-base_v1"
top_n (Optional[int]): 需要返回的最相关文档数量。如果为 None,API 会使用其默认值。
Returns:
Optional[List[Dict[str, Any]]]: 排序后的结果列表,包含 'index' 和 'relevance_score'。
如果 API 调用失败或返回非预期格式,则返回 None。
每个字典形如: {'index': int, 'relevance_score': float}
其中 'index' 是原始 documents 列表中的索引。
"""
if not api_key:
logger.error("SiliconFlow API key 未提供,无法调用 Rerank 服务。")
return None
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
payload: Dict[str, Any] = {
"model": model,
"query": query,
"documents": documents,
"return_documents": False, # 通常我们只需要排序后的索引和分数
}
if top_n is not None:
payload["top_n"] = top_n
logger.debug(
f"向 SiliconFlow Rerank API 发送请求: URL={SILICONFLOW_API_URL}, Model={model}, Query='{query[:50]}...', Docs Count={len(documents)}"
)
try:
async with httpx.AsyncClient() as client:
response = await client.post(
SILICONFLOW_API_URL,
headers=headers,
json=payload,
timeout=30.0, # 设置超时时间 (秒)
)
response.raise_for_status() # 如果状态码不是 2xx,则抛出 HTTPStatusError
result = response.json()
logger.debug(f"收到 SiliconFlow Rerank API 响应: {result}")
# 验证响应结构并提取所需信息
if "results" in result and isinstance(result["results"], list):
ranked_results = []
for item in result["results"]:
index = item.get("index")
score = item.get("relevance_score")
if index is not None and score is not None:
ranked_results.append(
{"index": index, "relevance_score": score}
)
else:
logger.warning(
f"SiliconFlow 响应中的项目缺少 index 或 relevance_score: {item}"
)
# 根据 relevance_score 降序排序 (API 可能已经排序,但最好确认)
ranked_results.sort(key=lambda x: x["relevance_score"], reverse=True)
return ranked_results
else:
logger.error(f"SiliconFlow Rerank API 响应格式不符合预期: {result}")
return None
except httpx.HTTPStatusError as e:
logger.error(
f"调用 SiliconFlow Rerank API 时发生 HTTP 错误: {e.response.status_code} - {e.response.text}"
)
return None
except httpx.RequestError as e:
logger.error(f"调用 SiliconFlow Rerank API 时发生请求错误: {e}")
return None
except Exception as e:
logger.error(f"调用 SiliconFlow Rerank API 时发生未知错误: {e}", exc_info=True)
return None
测试代码
-
记得填写
apikey哦 -
src\utils\remote_rerank.py
# --- 测试代码 --- #
async def _test_rerank():
"""测试 call_siliconflow_rerank 函数。"""
load_dotenv() # 加载 .env 文件中的环境变量
api_key = os.getenv("SILICONFLOW_API_KEY") # 从环境变量获取 API Key
if not api_key:
print("错误:请在 .env 文件或环境变量中设置 SILICONFLOW_API_KEY 进行测试。")
return
query = "全球变暖的影响"
documents = [
"农业产量可能会受到极端天气事件的影响。", # index 0
"海平面上升是全球变暖的一个显著后果,威胁沿海城市。", # index 1
"冰川融化导致淡水资源减少。", # index 2
"生物多样性面临威胁,许多物种栖息地改变。", # index 3
"关于可再生能源的讨论。", # index 4
]
print("--- 开始测试 SiliconFlow Rerank ---")
print(f"测试查询: {query}")
print("待排序文档:")
for i, doc in enumerate(documents):
print(f" [{i}] {doc}")
# 调用 Rerank API,请求 top 3
ranked_results = await call_siliconflow_rerank(
api_key=api_key,
query=query,
documents=documents,
model="BAAI/bge-reranker-v2-m3", # 或尝试 "netease-youdao/bce-reranker-base_v1"
top_n=3,
)
print("\n--- Rerank API 结果 ---")
if ranked_results:
print("排序后的 Top 结果 (原始索引, 相关性分数):\n")
for item in ranked_results:
original_index = item["index"]
score = item["relevance_score"]
print(f" 原始索引: {original_index}")
print(f" 相关性分数: {score:.4f}") # 格式化分数
if 0 <= original_index < len(documents):
print(f" 对应文档: {documents[original_index]}")
else:
print(" 错误:返回的索引超出范围!")
print("---")
else:
print("未能获取排序结果,请检查 API Key、网络连接或查看日志。")
print("--- 测试结束 --- ")
if __name__ == "__main__":
# 配置基本日志记录
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s - %(name)s - %(levelname)s - %(message)s",
)
logger.info("运行 remote-rerank.py 测试脚本...")
