






1: jdk8中新增的方法
在jdk8中对接口进行了增强,在jdk8之前
interface 接口名{
静态常量:
抽象方法:
}
在jdk8之后
interface 接口名{
静态常量:
抽象方法:
默认方法:
静态方法:
}
2:默认方法
在jdk8以前只能有抽象方法和静态常量,会存在一下问题
如果有接口进行扩展,这个接口的对应的实现类都需要重写,不利于扩展
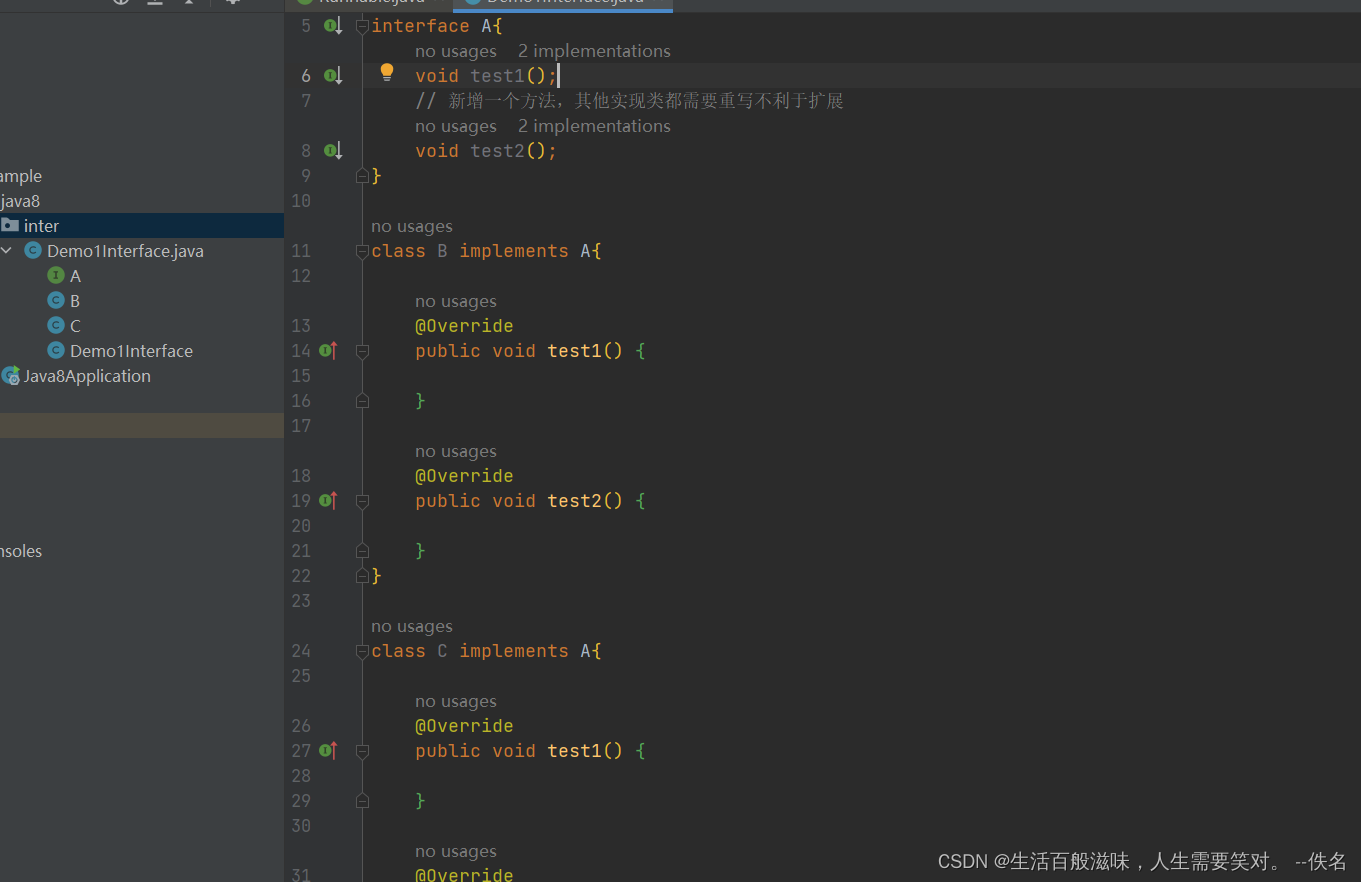
2.1:默认方法格式
interface 接口名:{
修饰符 default 返回值类型 方法名:{
方法体:
}
}
package com.example.java8.inter;
public class Demo1Interface {
public static void main(String[] args) {
A b = new B();
System.out.println(b.test3());
A c = new C();
System.out.println(c.test3());
}
}
interface A {
void test1();
// 新增一个方法,其他实现类都需要重写不利于扩展
void test2();
// 默认方法
default String test3() {
System.out.println("接口中默认方法");
return "你好";
}
}
class B implements A {
@Override
public void test1() {
}
@Override
public void test2() {
}
@Override
public String test3() {
return "接口B重写了方法";
}
}
class C implements A {
@Override
public void test1() {
}
@Override
public void test2() {
}
}
2.2:默认方法的使用
1:实现类调用接口的默认方法
2:实现类重写接口的默认方法
3:静态方法
3.1:静态方法格式:
interface 方法名:{
修饰符 static 返回值类型 方法名:{
方法体:
}
}
package com.example.java8.inter;
public class Demo1Interface {
public static void main(String[] args) {
A b = new B();
System.out.println(b.test3());
A c = new C();
System.out.println(c.test3());
System.out.println(A.test4());
}
}
interface A {
void test1();
// 新增一个方法,其他实现类都需要重写不利于扩展
void test2();
// 默认方法
default String test3() {
System.out.println("接口中默认方法");
return "你好";
}
/**
* 静态方法
* @return
*/
static String test4(){
return "静态方法";
}
}
class B implements A {
@Override
public void test1() {
}
@Override
public void test2() {
}
@Override
public String test3() {
return "接口B重写了方法";
}
}
