






目录
第一章 数据分析过程
第四章 数据处理pandas库 pandas库 dataframe 数据结构
第五章 pandas读取文件
第六章 pandas datafame对数据的筛选与访问
str.startswith (),str.endswith () 匹配开头和结尾
第十章数据可视化 推荐使用第三方的的bi平台,可视化效果更好,更高效
第十一章 描述性数据分析
第十二章 重采样resample
第一章
数据分析的步骤
- 提出问题 一个好的可以很好帮助我们去分析处理数据
- 准备数据 方式:1.观测统计 2.问卷调查 3. 数据库 4. 爬虫
- 处理和清洗数据 处理异常值 缺省值 重复值
- 数据分析
探索性数据分析:是指仅有一些非常浅的假设,通过数据分析方法,深入探索数据。
三大作用 : 分析现状 对比
分析结果 细分
预测未来 预测
数据分析的基本思路 对比 细分 预测
对比
对比:对比数据的高低,分析数据的差异, 差距
对比的思路 :就是环比和同比
同比:本期数据与过往同一起数据的对比
例如2020二季度GDP的同比增长,是和2019二季度GDP对比 可以消除不同季节的影响因数
环比:本期数据和下一个连续数据的对比 可以观测到数据的变化趋势
细分
细分:细分是指数据划分不同的部分,从而对比内部个部分之之间的异同和关系
细分方法:杜邦分析方法 :将要分析的数据指标不断拆分影响他的细分指标
预测:预测是预测未来数据的,挖掘数据之间的关系
预测通常要通过建立数学模型来实现
预测常用的一般分为:相关性分析 回归分析 时间序列模型
- 可视化得出结论
通过第一章的学习,掌握了数据分析的流程,已经数据分析所用的方法和思路来对数据的分析预测得出结论
第二章
数据分析所用的库(Numpy )
Numpy:是一个开源的,用于数组的科学计算模块,里面提供的许多数学模块
为什么要用numpy ,很多模块都依赖与numpy 如(pandas)numpy是一个科学计算模块,提供了科学计算的函数,可以减少我们进行数据分析时所要写的循环代码,提高我们的计算速度
n维数组:是一个多维数组:描述相同数据类型的数据集合
n维数组分两属性:1.数据类型 2.维度
维度:一维指长度,二维指长,宽度,
多个元素组成一维数组
多个一维数组组成二维数组
三维同理
在numpy中
创建n维的函数:array() 最外层中括号的是数组的维度
Array可把列表,元组转为n维数组
二维数组的运算
N维数组的计算可以大致分为两个方向
+,- ,*,/ 每个数据都进行相应的运算上
两二维的运算
相同的形状的数组才可以进行运算
+ - * /对应位置相加减
第三章
Pandas库
pandas是一个基于NumPy的模块,它的功能在于数据的筛选清洗和处理,与NumPy模块相比,pandas模块更擅长处理二维数据。
Pandas模块 主要两个结构 series(序列) 和datafram
Series是一种带有索引的数组
Series的结构
左边为索引index 右边位置 values 最下边为数据类型 dtype
Series与字典类似,不同的是,series是有序的除了通过索引访问,也可以通过下标位置访问 ,如果没有定义index 则index默认从0开始
构造series结构
Pandas提供了series函数来构造 第一个参数为data数组,第二个参数为index数组没有则默认0开始
Pd.Series(data=data,index=index)
Series结构如图

Series的访问方式为 1 索引访问和 2 位置访问
Series常用的三种属性 dtype 返回series对象的类型
values返回series对象的所有数据
Index 返回series对象的索引
第四章
dataframe是pandas下的一种结构
Dataframe与series类似不同的是dataframe是用于二维数组的
