






目录
一、前期准备
1.1环境配置
在本篇文章中所用到的编译环境是Python,编辑器是VSCode,以下相关环境配置将基于此编译器进行。
1.1.1安装解释器
首先我们要确保自己的电脑上有Python的解释器,如果没有Python的解释器的话我们就得需要去下载一个Python的的解释器,在本篇文章中所运行的代码程序都是在Anaconda下的Python环境下运行的。
Anaconda的官网链接:https://www.anaconda.com/
进入Anaconda官网之后你就会看到以下界面:

点击进去之后会看到:
在这里直接跳过就可以了

随后点击这里选择windows系统下载就可以了,如果用的不是windows系统那么就选择你对应的电脑系统下载

下载好之后点开文件进行安装即可。
进入安装的界面按照如下所示进行安装



选择自己的安装路径

点击Install等待安装完成即可

1.1.4配置环境变量
安装完Anaconda后对其进行环境配置,按照以下步骤进行配置
1.打开设置在系统中找到高级系统设置这个选项

随后点击环境变量

进入环境变量之后找到系统变量中的Path,点击进去

进入Path之后通过新建相关的变量即可

1.1.3编辑器的环境配置
对于编辑器的相关环境配置,本篇文章运行的主程序都是在VSCode这个编辑器下进行运行的。
因此我们首先要下载一个VSCode的编辑器
官网链接:https://code.visualstudio.com/
进入官网你就可以看到如下界面:

将VSCode下载后点击文件进行安装,安装过程中就一直点击下一步即可。
随后打开VSCode程序下载相应的插件。


如果想要安装中文插件的话只需要在框内输入chinese进行安装并重启后即可
安装完插件之后打开一个项目或者创建一个文件就可以选择我们之前所安装的编译器,在VSCode会自动的去列举你电脑里面所有的编译器,随后你选择就可以了



到此,相关的环境配置已经完成了。如果还有其他不懂的可以在CSDN上去搜索相关的问题解决。
1.1.4相关依赖下载
在项目开始之前,我们还需要下载我们所需要的相关依赖:
在这里我列举了一些需要安装的主要的库
1.Pandas version: 2.1.3
2.NumPy version: 1.24.3
3.SciPy version: 1.10.1
1.1.4项目下载
本篇文章所用到的项目地址如下:
https://gitee.com/simonyansenzhao/recommenders
将项目下载到自己的电脑中,也可以直接将其克隆到自己的项目里,在这里是直接下载到自己的电脑中

二、SAR原理
SAR(合成孔径雷达)算法的基本原理是利用雷达波进行地表或者目标的成像。SAR 系统通常安装在飞机或卫星上,通过发射微波并接收其反射波来获得地表的图像。这里是SAR算法的一些关键步骤和原理:
-
微波发射与接收:SAR系统发射的雷达波在遇到地表或者其他目标时会产生反射。这些反射波被SAR系统接收并记录下来。
-
距离测量:通过记录雷达波发射和接收之间的时间差,SAR系统可以计算出雷达波传播的距离,从而得到物体的位置信息。
-
合成孔径:在SAR中,随着载体(如卫星或飞机)的移动,雷达天线会在一定的路径上连续发射和接收雷达波。这个连续的过程产生的效果类似于一个很大的天线,即“合成孔径”,这有助于提高成像的分辨率。
-
相位信息的利用:SAR不仅记录反射波的强度,还记录波的相位,这是SAR技术中非常关键的一点。通过分析不同位置的雷达波的相位差异,可以提取更多关于地形的详细信息。
-
成像处理:收集到的原始雷达数据(称为“回波”)需要通过复杂的信号处理算法转换成图像。这通常涉及到信号的匹配滤波、距离-多普勒算法等技术,以构建高质量的二维或三维图像。
-
干涉测量:当使用两个或更多的SAR图像,且它们是从相近的位置但在不同时间获取的,可以通过干涉SAR(InSAR)技术来测量地表的微小变化,如地壳运动、地面沉降等。
SAR技术因其能够在夜间或云层覆盖条件下工作的能力而被广泛应用于地理测绘、环境监测、军事侦察等领域。
- SAR算法:
下图展示了SAR的高级架构。在非常高的级别上,创建了两个中间矩阵,并用于生成一组推荐分数:
一个物品相似度矩阵S估计物品与物品之间的关系。
亲和矩阵A估计用户-物品关系。
然后通过计算矩阵乘法A × s来创建推荐分数。
“时间衰减”和“删除已看到的项目”)在下面详细描述。