class C implements A {
@Override
public void test1() {
}
@Override
public void test2() {
}
}
3.2 静态方法的使用:
静态方法不能被重写,只能通过接口类型调用:接口名.方法名

4 二者之间的区别:
1:默认方法只能通过实现了调用,静态方法只能通过接口名调用
2:默认方法可以被继承,实现类可以直接调用默认方法,也可以进行重写
3:静态方法不可以被继承,实现类不可以直接调用默认方法,不可以进行重写
2: Steam Api
2.1 集合处理数据的弊端:
当我们对集合进行操作时,除了最基本的新增,删除操作,最典型的就是遍历
package com.example.java8.stream;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
public class SteamTest01 {
public static void main(String[] args) {
// 创建一个集合
List<String> list = new ArrayList<>();
list.add("张三丰");
list.add("张无");
list.add("杨幂");
list.add("你好");
System.out.println(list);
// 获取所有姓张的数据
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()){
String next = iterator.next();
if (!next.startsWith("张")){
iterator.remove();
}
}
System.out.println(list);
List<String> listSize = new ArrayList<>();
// 获取名字长度为3的数据
for (String item:list){
if (item.length()>=3){
listSize.add(item);
}
}
System.out.println(listSize);
}
}
针对上面不同的需求,需要对集合进行一遍遍的遍历,如果我们想进行更高效的遍历,需要jdk8中stream特性进行操作
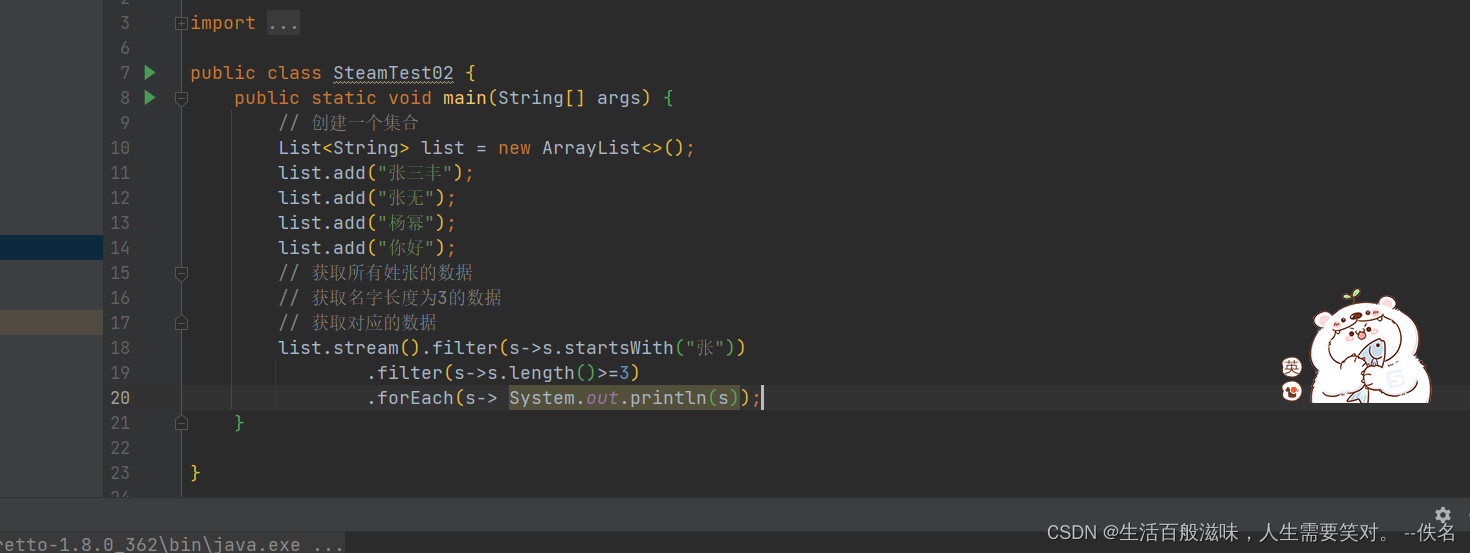
2.2 stream-forEach方法
forEach用来遍历流中的数据
void forEach(Consumer<? super T> action);
该方法接口一个Consumer接口,会将每一个流交给函数处理
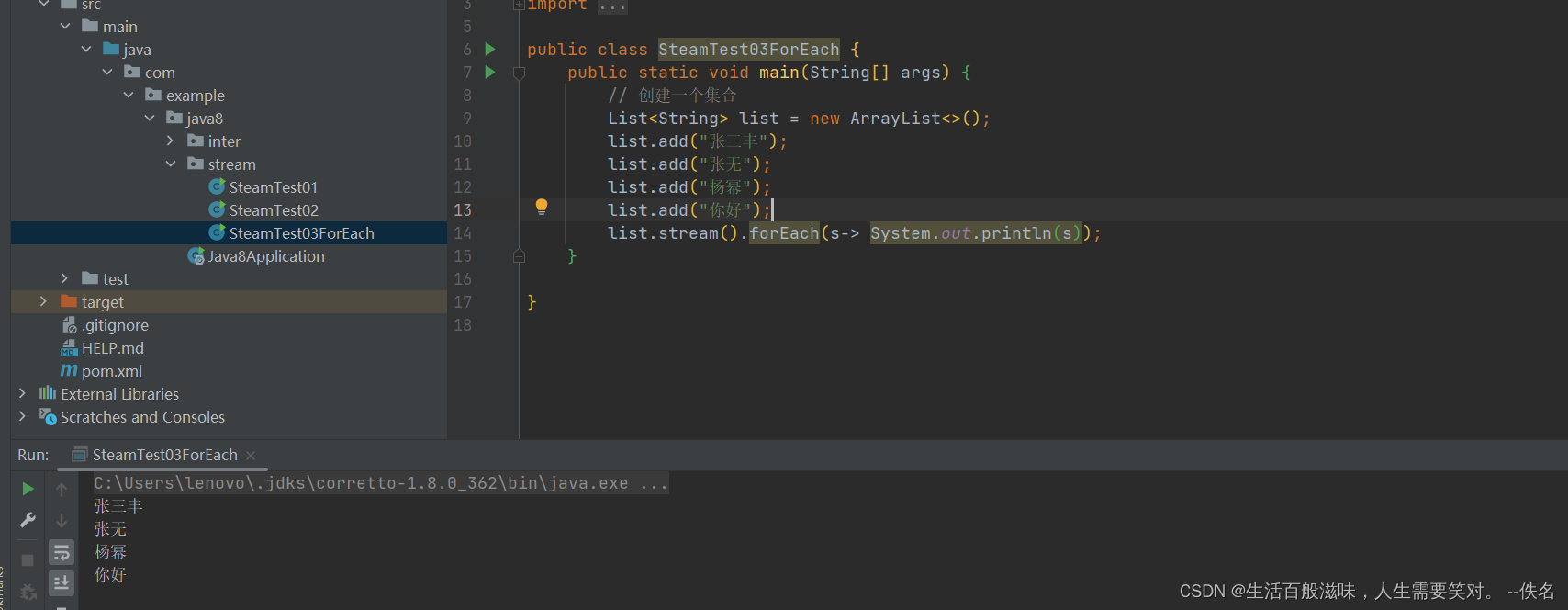
2.3 stream-count方法
count方法是用来计算流中元素的个数
long count();
该方法返回一个long值,代表个数
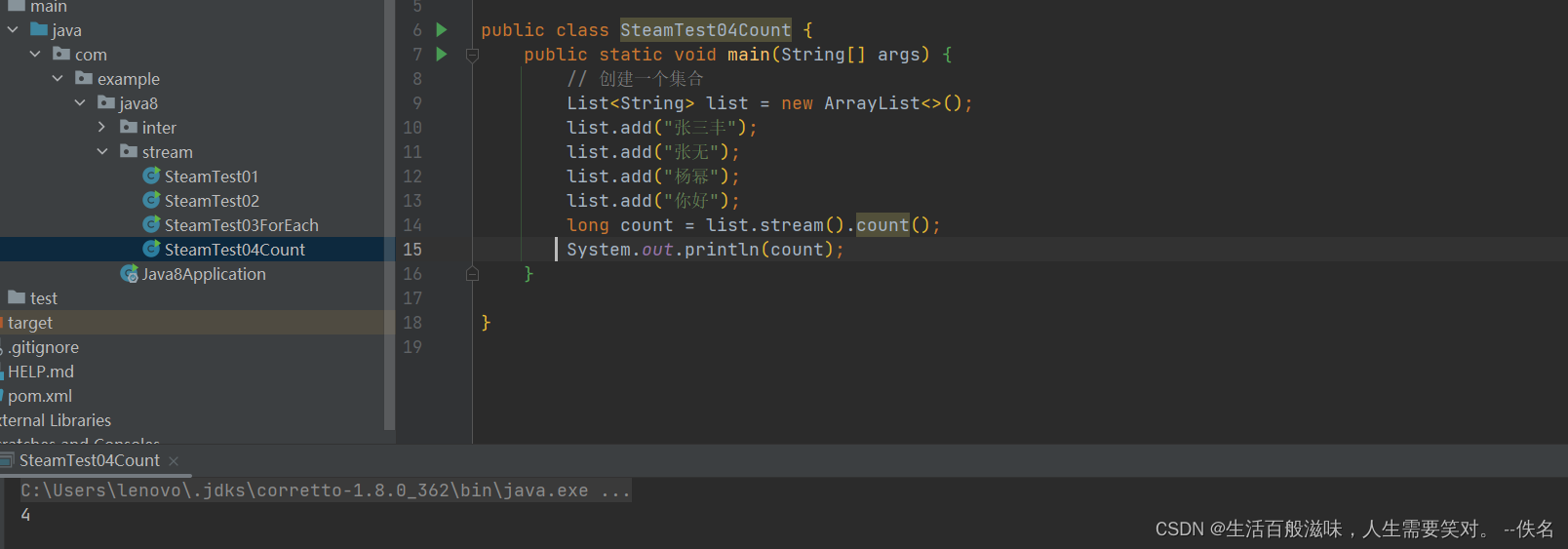
2.4 stream-filter方法
filter方法就是将一个流转换为另一个子集流
Stream<T> filter(Predicate<? super T> predicate);
该接口接受一个Predicate函数接口参数作为帅选条件
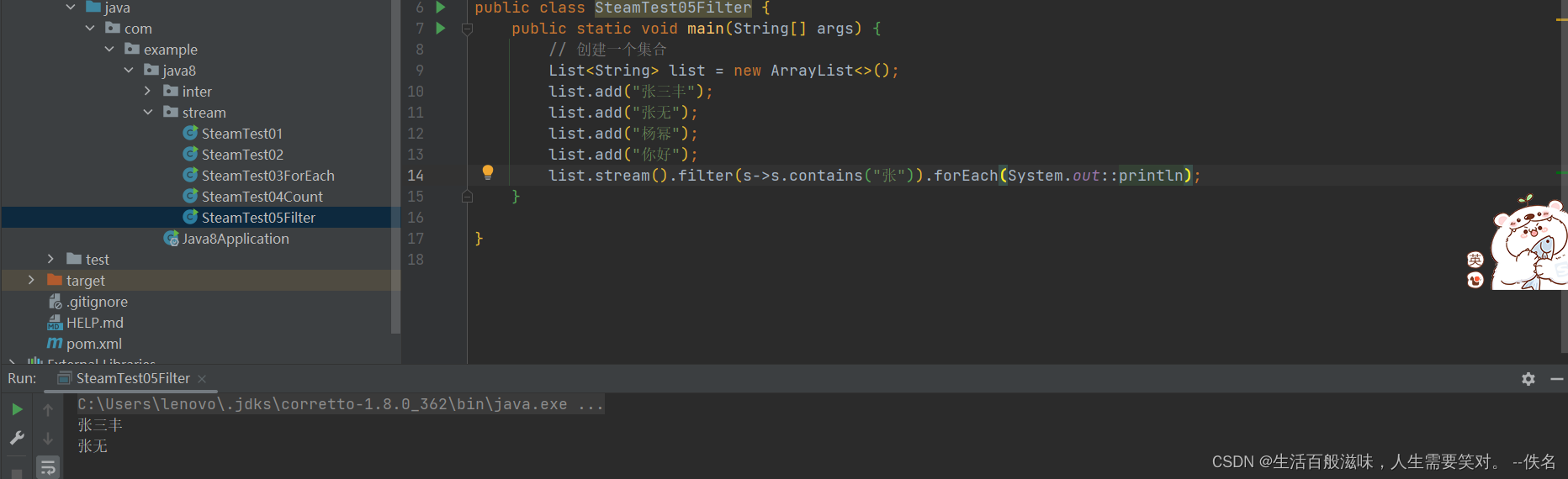
2.5 stream-limit方法
limit方法直接对流进行截取,支持前n个数据
Stream<T> limit(long maxSize);
参数传递是一个long值。
2.6 stream-spik方法
spik方法是跳过前面几个元素,然后转换为一个新的流
