







元类
一 元类介绍
什么是元类呢?一切源自于一句话:python中一切皆为对象。让我们先定义一个类,然后逐步分析
class StanfordTeacher(object):
school='Stanford'
def __init__(self,name,age):
self.name=name
self.age=age
def say(self):
print('%s says welcome to the Stanford to learn Python' %self.name)所有的对象都是实例化或者说调用类而得到的(调用类的过程称为类的实例化),比如对象t1是调用类StanfordTeacher得到的
t1=StanfordTeacher('lili',18)
print(type(t1)) #查看对象t1的类是<class '__main__.StanfordTeacher'>如果一切皆为对象,那么类StanfordTeacher本质也是一个对象,既然所有的对象都是调用类得到的,那么StanfordTeacher必然也是调用了一个类得到的,这个类称为元类
于是我们可以推导出===>产生StanfordTeacher的过程一定发生了:StanfordTeacher=元类(...)
print(type(StanfordTeacher))
# 结果为<class 'type'>,证明是调用了type这个元类而产生的StanfordTeacher,即默认的元类为type
插图:元类与类、对象的关系

二 class关键字创建类的流程分析
上文我们基于python中一切皆为对象的概念分析出:我们用class关键字定义的类本身也是一个对象,负责产生该对象的类称之为元类(元类可以简称为类的类),内置的元类为type
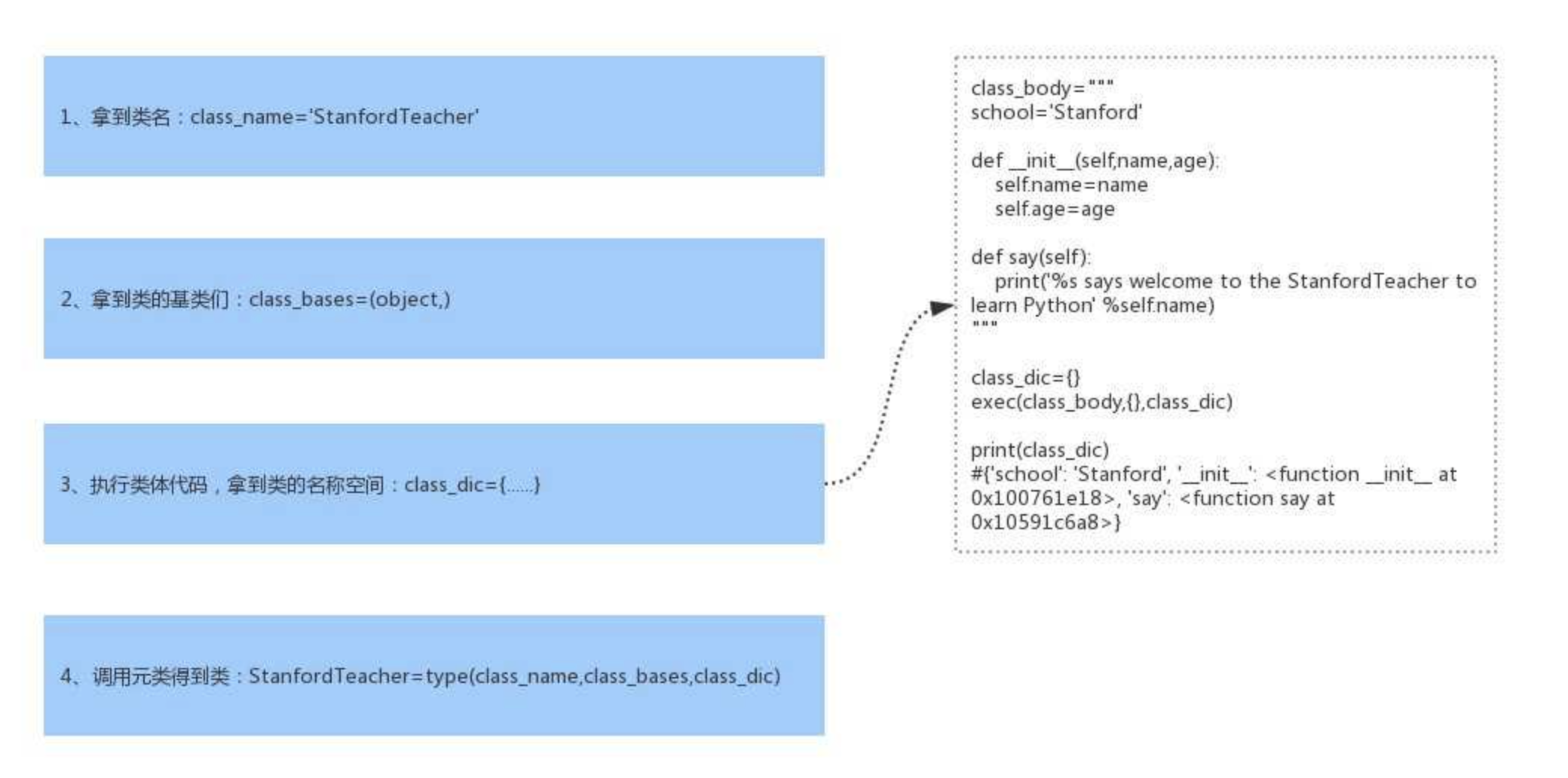
class关键字在帮我们创建类时,必然帮我们调用了元类StanfordTeacher=type(...),那调用type时传入的参数是什么呢?必然是类的关键组成部分,一个类有三大组成部分,分别是
1、类名class_name='StanfordTeacher'
2、基类们class_bases=(object,)
3、类的名称空间class_dic,类的名称空间是执行类体代码而得到的
调用type时会依次传入以上三个参数
综上,class关键字帮我们创建一个类应该细分为以下四个过程
插图:元类原理之类的创建流程
补充:exec的用法
#exec:三个参数
#参数一:包含一系列python代码的字符串
#参数二:全局作用域(字典形式),如果不指定,默认为globals()
#参数三:局部作用域(字典形式),如果不指定,默认为locals()
#可以把exec命令的执行当成是一个函数的执行,会将执行期间产生的名字存放于局部名称空间中
g={
'x':1,
'y':2
}
l={}
exec('''
global x,z
x=100
z=200
m=300
''',g,l)
print(g) #{'x': 100, 'y': 2,'z':200,......}
print(l) #{'m': 300}
三 自定义元类控制类StanfordTeacher的创建
一个类没有声明自己的元类,默认他的元类就是type,除了使用内置元类type,我们也可以通过继承type来自定义元类,然后使用metaclass关键字参数为一个类指定元类
class Mymeta(type): #只有继承了type类才能称之为一个元类,否则就是一个普通的自定义类
pass
# StanfordTeacher=Mymeta('StanfordTeacher',(object),{...})
class StanfordTeacher(object,metaclass=Mymeta):
school='Stanford'
def __init__(self,name,age):
self.name=name
self.age=age
def say(self):