三、主程序代码的解析
3.1导入库和设置
import sys
import os
import pandas as pd
import numpy as np
import math
import scipy.sparse as sparse
import itertools
from movielens import load_movielens_data
from python_splitters import python_stratified_split
from sar_singlenode import SARSingleNode
print("System version: {}".format(sys.version))
1.导入标准库:
- sys 和 os:用于系统级别的操作,例如文件路径操作。
- pandas:用于数据处理和分析,特别是表格数据。
- numpy:用于科学计算,特别是数组和矩阵操作。
- math:提供基本的数学函数。
- scipy.sparse:用于处理稀疏矩阵。
- itertools:提供高效的迭代器函数。
2.导入自定义模块:
- load_movielens_data:从 movielens 模块中导入,用于加载 Movielens 数据集。
- python_stratified_split:从 python_splitters 模块中导入,用于分割数据集。
- SARSingleNode:从 sar_singlenode 模块中导入,用于创建和训练 SAR 模型。
3.打印系统版本: 确保我们知道当前运行的 Python 版本,确保兼容性。

3.2数据加载和预处理
# 加载数据集
data = load_movielens_data(size='1m')
print("Data loaded.")
# 数据集分割
train, test = python_stratified_split(data, ratio=0.75, seed=42)
print("Data split done.")
数据集介绍
在这个项目中使用了 Movielens 数据集。以下是数据集的主要内容和相关信息:
Movielens 数据集
- 数据集大小:
- 100k:包含 100,000 条评分记录。
- 1m:包含 1,000,000 条评分记录。
- 数据内容:
- 评分数据 (ratings.dat):
- userId: 用户 ID。
- movieId: 电影 ID。
- rating: 用户对电影的评分。
- timestamp: 评分时间戳。
- 评分数据 (ratings.dat):
- 电影信息 (movies.dat):
- movieId: 电影 ID。
- title: 电影标题。
- genres: 电影类型。
代码详细解释
1加载数据集
data = load_movielens_data(size='1m')
print("Data loaded.")
- load_movielens_data(size=‘1m’): 调用自定义函数 load_movielens_data 加载
Movielens 数据集。参数 size=‘1m’ 指定使用包含 1,000,000 条记录的数据集。加载后的数据存储在 data
变量中。 - print(“Data loaded.”): 打印确认信息,表示数据加载完成。
2.数据集分割
train, test = python_stratified_split(data, ratio=0.75, seed=42)
print("Data split done.")
- python_stratified_split(data, ratio=0.75, seed=42): 调用自定义函数python_stratified_split将数据集按 75% 的比例分割为训练集和测试集。参数 ratio=0.75指定分割比例,seed=42 用于设置随机种子,确保分割结果可重复。
- train 和 test:分割后的训练集和测试集数据分别存储在 train 和 test 变量中。
- print(“Data split done.”):打印确认信息,表示数据集分割完成。
3.3初始化和训练 SAR 模型
sar = SARSingleNode(
remove_seen=True,
similarity_type="jaccard",
time_decay_coefficient=30,
time_now=None,
timedecay_formula=True
)
sar.fit(train)
print("Model training done.")
参数设置和解释:
- remove_seen=True: 是否移除已经看过的项目。设为 True 表示移除。
- similarity_type=“jaccard”: 相似度类型。此处使用 Jaccard 相似度。
- time_decay_coefficient=30: 时间衰减系数,设置时间衰减公式中的参数T。
- time_now=None: 当前时间,默认为 None。
- timedecay_formula=True: 是否使用时间衰减公式,设为 True 表示使用。
时间衰减公式:
在 SAR 模型中,用于计算用户与项目的亲和度的时间衰减公式为:
a
i
j
=
∑
k
w
k
(
1
2
)
t
0
−
t
k
T
a_{ij} = \sum_k w_k \left(\frac{1}{2}\right)^{\frac{t_0 - t_k}{T}}
aij=k∑wk(21)Tt0−tk
其中:
- ( w_k ): 事件的权重。
- ( t_0 ): 当前时间。
- ( t_k ): 事件发生时间。
- ( T ): 时间衰减系数。
训练模型:
sar.fit(train)
print("Model training done.")
- sar.fit(train): 调用 SAR 模型的 fit 方法,用训练集数据训练模型。
- print(“Model training done.”): 打印确认信息,表示模型训练完成。
3.4模型评估
eval_map = sar.map(test, train)
eval_ndcg = sar.ndcg(test, train)
eval_precision = sar.precision(test, train)
eval_recall = sar.recall(test, train)
print(f"MAP: {eval_map:.4f}")
print(f"NDCG: {eval_ndcg:.4f}")
print(f"Precision: {eval_precision:.4f}")
print(f"Recall: {eval_recall:.4f}")
计算评估指标:
eval_map = sar.map(test, train)
eval_ndcg = sar.ndcg(test, train)
eval_precision = sar.precision(test, train)
eval_recall = sar.recall(test, train)
- sar.map(test, train):计算模型在测试集上的平均精度(MAP)。
- sar.ndcg(test, train):计算模型在测试集上的归一化折现累积增益(NDCG)。
- sar.precision(test, train):计算模型在测试集上的精度(Precision)。
- sar.recall(test, train):计算模型在测试集上的召回率(Recall)。
打印评估结果:
print(f"MAP: {eval_map:.4f}")
print(f"NDCG: {eval_ndcg:.4f}")
print(f"Precision: {eval_precision:.4f}")
print(f"Recall: {eval_recall:.4f}")
评估指标和解释:
- MAP(Mean Average Precision):平均精度。
- NDCG(Normalized Discounted Cumulative Gain):归一化折现累积增益。
- Precision:精度。
- Recall:召回率。
全部代码以及运行结果
import sys
import logging
import scipy
import numpy as np
import pandas as pd
sys.path.append('C:\\recommenders')
from recommenders.datasets import movielens
from recommenders.datasets.python_splitters import python_stratified_split
from recommenders.evaluation.python_evaluation import map_at_k, ndcg_at_k, precision_at_k, recall_at_k
from recommenders.models.sar import SAR
from recommenders.utils.notebook_utils import store_metadata
print(f"System version: {sys.version}")
print(f"Pandas version: {pd.__version__}")
print(f"NumPy version: {np.__version__}")
print(f"SciPy version: {scipy.__version__}")

