







一、背景说明
以下xx代表你猜中的内容。
1.1 效果演示
用python开发了一个爬虫采集软件,可自动抓取xx评论数据,并且含二级评论!
软件默认采集全部评论,含一级评论和二级评论。
为什么有了源码还开发界面软件呢?方便不懂编程代码的小白用户使用,无需安装python、无需懂代码,双击打开即用!
软件界面截图: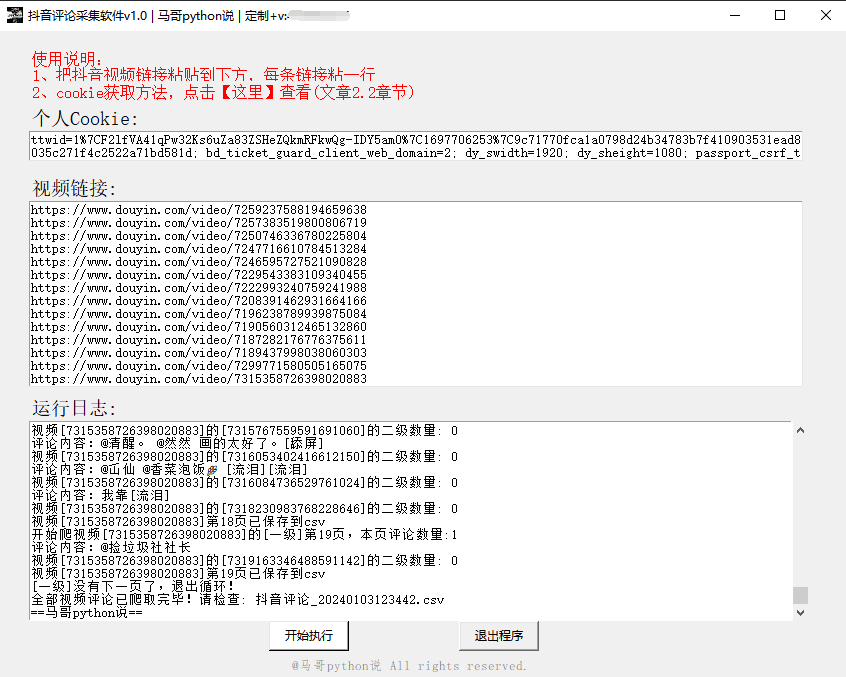
爬取结果截图: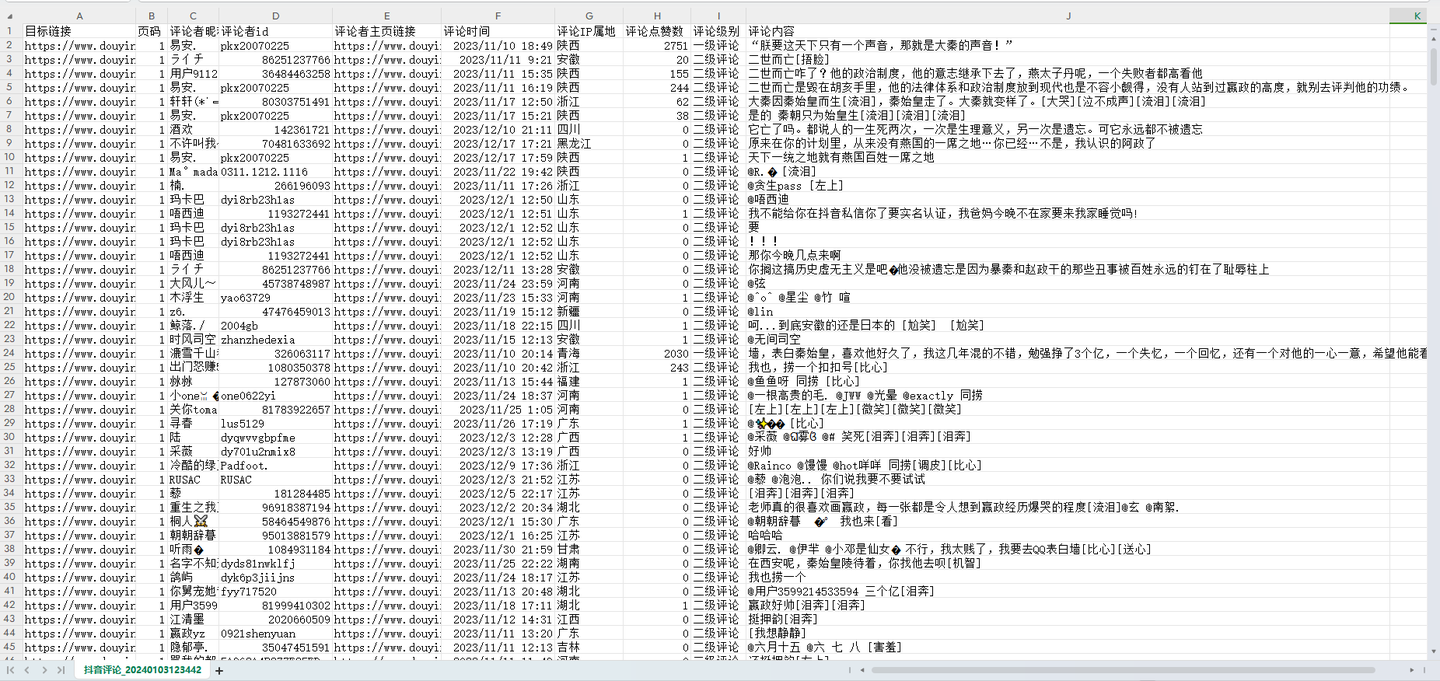
