







字符编码
字符编码的概念
字符串类型、文本文件的内容都是由字符组成的,'但凡涉及到字符的存取,都需要考虑字符编码的问题'。
# 1、软件运行前,软件的代码及其相关数据都是存放于硬盘中的
# 2、任何软件的启动都是将数据从硬盘中读入内存,然后cpu从内存中取出指令并执行
# 3、软件运行过程中产生的数据最先都是存放于内存中的,若想永久保存软件产生的数据,则需要将数据由内存写入硬盘
文本编辑器读取文件内容的流程:
阶段1、启动一个文件编辑器(文本编辑器如nodepad++,pycharm,word)
阶段2、文件编辑器会将文件内容从硬盘读入内存
阶段3、文本编辑器会将刚刚读入内存中的内容显示到屏幕上
字符编码介绍
字符编码的前提:
它只跟字符类型和文本类型相关。跟视频文件、音频文件、图片文件等无关
人类在与计算机交互时,用的都是人类能读懂的字符,如中文字符、英文字符、日文字符等。
而计算机内部只能够认识二进制01,计算机之所以能够认识各种各样的字符,那是因为计算机的内部维护着一张字符编码表。
毫无疑问,由人类的字符到计算机中的数字,必须经历一个过程,如下:
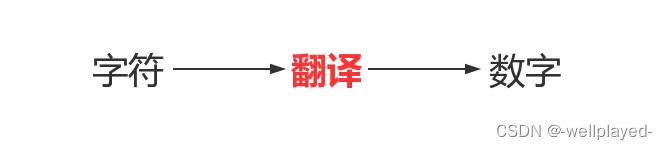
翻译的过程必须参照一个特定的标准,该标准称之为字符编码表,该表上存放的就是字符与数字一一对应的关系。
字符编码中的编码指的是翻译或者转换的意思,即将人能理解的字符翻译成计算机能识别的数字。
字符编码表:一些字符和数字之间的对应关系
字符编码的发展史
字符编码的发展经历了三个重要的阶段,如下:
阶段一:一家独大
现代计算机起源于美国,所以最先考虑仅仅是让计算机识别英文字符,于是诞生了ASCII表。
如图:

ASCII表的特点:
1、只有英文字符与数字的一一对应关系
2、一个英文字符对应1Bytes,1Bytes=8bit,8bit最多包含256个数字,可以对应256个字符,足够表示所有英文字符记忆:
A-Z: 65-90
a-z: 97-122
0-9: 48-
阶段二:诸侯割据、天下大乱
为了让计算机能够识别中文和英文,中国人定制了GBK
GBK表的特点:
1、只有中文字符、英文字符与数字的一一对应关系
2、一个英文字符对应1Bytes
一个中文字符对应2Bytes
补充说明:
1Bytes=8bit,8bit最多包含256个数字,可以对应256个字符,足够表示所有英文字符
2Bytes=16bit,16bit最多包含65536个数字,可以对应65536个字符,足够表示所有中文字符
日本人就为了让计算机识别他们的日文字符,也研究了一套字符编码表:
# Shift_JIS表:只有日文字符、英文字符与数字的一一对应关系
韩国人也向让计算机能够识别韩文字符,所以也研究了一套字符编码表:
# Euc-kr表:只有韩文字符、英文字符与数字的一一对应关系
……
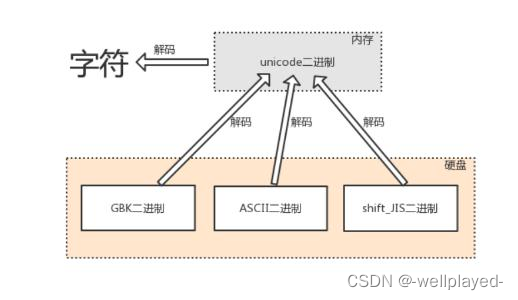
此时,美国人用的计算机里使用字符编码标准是ASCII、中国人用的计算机里使用字符编码标准是GBK、日本人用的计算机里使用字符编码标准是Shift_JIS,如下图所示:
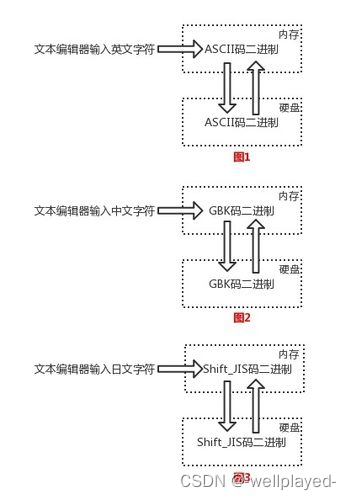
字符编码发展到了这个阶段,可以用一句话概括:诸侯割据、天下大乱。
阶段三:天下一统
unicode(万国码)于1990年开始研发,1994年正式公布,具备两大特点:
#1. 存在所有语言中的所有字符与数字的一一对应关系,即兼容万国字符
#2. 与传统的字符编码的二进制数都有对应关系,详解如下
很多地方或老的系统、应用软件仍会采用各种各样传统的编码,这是历史遗留问题。此处需要强调:软件是存放于硬盘的,而运行软件是要将软件加载到内存的,面对硬盘中存放的各种传统编码的软件,想让我们的计算机能够将它们全都正常运行而不出现乱码,内存中必须有一种兼容万国的编码,并且该编码需要与其他编码有相对应的映射/转换关系,这就是unicode的第二大特点产生的缘由
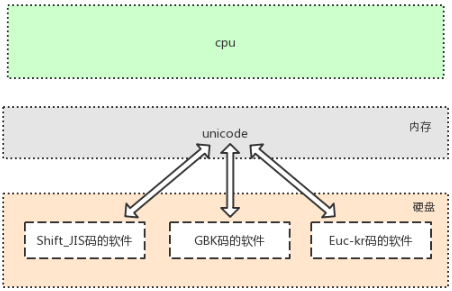
文本编辑器输入任何字符都是最新存在于内存中,是unicode编码的,存放于硬盘中,则可以转换成任意其他编码,只要该编码可以支持相应的字符
# 英文字符可以被ASCII识别
英文字符--->unciode格式的数字--->ASCII格式的数字
# 中文字符、英文字符可以被GBK识别
中文字符、英文字符--->unicode格式的数字--->gbk格式的数字
# 日文字符、英文字符可以被shift-JIS识别
日文字符、英文字符--->unicode格式的数字--->shift-JIS格式的数字
unicode的一些问题:
# 统一使用的是2个字节来保存字符
如果是英文字符:ASCII码用1个字节保存一个英文字符
而万国码中使用2个字节保存英文字符
从而就造成了空间的浪费# 优化
从内存中得万国码到硬盘中得utf-8字符
utf-8就是目前大家统一使用的一种编码:
1. 它统一使用一个字节来保存英文字符
2. 统一使用三个字节来保存中文字符
"""在utf-8编码表中,一个汉字使用的是三个字节!!!"""
# utf系列:
utf-8
utf-16
utf-...
