






Python 中常用的序列类型有字符串、列表、元组、集合、字典,以及 range、map、zip等对象也支持很多类似序列的操作。
-其它数据结构栈、队列、堆、链表、二叉树、图等
| 有序 | 可变 | 双向索引 | |
| 列表 | √ | √ | √ |
| 元组 | √ | × | √ |
| 字符串 | √ | × | √ |
| 字典 | × | √ | × |
| 集合 | × | √ | × |
双向索引:-1,-2 ... -n
/* 基础:print(f'{list1=}') 打印结果为 list1 = [];
3**n //3的n次方
- 列表(list)
一个列表中的数据类型可以各不相同
创建:list1 = [1,2,3]; list2 = list("Python");
list()函数将参数转换为列表。list2结果是 ‘p’、'y'、‘t’ ...
删除:del lst1 // 删除整个列表
del lst1[0] //删除位置为0的数据
增:
lst.append(x) //将元素x添加至列表lst尾部 **元素可以是串'you'
lst.extend(L) //将列表L中所有元素添加至列表lst尾部 **元素是'y’ ‘o’ ‘u'
lst.insert(index, x) //将元素x,插入索引index处的字符之前
//添加还可以用 + 运算符
删:
lst.remove(x) //在列表lst中删除首次出现的指定元素
lst.pop([index]) //删除并返回列表lst中下标为index的元素,默认最后一个元素
lst.clear() //删除列表lst中所有元素,但保留列表对象
**尽量删尾部,效率问题
改:利用索引进行赋值
查:
lst.index(x) //返回列表lst中第一个值为x的元素的下标lst.reverse() //对列表lst所有元素进行逆序, 没有排序
lst.sort(key=None, reverse=False) //对元素进行排序,key用来指定排序依据,reverse决定升序 (False)还是降序(True)
常见用法:
print(f"{3 in list1 =}") // in 判断3是否列表的成员,返回值为True or False
内置函数
“sorted() 作为Python内置函数之一,其功能是对序列(列表、元组、字典、集合、还包括字符串)进行排序。 //sorted(aList,reverse=True) 降序
len() //获取列表长度
max() min()
sum() #同样用于元组、range
sum(range(1, 11), 5) #指定start参数为5,等价于5+sum(range(1,11))
count(x) //返回指定元素x在(?)中的出现次数
copy() //用于复制列表,字典或集合等可变容器
index() //返回下标,用于有序数列
zip()函数返回可迭代的zip对象,将元素打包为元组。
>>> aList = [1, 2, 3]
>>> bList = [4, 5, 6]
>>> cList = zip(a, b) #返回zip对象
>>> cList
>>> list(cList) #把zip对象转换成列表
[(1, 4), (2, 5), (3, 6)]
enumerate(列表):枚举列表元素,返回枚举对象,其中每个元素为包 含下标和值的元组。该函数对元组、字符串同样有效。
>>> for item in enumerate('abcdef'): print(item)
