






在信息理论中,离散无记忆信源是指生成的每个符号都是独立且具有相同概率的信源。这样的信源模型具有一些特殊的属性和应用,对于理解和优化信息传输和存储过程非常重要。
离散无记忆信源是信息论中最简单的一类信源。它的特点是生成的每个符号都是相互独立的,并且每个符号出现的概率都是相等的。换句话说,每个符号都是独立地从一个固定的集合中选择的,选择每个符号的概率是相等的。
这样的信源模型可以用于描述一些简单的信息产生过程,比如硬币的正反面结果、骰子的点数或是数字0和1的序列。当然,离散无记忆信源还可以用来描述更复杂的情况,比如一些随机游戏的结果或是一些随机事件的发生概率。
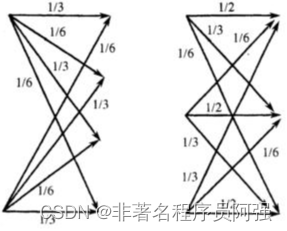
离散无记忆信源的独立性和等概率分布给了我们一些有用的性质和工具,用来理解和优化信息传输和存储过程。其中一个重要的概念是熵,它可以用来度量离散无记忆信源产生的信息的平均量。
熵是用来描述一个信源的不确定性或信息量的度量。对于离散无记忆信源,熵的计算很简单,只需要使用符号的概率来计算每个符号的信息量,然后将它们加起来。如果一个符号的概率是p,那么它的信息量可以被定义为-log(p)。离散无记忆信源产生的信息的熵就是所有符号信息量的平均值。
在信息论中,我们通常使用一个底为2的对数来定义熵,单位是比特(bit)。熵越大,表示信源产生的信息越不确定,每个符号携带的信息量也就越大。而当熵为0时,表示信源的输出是确定的,没有任何不确定性和信息量。

使用熵的概念,我们可以对离散无记忆信源的压缩和编码进行优化。通过使用更短的编码来表示出现概率较高的符号,我们可以减少整体的信息传输量。而通过使用更长的编码来表示出现概率较低的符号,我们可以保持编码的唯一性,减少解码的错误率。
除了优化编码之外,离散无记忆信源还可以应用于其他领域。例如,它可以用来建模和分析密码学中的随机性和安全性。在通信系统中,离散无记忆信源也被用来描述和分析信道的噪声和失真特性。
总而言之,离散无记忆信源是信息论中最简单的一类信源模型,它描述了生成独立且具有相同概率的符号的过程。通过使用熵的概念和优化编码,我们可以理解和优化信息传输和存储过程。离散无记忆信源的应用范围广泛,对于信息论和通信领域的发展有着重要的意义。
【学习交流群】不知道怎么学?遇到问题没人问?到处找资料?邀请你加入我的人工智能学习交流群,群内气氛活跃,大咖小白、在职、学生都有,还有群友整理收集的100G教程资料,点击下方进群占位。(点击跳转到群二维码,请放心点击!)扫码进群领资料


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