utf8mb4: 它能够存储表情
编码与解码
由字符转换成内存中的unicode,以及由unicode转换成其他编码的过程,都称为编码encode。
编码:
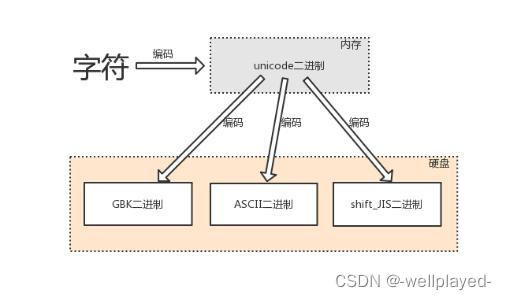
由内存中的unicode转换成字符,以及由其他编码转换成unicode的过程,都称为解码decode。
解码:
在诸多文件类型中,只有文本文件的内存是由字符组成的,因而文本文件的存取也涉及到字符编码的问题。
字符编码的应用
我们学习字符编码就是为了存取字符时不发生乱码问题:
#1、内存中固定使用unicode无论输入任何字符都不会发生乱码
#2、我们能够修改的是存/取硬盘的编码方式,如果编码设置不正确将会出现乱码问题。乱码问题分为两种:存乱了,读乱了
存乱了:如果用户输入的内容中包含中文和日文字符,如果单纯以shift_JIS存,日文可以正常写入硬盘,而由于中文字符在shift_jis中没有找到对应关系而导致存乱了
读乱了:如果硬盘中的数据是shift_JIS格式存储的,采GBK格式读入内存就读乱了
总结:
#1. 保证存的时候不乱:在由内存写入硬盘时,必须将编码格式设置为支持所输入字符的编码格式
#2. 保证存的时候不乱:在由硬盘读入内存时,必须采用与写入硬盘时相同的编码格式
拓展:代码的运用
1.统计一个字符串中得单词个数
s1 = 'kevin say hello hello hello sb sb sb jerry jerry handsome handsome handsome'
# 返回的结果:{'单词':3}
# 统计单词的个数
s1 = 'kevin say hello hello hello sb sb sb jerry jerry handsome handsome handsome sb sb sb jerry jerry handsome handsome handsome'
## 写任何的功能都不要上来就写代码,写代码一定是最后的操作
"""
1. 先分析我们需要做哪些功能(需求分析)
2. 最后把你分析的步骤写出来:注释、笔记、文档、
3. 开发方案-------->给你一个需求,你来写一写这个需求应该怎么开发------->数据库如何设计、表结构如何设计、逻辑有哪些...
4. 功能比较少、就以注释的形式写出你的开发步骤
"""
#### 以后拿到不管什么样的数据类型,如果你能够把它转为列表形式,就已经很简单了
# 列表类型是我们最容易处理的数据类型
# 1. 先把字符串转为列表,我们可以使用切分字符串的形式,转为列表
s_list = s1.split(
' ') # ['kevin', 'say', 'hello', 'hello', 'hello', 'sb', 'sb', 'sb', 'jerry', 'jerry', 'handsome', 'handsome', 'handsome',]
print(s_list)
# 2. 定义一个空字典:用来存储返回的结果
word_dic = {} # {kevin:1, say:1}
# 3. 来循环列表:只要是列表,除了正常的取值之外,就要想到循环
for i in s_list:
# word_dic里面如果没有当前循环的这个单词,就增加一个,如果存在了,就把个数+1
if i not in word_dic:
word_dic[i] = 1 # {'kevin':1}
else:
# word_dic['kevin'] = word_dic['kevin'] + 1
word_dic[i] += 1
print(word_dic) # {'kevin': 1, 'say': 1, 'hello': 3, 'sb': 3, 'jerry': 2, 'handsome': 3}
# {'kevin': 1, 'say': 1, 'hello': 3, 'sb': 6, 'jerry': 4, 'handsome': 6}
2.统计字符串中字符的个数
s2 = 'kevinsayhellosb' # 你要知道字符串是可以支持循环的
s2 = 'kevinsayhellosb' # 你要知道字符串是可以支持循环的
# 1. 先定义一个空字典:用来存储我们统计的结果
temp_dict = {}
# 2. 循环字符串
for i in s2:
if i not in temp_dict:
temp_dict[i] = 1
else:
temp_dict[i] += 1
print(temp_dict) # {'k': 1, 'e': 2, 'v': 1, 'i': 1, 'n': 1, 's': 2, 'a': 1, 'y': 1, 'h': 1, 'l': 2, 'o': 1, 'b': 1}















 920
920











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