print('%s says welcome to the Stanford to learn Python' %self.name)自定义元类可以控制类的产生过程,类的产生过程其实就是元类的调用过程,即StanfordTeacher=Mymeta('StanfordTeacher',(object),{...}),调用Mymeta会先产生一个空对象StanfordTeacher,然后连同调用Mymeta括号内的参数一同传给Mymeta下的__init__方法,完成初始化,于是我们可以
class Mymeta(type): # 只有继承了type类才能称之为一个元类,否则就是一个普通的自定义类
def __init__(self,class_name,class_bases,class_dic):
# print(self) # <class '__main__.StanfordTeacher'>
# print(class_bases) # (<class 'object'>,)
# print(class_dic) # {'__module__': '__main__', '__qualname__': 'StanfordTeacher', 'school': 'Stanford', '__init__': <function StanfordTeacher.__init__ at 0x102b95ae8>, 'say': <function StanfordTeacher.say at 0x10621c6a8>}
super(Mymeta, self).__init__(class_name, class_bases, class_dic) # 重用父类的功能
if class_name.islower():
raise TypeError('类名%s请修改为驼峰体' %class_name)
if '__doc__' not in class_dic or len(class_dic['__doc__'].strip(' \n')) == 0:
raise TypeError('类中必须有文档注释,并且文档注释不能为空')
# StanfordTeacher=Mymeta('StanfordTeacher',(object),{...})
class StanfordTeacher(object,metaclass=Mymeta):
"""
类StanfordTeacher的文档注释
"""
school='Stanford'
def __init__(self,name,age):
self.name=name
self.age=age
def say(self):
print('%s says welcome to the Stanford to learn Python' %self.name)
四 自定义元类控制类StanfordTeacher的调用
储备知识:__call__
class Foo:
def __call__(self, *args, **kwargs):
print(self)
print(args)
print(kwargs)
obj=Foo()
# 1、要想让obj这个对象变成一个可调用的对象,需要在该对象的类中定义一个方法__call__方法,该方法会在调用对象时自动触发
# 2、调用obj的返回值就是__call__方法的返回值
res=obj(1,2,3,x=1,y=2)由上例得知,调用一个对象,就是触发对象所在类中的__call__方法的执行,如果把StanfordTeacher也当做一个对象,那么在StanfordTeacher这个对象的类中也必然存在一个__call__方法
class Mymeta(type): # 只有继承了type类才能称之为一个元类,否则就是一个普通的自定义类
def __call__(self, *args, **kwargs):
print(self) # <class '__main__.StanfordTeacher'>
print(args) # ('lili', 18)
print(kwargs) #{}
return 123
class StanfordTeacher(object,metaclass=Mymeta):
school='Stanford'
def __init__(self,name,age):
self.name=name
self.age=age
def say(self):
