






报错:
spark任务在Insert时出错
User class threw exception:org.apache.spark.sql.AnalysisException:`ods_binlog`.`ods_binlog_doctorrecipe_avatar_recipedetails_di` requires thatthe data to be inserted have the same number of columns as the target table:target table has 3 column(s) but the inserted data has 2 column(s), including 0partition column(s) having constant value(s).
翻译:
用户类引发异常:org.apache.spark.sql。AnalysisException:`ods_binlog``ods_binlog_doctorrecipe_avatar_recipedetails_di`要求要插入的数据具有与目标表相同的列数:目标表有3列,但插入的数据有2列,包括0个具有常量值的分区列。
查文件:
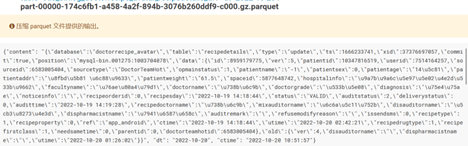

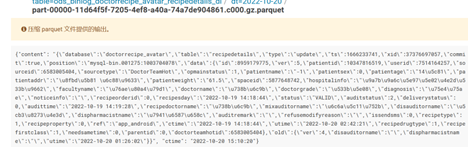
发现暂停消费改代码后重新消费时,数据中没有dt列
查sql:
select * fromods_binlog.ods_binlog_doctorrecipe_avatar_recipedetails_di where ctime > '2022-10-2015';

发现这些数据在sql查询结果中是有dt列的
查出该数据所在文件:
select *, INPUT__FILE__NAME fromods_binlog.ods_binlog_doctorrecipe_avatar_recipedetails_di where dt ='2022-10-20'
andget_json_object(get_json_object(content,'$.data'),'$.id') = '8959181639' andget_json_object(get_json_object(content,'$.data'),'$.ver') = '5';
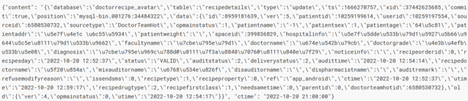
发现dt去过滤的时候也是生效的,但是文件里却一直没有dt字段,那是如何生效的就很奇怪,外表依赖映射文件,文件里没有的列外表为什么有,而且还是一个正常的值
尝试直接查询并插入hive表:
CREATE TABLE tmp.zy_binlogtest ( content STRING, ctime STRING ) PARTITIONED BY ( dt STRING ) STORED AS PARQUET;
insert OVERWRITE table tmp.zy_binlogtest partition (dt)
select * from ods_binlog.ods_binlog_doctorrecipe_avatar_recipedetails_di where dt = '2022-10-20'
and get_json_object(get_json_object(content,'$.data'),'$.id') = '8959181639' and get_json_object(get_json_object(content,'$.data'),'$.ver') = '5';发现直接插入这条记录时并没有什么问题,hive插入读的是下面的sql语句,而hive的文件只要在当前分区目录内,尽管文件里没有该字段,但他查询时可以自己加上分区字段,
那为什么3点以前的文件明明有三列,再加上分区字段列,也就是四列,但是插入时也没问题呢?4列是如何插入3列里呢?
创建临时表模拟情景:
CREATE TABLE tmp.zhangyang ( name STRING , age INT) PARTITIONED BY ( dt STRING )
row format delimited fields terminated by '\t';
msck repair table tmp.zhangyang;
select * from tmp.zhangyang;

表中数据有两列另外有一个dt字段,映射的txt文件却直接有三列,且在dt=2022-10-21分区目录下,但查询结果却为三列,直接忽略了文件中为性别的列
所以说,hive和文件之间的映射,并不简单的只是映射文件,而是映射相应的列,和相应的分区目录,就算文件内有其他多个不相干的列,只要有表所需要的列,也不会出问题,也可以完成映射关系
扩展思考:
如果我们吧性别和年龄反过来了会怎样?会把性别读成年龄吗?还是会直接隔过去性别直接读后面的年龄?


答案是都不是,会按顺序读,如果类型不匹配直接补NULL,那如果后面还有性别列呢?会继续读到吗?
CREATE external TABLE tmp.zhangyang1 ( name STRING , age INT, sex STRING) PARTITIONED BY ( dt STRING )
row format delimited fields terminated by '\t' location 'hdfs://HDFSNS/Data/d1/hive/warehouse/tmp.db/zhangyang';
msck repair table tmp.zhangyang1;
答案是,他并不会吧第二列性别当性别,他是按照下标取,直接取第三列年龄作为性别,原来宁可将就也不回头找前任啊
查看报错对应的代码:
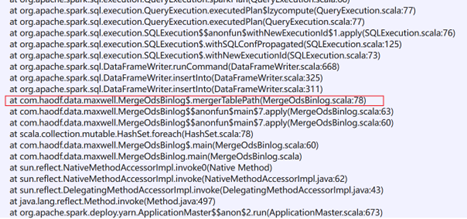
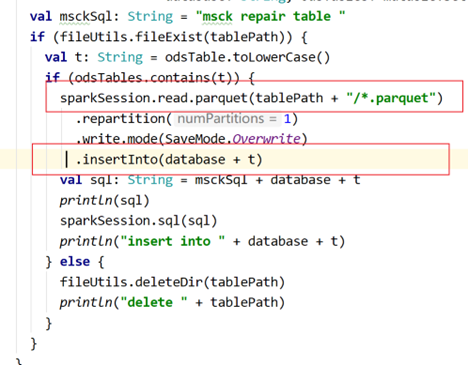
由此可知,spark任务在这里读的只是文件本身,他不关心你是在哪个分区目录下的,他也不会给你自动加上去,而目标表需要分区字段,无法拿到dt字段自然就给不了所以报错
所以说spark和Hive不一样,spark这里读文件,有几列我就挨着顺序读几列,分区也得给而且只能给到最后一列,不会读分区目录,也不会根据类型判断取谁不取谁和补NULL等操作















 1476
1476











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