Stream<T> skip(long n);
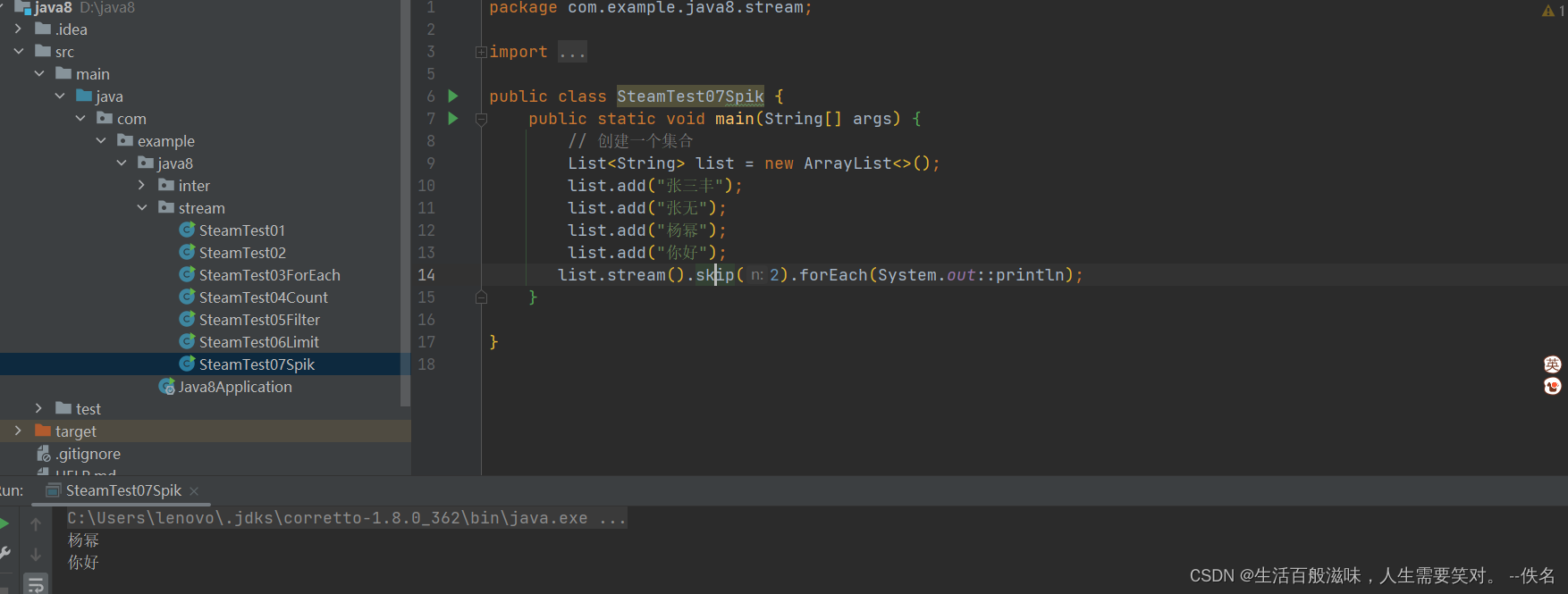
2.7 stream-map方法
map方法是将流中的元素映射到另一个流中
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
该方法接口一个Function函数式接口,将T类型数据转换为R类型数据
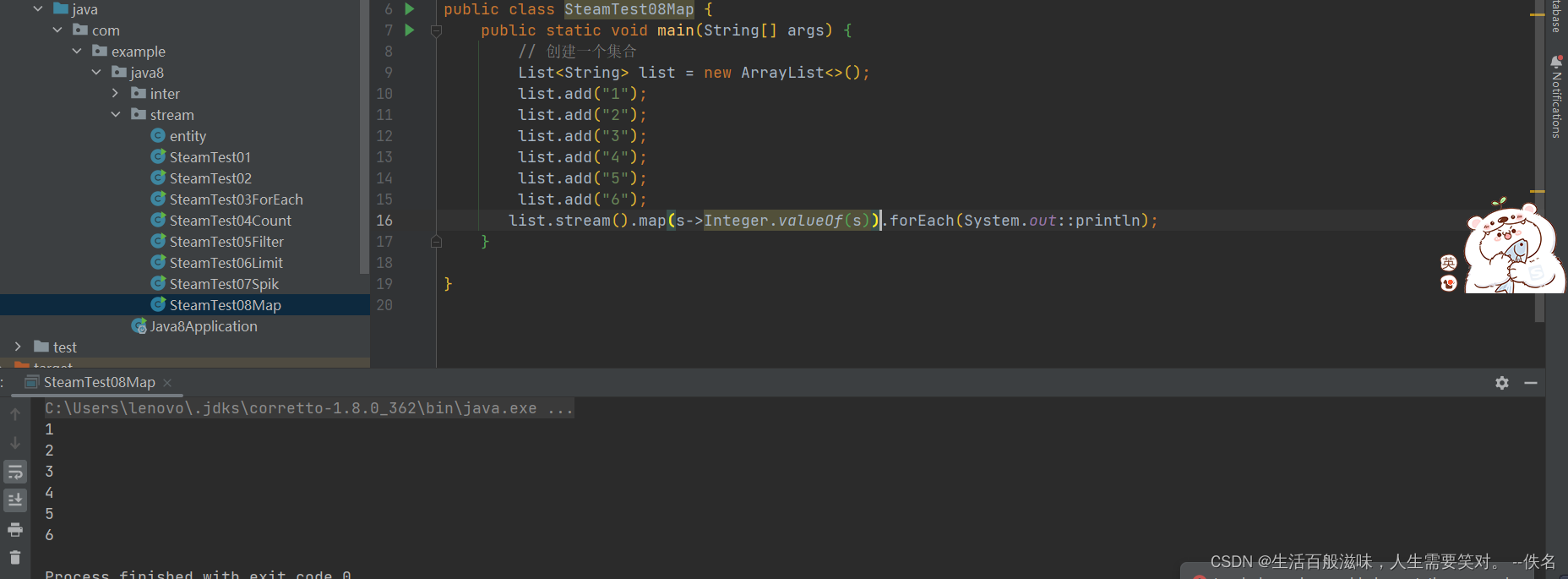
2.8 stream-sorted方法
sorted方法是将元素进行排序
Stream<T> sorted();
Stream<T> sorted(Comparator<? super T> comparator);
一个是自然排序,一个是自定义排序
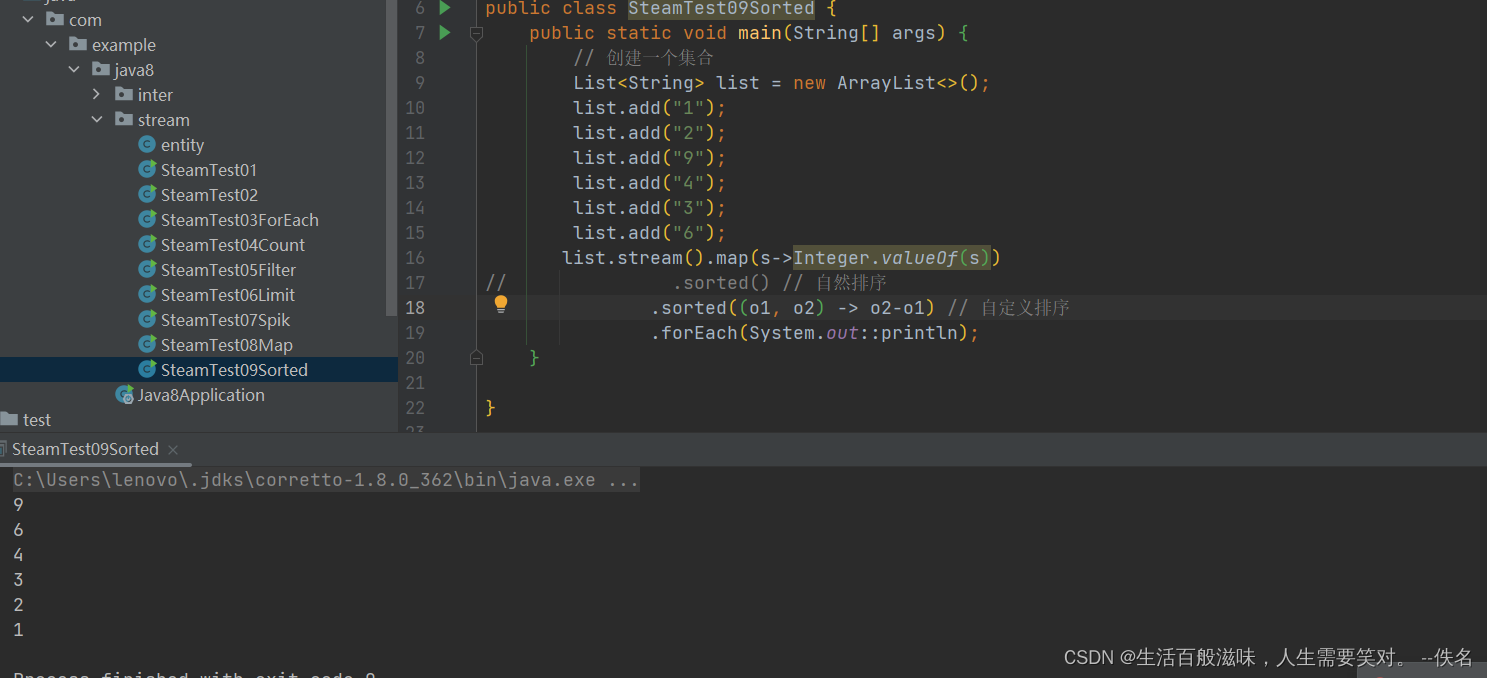
2.8 stream-distinct方法
distinct方法去掉元素中重复的数据
Stream<T> distinct();
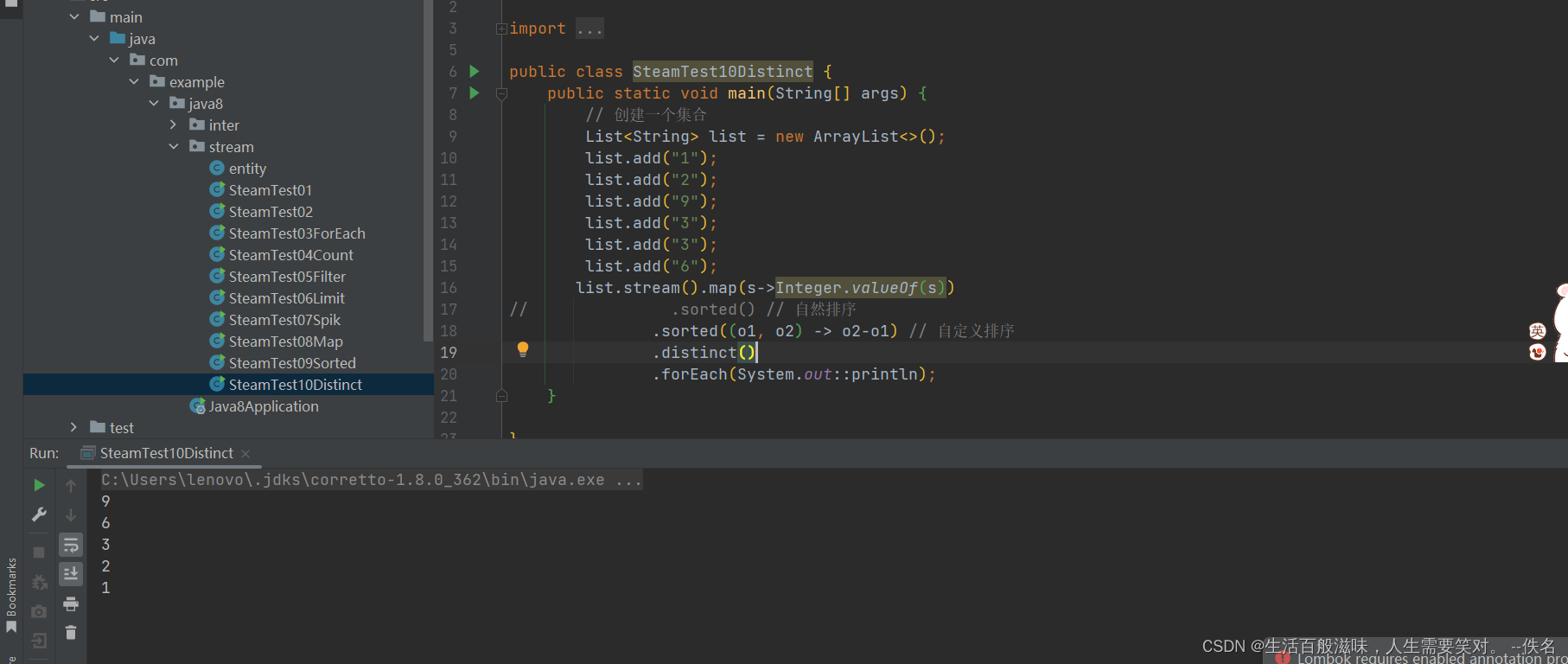
2.9 stream-reduce方法
reduce将所有数据归纳成一个数据
T reduce(T identity, BinaryOperator<T> accumulator);
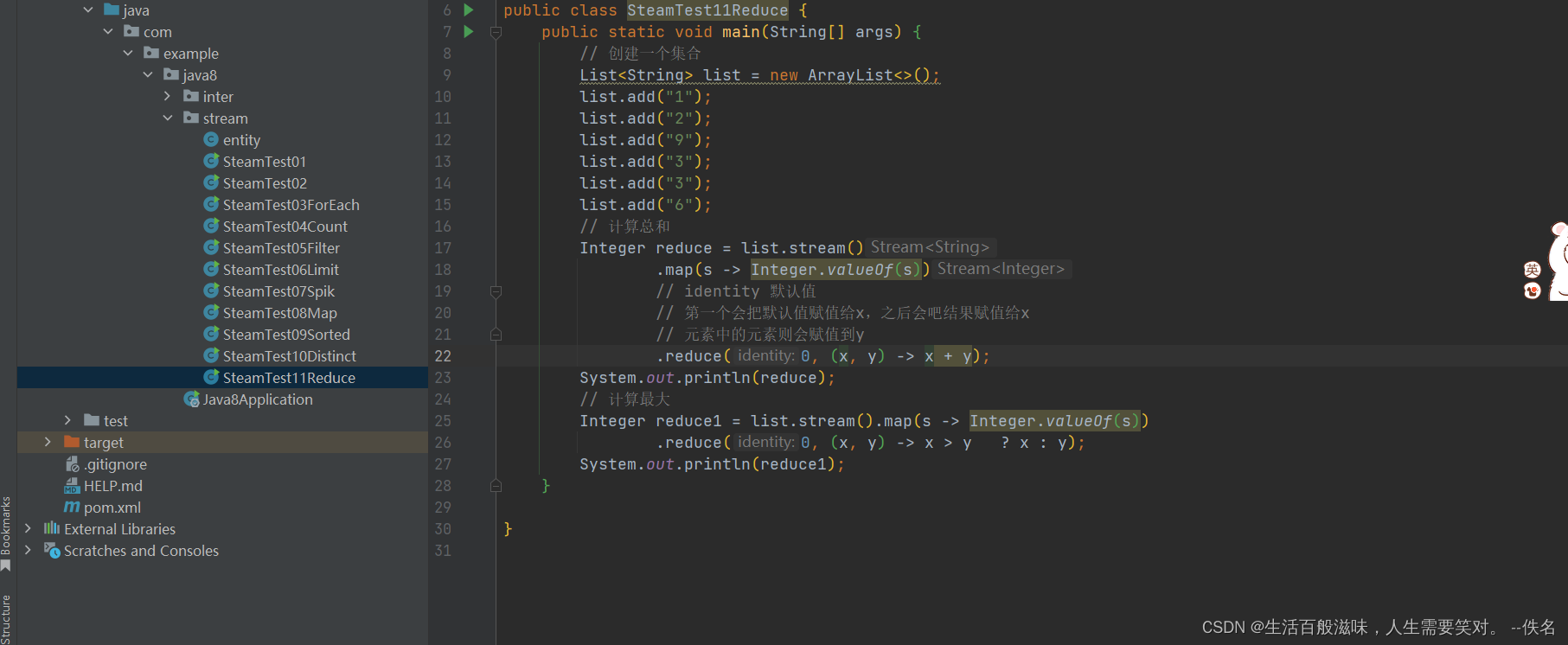
2.10 stream-mapToInt方法
mapToInt是将方法中Interger类型转换为int类型
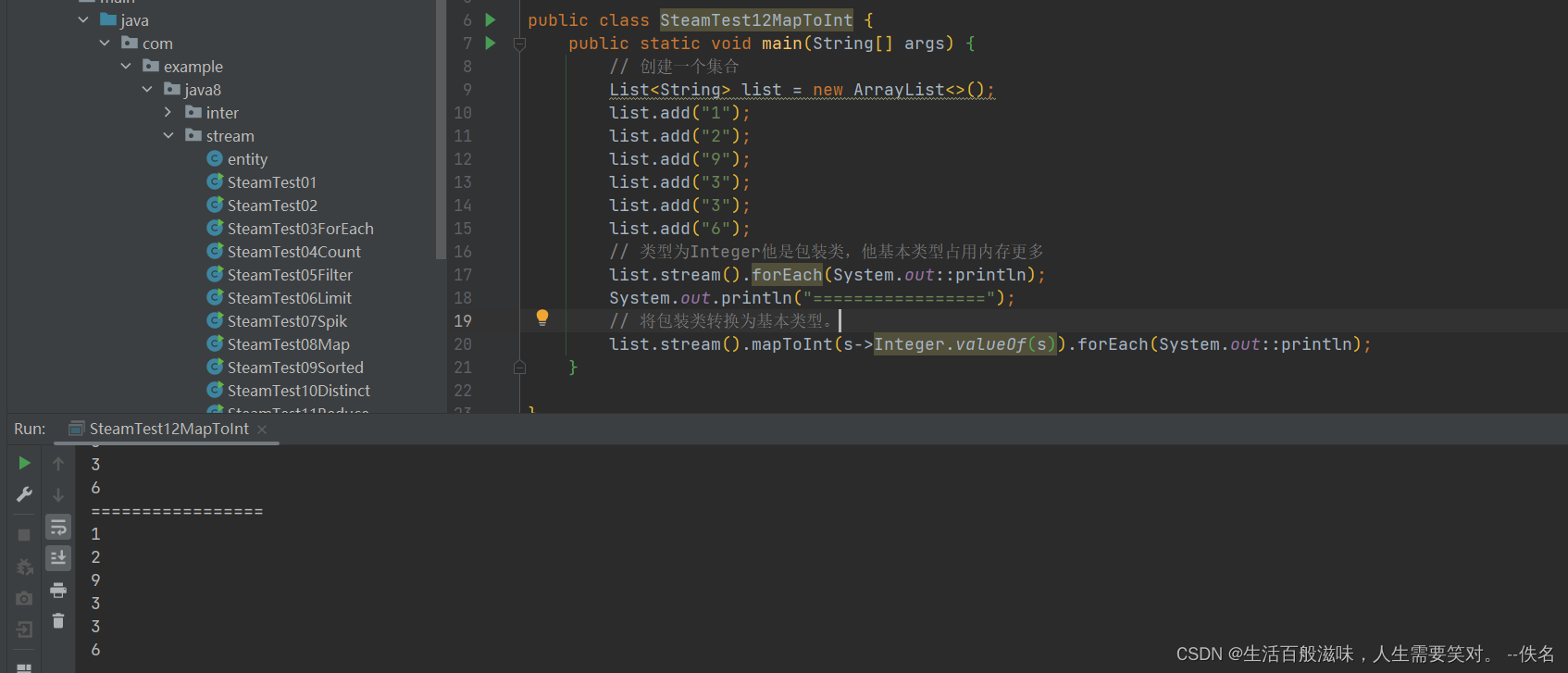
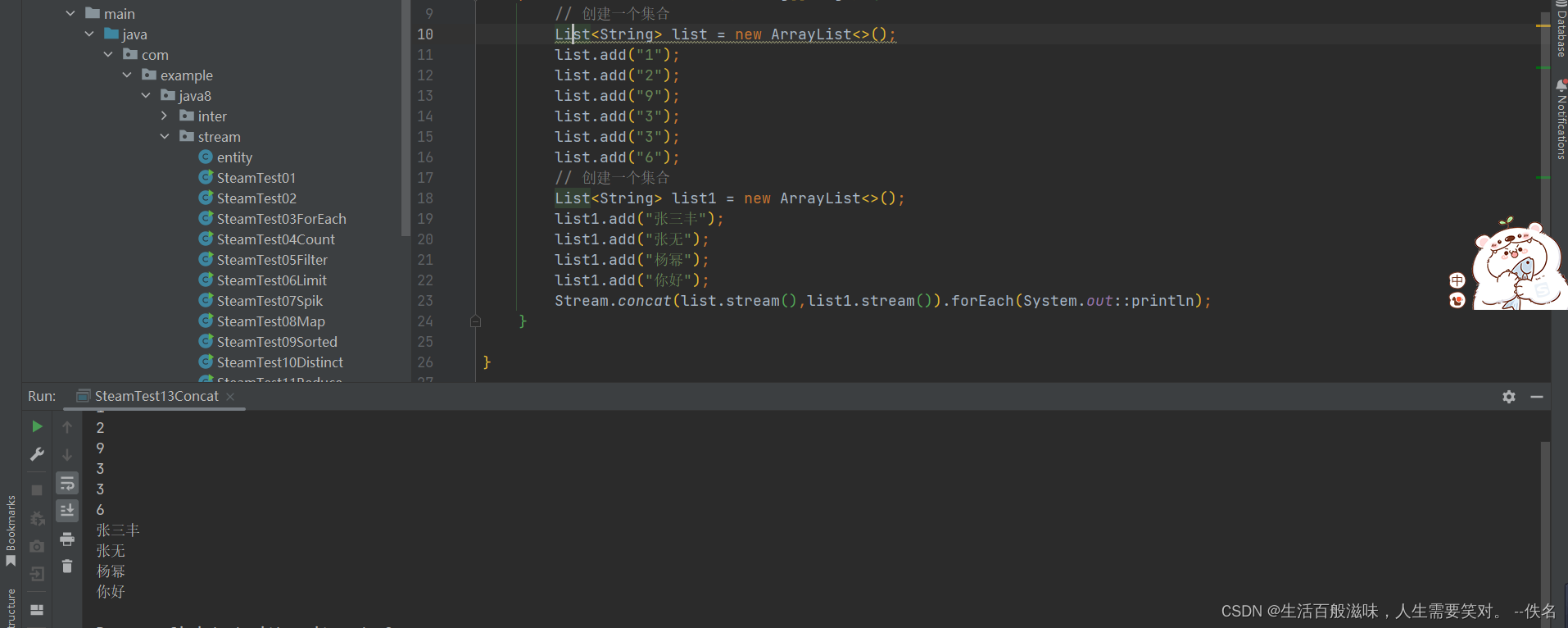
2.11 stream-concat方法
concat方法是将2个流合并到一个流里面,他是一个静态方法
public static <T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b) {
Objects.requireNonNull(a);
Objects.requireNonNull(b);
@SuppressWarnings("unchecked")
Spliterator<T> split = new Streams.ConcatSpliterator.OfRef<>(
(Spliterator<T>) a.spliterator(), (Spliterator<T>) b.spliterator());
Stream<T> stream = StreamSupport.stream(split, a.isParallel() || b.isParallel());
return stream.onClose(Streams.composedClose(a, b));
}
2.12 stream-结果数据到集合中
将结果转换为集合
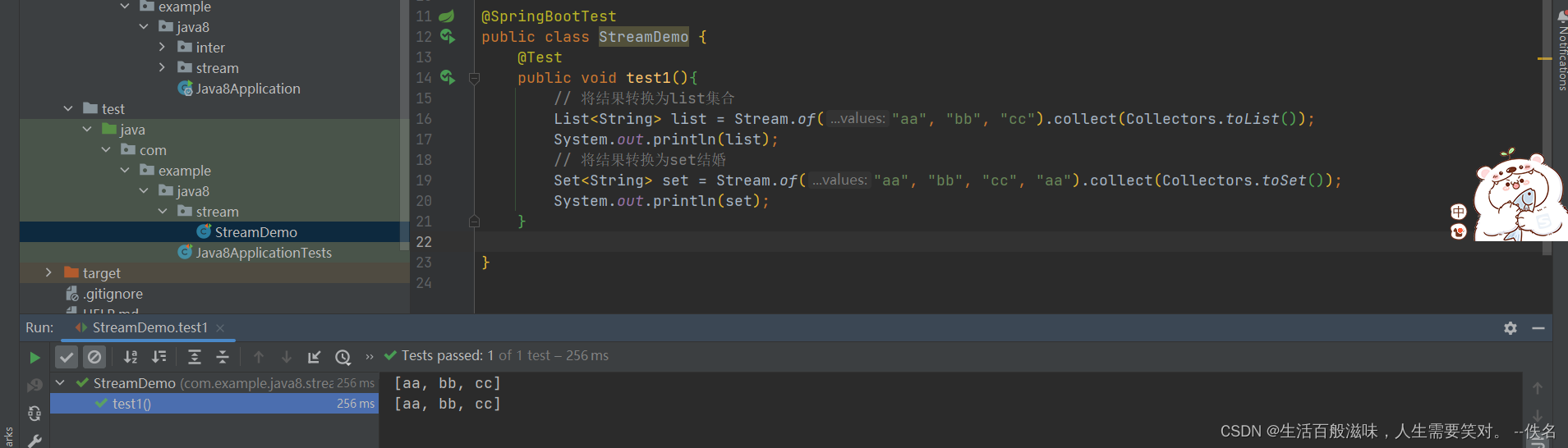
将结果转换数组
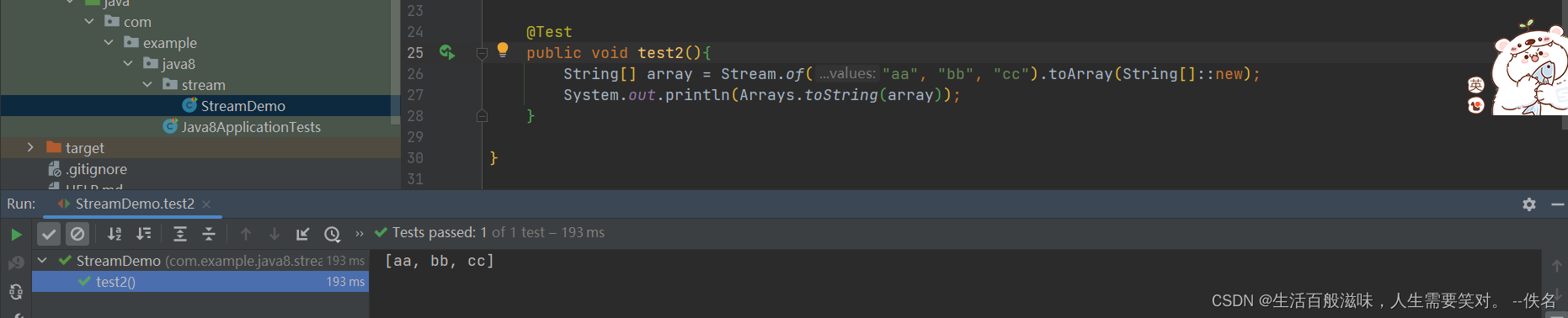
2.13 stream-对流中数据进行聚合操作
当对流进行操作后,可以像数据库一样同时对流进行一些操作,如果最大值,最小值,平均值,统计数量
@Test
public void test3(){
// 找到最大值
Optional<entity1> max = Stream.of(new entity1(1, "你好"),
new entity1(2, "杨幂"),
new entity1(3, "赵丽颖"),