Dataframe,是一个二维的数据表, 是series的集合
Dataframe的结构为
有行索引和列索引
行索引定位到相应的行位置上 index
列索引定位到相应的列位置上 cloumns
通过行和列索引来定位二维数组中的数据
Dataframe的使用
Pd.DateFrame(data=data,index=index,columns=columns)
data是嵌套列表
Data如果是字典{key:[value1,value2]}则key为列索引
如果columns没有给出,则默认从0开始
DataFram 的三种常用属性 1.Dtypes
- Values 返回二维数组
- index 返回索引
- Axis(轴) 轴是为超一维的数组用来定义属性的
Axis=0为垂直方向的Axis=1为水平方向的轴
axis属性是用来对某一个方向的进行计算
如:df.mean(axis=0)对每一列进行求平均值
Df.sum(axis=1)对每一行的数据进行求和
DataFrame中的index可以被重新赋值
第五章
Pandas作为数据处理的模块所需要的数据一般从excel和csv文件中来
一般使用dataframe来对数据的处理
Cvs 是一种一纯文字的形式来存储表格数据
Pandas读取csv的方式为:
data=pd.read_csv(encoding=’utf-8’,index_col='列名',usecols=[ ] ,names=[ ])
以下可选参数:
1. 防止乱码 - encoding="utf-8"
2. 指定index - index_col
3. 读取指定列 - usecols
4. 添加columns - header=None 和 names
data.to_csv()#将读取到的数据导到指定路径
如果只写给路径参数会将索引写入csv的第一列
参数 index=False不会将索引写入第一列
参数 encoding=’utf-8-sig’可以防止乱码
使用excel来读取文件
读取excel需要使用 xlrd 模块来辅助
Excel的两种文件格式 xls xlsx
在pnads中读取文件的方式为:
Pd.read_excle(path=’路径’,Sheet_name=’工作表的名字’)
读取工作表 :在一个excel中可能会多个工作表 所以我们要指定工作表
Sheet_name来读取指定的工作表
第六章
访问pandas中的数据
4种方式访问索引
1列索引 访问列数据 单列 如: data[“price”]
访问多列 data[["payment" , "price" , "cutdown_price" ]]
2 .loc属性 通过索引的值访问行数据和元素
访问单行 data.loc[0]
访问多行data.loc[0:15]
访问不联系的多行 data.loc[[0,2,5,6,8]]
访问单个数据data[1,’price’]
访问多个元素data.loc[0:7,”payment”:”cutdown_price”]
3 .iloc属性:通过索引的位置访问行数据和元素
访问1行 data.iloc[0]
访问第3行5列 data.iloc[2,4]
访问2行4列,3行,4列的 data.iloc[[1,3],[2,3]]
4 行列索引的结合:访问元素
布尔索引
查找满足条件的的行数据 =>,<=,>,<,==
Data[Data["cutdown_price"]>0]
Data[] 筛选的对象数据
Data["cutdown_price"]>0 筛选的条件表达式
多条件表达式 & | ~
Data[(data[ "cutdown_price"]>0) | (data[‘price’]>0) ]
拿到数据要做一些简单的处理也叫做数据的预处理
常见的数据预处理包括 数据类型的转换 和 index的转换
- 时间数据类型
- 字符数据转时间函数
- 时间转字符函数
- 格式转换函数
时间数据是一种结构化数据形式