print('%s says welcome to the Stanford to learn Python' %self.name)
# 调用StanfordTeacher就是在调用StanfordTeacher类中的__call__方法
# 然后将StanfordTeacher传给self,溢出的位置参数传给*,溢出的关键字参数传给**
# 调用StanfordTeacher的返回值就是调用__call__的返回值
t1=StanfordTeacher('lili',18)
print(t1) #123默认地,调用t1=StanfordTeacher('lili',18)会做三件事
1、产生一个空对象obj
2、调用__init__方法初始化对象obj
3、返回初始化好的obj
对应着,StanfordTeacher类中的__call__方法也应该做这三件事
class Mymeta(type): #只有继承了type类才能称之为一个元类,否则就是一个普通的自定义类
def __call__(self, *args, **kwargs): #self=<class '__main__.StanfordTeacher'>
#1、调用__new__产生一个空对象obj
obj=self.__new__(self) # 此处的self是类OldoyTeacher,必须传参,代表创建一个StanfordTeacher的对象obj
#2、调用__init__初始化空对象obj
self.__init__(obj,*args,**kwargs)
#3、返回初始化好的对象obj
return obj
class StanfordTeacher(object,metaclass=Mymeta):
school='Stanford'
def __init__(self,name,age):
self.name=name
self.age=age
def say(self):
print('%s says welcome to the Stanford to learn Python' %self.name)
t1=StanfordTeacher('lili',18)
print(t1.__dict__) #{'name': 'lili', 'age': 18}
上例的__call__相当于一个模板,我们可以在该基础上改写__call__的逻辑从而控制调用StanfordTeacher的过程,比如将StanfordTeacher的对象的所有属性都变成私有的
class Mymeta(type): #只有继承了type类才能称之为一个元类,否则就是一个普通的自定义类
def __call__(self, *args, **kwargs): #self=<class '__main__.StanfordTeacher'>
#1、调用__new__产生一个空对象obj
obj=self.__new__(self) # 此处的self是类StanfordTeacher,必须传参,代表创建一个StanfordTeacher的对象obj
#2、调用__init__初始化空对象obj
self.__init__(obj,*args,**kwargs)
# 在初始化之后,obj.__dict__里就有值了
obj.__dict__={'_%s__%s' %(self.__name__,k):v for k,v in obj.__dict__.items()}
#3、返回初始化好的对象obj
return obj
class StanfordTeacher(object,metaclass=Mymeta):
school='Stanford'
def __init__(self,name,age):
self.name=name
self.age=age
def say(self):
print('%s says welcome to the Stanford to learn Python' %self.name)
t1=StanfordTeacher('lili',18)
print(t1.__dict__) #{'_StanfordTeacher__name': 'lili', '_StanfordTeacher__age': 18}
五 再看属性查找