# Top k items to recommend
TOP_K = 10
# Select MovieLens data size: 100k, 1m, 10m, or 20m
MOVIELENS_DATA_SIZE = "100k"
# set log level to INFO
logging.basicConfig(
level=logging.DEBUG,
format="%(asctime)s %(levelname)-8s %(message)s",
datefmt="%Y-%m-%d %H:%M:%S",
)
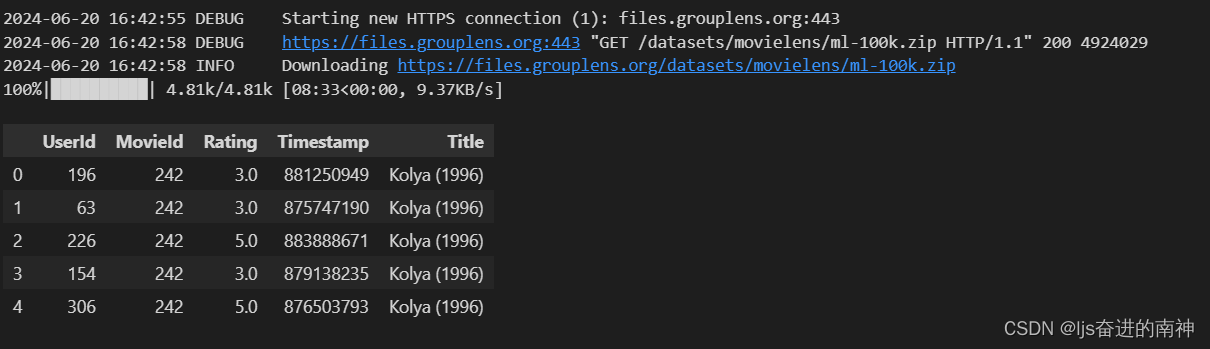
data = movielens.load_pandas_df(
size=MOVIELENS_DATA_SIZE,
header=["UserId", "MovieId", "Rating", "Timestamp"],
title_col="Title",
)
# Convert the float precision to 32-bit in order to reduce memory consumption
data["Rating"] = data["Rating"].astype(np.float32)
data.head()
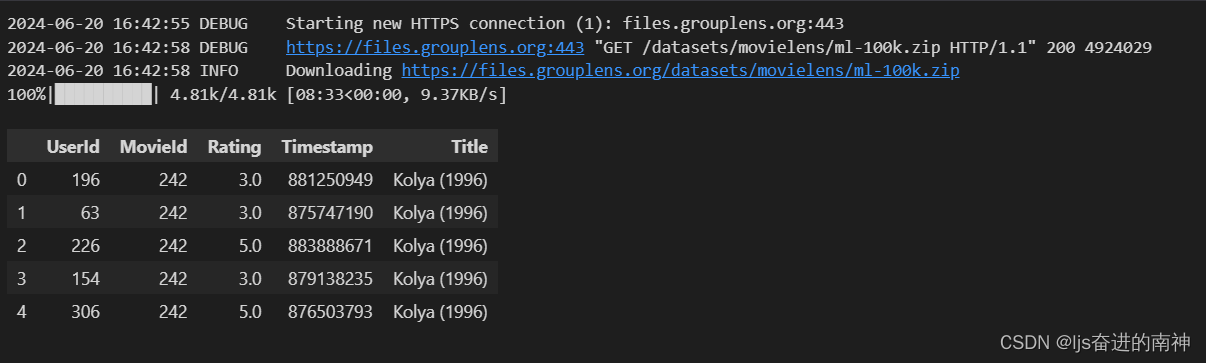
header = {
"col_user": "UserId",
"col_item": "MovieId",
"col_rating": "Rating",
"col_timestamp": "Timestamp",
"col_prediction": "Prediction",
}
train, test = python_stratified_split(
data, ratio=0.75, col_user=header["col_user"], col_item=header["col_item"], seed=42
)
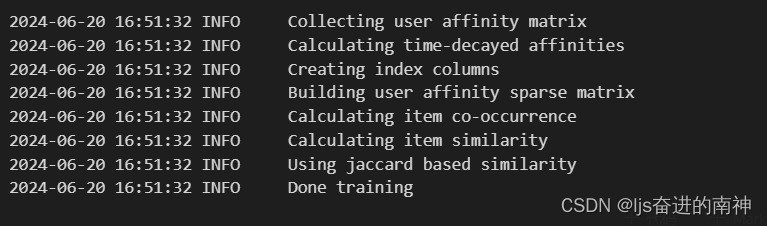
model = SAR(