时间运算有自己的规则与基本数据类型不一样
时间数据的三种形式对于三种时间数据类型
2020/09/30 12:00:00 datetime
2020/09/30 12:00:00 timedelta
2020年9月 period
在构造时间是是以字符的格式存入 无法对时间进行运算的
我们可以用python自带的datetime模块中的datatime数据类型来构建
例如:from datetime import datetime
#2022-10-7 22:10 可以精确到秒
Start=datetime(2022,10,7,22,10)
对于从excel与csv中读取到的都是字符串类型
如果要将时间转为datetime就要使用pandas提供的to_datetime()函数
在实际应用中我们只需要年月日
后缀.dt 可以吧时间数据类型转换成我们便于提取的日期和时间对象
对象中包含许多属性:如 year month day
例如 da[“pay_time”].dt.year 提该列取年
da[“pay_time”].dt.month 提取该列的月
对于后续的分组和可视化时要使用年月日的字符串类型
Strftime()函数 可以将时间数据类型转为字符数据类型
例如
将时间时间类型后缀化了才可以strftime
da[“pay_time”].dt.strftime(“%y-%m”)
da[“pay_time”].dt.strftime(“%y年%m月”)
y年 m月 M 分 H 小时 u 星期
以上是数据类型与字符串之间的转换
基本数据类型在一定条件下也可以实现数据类型的相互转换
通过 astype() 函数来转换
第八章聚合函数
在dataframe中常对水平方向和垂直方向进行聚合
所用到的参数为axis=0(垂直) axis=1(水平)
常用的聚合函数为 count ,sum ,mean , median min max
对单列聚合
Data【“price”】.mean( )
四舍五入函数 round(n)
n为正保留 n位小数
n为0 为整数
n为负 -1十位 -2百位 以此类推
对多列进行聚合
Data[[“price”,”number”]].mean()
- 实战案例
为分析那火锅店的火锅好吃,从而通过爬虫爬取店铺的评论数据对此展开分析
回顾 读取数据的方式有 iloc 位置读取 loc索引值读取 列名读取
对其读取前n行方法 data.iloc[:n]
Data.head(n) 不加参数默认前5行
查找含有莫个字的字符串
通配筛选字符 data[“name”].str.contains(“ 汤”)
设置索引 data.set_index(“name”)
Data[“price”].idxmax() 返回最大值的索引
Resetindex() 重置索引用默认值代替
需求一
小明想要指定那家牛肉火锅好吃在爬下的 火锅评论.csv文件中 找到评分最高的
| 店铺名称 | 口味评分 | 服务评分 | 环境评分 | 人均消费 |
代码如下
import pandas as pd
Df=pd.read_csv(“../火锅评论.csv”)
Beef=Df[Df[“店铺名称”].str.contains(“牛”)]
Max_score=Beef[“口味评分”].idxmax()
print(Max_score)
str.startswith (),str.endswith () 匹配开头和结尾
需求二
小名想找到性价比高的,适合聚会的火锅店 性价比为: (口味评分/价钱比) *40
适合聚合 (服务评分+环境评分)/2
将的到的性价比 和平均氛围加到data列中
添加列的方式为 data[“性价比”]=(data[“口味评分”]/data[“人均消费”])*40
对列进行排序 sort_values(by=”性价比”,ascending=False) 默认升序
- 数据的清洗
当我们拿到数据后 ,第一件事就是对数据的清洗,避免脏数据对分析结果的影响
