






目录
2.HDFS的优点:
3.HDFS的缺点:
5.块的介绍和使用:
7.HDFS API
9.Namendoe与scondarynamenode的工作原理
定义:HDFS是海量数据分布式存储系统
HDFS的优点:
高容错性(自动保存多个副本(默认3份副本),提高容错,当一个副本丢失后能自动恢复,)
适合大规模存储数据(采用了分布式存储的思想,以块的形式分别存储在datanode阶段中实现大规模数据的存储)
可以搭建在廉价的机器上
HDFS的缺点:
不支持修改,但可以追加
不支持低延迟访问(HDFS文件系统是数据的查找方式为顺序访问,检索时间长)
不适合存储大量小文件(HDFS的设计目的是为了存储大文件,因为采用的块(blak)的设计方式,每一个小文件都会,占用块信息。而存储元数据的只有namenode,namnodee而内存有限,这样会增大namenode的压力,而且寻址时间也变比读取数据长)
HDFS 的组成:
Namenode:
1.负责处理client的请求(读写)
2.负责管理块信息的映射
3.负责分配副本的
4.负责管理命名空间
Secondary
1.协助namenode工作,合并(fsimage,和edits)
2.紧急情况可以回复namenode的部分功能,但不能替代那么namenode的的工作
Datanode
- 存储实际的块数据
- 执行读写操作
Clinet:
- 负责将文件切块
- 负责与namenode交互
- 负责与datanode交互
- 负责对hdfs的增删查操作
块:
是HDFS的最小存储单位(可自定义大小)2.x默认64M 3.x默认128M
块的大小的配置与磁盘的传输速率有关:如果磁盘为100m/s则设立块大小为128
如果磁盘为200m/s 则设立块大小为256
如果块太大则处理块的数据会很慢。如:100m/s的 磁盘速率 如果 1Gb的块,虽然定位到这块的时间短但处理要很久
如果块太小,则会导致块很多,寻址时间会很长
HDFS的shell命令:
因为hdfs的shell命令与Linux的相似则只记一下重点
-ls -ls <路径> 查看指定路径的当前目录结构
-lsr -lsr <路径> 递归查看指定路径的目录结构
-du -du <路径> 统计目录下各文件大小
-dus -dus <路径> 汇总统计目录下文件(夹)大小
-count -count [-q] <路径> 统计文件(夹)数量
-mv -mv <源路径> <目的路径> 移动
-cp -cp <源路径> <目的路径> 复制
-rm -rm [-skipTrash] <路径> 删除文件/空白文件夹
-rmr -rmr [-skipTrash] <路径> 递归删除
-put -put <多个linux上的文件> <hdfs 路径> 上传文件
-copyFromLocal -copyFromLocal <多个linux 上的文件> <hdfs 路径> 从本地复制
-moveFromLocal -moveFromLocal <多个linux 上的文件> <hdfs 路径> 从本地移动
-getmerge -getmerge <源路径> <linux 路径> 合并到本地
-cat -cat <hdfs 路径> 查看文件内容
-text -text <hdfs 路径> 查看文件内容
-copyToLocal -copyToLocal [-ignoreCrc] [-crc] [hdfs 源路径] [linux 目的路径] 复制到本地
-moveToLocal -moveToLocal [-crc] <hdfs 源路径> <linux目的路径> 移动到本地
-setrep -setrep [-R] [-w] <副本数> <路径> 修改副本数量
-mkdir -mkdir <hdfs 路径> 创建空白文件夹
-touchz -touchz <文件路径> 创建空白文件
-stat -stat [format] <路径> 显示文件统计信息
-tail -tail [-f] <文件> 查看文件尾部信息
-chmod -chmod [-R] <权限模式> [路径] 修改权限
-chown -chown [-R] [属主][:[属组]]路径 修改属主
-chgrp -chgrp [-R] 属组名称 路径 修改属组
-help 帮助
HDFS API
1在windows下配置Hadoop依赖的环境变量 (根据安装的Hadoop版本选择依赖)
2创建maven工程
3在pom中</project> 上添加依赖如下
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
</dependencies>4在项目的 src/main/resources 目录下,新建一个文件,
命名为“log4j.properties”,为了打印日志
在文件中输入
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
HDFS的读写流程:
写数据
- client请求上传文件
- Namenode检查是否有权限,文件是否存在,并返回响应
- Clinet请求上传第一个块,请求返回上传位置
- Namenode,根据距离最近,和负载情况分配节点
- Client与datanode节点建立传输通道创建输出流,打包chunk,生成一共packet文件传输一份写如磁盘一份写入内存,然后在穿给下一个datanode,直到执行完成,最后一个节点往前应答成功到第一个节点,最后关闭输出流
读流程
- client请求读取文件
- Namenode检查是否有权限,文件是否操作,放回目标文件的元数据
- Client创建输入流,根据元数据找到块的位置读取数据(根据节点最近与负载情况访问节点)
- 返回读到的数据给client
节点距离的计算问题:
节点距离等于共同祖先的距离之和
互联网 是机房祖先 机房是机架祖先
网络拓扑结构
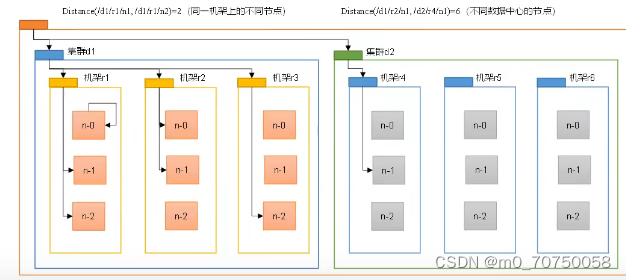
机架感知(副本的选择)
第一个副本选择client在的节点上
第二个副本选择client的之外的集群中的节点(保证容错)
第三个副本选择第二个副本在的集群的其他节点(保证传输速率)
Namendoe与scondarynamenode的工作原理
Namenode对元数据的存储方式
- 内存
- Fsimage 负责存数据
- Edits 负责记录操作
- Namenode启动时将edits与fsimage加载到内存中
- Client提出元数据的增删改
- Edits先记录增删改操作
- 然后对内存fsimage数据进行修改
- Fsimage与edits合并成为最新的文件
Secondarynamenode会对namenode发出请求是否需要合并文件checkpoint(1.定时合并,设定大小满则合并) 减少namenode的负担
查看Fsimage的语法 hdfs oiv -p XML - i [ file_name ] -o [ path ]
查看Edits的语法 hdfs oev -p XML - i [ file_name ] -o [ path ]
Datanode的工作原理
Datanode 维护具体的数据,数据长度,时间戳,校验和
流程:1.datanode启动时会向namenode注册并上报块的信息,块是否完整
2.namenode记录元数据信息,
3.Datanode定期向namenode上报块信息
4.Datanode每3秒一次心跳汇报是否活着
5.认为挂掉 10分+最后30s (根据机器性能决定)















 5138
5138











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