# 运行测试函数
asyncio.run(_test_rerank())
测试结果
PS D:\aProject\fastapi> & d:/aProject/fastapi/.venv/Scripts/python.exe d:/aProject/fastapi/src/utils/remote_rerank.py
2025-05-01 16:31:30,922 - __main__ - INFO - 运行 remote-rerank.py 测试脚本...
--- 开始测试 SiliconFlow Rerank ---
测试查询: 全球变暖的影响
待排序文档:
[0] 农业产量可能会受到极端天气事件的影响。
[1] 海平面上升是全球变暖的一个显著后果,威胁沿海城市。
[2] 冰川融化导致淡水资源减少。
[3] 生物多样性面临威胁,许多物种栖息地改变。
[4] 关于可再生能源的讨论。
2025-05-01 16:31:31,303 - httpx - INFO - HTTP Request: POST https://api.siliconflow.cn/v1/rerank "HTTP/1.1 200 OK"
--- Rerank API 结果 ---
排序后的 Top 结果 (原始索引, 相关性分数):
原始索引: 1
相关性分数: 0.9898
对应文档: 海平面上升是全球变暖的一个显著后果,威胁沿海城市。
---
原始索引: 3
相关性分数: 0.1014
对应文档: 生物多样性面临威胁,许多物种栖息地改变。
---
原始索引: 2
相关性分数: 0.0671
对应文档: 冰川融化导致淡水资源减少。
---
--- 测试结束 ---
融入 RAG 链
我们先来看结构草图:
- 未使用 重排序,base_retriever:
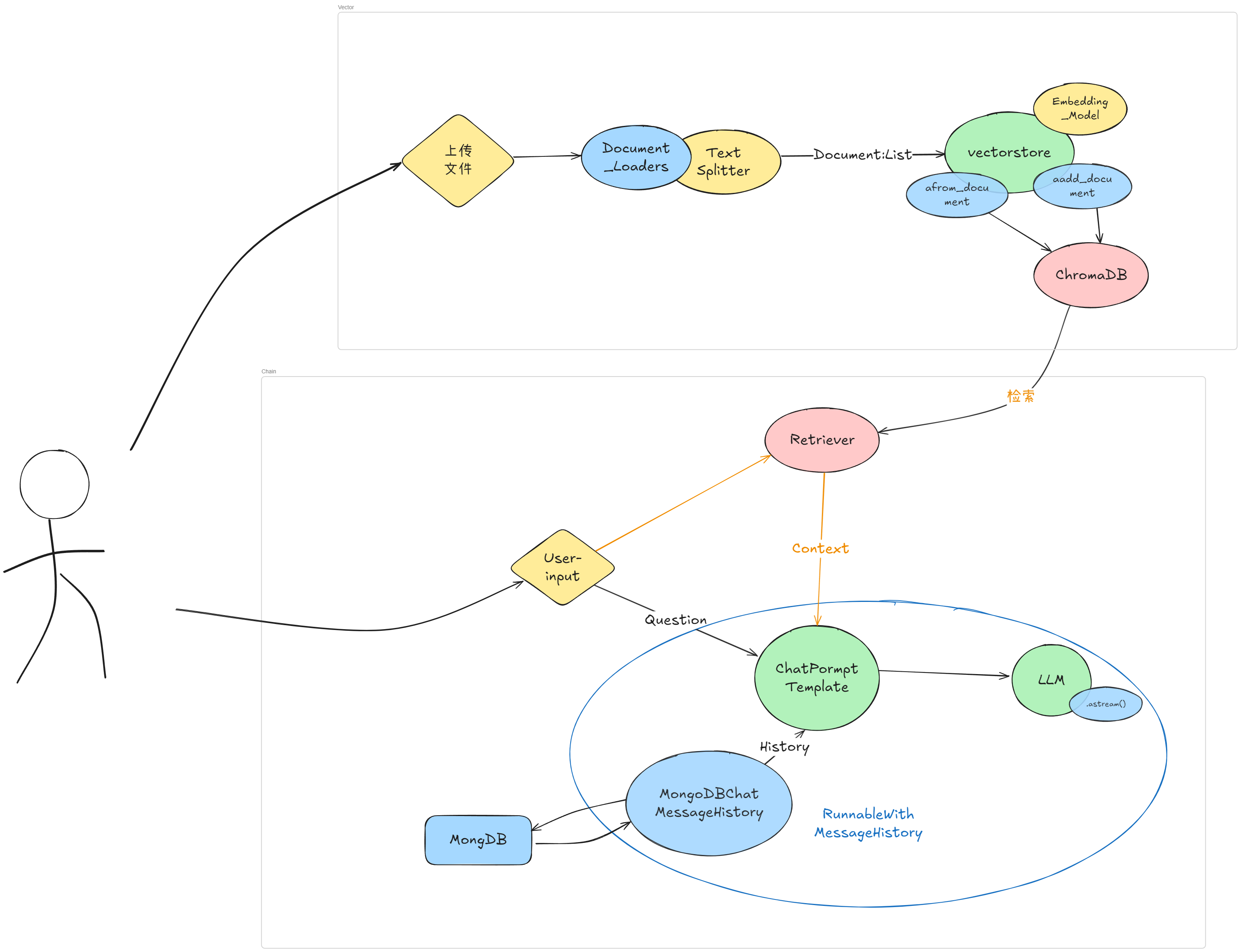
- 启用 重排序
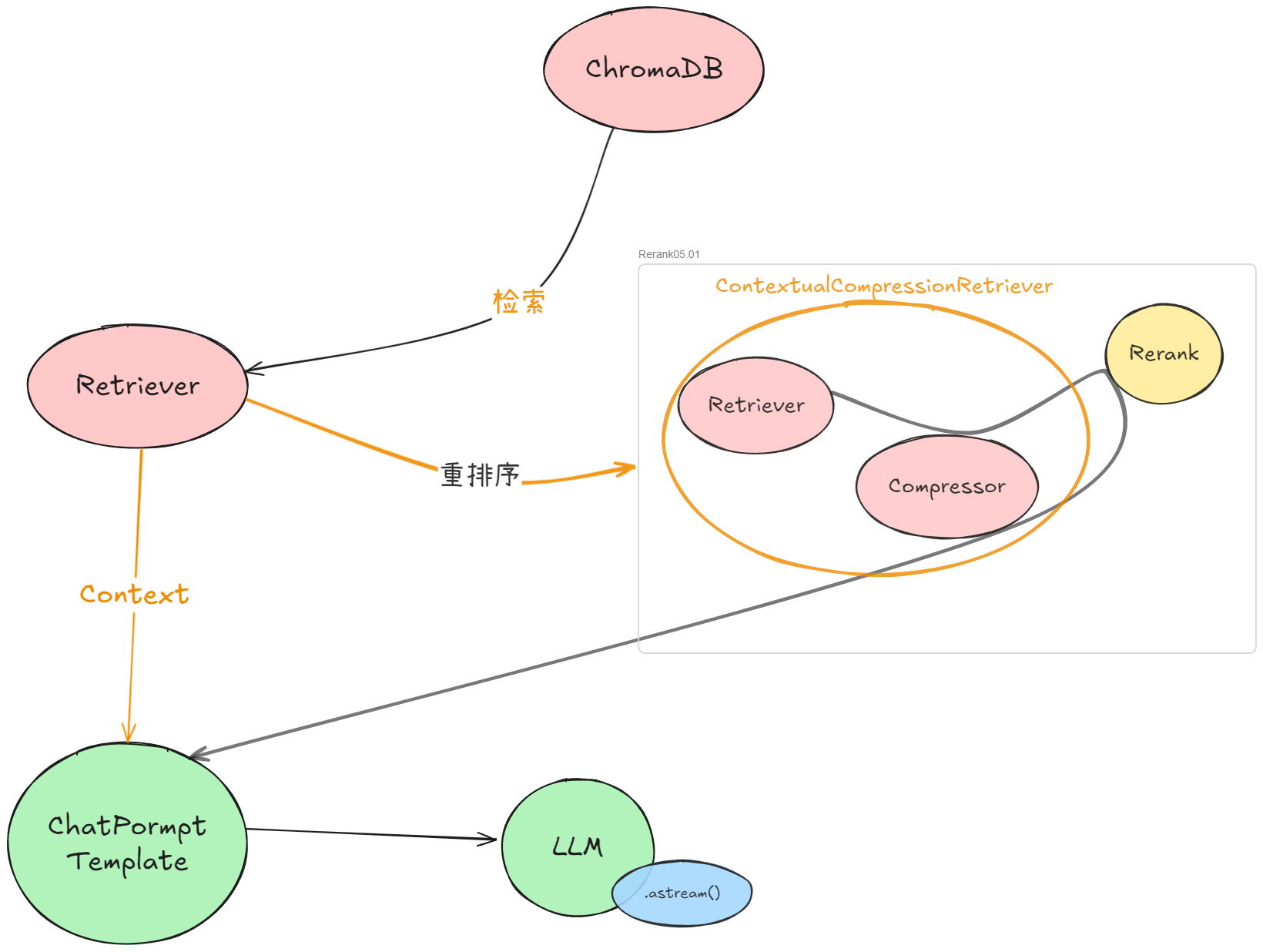
前面我们已经成功编写并测试了调用 SiliconFlow Rerank API 的函数 call_siliconflow_rerank。现在,关键的一步是如何将这个外部 API 调用优雅地整合进我们基于 Langchain 构建的 RAG (Retrieval-Augmented Generation) 链中。目标是让 RAG 链能够根据 API 请求的配置,灵活地选择使用本地重排序模型,或者调用 SiliconFlow 的远程服务。
