







项目中进行接口压测,发现批量插入的速度有点超出预期,感觉很奇怪,经过定位后发现mybatise-plus批量保存的处理十分缓慢,使用的是saveBatch方法,这点有点想不通。于是就进行了相关内容分析。
根据mybatise-plus中saveBatch的方法进行源码查看:

继续跟踪逻辑,从代码上看,确实是一条条执行了sqlSession.insert(sqlStatement, entity) 方法。

继续跟踪,下面的consumer执行的就是上面的sqlSession.insert方法:
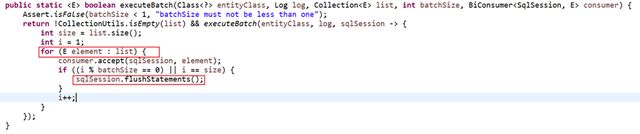
具体执行逻辑中是累计到 一定数量后,一批数据进行flush。
其实,从上述的代码实现上看,整个实现机制跟我们预想的差不多,基本上是批量的实现思路。这种批量的处理肯定比一条条的insert要快。
但是,为什么还是如此的缓慢。
下面我们就进行一个粗略的实验,来对比一波。现在使用4种方式进行比较:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