结合python继承的实现原理+元类重新看属性的查找应该是什么样子呢???
在学习完元类后,其实我们用class自定义的类也全都是对象(包括object类本身也是元类type的 一个实例,可以用type(object)查看),我们学习过继承的实现原理,如果把类当成对象去看,将下述继承应该说成是:对象StanfordTeacher继承对象Foo,对象Foo继承对象Bar,对象Bar继承对象object
class Mymeta(type): #只有继承了type类才能称之为一个元类,否则就是一个普通的自定义类
n=444
def __call__(self, *args, **kwargs): #self=<class '__main__.StanfordTeacher'>
obj=self.__new__(self)
self.__init__(obj,*args,**kwargs)
return obj
class Bar(object):
n=333
class Foo(Bar):
n=222
class StanfordTeacher(Foo,metaclass=Mymeta):
n=111
school='Stanford'
def __init__(self,name,age):
self.name=name
self.age=age
def say(self):
print('%s says welcome to the Stanford to learn Python' %self.name)
print(StanfordTeacher.n) #自下而上依次注释各个类中的n=xxx,然后重新运行程序,发现n的查找顺序为StanfordTeacher->Foo->Bar->object->Mymeta->type于是属性查找应该分成两层,一层是对象层(基于c3算法的MRO)的查找,另外一个层则是类层(即元类层)的查找
插图:01元类-继承背景下的属性查找
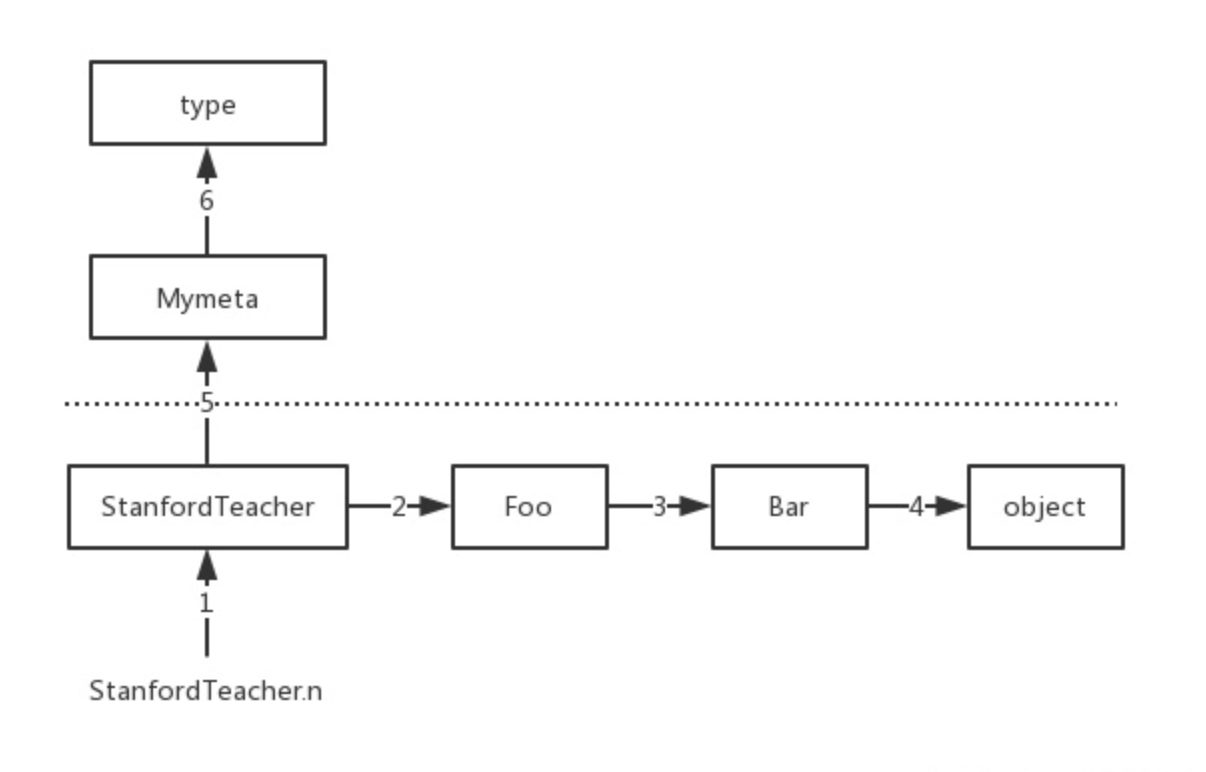
查找顺序:
1、先对象层:StanfordTeacher->Foo->Bar->object
2、然后元类层:Mymeta->type
依据上述总结,我们来分析下元类Mymeta中__call__里的self.__new__的查找
class Mymeta(type):
n=444
def __call__(self, *args, **kwargs): #self=<class '__main__.StanfordTeacher'>
obj=self.__new__(self)
print(self.__new__ is object.__new__) #True
class Bar(object):
n=333
# def __new__(cls, *args, **kwargs):
# print('Bar.__new__')
class Foo(Bar):
n=222
# def __new__(cls, *args, **kwargs):
# print('Foo.__new__')
class StanfordTeacher(Foo,metaclass=Mymeta):
n=111
school='Stanford'
def __init__(self,name,age):
self.name=name
self.age=age
def say(self):
print('%s says welcome to the Stanford to learn Python' %self.name)
# def __new__(cls, *args, **kwargs):
# print('StanfordTeacher.__new__')
StanfordTeacher('lili',18) #触发StanfordTeacher的类中的__call__方法的执行,进而执行self.__new__开始查找总结,Mymeta下的__call__里的self.__new__在StanfordTeacher、Foo、Bar里都没有找到__new__的情况下,会去找object里的__new__,而object下默认就有一个__new__,所以即便是之前的类均未实现__new__,也一定会在object中找到一个,根本不会、也根本没必要再去找元类Mymeta->type中查找__new__
