







1.requests库的安装
rrequests库是公认的python的一个一个非常优秀的第三方库,下载方法也很简单
只需Win+R打开控制台命令窗口,输入pip install requests后回车等待安装成功即可
如下图
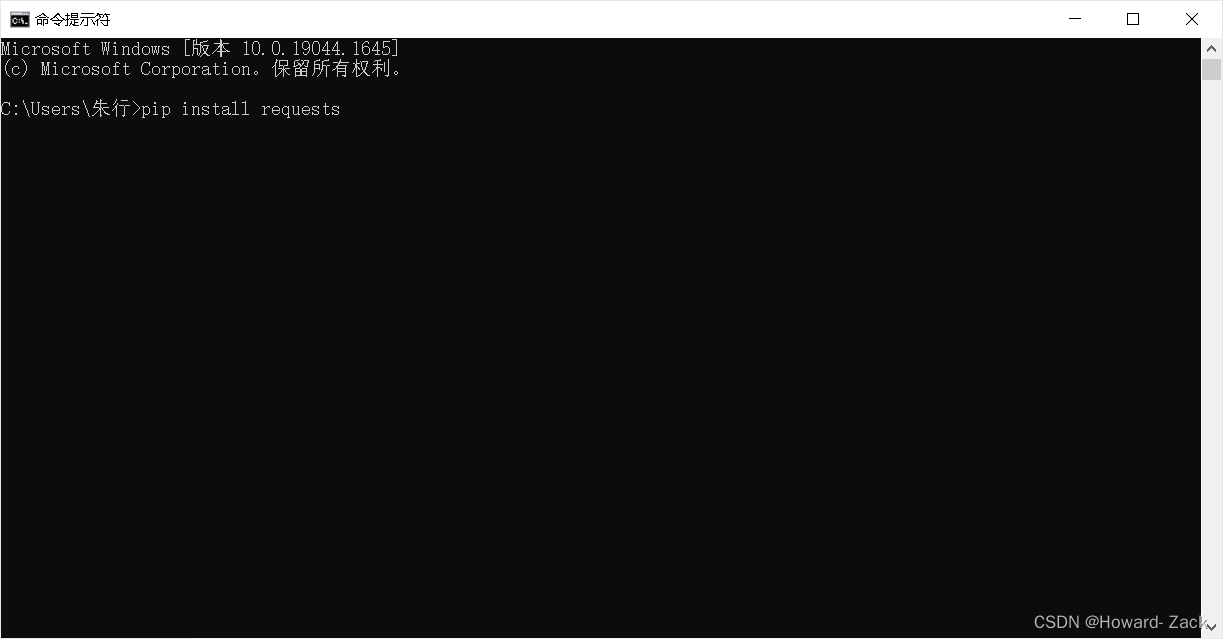
安装好后我们就可以使用request库的方法来获取网页上的一些资源
2.下面介绍用request库的request.get()方法获取网页的图片资源
首先,我们要打开想要下载的图片所在网页,比如在必应中搜索天空的图片,打开后,右键复制图片的地址,即url,注意,要右键点击复制图像链接,而不是复制网页顶端的url
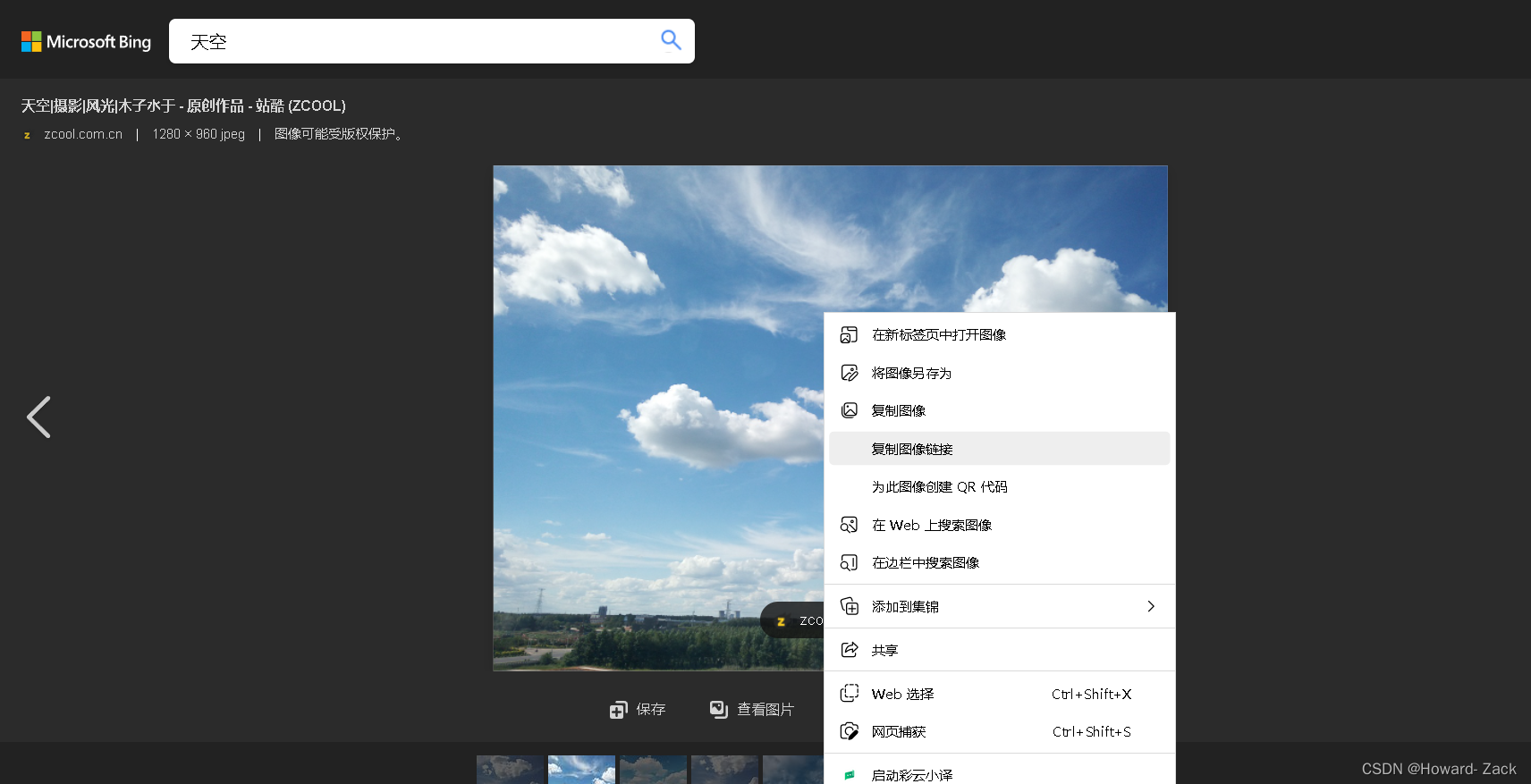
然后打开pycharm 输入如下代码
import requests
# 首先要引入requests库
path = "D:/a.jpg"
# 这里的储存路径可以自己设置,格式按照你找到图片的链接格式即可,比如本例的图片格式在url末端可以看到是jpg格式的
url = "https://img.zcool.cn/community/013f9e590a874ca801214550bfaf1a.jpg@1280w_1l_2o_100sh.jpg"
r = requests.get(url)
print(r.status_code)
# 这句话 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3074
3074











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









