






目录
如何用scrapy_redis组建跟redis进行连接:setting设置
本学习 由笑笑老师指导, 回顾常规scrapy爬虫
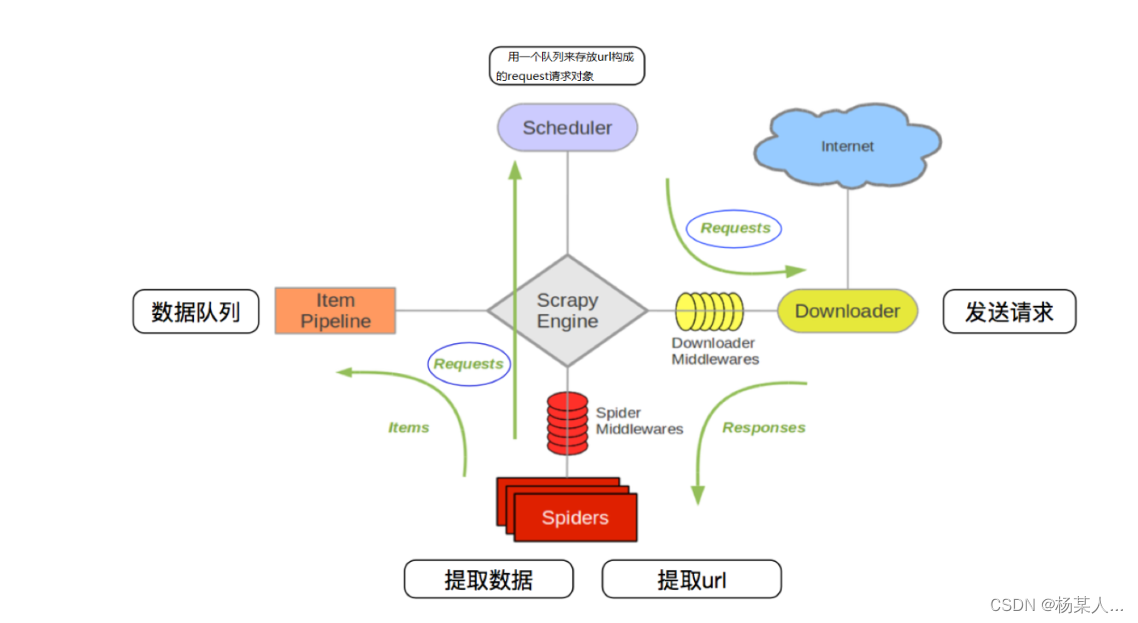
- 爬虫中起始的url构造成request对象-->爬虫中间件-->引擎-->调度器
- 调度器把request-->引擎-->下载中间件--->下载器
- 下载器发送请求,获取response响应---->下载中间件---->引擎--->爬虫中间件--->爬虫
- 爬虫提取url地址,组装成request对象---->爬虫中间件--->引擎--->调度器,重复步骤2
- 爬虫提取数据--->引擎--->管道处理和保存数据
从列表中 取出数据:
lrange key(demo3) 起始字符(0) 结束字符(1)
往一个目标里面添加数据
lpush demo3 aa
创建一个新列表
rpush dd 1
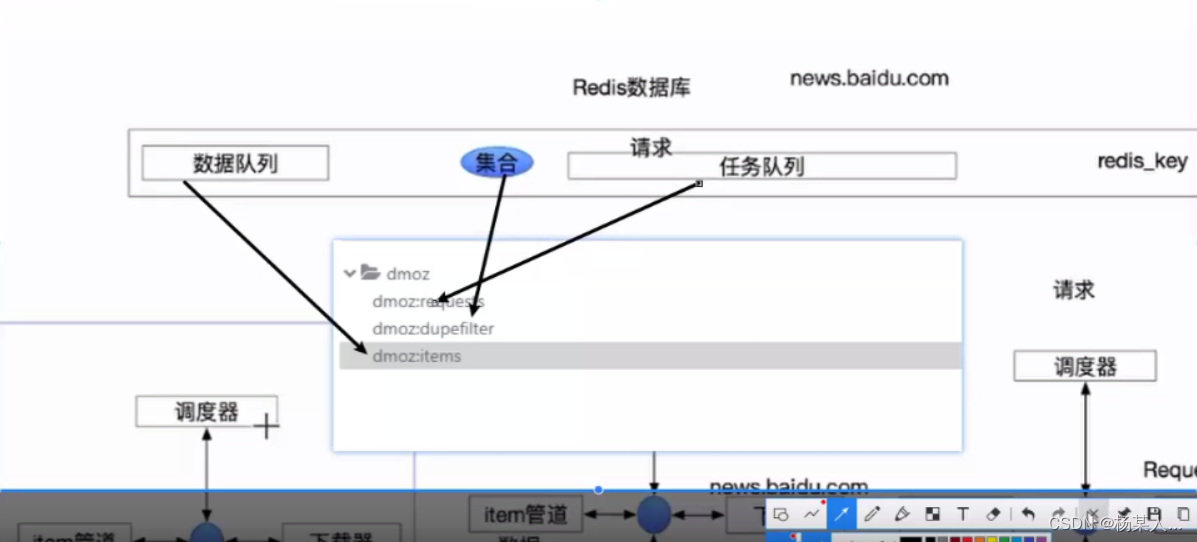
如下:存放的是请求对象相关信息。进行判断 有的话抛弃 没有就存储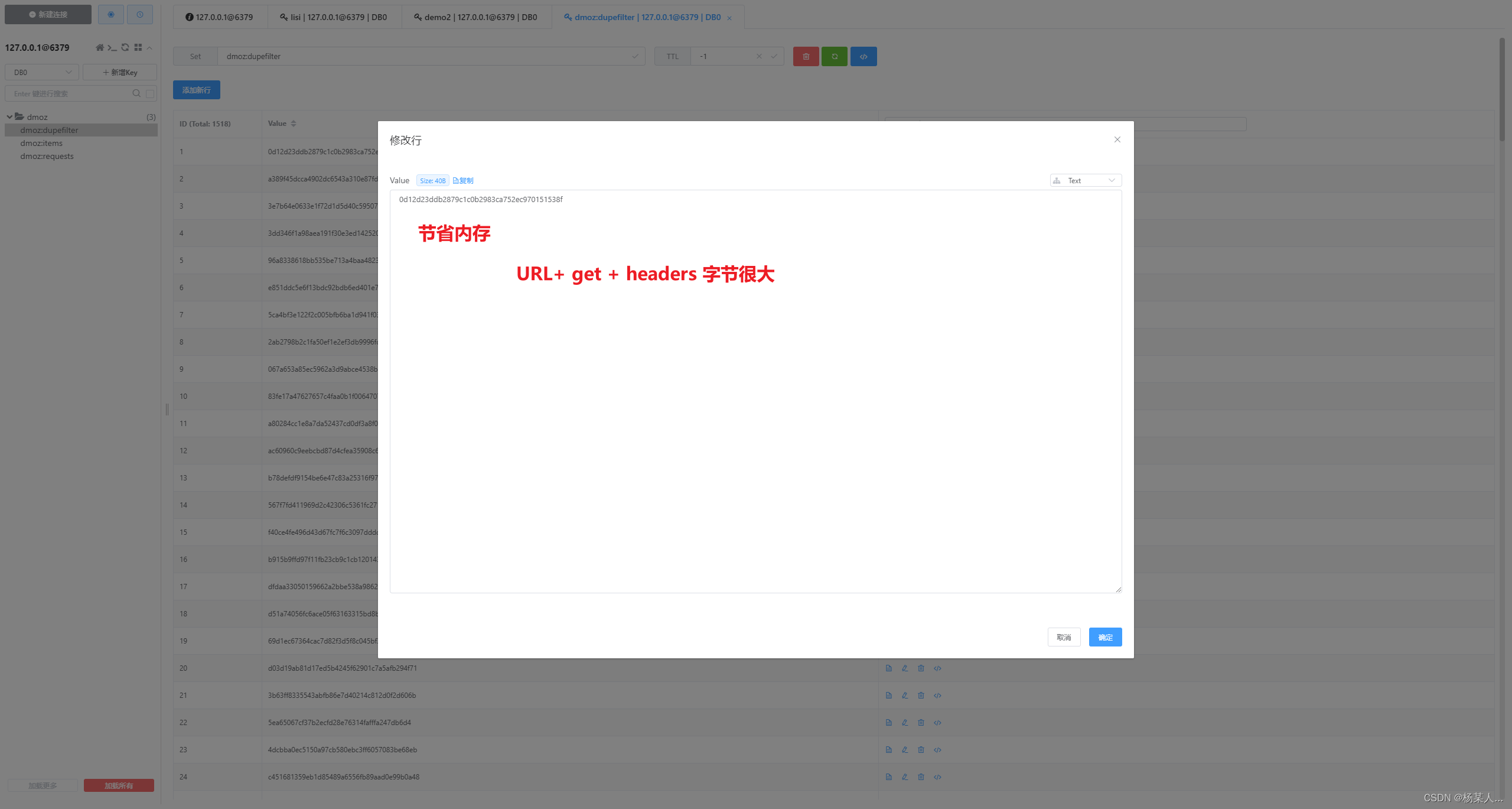

安装redis服务
redis服务的安装视频教程链接:百度网盘 请输入提取码
提取码:un7y
- 测试:
- 输入redis-cli连接到redis数据库
- 输入set mykey abc在数据库里添加键值对
- 输入get mykey表示通过键名获取出redis中的键值
- 结果:abc初识scrapy_redis源码