(0, 'a')
(1, 'b')
(2, 'c')
(3, 'd')
(4, 'e')
(5, 'f')
导包
import numpy as np
np.mean()
切片操作
适用于列表、元组、字符串、range对象(列表功能最强) //有序的
空格也切
语法格式:[start,stop,step] //不包含stop
List[100:] //下标100之后的元素,自动截断
List[100:] //发生越界
可配合del进行删除
del List[:3] //删除前三个元素
切片操作不会因为下标越界而抛出异常,而是在列表尾部截断或者返回一个空列表
列表推导式
1)定义:列表推导式基于现有可迭代对象创建新列表的简洁方法。
2)语法:[expression for item in iterable [if condition]]
其中 expression 是要对 item 进行操作的表达式, iterable 是要进行迭代的对象,condition 是可选的条件表达式, 只有满足条件的元素才会包含在结果列表中。
例子:
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
even_numbers = [num for num in numbers if num % 2 == 0]
print(even_numbers)
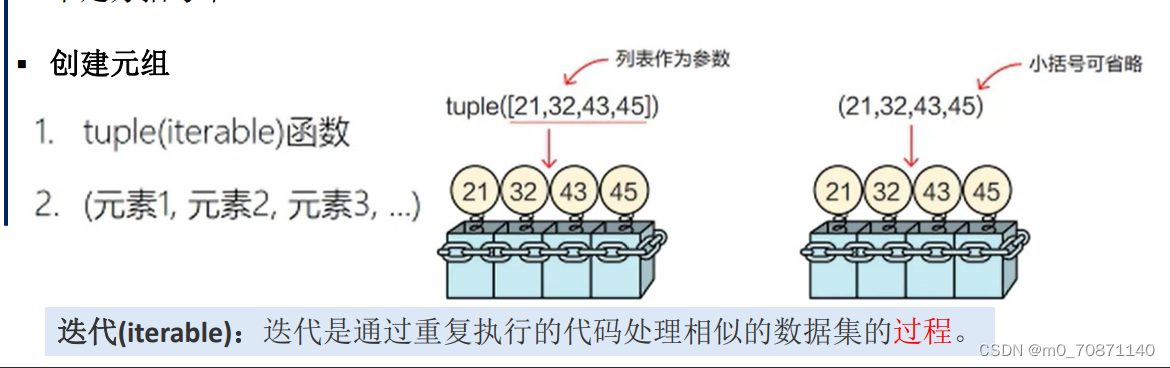
- 元组(tuple)
元组的定义方式和列表相同,但定义时所有元素是放在一对圆括号“()”中。
元组一旦创建,用任何方法都不可以修改其元素。
元组中包含的可变对象仍然可变,但元组元素 的引用仍是不可变的。
tup1([1,2,3],55)
tup1[0][0] = 5; //修改了列表
打包与拆包
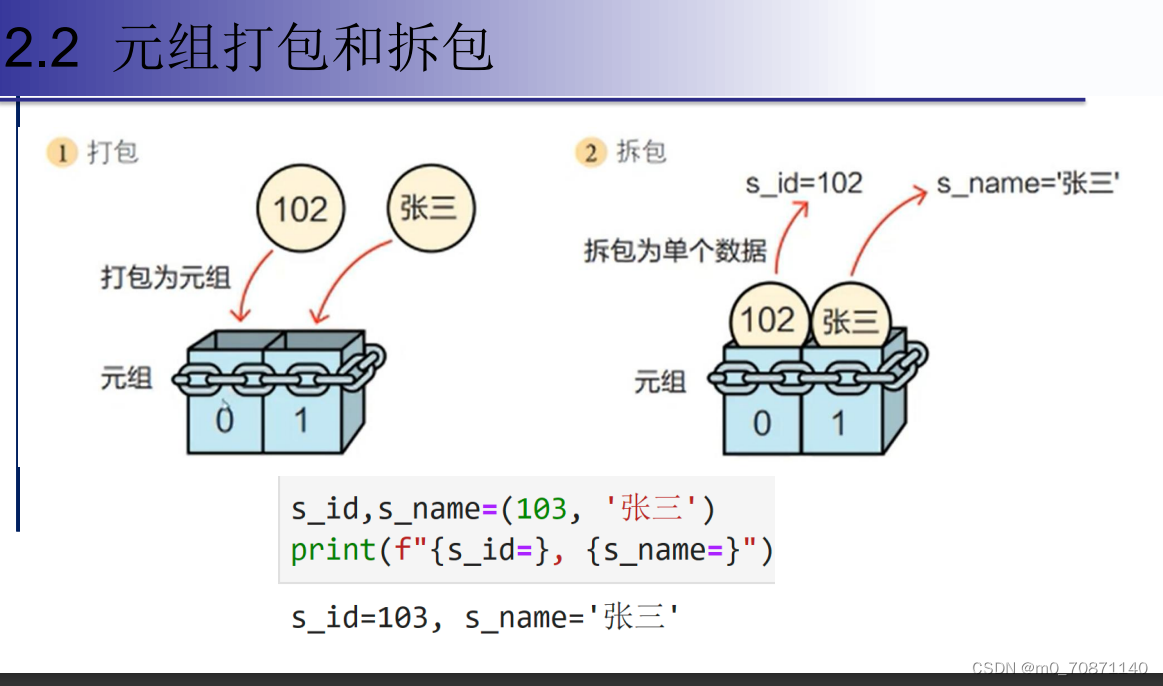
例子:
tup1,tup2 = tuple(1,),(2) //为3个元组赋值
tup = tup1 + tup2 ; //用 “+”连接符 结果是(1,2)
tup[0] //用下标查询元素
元组的速度比列表更快,得代码更加安全
元组可用作字典的“键”,也可以作为集合的元素。列表不能作为字典的“键”, 包含列表、字典、集合或其他类型可变对象的元组也不能做字典的“键”
- 字典(dict)
字典dict是无序、可变序列。
dict = {value:key}
◆ 字典的每个元素是用冒号分隔的键值对,即:key : value,元素 之间用逗号分隔,所有的元素放在一对大括号“{}”中。
◆ 字典中的键可以为任意不可变数据,比如数字、字符串、元组等。
◆ 键 视图不能包含重复的元素,值 视图能。
方法:
▪以键作为下标可以读取字典元素,若键不存在则抛出异常。 //fruit['apple']
▪使用get()方法获取指定键对应的值,get('键',返回值(默认为None))
◆ items()方法可以返回字典所有的元素。
◆ keys()方法可以返回字典所有的“键”。
◆ values()方法可以返回字典所有的“值”
◆
fromkeys()是 Python 字典对象的方法,可以用于创建一个新字典,其所有键都来自于可迭代对象(例如,列表、元组或字符串),并且每个键都具有相同的值(即输入的第二个参数)。 # dict.fromkeys(['x', 'y', 'z'], 0) //x,y,z都为0