new entity1(4, "知道"),
new entity1(40, "ok"))
.collect(Collectors.maxBy((k, k1) -> k.getId() - k1.getId()));
System.out.println(max.get());
// 找到id为最小的数据
Optional<entity1> min = Stream.of(new entity1(1, "你好"),
new entity1(2, "杨幂"),
new entity1(3, "赵丽颖"),
new entity1(4, "知道"),
new entity1(40, "ok"))
.collect(Collectors.minBy((k, k1) -> k.getId() - k1.getId()));
System.out.println(min.get());
// 计算出id的总和
Integer sum = Stream.of(new entity1(1, "你好"),
new entity1(2, "杨幂"),
new entity1(3, "赵丽颖"),
new entity1(4, "知道"),
new entity1(40, "ok"))
.collect(Collectors.summingInt(s -> s.getId()));
System.out.println(sum);
// 计算出id的平均值
Double avg = Stream.of(new entity1(1, "你好"),
new entity1(2, "杨幂"),
new entity1(3, "赵丽颖"),
new entity1(4, "知道"),
new entity1(40, "ok"))
.collect(Collectors.averagingInt(s -> s.getId()));
System.out.println(avg);
// 统计数量
Long collect = Stream.of(new entity1(1, "你好"),
new entity1(2, "杨幂"),
new entity1(3, "赵丽颖"),
new entity1(4, "知道"),
new entity1(40, "ok"))
.filter(s -> s.getId() > 1).collect(Collectors.counting());
System.out.println(collect);
}结果
entity1(id=40, name=ok)
entity1(id=1, name=你好)
50
10.0
4
2.14 stream-对流中数据进行分组
@Test
public void test4(){
// 根据id进行分组
Map<Integer, List<entity1>> map = Stream.of(new entity1(1, "你好"),
new entity1(3, "杨幂"),
new entity1(3, "赵丽颖"),
new entity1(4, "知道"),
new entity1(40, "ok"),
new entity1(40, "ok"))
.collect(Collectors.groupingBy(entity1::getId));
map.forEach((k,k1)->{
System.out.println(k+"\n"+k1);
});
// id大于3的为优秀,否则为不合格
Map<String, List<entity1>> map1 = Stream.of(new entity1(1, "你好"),
new entity1(3, "杨幂"),