从GitHub上将scrapy-redis源码文件下载到本地:GitHub - rmax/scrapy-redis: Redis-based components for Scrapy.
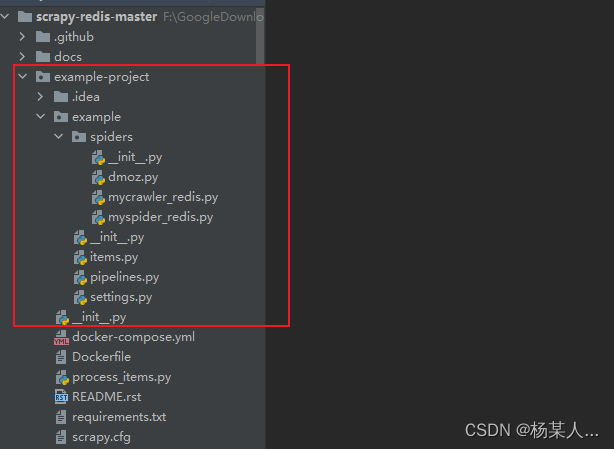
1.运行上图中的dmoz.py文件 借此来解释redis数据库中的结构

2.运行后,此时再打开Redis Desktop Manager的界面
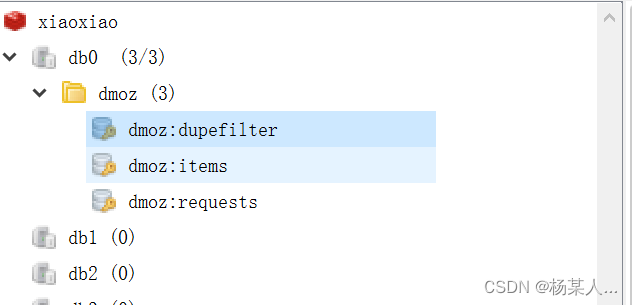
3.我们执行domz的爬虫,会发现redis中多了一下三个键:
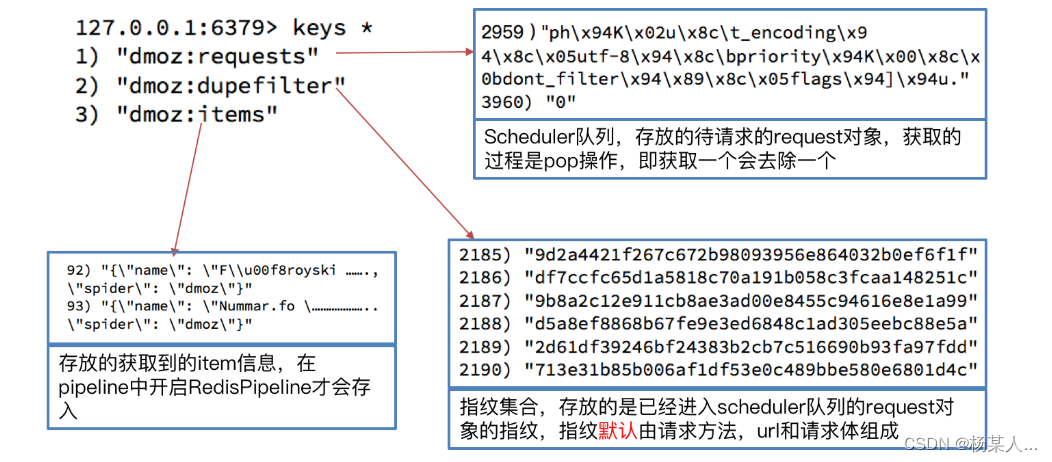
4.中止进程后再次运行dmoz爬虫
继续执行程序,会发现程序在前一次的基础之上继续往后执行
如何用scrapy_redis组建跟redis进行连接:setting设置
SPIDER_MODULES = ['example.spiders']
NEWSPIDER_MODULE = 'example.spiders'
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
# 设置重复过滤器的模块(0RFPDupeFilter),设置了就使用redis集合做去重,不设置的话使用是scrapy自己的去重方式
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
#设置调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
