






VidBot项目介绍
VidBot,视学知识助手。它提供视频流量分析、视频转知识图谱、视频转思维导图、知识点联查、视频自动分段、智能助教和共享笔记等功能,旨在改善您的在线视频体验和学习过程,帮助视频上传者了解观众行为和优化内容。无论您是教育工作者、内容创作者,还是渴望更深入理解视频内容的学习者,VidBot都将成为您不可或缺的工具。
项目展示:
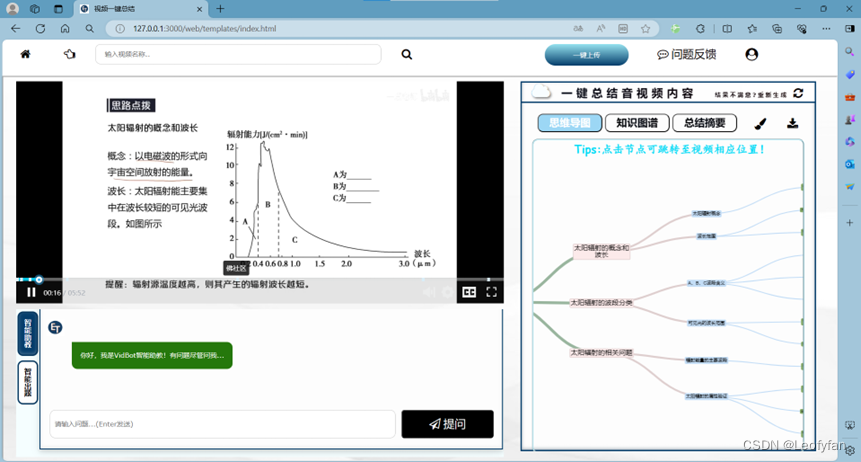
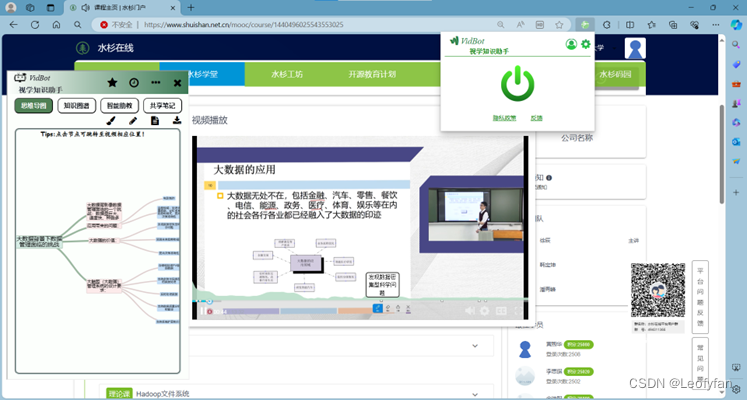
IPEX-LLM加速
(注:本项目示例运行在AIPC上,操作系统版本为Windows11。CPU型号:Intel(R) Core(TM) Ultra 5 125H 3.60 GHz)
1.IPEX-LLM简介
IPEX-LLM is a PyTorch library for running LLM on Intel CPU and GPU (e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max) with very low latency.【IPEX-LLM官方文档】
简单来说,IPEX-LLM提供了基于Intel的CPU与GPU来量化和加速模型的API。
若要利用IPEX-LLM中的 Intel GPU 加速,需要安装对应的英特尔GPU驱动。Intel GPU 配置环境官方文档
2. Whisper语音模型加速
Whisper是 OpenAI 2022年发布的一款语音预训练大模型,集成了多语种ASR、语音翻译、语种识别的功能。
可选择模型类型:

IPEX-LLM提供了Whisper的CPU与GPU(i-gpu)加速接口。
CPU加速示例(以openai-whisper模型接口为例):
import whisper
from ipex_llm import optimize_model
# Load whisper model under pytorch framework
model = whisper.load_model(model_name)
# With only one line to enable IPEX-LLM optimize on a pytorch model
model = optimize_model(model)GPU加速示例:
from ipex_llm.transformers import AutoModelForSpeechSeq2Seq
from transformers import WhisperProcessor
# Load model in 4 bit,
# which convert the relevant layers in the model into INT4 format
model = AutoModelForSpeechSeq2Seq.from_pretrained(model_path,
load_in_4bit=True,
optimize_model=False,
use_cache=True)
# 这一行代码将whipser模型放在i-gpu上进行推理
model.to('xpu')3.ChatGLM3-6B语言模型加速
ChatGLM3是智谱AI和清华大学 KEG 实验室联合发布的对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型。【ChatGLM3-6b官方文档】
模型任务:总结给定文本摘要示例
IPEX-LLM在i-gpu加速ChatGLM3-6b的推理示例:
from ipex_llm.transformers import AutoModel
from transformers import AutoTokenizer
import subprocess
import time
MODEL_PATH = os.environ.get('MODEL_PATH', model_path)
TOKENIZER_PATH = os.environ.get("TOKENIZER_PATH", model_path)
print('----------- ipex-gpu Warm-up... -----------')
model = AutoModel.load_low_bit(MODEL_PATH,trust_remote_code=True)
model = model.to('xpu')
tokenizer = AutoTokenizer.from_pretrained(TOKENIZER_PATH, trust_remote_code=True)
# 格式化提示
CHATGLM_V3_INIT_PROMPT_TEMPLATE = "这是Warm-up过程,无需做出回答\n"
prompt = CHATGLM_V3_INIT_PROMPT_TEMPLATE
# 编码提示
input_ids = tokenizer.encode(prompt, return_tensors="pt")
input_ids = input_ids.to('xpu')
output = model.generate(input_ids,
do_sample=False,
max_new_tokens=32) # warm-up
print('----------- ipex-gpu Warm-up finished -----------')
def GetExtract(
text_path,
time_path,
extract_path,
json_path,
video_name,
n_predict=5000):
CHATGLM_V3_PROMPT_TEMPLATE = "总结下面的文字的大纲。\n{prompt}\n答:"
# 打开要总结的文本文件
with open (text_path, "r", encoding="utf-8") as f:
prompt = f.read()
# 格式化提示
prompt = CHATGLM_V3_PROMPT_TEMPLATE.format(prompt=prompt)
# 编码提示
input_ids = tokenizer.encode(prompt, return_tensors="pt")
# 将输入送到GPU上(如果您的模型是在GPU上训练的)
input_ids = input_ids.to('xpu')
# 开始时间
st = time.time()
# 生成输出
output = model.generate(input_ids, max_new_tokens=n_predict)
# 结束时间
end = time.time()
# 解码输出
output_str = tokenizer.decode(output[0], skip_special_tokens=True)
# 处理输出,分离“答:”前的部分
parts = output_str.split("答:")
if len(parts) > 1:
output_str = parts[1]
# 打印时间消耗
print(f'----------- 模型生成摘要用时: {end-st} s -----------')
# 将生成的摘要保存到文件
with open(extract_path, "w", encoding="utf-8") as f:
f.write(output_str)
总结
IPEX-LLM 是一个针对大语言模型的优化加速库,它提供了各种低精度优化(例如 INT4 / INT5 / INT8),并可利用多种英特尔® CPU集成的硬件加速技术(AVX/VNNI/AMX 等)和最新的软件优化,来赋能大语言模型在英特尔® 平台上实现更高效的优化和更为快速的运行。
IPEX-LLM 的一大重要特性是:对基于 Hugging Face Transformers API 的模型,只需改动一行代码即可对模型进行加速,理论上可以支持运行任何 Transformers 模型,这对熟悉 Transformers API 的开发者非常友好。
参考连接
https://github.com/intel-analytics/ipex-llm
https://github.com/openai/whisper
THUDM/ChatGLM3: ChatGLM3 series: Open Bilingual Chat LLMs | 开源双语对话语言模型 (github.com)https://zhuanlan.zhihu.com/p/653723972

















 1595
1595

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