Langchain 的重排序机制:ContextualCompressionRetriever
Langchain 提供了一个标准的组件来实现检索后处理(包括重排序和过滤),那就是 ContextualCompressionRetriever。它的工作方式是:
-
接收一个
base_retriever(基础检索器):这是我们原始的从向量数据库(ChromaDB)检索文档的 retriever。 -
接收一个
base_compressor(文档压缩器):这个压缩器负责处理base_retriever返回的文档列表,并输出一个更精简、更相关的文档列表。
重排序就是 base_compressor 的一种功能。Langchain 内置了一些 compressor,比如我们之前使用的基于本地 Cross-Encoder 的 CrossEncoderReranker。为了使用 SiliconFlow API,我们需要创建一个自定义的 compressor。
创建自定义 Compressor:RemoteRerankerCompressor
为了将 call_siliconflow_rerank 函数接入 Langchain 流程,我们需要创建一个自定义的文档压缩器类,让它继承自 Langchain 的 BaseDocumentCompressor 基类。我们在 src/utils/Knowledge.py 文件中定义了这个类:
# src/utils/Knowledge.py
# --- 自定义远程 Reranker Compressor ---
class RemoteRerankerCompressor(BaseDocumentCompressor):
"""
一个自定义的 Langchain 文档压缩器,
通过调用 SiliconFlow API 来对文档进行重排序。
注意:此类继承自 Langchain 的 BaseDocumentCompressor,
其配置参数通过类属性定义,由 Pydantic 处理初始化。
"""
# 将参数定义为类属性,而不是在 __init__ 中
api_key: str
"SiliconFlow API 密钥。" # Docstring for attribute