new entity1(3, "赵丽颖"),
new entity1(4, "知道"),
new entity1(40, "ok"),
new entity1(40, "ok"))
.collect(Collectors.groupingBy(entity1 -> {
return entity1.getId() > 3 ? "优秀" : "不合格";
}));
map1.forEach((k,k1)->{
System.out.println(k+"\n"+k1);
});
}1
[entity1(id=1, name=你好)]
3
[entity1(id=3, name=杨幂), entity1(id=3, name=赵丽颖)]
4
[entity1(id=4, name=知道)]
40
[entity1(id=40, name=ok), entity1(id=40, name=ok)]
优秀
[entity1(id=4, name=知道), entity1(id=40, name=ok), entity1(id=40, name=ok)]
不合格
[entity1(id=1, name=你好), entity1(id=3, name=杨幂), entity1(id=3, name=赵丽颖)]
进行多级分组
@Test
public void test5(){
// 根据id进行分组
Map<Integer, Map<String, List<entity1>>> collect = Stream.of(new entity1(1, "你好"),
new entity1(3, "杨幂"),
new entity1(3, "赵丽颖"),
new entity1(4, "知道"),
new entity1(40, "ok"),
new entity1(40, "ok"))
.collect(Collectors.groupingBy(entity1::getId, Collectors.groupingBy(entity1::getName)));
collect.forEach((k,k1)->{
k1.forEach((k2,k3)->{
System.out.println(k+"\n"+k2+"\n"+k3);
});
});
System.out.println("----------------------------");
// id大于3的为优秀,否则为不合格
Map<String, Map<String, List<entity1>>> collect1 = Stream.of(new entity1(1, "你好"),
new entity1(3, "杨幂"),
new entity1(3, "赵丽颖"),
new entity1(4, "知道"),
new entity1(40, "ok"),
new entity1(40, "ok"))
.collect(Collectors.groupingBy(entity1::getName,
Collectors.groupingBy(entity1 -> entity1.getId() > 3 ? "优秀" : "不合格")));
collect1.forEach((k,k1)-> {
k1.forEach((k2, k3) -> {
System.out.println(k + "\n" + k2 + "\n" + k3);
});
});
}1
你好
[entity1(id=1, name=你好)]
3
赵丽颖
[entity1(id=3, name=赵丽颖)]
3
杨幂
[entity1(id=3, name=杨幂)]
4
知道
[entity1(id=4, name=知道)]
