






1、K-邻近算法概述
用官方的话来说,所谓K-近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例(也就是上面所说的K个邻居), 这K个实例的多数属于某个类,就把该输入实例分类到这个类中。
1.1K-邻近算法的优缺点
优点:
1、思想简单、效果强大。
2、天然可解决多分类问题。
3、重新训练的代价较低(类别体系的变化和训练集的变化,在Web环境和电子商务应用中是很常见的)。
4、计算时间和空间线性于训练集的规模(在一些场合不算太大)。
缺点:
1、效率低下,如果训练集有m个样本,n个特征,则预测每一个新的数据,计算复杂度O(m*n)
2、高度数据相关,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数;对数据的局部结构比较敏感。如果查询点是位于训练集较密集的区域,那预测相对比其他稀疏集来说更准确。
3、预测结果不具有可解释性,只是找到了预测样本距离最近的样本点,不知道为什么属于预测类别。
4、维数灾难:随着维度增加,看似距离很近的2个点距离越来越大。
1.2K-近邻算法对工作原理
对于一个新样本,K近邻算法的目的就是在已有数据中寻找与它最相似的K个数据,或者说“离它最近”的K个数据,如果这K个数据大多数属于某个类别,则该样本也属于这个类别。
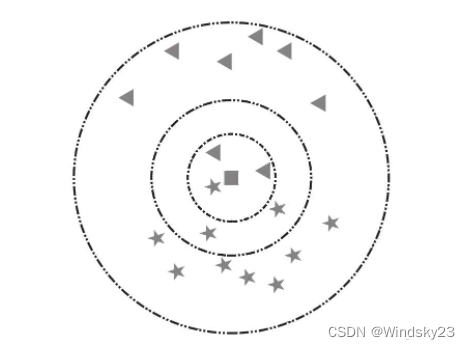
(K的含义)以下图为例,假设五角星代表爱情片,三角形代表科幻片。此时加入一个新样本正方形,需要判断其类别。当选择以离新样本最近的3个近邻点(K=3)为判断依据时,这3个点由1个五角星和2个三角形组成,根据“少数服从多数”原则,可以认为新样本属于三角形的类别,即新样本是一部科幻片。同理,当选择离新样本最近的5个近邻点(K=5)为判断依据时,这5个点由3个五角星和2个三角形组成,根据“少数服从多数”原则,可以认为新样本属于五角星的类别,即新样本是一部爱情片。
1.3K-邻近算法的一般流程
1.计算已知类别数据集中的点与当前点之间的距离;
2.按照距离递增次序排序;
3.选取与当前点距离最小的𝑘个点;
4.确定前𝑘个点所在类别的出现频率;
5.返回前𝑘个点所出现频率最高的类别作为当前点的预测分类。
1.4距离计算
通常KNN算法中使用的是欧式距离,其实就是计算(x1,y1)和(x2,y2)的距离,拿二维平面为例,二维空间两个点的欧式距离计算公式如下:
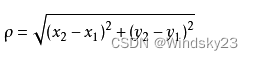
例如:点(0,0)和(1,2)的距离计算为:
![]()
1.5K值的选择
对于K值的选择,一般根据样本分布选择一个较小的值,然后通过交叉验证来选择一个比较合适的最终值;
K值小,相当于用较小的领域中的训练实例进行预测,只要与输入实例相近的实例才会对预测结果,模型变得复杂,只要改变一点点就可能导致分类结果出错,泛化性不佳。(学习近似误差小,但是估计误差增大,过拟合)
K值大,相当于用较大的领域中的训练实例进行预测,与输入实例较远的实例也会对预测结果产生影响,模型变得简单,可能预测出错。(学习近似误差大,但是估计误差小,欠拟合)
极端情况:K=0,没有可以类比的邻居;K=N,模型太简单,输出的分类就是所有类中数量最多的,距离都没有产生作用。
什么是近似误差和估计误差:
近似误差:训练集上的误差
估计误差:测试集上的误差
1.6实例分析
雅思和托福考试是留学的必要准备,其中雅思考试主要适合英式英语的国家,如英国、澳大利亚等;托福考试主要适合美式英语国家,如美国、加拿大等。现根据几位同学更喜欢哪种英语来判断他们需要进行雅思考试还是托福考试。数据如图所示:
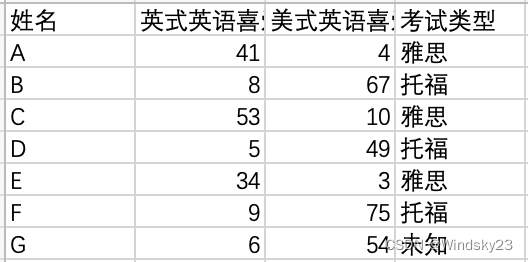
计算未知学生与样本集中其他学生的距离,如下图所示:
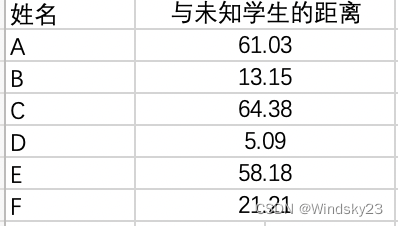