model_name: str = DEFAULT_REMOTE_RERANK_MODEL
"要使用的 SiliconFlow Rerank 模型名称。" # Docstring for attribute
top_n: int = 3
"返回最相关的 top_n 个文档。" # Docstring for attribute
# 移除了自定义的 __init__ 方法,以兼容 Pydantic 初始化
async def acompress_documents(
self,
documents: Sequence[Document],
query: str,
callbacks: Optional[Callbacks] = None,
) -> Sequence[Document]:
"""
异步压缩文档,通过调用 SiliconFlow API 进行重排序。
(方法内部逻辑调用 call_siliconflow_rerank)
"""
if not documents:
return []
if not self.api_key:
logger.error("缺少 SiliconFlow API key,无法执行远程重排序。")
return documents # 返回原始文档作为后备
doc_contents = [doc.page_content for doc in documents]
logger.debug(f"调用 SiliconFlow Rerank: query='{query[:50]}...', docs_count={len(doc_contents)}")
# 调用我们之前定义的 remote_rerank 函数
ranked_results = await call_siliconflow_rerank(
api_key=self.api_key, # 通过 self 访问由 Pydantic 初始化的值
query=query,
documents=doc_contents,
model=self.model_name, # 通过 self 访问
top_n=self.top_n, # 通过 self 访问
)
final_docs = []
if ranked_results:
logger.debug(f"SiliconFlow Rerank 返回 {len(ranked_results)} 个结果。")