40
ok
[entity1(id=40, name=ok), entity1(id=40, name=ok)]
----------------------------
知道
优秀
[entity1(id=4, name=知道)]
赵丽颖
不合格
[entity1(id=3, name=赵丽颖)]
你好
不合格
[entity1(id=1, name=你好)]
杨幂
不合格
[entity1(id=3, name=杨幂)]
ok
优秀
[entity1(id=40, name=ok), entity1(id=40, name=ok)]
2.15 stream-对流中数据进行拼接
@Test
public void test6(){
// 对数据进行拼接
String collect = Stream.of(new entity1(1, "你好"),
new entity1(3, "杨幂"),
new entity1(3, "赵丽颖"),
new entity1(4, "知道"),
new entity1(40, "ok"),
new entity1(40, "ok"))
.map(entity1::getName)
.collect(Collectors.joining());
System.out.println(collect);
// 按逗号进行拼接
String collect1 = Stream.of(new entity1(1, "你好"),
new entity1(3, "杨幂"),
new entity1(3, "赵丽颖"),
new entity1(4, "知道"),
new entity1(40, "ok"),
new entity1(40, "ok"))
.map(entity1::getName)
.collect(Collectors.joining(","));
System.out.println(collect1);
// 按逗号进行拼接,并加上前缀和后缀
String collect2 = Stream.of(new entity1(1, "你好"),
new entity1(3, "杨幂"),
new entity1(3, "赵丽颖"),
new entity1(4, "知道"),
new entity1(40, "ok"),
new entity1(40, "ok"))
.map(entity1::getName)
.collect(Collectors.joining(",","aaa","ccc"));
System.out.println(collect2);
}
你好杨幂赵丽颖知道okok
你好,杨幂,赵丽颖,知道,ok,ok
aaa你好,杨幂,赵丽颖,知道,ok,okccc
2.15 stream-串行流
穿行流也就是在一个线程上运行
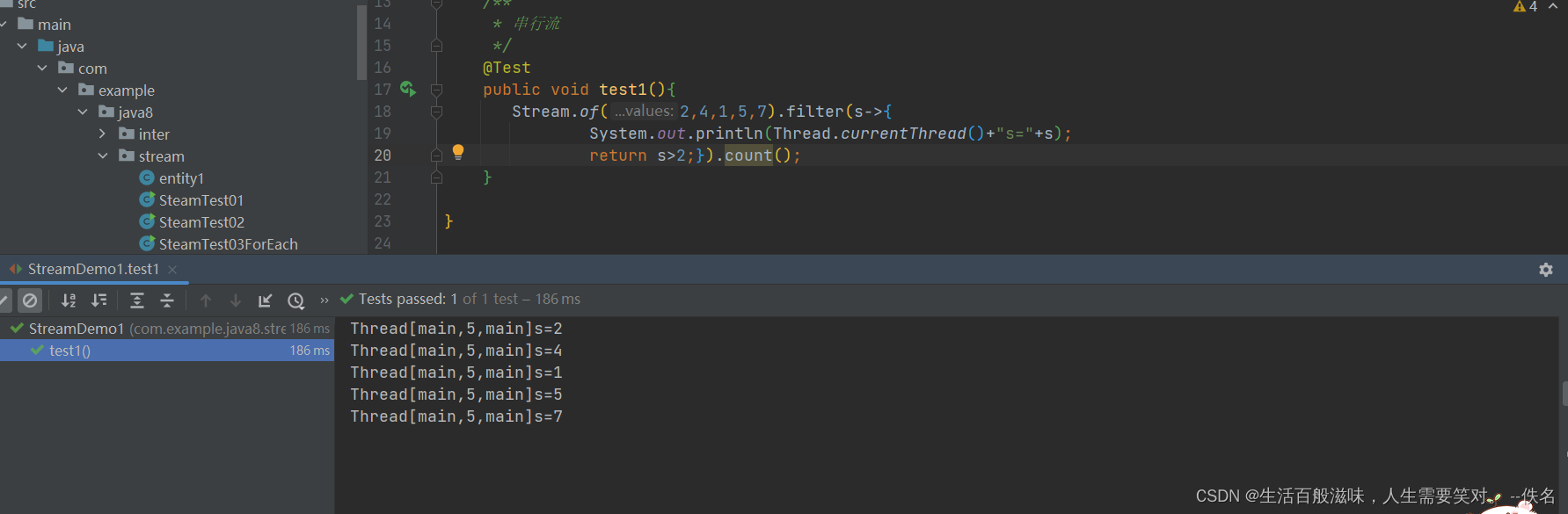
2.16 stream-并行流
可以通过2种方式获取
集合中通过parallelStream获取
串行流中通过parallel获取
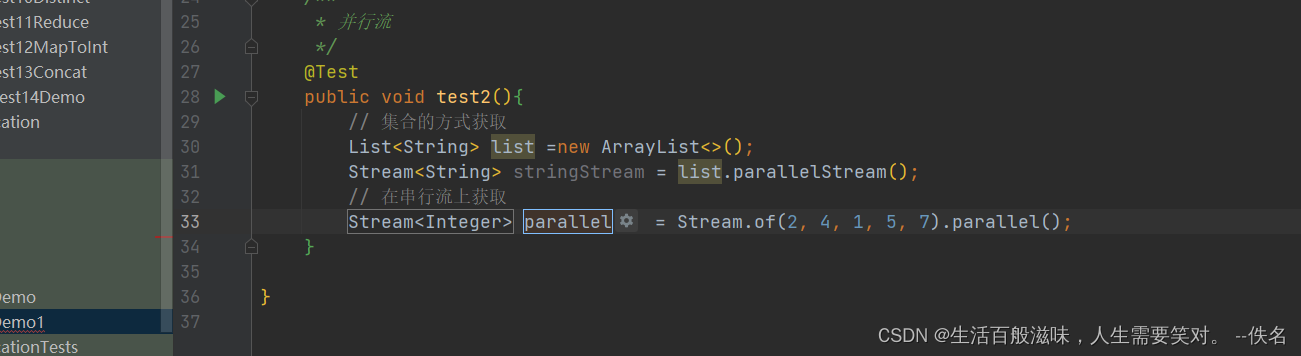
如何使用
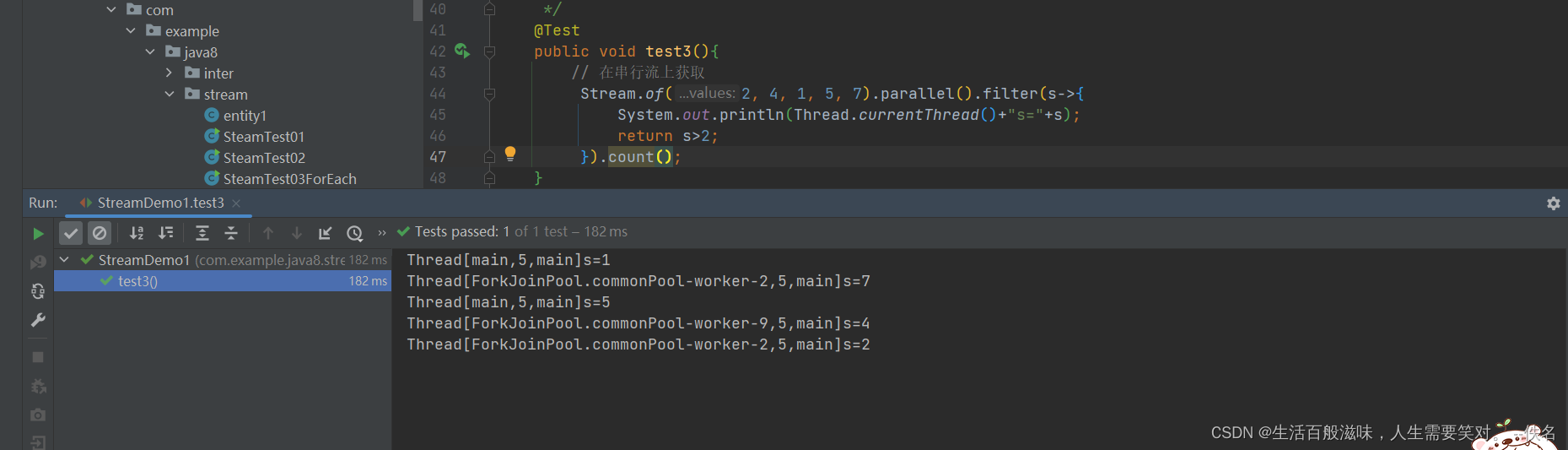
2.17 stream-for循环/并行流/串行流对比
package com.example.java8.stream;
import org.junit.jupiter.api.AfterAll;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.event.annotation.AfterTestMethod;