我们在元类的__call__中也可以用object.__new__(self)去造对象
插图:02元类-继承背景下的属性查找
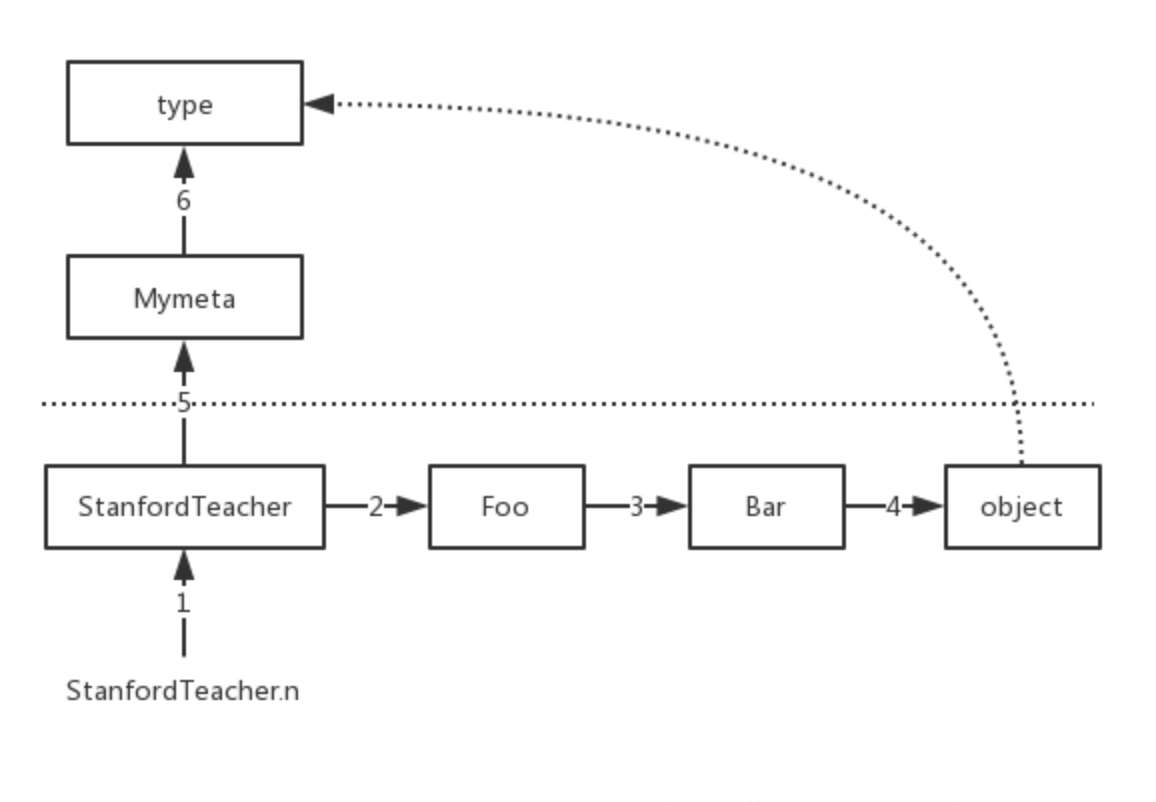
但我们还是推荐在__call__中使用self.__new__(self)去创造空对象,因为这种方式会检索三个类StanfordTeacher->Foo->Bar,而object.__new__则是直接跨过了他们三个
最后说明一点
class Mymeta(type): #只有继承了type类才能称之为一个元类,否则就是一个普通的自定义类
n=444
def __new__(cls, *args, **kwargs):
obj=type.__new__(cls,*args,**kwargs) # 必须按照这种传值方式
print(obj.__dict__)
# return obj # 只有在返回值是type的对象时,才会触发下面的__init__
return 123
def __init__(self,class_name,class_bases,class_dic):
print('run。。。')
class StanfordTeacher(object,metaclass=Mymeta): #StanfordTeacher=Mymeta('StanfordTeacher',(object),{...})
n=111
school='Stanford'
def __init__(self,name,age):
self.name=name
self.age=age
def say(self):
print('%s says welcome to the Stanford to learn Python' %self.name)
print(type(Mymeta)) #<class 'type'>
# 产生类StanfordTeacher的过程就是在调用Mymeta,而Mymeta也是type类的一个对象,那么Mymeta之所以可以调用,一定是在元类type中有一个__call__方法
# 该方法中同样需要做至少三件事:
# class type:
# def __call__(self, *args, **kwargs): #self=<class '__main__.Mymeta'>
# obj=self.__new__(self,*args,**kwargs) # 产生Mymeta的一个对象
# self.__init__(obj,*args,**kwargs)
# return obj异常处理
一 什么是异常
异常是程序发生错误的信号。程序一旦出现错误,便会产生一个异常,若程序中没有处理它,就会抛出该异常,程序的运行也随之终止。在Python中,错误触发的异常如下
插图:异常处理

而错误分成两种,一种是语法上的错误SyntaxError,这种错误应该在程序运行前就修改正确
>>> if
File "<stdin>", line 1
if
^
SyntaxError: invalid syntax另一类就是逻辑错误,常见的逻辑错误如
# TypeError:数字类型无法与字符串类型相加
1+’2’
# ValueError:当字符串包含有非数字的值时,无法转成int类型
num=input(">>: ") #输入hello
int(num)
# NameError:引用了一个不存在的名字x
x
# IndexError:索引超出列表的限制
l=['egon','aa']
l[3]
# KeyError:引用了一个不存在的key
dic={'name':'egon'}
dic['age']
# AttributeError:引用的属性不存在
class Foo:
pass
Foo.x
# ZeroDivisionError:除数不能为0
1/0二 异常处理
为了保证程序的容错性与可靠性,即在遇到错误时有相应的处理机制不会任由程序崩溃掉,我们需要对异常进行处理,处理的基本形式为
try:
被检测的代码块
except 异常类型:
检测到异常,就执行这个位置的逻辑举例:
try:
print('start...')