# ... (处理 ranked_results,创建包含相关性分数的 Document 列表) ...
for result in ranked_results:
original_index = result.get("index")
score = result.get("relevance_score")
if original_index is not None and 0 <= original_index < len(documents):
original_doc = documents[original_index]
new_metadata = original_doc.metadata.copy() if original_doc.metadata else {}
new_metadata["relevance_score"] = score # 添加相关性分数
final_docs.append(
Document(page_content=original_doc.page_content, metadata=new_metadata)
)
else:
logger.warning(f"SiliconFlow 返回了无效的索引: {original_index}")
logger.info(f"远程重排序完成,返回 {len(final_docs)} 个文档。")
else:
logger.warning("远程 Rerank 调用失败或未返回有效结果,将返回原始文档。")
return documents # 返回原始文档
return final_docs
# 同步 compress_documents 方法 (可选实现或包装异步)
def compress_documents(...) -> Sequence[Document]:
# ...
关键点:
- 继承
BaseDocumentCompressor - Pydantic 兼容性: 我们遵循 Langchain/Pydantic 的最佳实践,将配置(
api_key,model_name,top_n)定义为类属性,而不是使用自定义的__init__。这解决了之前遇到的AttributeError: ... object has no attribute '__pydantic_fields_set__'问题。Pydantic 会负责这些属性的初始化。 - 调用外部 API:
acompress_documents方法是核心,它接收文档列表和查询,调用我们之前写的call_siliconflow_rerank函数,然后根据返回的排序结果(包含原始索引和分数)重新构建并返回排序后的Document列表。我们将相关性分数添加到了每个返回文档的metadata中,方便后续可能的使用。
更新核心逻辑:Knowledge 类
接下来,我们需要修改 src/utils/Knowledge.py 中的 Knowledge 类,使其能够根据传入的配置,决定是使用本地 Reranker 还是我们新创建的 RemoteRerankerCompressor。
- 修改
__init__方法:
我们更新了Knowledge类的初始化方法,添加了更精细的参数来控制重排序行为:
```python
# src/utils/Knowledge.py
class Knowledge:
def init(
self,
_embeddings=None,
splitter=“hybrid”,
# — 重排序相关配置 —
use_reranker: bool = False, # 是否启用重排序
reranker_type: Literal[“local”, “remote”] = “local”, # 重排序器类型
local_rerank_model_path: str = DEFAULT_LOCAL_RERANK_MODEL, # 本地模型路径
remote_rerank_config: Optional[Dict[str, Any]] = None, # 远程配置字典
rerank_top_n: int = 3 # 返回的文档数量
):
# … (存储这些配置到 self) …
self._embeddings = _embeddings
self.splitter = splitter
self.use_reranker = use_reranker
self.reranker_type = reranker_type
self.local_rerank_model_path = local_rerank_model_path
self.remote_rerank_config = remote_rerank_config if reranker_type == “remote” else None
# 验证远程配置…
self.rerank_top_n = rerank_top_n
logger.info(f"Knowledge 初始化: Reranker={‘启用’ if use_reranker else ‘禁用’}, Type={reranker_type if use_reranker else ‘N/A’}, TopN={rerank_top_n if use_reranker else ‘N/A’}")
```
2. 修改 get_retriever_for_knowledge_base 方法:
这是关键的决策点。在这个方法中,我们根据 self.use_reranker 和 self.reranker_type 来决定创建哪个 compressor:
```python
# src/utils/Knowledge.py
class Knowledge:
# …
def get_retriever_for_knowledge_base(
self, kb_id: str, filter_dict: Optional[dict] = None, search_k: int = 10
) -> BaseRetriever:
# … (加载向量数据库,创建 base_retriever) …
vectorstore = self.load_knowledge(kb_id_str)