脏数据:是错误的数据,没有任何意义的数据
缺省值:值为空 info()哪一列为空 isnull() 判断是一行否为空
重复值:在值唯一的地方重复
异常值:不合理的,超出规定范围的值
缺省值的处理方式 删除,补充,修改
删除: 如果缺失数据少则删除缺失数据所在的行 如:10w的数据 300行缺失对数据分析影响不大 删除数据使用的函数为 drop(index=index,inplace=True)默认为true 是否对当前对象生效
补充:如果缺省值缺失过多且这一列的缺省值不是分析重点则对其进行补充 所用到的函数为 data[“time”].fillan(value,inplace=True) 如果缺失过多的是分析重点,则需要重新采集数据fillan
异常值的处理方式
查找异常值 通过bool语句查找异常值是否在氛围内
Data[“price”].isin([20,60,40])判断这一列是否在这个列表中内
~运算符 对结果进行取反~Data[“price”].isin([20,60,40])
判断是否有重复值 duolicated()函数 duolicated
数据清洗的步骤要按
缺省值-异常值-重复值顺序进行
因为去除重复值的适合可能把正确的数据去掉,保留异常值
第十章数据可视化
所用到的库为matplotlib
Matplotlib是python的基本绘图模块,包含大量的工具,可以创建简单的图像,也可以创建复杂的三维图像,在matplotlib中有一个模块 pyplot,数据分析常用这个模块
Matplotilb组成元素 画布 坐标 图像标题

一个画布至少包含一个坐标
画完坐标后 在坐标上添加 图形,标记
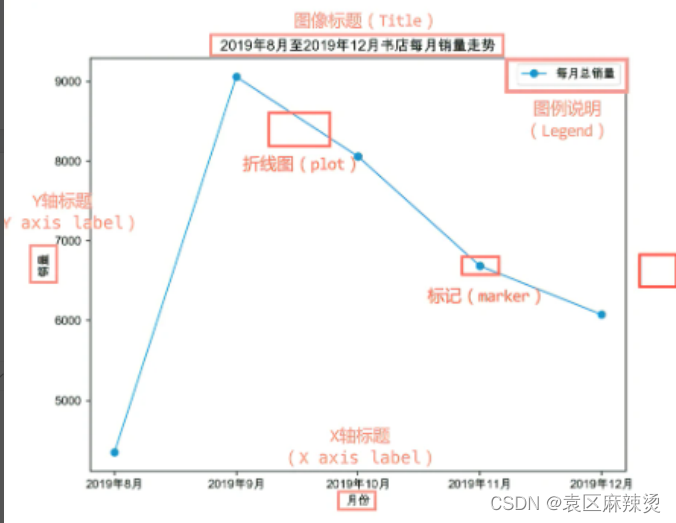
然后可以在图的周围加上标题,和说明,这样更容易被理解
常见的图像为:趋势图,分布图,构成图,比较图,联系图
趋势图描述则随着时间或某个值的变化情况
通常有 折线图,柱形图来展示
分布图 用来观测数据的分布规律分析两个数据之间是否存在某种关系
通常有 散点图来展现分布特征
构成图描述数据在总体的占比
一般用 饼图
如果描述不同时间的占比用 百分比堆积柱形图 理解各数据在不同时段的占比情况
比较图 用于数据在某个维度的比较 通常有族状图 并列子图 反映同一时间内不同数据的大小情况
联系 用于描述两种维度数据之间的关系,即一个数据大小是否随着另一个数据的大小变化而变化
通常使用 双y轴叠加图
绘图准备
导入 import matplotlib.pyplot as plt
Matplotlib是不支持中文的,设置标题的适合可能会出现乱码
Plt.rcParams[“font.sans-serif”]=”Arial Unicode MS”自定义字体
创建画布
Plt.figure(figsize=(4,3))
Figsize=()设置画布大小
Facecolor=’blue’ 设置颜色
Plt.show()显示画布
绘制折线图
折线图强调数据随时间的变化规律或者趋势,非常适用于展示在相等时间间隔下数据的趋势。
一般x轴为时间 y轴为数值
使用Plt.plot()绘制折线图
然后将x,y的数据传入即可,可添加以下参数
Color=””折线params设置颜色
Marker=”o” 圆点标记每个值
Label=params set图例
调用方法显示图例 Plt.legend()显示图例
plt.xlabel()设置x标题
Plt.ylabel()设置y标题
Plt.title()设置图标题
绘制柱状图函数 Plt.bar()
参数与折线图类似
散点图:通常用描述数据之间的关系
通过数据的分布情况可以得到以下信息
- 是否存在关联
- 如果存在关联,是线性相关还是非线性相关
- 是否存在离群, 离群:与其他数据相比差距较大
绘制函数 plt.scatter()
将x,y传入
常用的参数与其它图形类似
双y轴叠加图