增改:
◆当用指定键为字典赋值时,执行结果分两种情况:
1)若键存在,则可以修改该键的值; //改
2)若键不存在,则添加该键:值对。
用update()方法,添加
a1.update(a2) //将a2的元素加到a1后面
删:
▪del删除字典中指定键的元素,或整个字典。
▪clear()方法来删除字典中所有元素
▪pop(key)方法删除并返回指定键的值
▪popitem()方法删除并返回字典中的一个元素 //字典是无序的,所以删除是随机的。
字典推导式
字典推导式(Dictionary comprehensions)是一种快速创建字典的方法,它类似于列表推导式,但是可以返回一个字典对象。
语法形式为:{key_expression: value_expression for expression in iterable}


- 集合(set)
▪ 集合是无序、可变序列,使用一对大括号{ }界定,元素不可重复,同一个集合中 每个元素都是唯一的。
▪ 集合中只能包含数字、字符串、元组等不可变类型(或者说可哈希)的数据,而不能包含列表、字典、集合等可变类型的数据。
创建集合:
set(iterable)函数 //set('abc')
set(字典) //会将字典里面的键,作为元素
{1,2,3,4}
添加:
add(elem) //添加元素,存在也不会报错
删除:
remove(elem) //删除指定元素,没有就报错
discard(elem)
clear() //清除所有元素
frozenset() //变成不可变集合
set1.issubset(set2) //set1是否是set2的子集
set2.issuperset(set1) //set2是否是set1的父集





在 Python 中,变量赋值时会将变量名和对象之间建立引用关系,即把变量名和对象地址相关联。对于可变类型的对象(如列表),当多个变量名引用同一个对象时,修改该对象会影响所有引用该对象的变量名。
在上面的代码中,lst2 = lst1 相当于将 lst2 的引用指向了 lst1 所引用的对象。也就是说,lst1 和 lst2 引用的是同一个列表对象。因此,对 lst2 进行修改会影响到 lst1。
假设我们运行以下代码:
lst1 = [1, 2, 3]
lst2 = [4, 5, 6]
lst2 = lst1
lst2[0] = 10
print(lst1) # 输出 [10, 2, 3]
print(lst2) # 输出 [10, 2, 3]















 4279
4279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