base_retriever = vectorstore.as_retriever(search_kwargs=search_kwargs) # search_kwargs 包含 k
if self.use_reranker: # 检查是否启用重排序
logger.info(f"启用重排序 (类型: {self.reranker_type}, TopN: {self.rerank_top_n})…")
compressor: Optional[BaseDocumentCompressor] = None
if self.reranker_type == “local”:
# — 使用本地 CrossEncoder Reranker —
try:
# … (加载 HuggingFaceCrossEncoder) …
encoder_model = HuggingFaceCrossEncoder(…)
compressor = CrossEncoderReranker(model=encoder_model, top_n=self.rerank_top_n)
logger.info(“本地 CrossEncoderReranker 初始化成功。”)
except Exception as e:
# … (错误处理,回退到 base_retriever) …
return base_retriever
elif self.reranker_type == “remote”:
# — 使用远程 SiliconFlow Reranker —
if self.remote_rerank_config and self.remote_rerank_config.get(“api_key”):
try:
# 使用关键字参数初始化我们自定义的 Compressor
compressor = RemoteRerankerCompressor(
api_key=self.remote_rerank_config[“api_key”],
model_name=self.remote_rerank_config.get(“model”, DEFAULT_REMOTE_RERANK_MODEL),
top_n=self.rerank_top_n
)
logger.info(“远程 RemoteRerankerCompressor 初始化成功。”)
except Exception as e:
# … (错误处理,回退到 base_retriever) …
return base_retriever
else:
# … (API Key 未提供的错误处理) …
return base_retriever
else:
# … (未知 reranker_type 的处理) …
return base_retriever
# — 如果成功创建了 compressor,则包装 Retriever —
if compressor:
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=base_retriever
)
logger.info(“ContextualCompressionRetriever 创建成功。”)
return compression_retriever # 返回包装后的 retriever
else:
# … (Compressor 创建失败的回退) …
return base_retriever
else:
# — 不使用重排序 —
logger.info(“重排序未启用,返回基础检索器。”)
return base_retriever # 返回原始的 base_retriever
# … (异常处理) …
```
配置 API 接口:chatRouter.py
最后,为了让前端或 API 调用者能够控制使用哪种 Reranker 并提供必要的配置(特别是 SiliconFlow API Key),我们需要修改 FastAPI 路由层 (src/router/chatRouter.py)。
- 定义 Pydantic 配置模型:
我们定义了一个新的 RerankerConfig 模型,并用它替换了 KnowledgeConfig 中原来的 is_reorder: bool 字段。
```python
# src/router/chatRouter.py
from typing import Literal, Optional, Dict, Any
class RerankerConfig(BaseModel):
use_reranker: bool = Field(default=False, …)
reranker_type: Literal[“local”, “remote”] = Field(default=“local”, …)
remote_rerank_config: Optional[Dict[str, Any]] = Field(default=None, …)
rerank_top_n: int = Field(default=3, …)
class KnowledgeConfig(BaseModel):
knowledge_base_id: str
filter_by_file_md5: Optional[str] = None
search_k: Optional[int] = Field(default=10, …) # 基础检索 k
reranker_config: RerankerConfig = Field(default_factory=RerankerConfig) # 使用新模型
```
2. 更新依赖注入函数 get_chat_service:
这个函数负责根据 API 请求创建 ChatSev 实例。我们需要修改它,以解析新的 reranker_config 并将其传递给 Knowledge 类的构造函数。
```python
# src/router/chatRouter.py
async def get_chat_service(request: ChatRequest) -> ChatSev:
knowledge_instance: Optional[Knowledge] = None
if request.knowledge_config:
try:
# … (获取 embedding) …
_embedding = get_embedding(…)
# 从 request 中获取 reranker 配置
reranker_cfg = request.knowledge_config.reranker_config
knowledge_instance = Knowledge(
_embeddings=_embedding,
splitter=“hybrid”,
# — 传递 Reranker 配置 — #
use_reranker=reranker_cfg.use_reranker,
reranker_type=reranker_cfg.reranker_type,
# local_rerank_model_path 使用 Knowledge 类中的默认值
remote_rerank_config=reranker_cfg.remote_rerank_config,
rerank_top_n=reranker_cfg.rerank_top_n
)
except Exception as e:
# … (错误处理) …
knowledge_instance = None
# 创建 ChatSev 实例
chat_sev = ChatSev(knowledge=knowledge_instance, …)
return chat_sev
```
工作流程总结
现在,整个流程是这样的:
-
用户通过 API (例如
/chat/stream) 发送请求,请求体中包含knowledge_config,其中嵌套了reranker_config,指定是否启用、使用哪种类型(local/remote)以及远程 API Key。 -
FastAPI 的依赖注入系统调用
get_chat_service函数。 -
get_chat_service解析请求中的reranker_config,并用这些配置初始化Knowledge类实例。 -
当
ChatSev中的stream_chat方法需要检索文档时,它会调用Knowledge实例的get_retriever_for_knowledge_base方法。 -
get_retriever_for_knowledge_base根据初始化时收到的配置:
- 如果 use_reranker 为 False,返回基础的 VectorStoreRetriever。
- 如果 use_reranker 为 True 且 reranker_type 为 local,创建本地 CrossEncoderReranker 并包装成 ContextualCompressionRetriever 返回。
- 如果 use_reranker 为 True 且 reranker_type 为 remote,创建我们自定义的 RemoteRerankerCompressor(传入 API Key 等),并包装成 ContextualCompressionRetriever 返回。
- RAG 链(
create_retrieval_chain)使用这个最终返回的 retriever 来获取(可能经过重排序的)文档,然后传递给 LLM 生成答案。
如何使用远程 Rerank
现在,只需要在 API 请求的 knowledge_config 中进行如下配置,即可启用 SiliconFlow 远程重排序:
{
// ... 其他字段如 question, session_id, llm_config ...
"knowledge_config": {
"knowledge_base_id": "your_kb_id",
"search_k": 10, // 建议 > rerank_top_n * 2
"reranker_config": {
"use_reranker": true,
"reranker_type": "remote",
"rerank_top_n": 3,
"remote_rerank_config": {
"api_key": "YOUR_SILICONFLOW_API_KEY",
"model": "BAAI/bge-reranker-v2-m3" // 可选,会覆盖默认值
}
}
}
// ... chat_config ...
}
至此,我们成功地将 SiliconFlow 的第三方重排序服务无缝地集成到了 RAG 链中,并通过 API 实现了灵活配置,解决了本地模型性能不足的问题。
Look|效果
…待实际环境测试
以上就是本期的全部内容,谢谢你的到来,我们下期再见
关于作者
- CSDN 大三小白新手菜鸟咸鱼本科生长期更新强烈建议不要关注!
作者的其他文章
RAG调优|AI聊天|知识库问答
- 你是一名平平无奇的大三生,你投递了简历和上线的项目链接,结果HR真打开链接看!结果还报错登不进去QAQ!【RAG知识库问答系统】新增模型混用提示和报错排查【用户反馈与优化-2025.04.28-CSDN博客
- 你知不知道像打字机一样的流式输出效果是怎么实现的?AI聊天项目实战经验:流式输出的前后端完整实现!图文解说与源码地址(LangcahinAI,RAG,fastapi,Vue,python,SSE)-CSDN博客
- 【Langchain】RAG 优化:提高语义完整性、向量相关性、召回率–从字符分割到语义分块 (SemanticChunker)-CSDN博客
- 【MCP】哎只能在cursor中用MCP吗?NONONO!三分钟教你自己造一个MCP客户端!-CSDN博客
- 如何让你的RAG-Langchain项目持久化对话历史\保存到数据库中_rag保存成数据库-CSDN博客
- 分享开源项目oneapi的部分API接口文档【oneapi?你的大模型网关】-CSDN博客



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