import org.springframework.test.context.event.annotation.BeforeTestMethod;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.LongStream;
import java.util.stream.Stream;
@SpringBootTest
public class StreamDemo2 {
private static long times = 500000000;
/**
* for循环
*/
@Test
public void test(){
System.out.println("普通for循环");
long l = System.currentTimeMillis();
int sum = 0;
for (int i =0;i<times;i++){
sum+=i;
}
System.out.println("普通for循环耗时:"+(System.currentTimeMillis()-l));
}
/**
* 串行流
*/
@Test
public void test1(){
System.out.println("串行流循环");
long l = System.currentTimeMillis();
LongStream.rangeClosed(0,times)
.reduce(0,Long::sum);
System.out.println("串行流循环耗时:"+(System.currentTimeMillis()-l));
}
/**
* 并行流
*/
@Test
public void test2(){
System.out.println("并行流循环");
long l = System.currentTimeMillis();
LongStream.rangeClosed(0,times).parallel()
.reduce(0,Long::sum);
System.out.println("并行流循环耗时:"+(System.currentTimeMillis()-l));
}
}
结果
普通for循环
普通for循环耗时:310
串行流循环
串行流循环耗时:222
并行流循环
并行流循环耗时:65
2.17 stream-flatMap
flatMap方法主要是将一个流中每一个元素都转换为一个流,然后将这些流进行连接
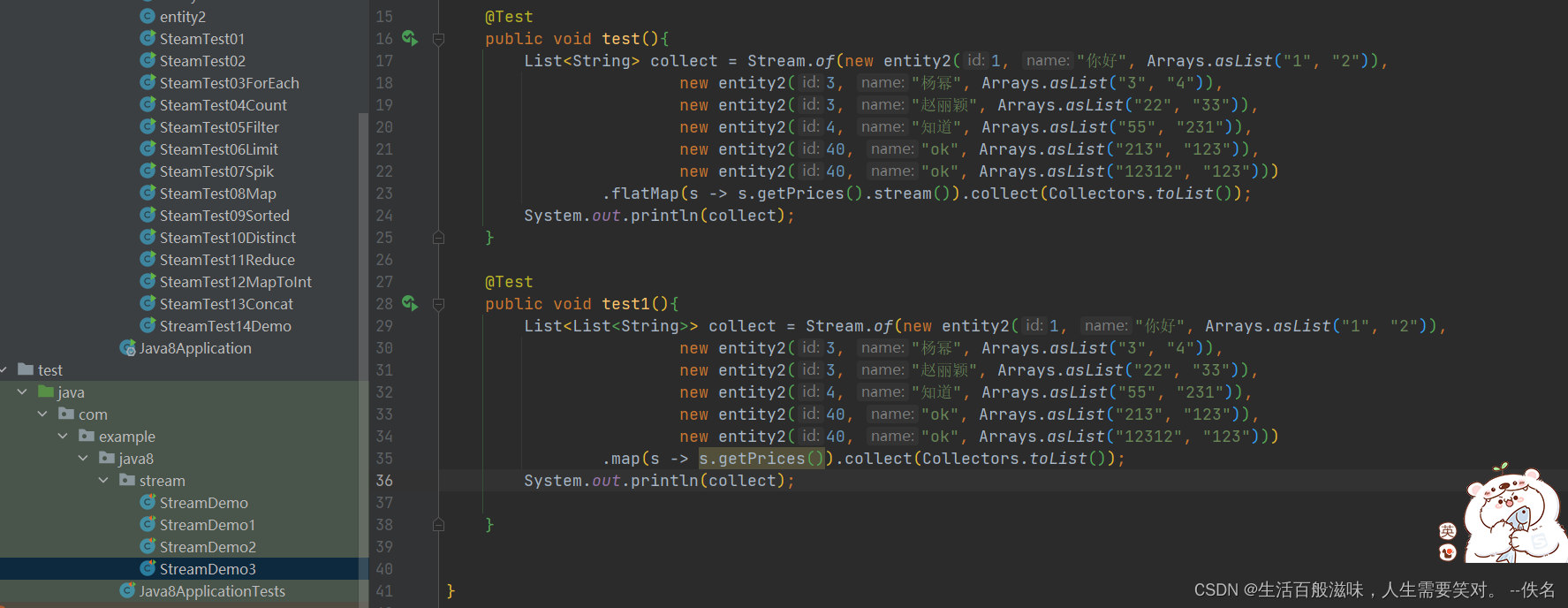
结果
[1, 2, 3, 4, 22, 33, 55, 231, 213, 123, 12312, 123]
3:Optional类
optional是一个没有子类的工具类,,optional是一个可以为null的容器对象,它的主要作用是避免null检查,防止出现空指针
3.1 optional的创建方式
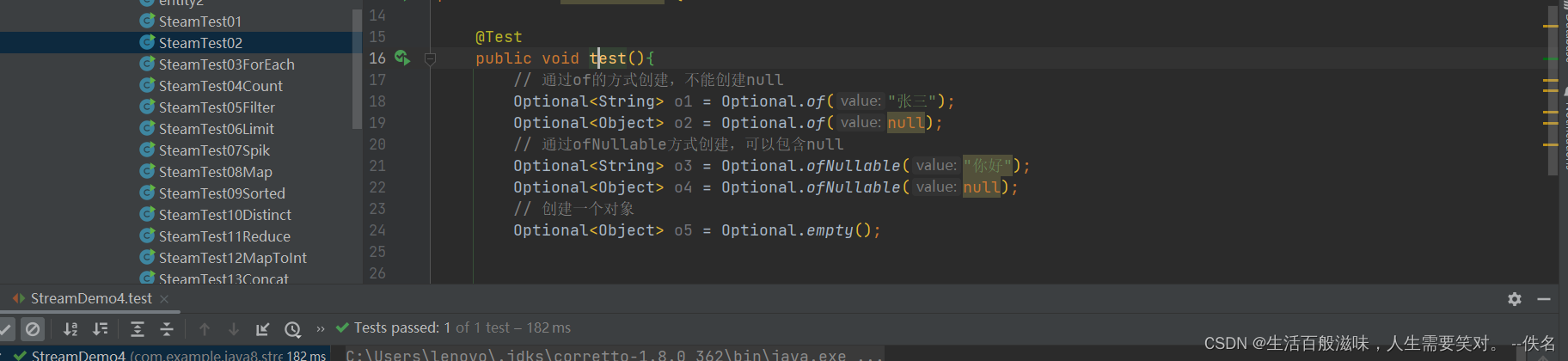
3.2 optional的基本使用
/**
* get()方法有值返回,没有值会抛出异常
* isPresent() 方法返回true和false 是用来判定对象是否为null
* orElse() 方法如果是空值,则返回方法中传递的参数
*/
@Test
public void test1(){
Optional<String> o = Optional.of("你好");
Optional<String> o1 = Optional.empty();
if (o.isPresent()){
String s1 = o.get();
System.out.println(s1);