print(x) # 引用了一个不存在的名字,触发异常NameError
print('end...')
except NameError as e: # as语法将异常类型的值赋值给变量e,这样我们通过打印e便可以知道错误的原因
print('异常值为:%s' %e)
print('run other code...')
#执行结果为
start...
异常值为:name 'x' is not defined
run other code...本来程序一旦出现异常就整体结束掉了,有了异常处理以后,在被检测的代码块出现异常时,被检测的代码块中异常发生位置之后的代码将不会执行,取而代之的是执行匹配异常的except子代码块,其余代码均正常运行。
当被检测的代码块中有可能触发不同类型的异常时,针对不同类型的异常:
如果我们想分别用不同的逻辑处理,需要用到多分支的except(类似于多分支的elif,从上到下依次匹配,匹配成功一次便不再匹配其他)
try:
被检测的代码块
except NameError:
触发NameError时对应的处理逻辑
except IndexError:
触发IndexError时对应的处理逻辑
except KeyError:
触发KeyError时对应的处理逻辑举例:
def convert_int(obj):
try:
res=int(obj)
except ValueError as e:
print('ValueError: %s' %e)
res=None
except TypeError as e:
print('TypeError: %s' %e)
res=None
return res
convert_int('egon') # ValueError: invalid literal for int() with base 10: 'egon'
convert_int({'n':1}) # TypeError: int() argument must be a string, a bytes-like object or a number, not 'dict'如果我们想多种类型的异常统一用一种逻辑处理,可以将多个异常放到一个元组内,用一个except匹配
try:
被检测的代码块
except (NameError,IndexError,TypeError):
触发NameError或IndexError或TypeError时对应的处理逻辑举例:
def convert_int(obj):
try:
res=int(obj)
except (ValueError,TypeError):
print('argument must be number or numeric string')
res=None
return res
convert_int('egon') # argument must be number or numeric string
convert_int({'n':1}) # argument must be number or numeric string如果我们想捕获所有异常并用一种逻辑处理,Python提供了一个万能异常类型Exception
try:
被检测的代码块
except NameError:
触发NameError时对应的处理逻辑
except IndexError:
触发IndexError时对应的处理逻辑
except Exception:
其他类型的异常统一用此处的逻辑处理在多分支except之后还可以跟一个else(else必须跟在except之后,不能单独存在),只有在被检测的代码块没有触发任何异常的情况下才会执行else的子代码块
try:
被检测的代码块
except 异常类型1:
pass
except 异常类型2:
pass
......
else:
没有异常发生时执行的代码块此外try还可以与finally连用,从语法上讲finally必须放到else之后,但可以使用try-except-finally的形式,也可以直接使用try-finally的形式。无论被检测的代码块是否触发异常,都会执行finally的子代码块,因此通常在finally的子代码块做一些回收资源的操作,比如关闭打开的文件、关闭数据库连接等
try:
被检测的代码块
except 异常类型1:
pass
except 异常类型2:
pass
......