现在我们得到了样本集中所有学生与未知学生的距离,按照距离递增排序,可以找到k个距
离最近的学生。假定k=2,则两个最靠近的学生依次是学生B、D,k-近邻算法按照距离最近的两名学生的考试类型,决定未知学生的考试类型,而这两名全是托福考试,因此我们判定未知学生考试类型为托福。
2、python代码实现
导入科学计算包Numpy,运算符模块
from numpy import *
import operator
# 训练样本集以及对应的类别
def createDateSet():
group = array([[41,4], [8, 67], [53, 10], [5, 49], [34, 3], [9, 75]])
labels = ['雅思', '托福', '雅思', '托福', '雅思', '托福']
return group, labels根据k-近邻算法流程编写代码
def classify(inX, dataSet, labels, k):
# dataSetSize是训练样本集数量
dataSetSize = dataSet.shape[0]
# 根据欧式距离公式计算已知点和未知点的距离
# tile函数,把inX变成能与dataSet相减的二维数组
diffMat = tile(inX, (dataSetSize, 1)) - dataSet
sqDiffMat = diffMat ** 2
# axis=1是列相加求和,即得到(x1-x2)^2+(y1-y2)^2的值
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances ** 0.5
# 按照距离递增次序排序,返回下标
sortedDistIndicies = distances.argsort()
# 选择与当前点距离最小的k个点
classCount = {}
for i in range(k):
voteILabel = labels[sortedDistIndicies[i]]
classCount[voteILabel] = classCount.get(voteILabel, 0) + 1
# 确定前k个点所在类别的出现频率
# 按照字典里的关键字的值排序,reverse=True降序排序
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
# 返回前k个点中出现频率最高的标签
return sortedClassCount[0][0]classify( )函数有4个输入参数:用于分类的输入向量是inX,输入的训练样本集为dataSet,标签向量为labels,最后的参数k表示用于选择最近邻居的数目,其中标签向量的元素数目和矩阵dataSet的行数相同。
测试算法
i = 0
print("训练样本集")
group, labels = createDateSet()
for item in group:
print('学生姓名%c:英式英语喜爱程度%3d 美式英语喜爱程度%3d 考试类型 %s' % (chr(ord('A') + i), item[0], item[1], labels[i]))
i += 1
print("\n测试数据集")
myTests = array([[6,54]])
myLabels = []
for i in range(1):
myLabels.append(classify(myTests[i], group, labels, 2))
print('学生姓名%c:英式英语喜爱程度%3d 美式英语喜爱程度%3d 考试类型 %s' % (
chr(ord('G') + i), myTests[i][0], myTests[i][1], myLabels[i]))
输出结果
















 362
362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