#****设置爬虫结束的时候 是否要保持redis服务的去重集合和任务队列,为Ture才表示持久化
SCHEDULER_PERSIST = True
#request请求的优先级,默认先进先出
# SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue"
# SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderQueue"
# SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderStack"
ITEM_PIPELINES = {
# 'example.pipelines.ExamplePipeline': 300,
#scrapy_redis的管道, 启动的haul表示吧数据存入redis服务中
'scrapy_redis.pipelines.RedisPipeline': 400,
}
#日志信息
LOG_LEVEL = 'DEBUG'
# Introduce an artifical delay to make use of parallelism. to speed up the
# crawl.
#速度的限制
DOWNLOAD_DELAY = 1分布式爬虫运行命令
- 运行 ,从机名字
- scrapy runspider myspider_redis.py
- 设置redis-key获取start_url
- 启动redis
- redis-cli
- 添加reids-key去发布爬虫任务
- lpush x1 http://www.baidu.com
- 启动redis
总结:
一,scrapy_redis组件的安装:
pip install scrapy-redis二,作用:
加快项目的运行速度,但是需要的资源还是原有的,单个节点的不稳定性不影响整个系统的稳定性三,scrapy_redis的流程:
1.在scrapy_redis中,所有的待抓取的请求对象和去重指纹都是存在一个公共的redis服务中 (主机)
2.所有的请求对象在正式存入redis的请求队列之前,都先会去redis中的dupefilter进行指纹集合的比对,来判断之前是否已经存入过
3.所有的scrapy进程共用redis中的请求队列,也就是都会去从redis的请求队列获取任务,每获取出一个队列中会少一个请求 (从机)
4.默认情况下所有的数据都会存入到redis中的item,也可以根据实际情况做调整四,分布式爬虫的运行命令:
1.运行:scrapy runspider 爬虫文件名.py
2.设置redis-key (目的是便于运行时获取起始url)
- 启动redis的命令:redis-cli
- 添加redis_key: lpish key_name start_url 例如:lpush x1 http://www.baidu.com















 2205
2205











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