else:
没有异常发生时执行的代码块
finally:
无论有无异常发生都会执行的代码块举例:
f=None
try:
f=open(‘db.txt’,'r',encoding='utf-8')
s=f.read().strip()
int(s) # 若字符串s中包含非数字时则会触发异常ValueError
# f.close() # 若上面的代码触发异常,则根本不可能执行到此处的代码,应该将关闭文件的操作放到finally中
finally:
if f: # 文件存在则f的值不为None
f.close()在不符合Python解释器的语法或逻辑规则时,是由Python解释器主动触发的各种类型的异常,而对于违反程序员自定制的各类规则,则需要由程序员自己来明确地触发异常,这就用到了raise语句,raise后必须是一个异常的类或者是异常的实例
class Student:
def __init__(self,name,age):
if not isinstance(name,str):
raise TypeError('name must be str')
if not isinstance(age,int):
raise TypeError('age must be int')
self.name=name
self.age=age
stu1=Student(4573,18) # TypeError: name must be str
stu2=Student('egon','18') # TypeError: age must be int
在内置异常不够用的情况下,我们可以通过继承内置的异常类来自定义异常类
class PoolEmptyError(Exception): # 可以通过继承Exception来定义一个全新的异常
def __init__(self,value='The proxy source is exhausted'): # 可以定制初始化方法
super(PoolEmptyError,self).__init__()
self.value=value
def __str__(self): # 可以定义该方法用来定制触发异常时打印异常值的格式
return '< %s >' %self.value
class NetworkIOError(IOError): # 也可以在特定异常的基础上扩展一个相关的异常
pass
raise PoolEmptyError # __main__.PoolEmptyError: < The proxy source is exhausted >
raise NetworkIOError('连接被拒绝') # __main__.NetworkIOError: 连接被拒绝最后,Python还提供了一个断言语句assert expression,断定表达式expression成立,否则触发异常AssertionError,与raise-if-not的语义相同,如下
age='18'
# 若表达式isinstance(age,int)返回值为False则触发异常AssertionError
assert isinstance(age,int)
# 等同于
if not isinstance(age,int):
raise AssertionError
三 何时使用异常处理
在了解了异常处理机制后,本着提高程序容错性和可靠性的目的,读者可能会错误地认为应该尽可能多地为程序加上try...except...,这其是在过度消费程序的可读性,因为try...except本来就是你附加给程序的一种额外的逻辑,与你的主要工作是没有多大关系的。
如果错误发生的条件是“可预知的”,我们应该用if来进行”预防”,如下
age=input('input your age>>: ').strip()
if age.isdigit(): # 可预知只有满足字符串age是数字的条件,int(age)才不会触发异常,
age=int(age)
else:
print('You must enter the number')如果错误发生的条件“不可预知”,即异常一定会触发,那么我们才应该使用try...except语句来处理。例如我们编写一个下载网页内容的功能,网络发生延迟之类的异常是很正常的事,而我们根本无法预知在满足什么条件的情况下才会出现延迟,因而只能用异常处理机制了
import requests
from requests.exceptions import ConnectTimeout # 导入requests模块内自定义的异常
def get(url):
try:
response=requests.get(url,timeout=3)#超过3秒未下载成功则触发ConnectTimeout异常
res=response.text
except ConnectTimeout:
print('连接请求超时')
res=None
except Exception:
print('网络出现其他异常')
res=None
return res
get('https://www.python.org')断言机制:
# assert 条件 # 条件必须是成立的
l = ['kevin', 'jason', 'tank1']
assert 'tank' in l
print(123)
# 有什么用:单元测试(断言) 我自己写代码去测试我的写代码的bug UnitTest自定义异常:
class MyException(BaseException):
def __init__(self, msg):
self.msg = msg
def __str__(self):
return self.msg
def reponse(self):
pass
raise MyException('用户名必须填写')补充:Python Mixins机制
一个子类可以同时继承多个父类,这样的设计常被人诟病,一来它有可能导致可恶的菱形问题,二来在人的世界观里继承应该是个”is-a”关系。 比如轿车类之所以可以继承交通工具类,是因为基于人的世界观,我们可以说:轿车是一个(“is-a”)交通工具,而在人的世界观里,一个物品不可能是多种不同的东西,因此多重继承在人的世界观里是说不通的,它仅仅只是代码层面的逻辑。不过有没有这种情况,一个类的确是需要继承多个类呢?
答案是有,我们还是拿交通工具来举例子:
民航飞机、直升飞机、轿车都是一个(is-a)交通工具,前两者都有一个功能是飞行fly,但是轿车没有,所以如下所示我们把飞行功能放到交通工具这个父类中是不合理的
class Vehicle: # 交通工具
def fly(self):
'''
飞行功能相应的代码
'''
print("I am flying")
class CivilAircraft(Vehicle): # 民航飞机
pass
class Helicopter(Vehicle): # 直升飞机
pass
class Car(Vehicle): # 汽车并不会飞,但按照上述继承关系,汽车也能飞了
pass但是如果民航飞机和直升机都各自写自己的飞行fly方法,又违背了代码尽可能重用的原则(如果以后飞行工具越来越多,那会重复代码将会越来越多)。
怎么办???为了尽可能地重用代码,那就只好在定义出一个飞行器的类,然后让民航飞机和直升飞机同时继承交通工具以及飞行器两个父类,这样就出现了多重继承。这时又违背了继承必须是”is-a”关系。这个难题该怎么解决?