相同的x值,两个y值
比较两种不同单位的数据,放在同一张图进行比较
比如在每个月的曝光率与转化率的变化趋势差异
绘图方式
先绘制bar
再添加y plt.twinx()
在绘制plot()
绘制的顺序影响两图的先后
两个图例会默认在右上
通过legend(loc=”upper left”) 调整位置
百分比堆积柱状图,族形柱状图
一般用于展示多个数据,
比如展现每层楼的销售量
pandas提供绘图功能,这是基于matplotlib下的
绘制族形柱状图
Data.plot.bar(x=“” ,y=[“”,””,””])
对于某一列的绘制柱状图
Data[“”].plot.bar() index为x轴 该列为y轴
百分比堆积柱状图 用来展现每个数据在整体占的百分比
如在每一个月,多种商品的销售量
绘制百分比堆积柱状图
Data.plot.bar(x=“” ,y=[“”,””,””] ,stacked=True)
并列图
在一张画布上包含多个坐标系,多个图
plt.subplot(2,2,1) 2x2的之图 序号为1
plt.subplot(2,2,2)
当运行结果出x现叠加是
Plt.xticks(rotation=90) x轴旋转90度
Plt.tight_layout() 调整布局
第十一章
描述性数据分析
从大量的数据归纳,从而发现数据内部的规律
平均数绑架 陷阱
大的数据和小的数据形成互补 如:【10,11,12,13,100,200,300,400】 就是平均数绑架
从而平均数与实际的有着巨大差异
为避免绑架
描述性分析的核心是 集中趋势 离散趋势
通过许多指标来描述这两种趋势
也可以通过图像来描述这两种趋势
集中趋势(数据中心的位置) 通常在平均数上下波动来反映
平均数是指:数值平均数 ,位置平均数
avg median
直方图:x轴只能是数值,y是一段区间的总和 直方图不需要传入y,hist()可以自行统计 bnis可以对直方图划分区间 bins=100 划分100个统计区间
柱状图:y轴可以是字符串,y对应着一个值 bar需要传入x,y
正态分布 数据分布相对均匀
直方图左右对称 均值和中位数相等
偏态 数据分布不完全对称 一些极端大,极端小的数据影响出现的左偏和右偏
右偏 中位数<均值
左偏 中位数>均值
两极分化:
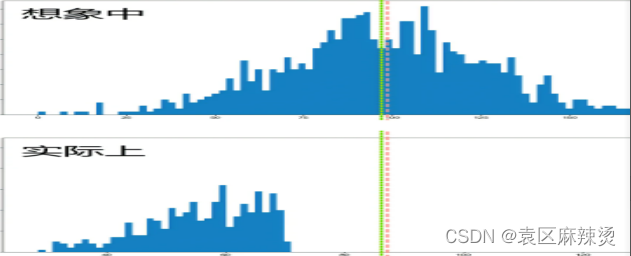
离散趋势 描述偏离中心值
通常通过方差和标准差来描述离散趋势
也可以通过四分位数
方差=E(真实值-均值)^2/n
标准差=方差开根号
方差越大越离散
方差 var ()标准差 std()
四分位数
将数组从小到大排序然后分为4个等份
此时会产生三个分割点就叫四分位数
第一个点25%的是下四分数
第二个点50%的是中四分位数
第三个个点75%的是上四分位数
获取四分位数的函数 quantile()
Describe()
四分位数的输出结果
Pandas的数据类型还包括分类数据
分类数据是一种取值有限的 如:性别,地区
Astype强制数据类型转换函数
Value_counts 统计频率,降序排序
第十二章
分组聚合
Groupby对数据按照一定的规则进行分组
聚合函数通常为 sum mean meidan count 等等
重采样resample
讲数据的中的时间点从一个频频转为另一个频率
简单来说计算基于时间的分组操作
向下采样 从高频率到低频率 从天到月
向上采样 从低频率到高频率 从月到天
同步频率 频率不变 每月的星期四改为每月的星期五
从采样需要时间格式下的行索引进行
将时间作为索引在进行从采样
Resample()函数完成重采样

重采样的过程
先对原数据进行分组
然后在对不同分组进行聚合















 8858
8858











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