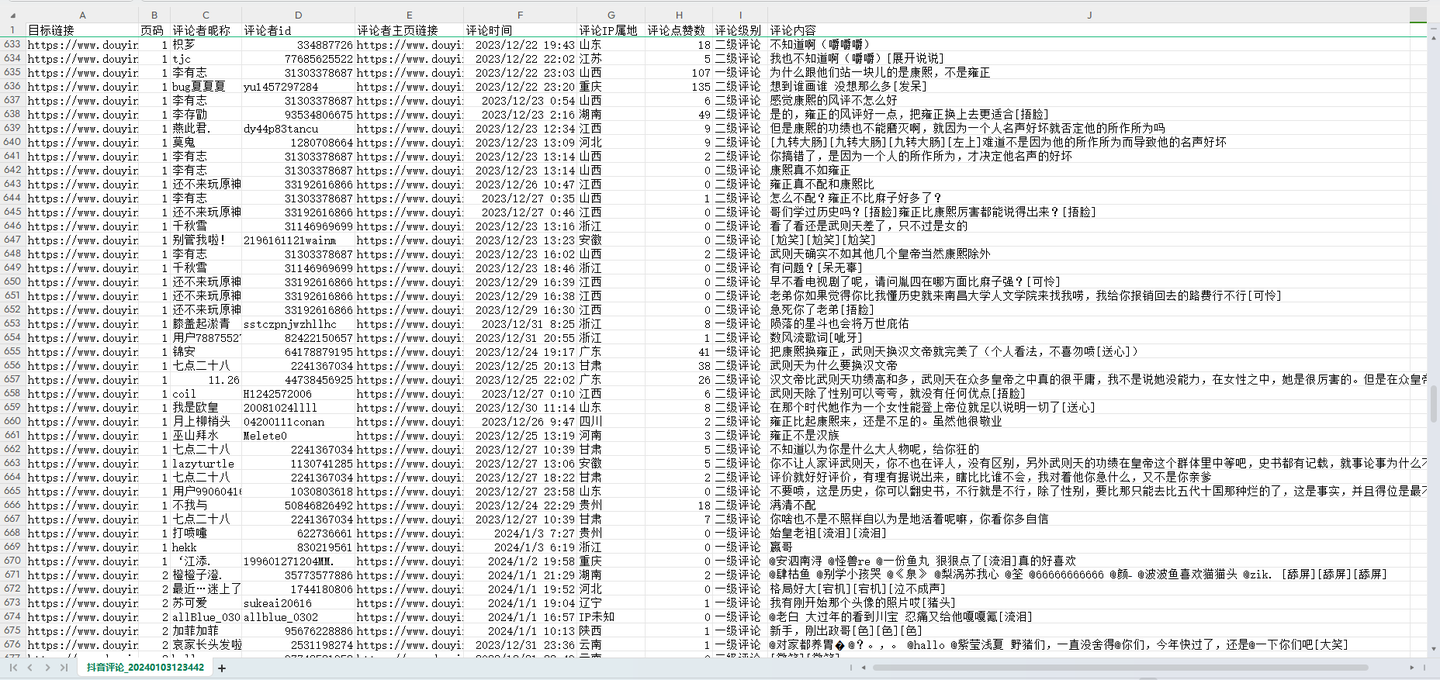
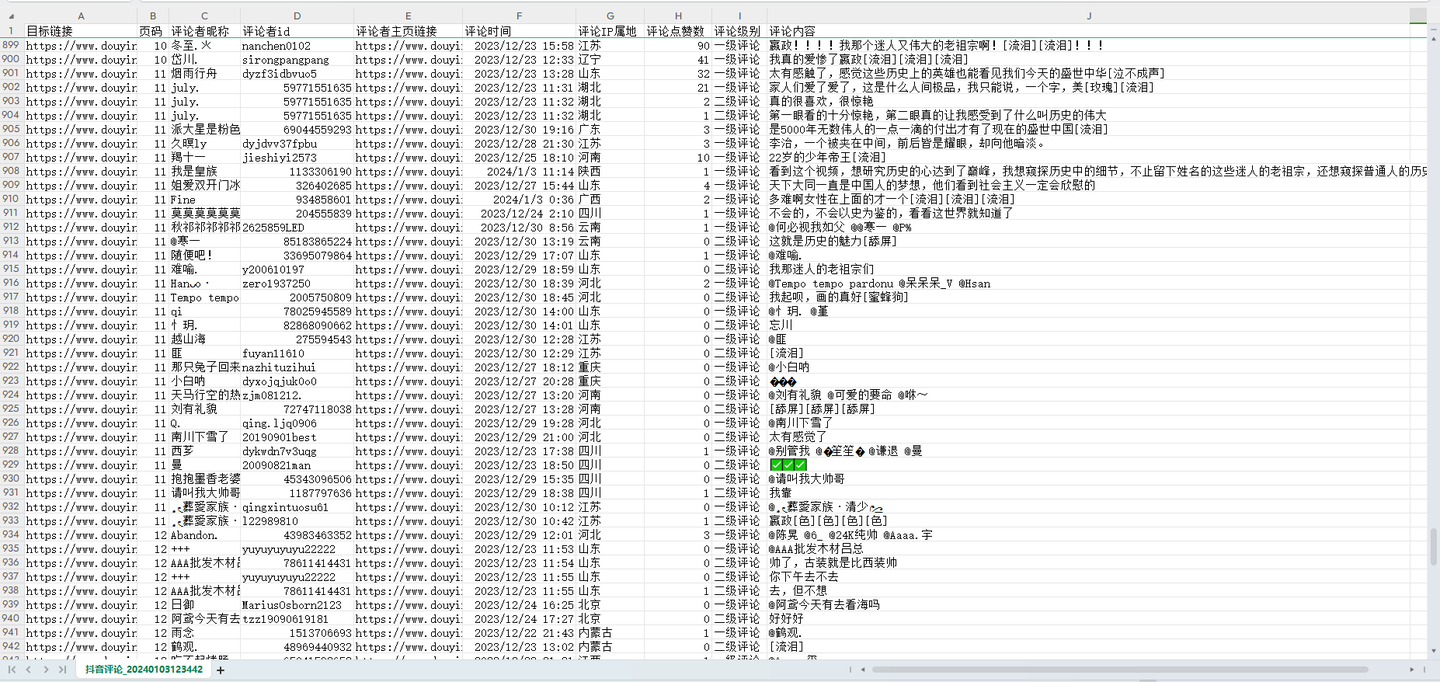
以上。
1.2 演示视频
软件运行演示:【软件演示】xx评论采集工具,可爬取上万条,含二级评论!