不同的语言给出了不同的方法,让我们先来了解Java的处理方法。Java提供了接口interface功能,来实现多重继承:
// 抽象基类:交通工具类
public abstract class Vehicle {
}
// 接口:飞行器
public interface Flyable {
public void fly();
}
// 类:实现了飞行器接口的类,在该类中实现具体的fly方法,这样下面民航飞机与直升飞机在实现fly时直接重用即可
public class FlyableImpl implements Flyable {
public void fly() {
System.out.println("I am flying");
}
}
// 民航飞机,继承自交通工具类,并实现了飞行器接口
public class CivilAircraft extends Vehicle implements Flyable {
private Flyable flyable;
public CivilAircraft() {
flyable = new FlyableImpl();
}
public void fly() {
flyable.fly();
}
}
// 直升飞机,继承自交通工具类,并实现了飞行器接口
public class Helicopter extends Vehicle implements Flyable {
private Flyable flyable;
public Helicopter() {
flyable = new FlyableImpl();
}
public void fly() {
flyable.fly();
}
}
// 汽车,继承自交通工具类,
public class Car extends Vehicle {
}现在我们的飞机同时具有了交通工具及飞行器两种属性,而且我们不需要重写飞行器中的飞行方法,同时我们没有破坏单一继承的原则。飞机就是一种交通工具,可飞行的能力是飞机的属性,通过继承接口来获取。
回到主题,Python语言可没有接口功能,但Python提供了Mixins机制,简单来说Mixins机制指的是子类混合(mixin)不同类的功能,而这些类采用统一的命名规范(例如Mixin后缀),以此标识这些类只是用来混合功能的,并不是用来标识子类的从属"is-a"关系的,所以Mixins机制本质仍是多继承,但同样遵守”is-a”关系,如下
class Vehicle: # 交通工具
pass
class FlyableMixin:
def fly(self):
'''
飞行功能相应的代码
'''
print("I am flying")
class CivilAircraft(FlyableMixin, Vehicle): # 民航飞机
pass
class Helicopter(FlyableMixin, Vehicle): # 直升飞机
pass
class Car(Vehicle): # 汽车
pass
# ps: 采用某种规范(如命名规范)来解决具体的问题是python惯用的套路可以看到,上面的CivilAircraft、Helicopter类实现了多继承,不过它继承的第一个类我们起名为FlyableMixin,而不是Flyable,这个并不影响功能,但是会告诉后来读代码的人,这个类是一个Mixin类,表示混入(mix-in),这种命名方式就是用来明确地告诉别人(python语言惯用的手法),这个类是作为功能添加到子类中,而不是作为父类,它的作用同Java中的接口。所以从含义上理解,CivilAircraft、Helicopter类都只是一个Vehicle,而不是一个飞行器。
使用Mixin类实现多重继承要非常小心:
- 首先它必须表示某一种功能,而不是某个物品,python 对于mixin类的命名方式一般以 Mixin, able, ible 为后缀
- 其次它必须责任单一,如果有多个功能,那就写多个Mixin类,一个类可以继承多个Mixin,为了保证遵循继承的“is-a”原则,只能继承一个标识其归属含义的父类
- 然后,它不依赖于子类的实现
- 最后,子类即便没有继承这个Mixin类,也照样可以工作,就是缺少了某个功能。(比如飞机照样可以载客,就是不能飞了)
Mixins是从多个类中重用代码的好方法,但是需要付出相应的代价,我们定义的Minx类越多,子类的代码可读性就会越差,并且更恶心的是,在继承的层级变多时,代码阅读者在定位某一个方法到底在何处调用时会晕头转向,如下
class Displayer:
def display(self, message):
print(message)
class LoggerMixin:
def log(self, message, filename='logfile.txt'):
with open(filename, 'a') as fh:
fh.write(message)
def display(self, message):
super().display(message) # super的用法请参考下一小节
self.log(message)
class MySubClass(LoggerMixin, Displayer):
def log(self, message):
super().log(message, filename='subclasslog.txt')
obj = MySubClass()
obj.display("This string will be shown and logged in subclasslog.txt")
# 属性查找的发起者是obj,所以会参照类MySubClass的MRO来检索属性
#[<class '__main__.MySubClass'>, <class '__main__.LoggerMixin'>, <class '__main__.Displayer'>, <class 'object'>]
# 1、首先会去对象obj的类MySubClass找方法display,没有则去类LoggerMixin中找,找到开始执行代码
# 2、执行LoggerMixin的第一行代码:执行super().display(message),参照MySubClass.mro(),super会去下一个类即类Displayer中找,找到display,开始执行代码,打印消息"This string will be shown and logged in subclasslog.txt"
# 3、执行LoggerMixin的第二行代码:self.log(message),self是对象obj,即obj.log(message),属性查找的发起者为obj,所以会按照其类MySubClass.mro(),即MySubClass->LoggerMixin->Displayer->object的顺序查找,在MySubClass中找到方法log,开始执行super().log(message, filename='subclasslog.txt'),super会按照MySubClass.mro()查找下一个类,在类LoggerMixin中找到log方法开始执行,最终将日志写入文件subclasslog.txt















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