}
if (o1.isPresent()){
String s2 = o1.get();
System.out.println(s2);
}else {
System.out.println("空对象");
}
String s3 = o.orElse("知道了");
String s4 = o1.orElse("收到");
System.out.println(s3);
System.out.println(s4);
}
4:函数型接口
4.1 常用接口有那些
一 :Consumer 消费者接口
有参无返回值
@FunctionalInterface
public interface Consumer<T> {
/**
* Performs this operation on the given argument.
*
* @param t the input argument
*/
void accept(T t);
使用:

andThen方法的使用
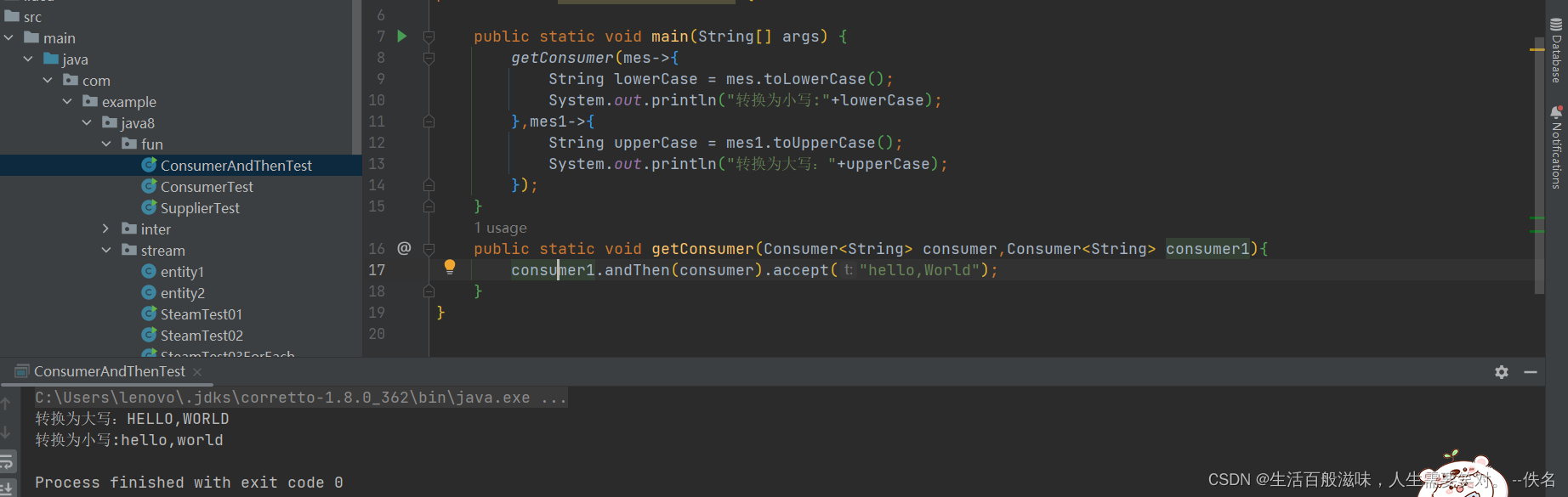
二:Function
有参有返回值 根据一个类型的数据得到另一个类型的数据,前者称为前者条件,后者为后置条件
@FunctionalInterface
public interface Function<T, R> {
/**
* Applies this function to the given argument.
*
* @param t the function argument
* @return the function result
*/
R apply(T t);
使用:

三:Predicate
有参返回true/false
@FunctionalInterface
public interface Predicate<T> {
/**
* Evaluates this predicate on the given argument.
*
* @param t the input argument
* @return {@code true} if the input argument matches the predicate,
* otherwise {@code false}
*/
boolean test(T t);
使用:
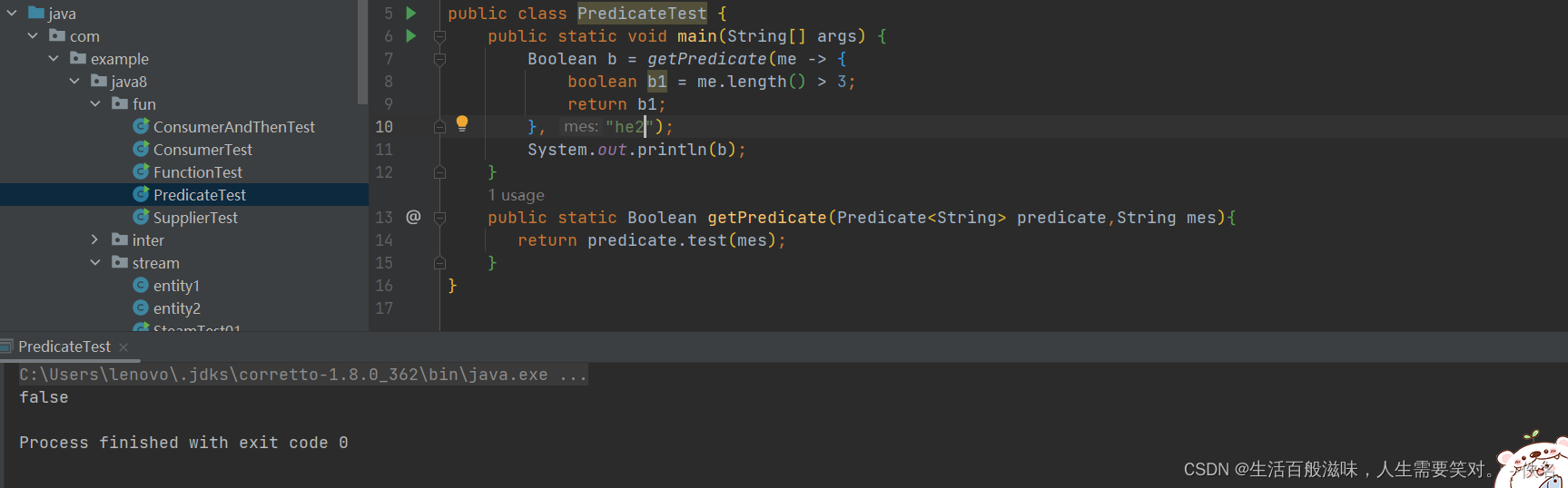
四:Supplier 供给者结构
无参有返回值
@FunctionalInterface
public interface Supplier<T> {
/**
* Gets a result.
*
* @return a result
*/
T get();
使用
package com.example.java8.fun;
import java.util.function.Supplier;
public class SupplierTest {
public static void main(String[] args) {
String supplier = getSupplier(() -> "你好");
System.out.println(supplier);
}
public static String getSupplier(Supplier<String> supplier){
return supplier.get();
}
}















 9540
9540











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