1.3 软件说明
几点重要说明:
1. Windows用户可直接双击打开使用,无需Python运行环境,非常方便
2. 需要填入cookie和爬取目标视频链接
3. 支持同时爬多个视频的评论
4. 可爬取10个关键字段,含:视频链接,页码,评论者昵称,评论者id(个人xx号),评论者主页链接,评论时间,评论IP属地,评论点赞数,评论级别,评论内容。
5. 评论中包含二级评论及二级展开评论。
二、代码讲解
2.1 爬虫采集模块
首先,定义接口地址作为请求地址:
# 请求地址
url = 'https://www.douyin.com/aweme/v1/web/comment/list/'
定义一个请求头,用于伪造浏览器:
# 请求头
h1 = {
'accept': 'application/json, text/plain, */*',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'cookie': '换成自己的cookie值',
'referer': 'https://www.douyin.com/',
'sec-ch-ua': '"Not_A Brand";v="99", "Google Chrome";v="109", "Chromium";v="109"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"macOS"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': ua,
}
其中,cookie是个关键参数,需要填写到软件界面里。cookie获取方法如下: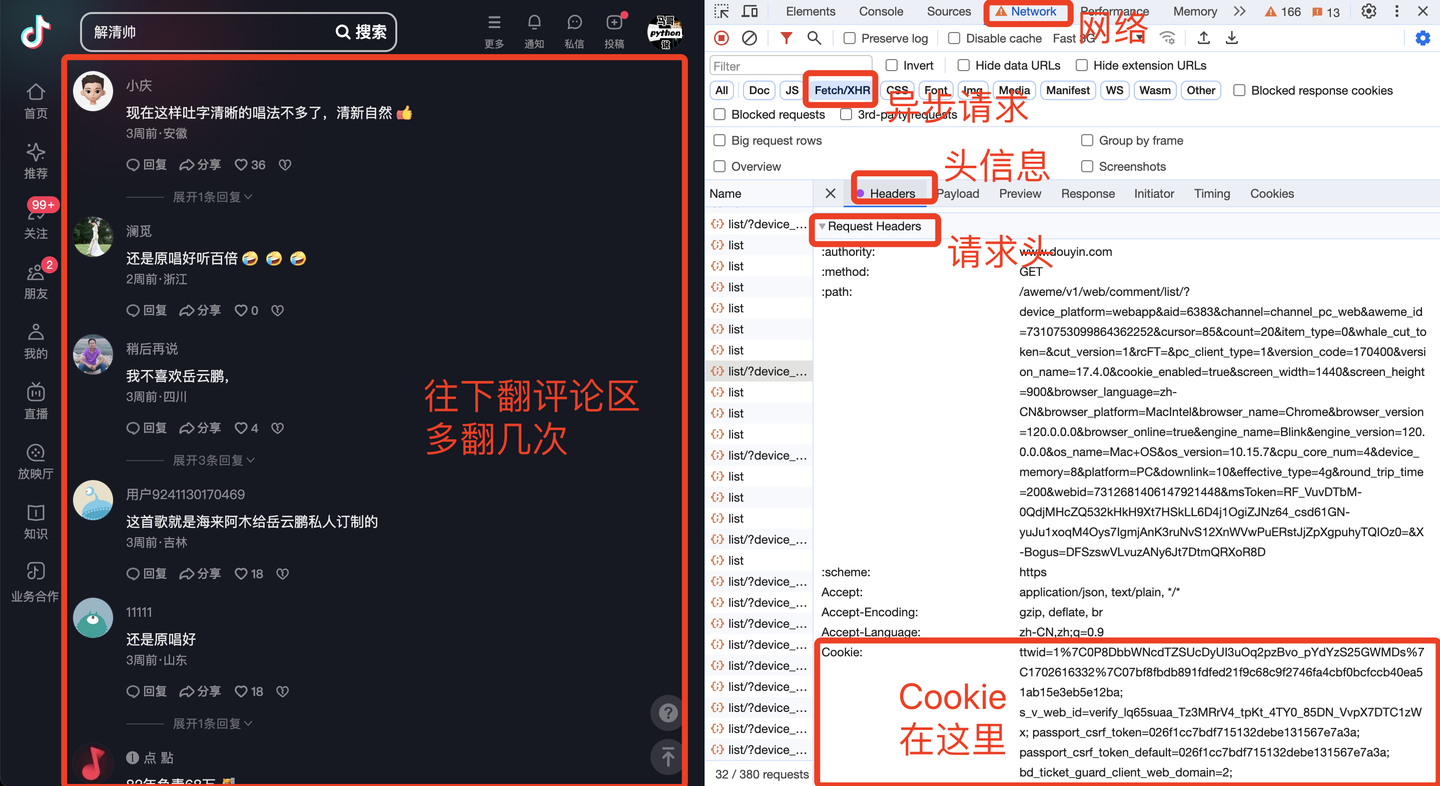
加上请求参数,告诉程序你的爬取条件是什么:
# 请求参数
params = {
'device_platform': 'webapp',
'aid': 6383,
'channel': 'channel_pc_web',
'aweme_id': video_id, # 视频id
'cursor': page  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 548
548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