similarity_type="jaccard",
time_decay_coefficient=30,
time_now=None,
timedecay_formula=True,
**header
)
model.fit(train)
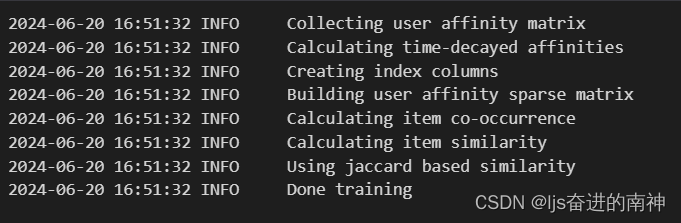
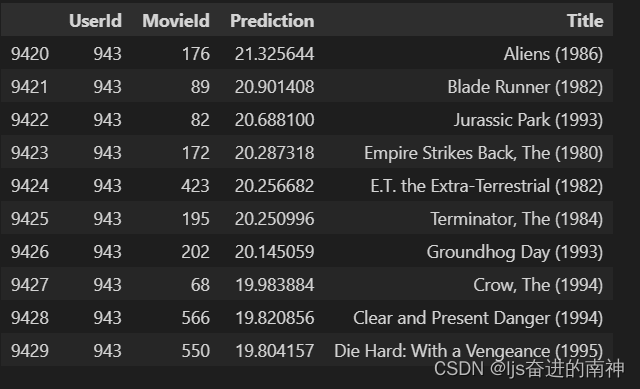
top_k = model.recommend_k_items(test, top_k=TOP_K, remove_seen=True)

top_k_with_titles = top_k.join(
data[["MovieId", "Title"]].drop_duplicates().set_index("MovieId"),
on="MovieId",
how="inner",
).sort_values(by=["UserId", "Prediction"], ascending=False)
top_k_with_titles.head(10)
# all ranking metrics have the same arguments
args = [test, top_k]
kwargs = dict(
col_user="UserId",
col_item="MovieId",
col_rating="Rating",
col_prediction="Prediction",
relevancy_method="top_k",
k=TOP_K,
)
eval_map = map_at_k(*args, **kwargs)
eval_ndcg = ndcg_at_k(*args, **kwargs)
eval_precision = precision_at_k(*args, **kwargs)
eval_recall = recall_at_k(*args, **kwargs)
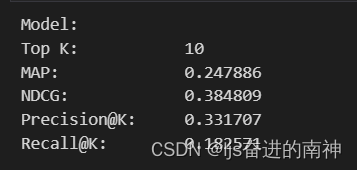
print(f"Model:",
f"Top K:\t\t {TOP_K}",
f"MAP:\t\t {eval_map:f}",
f"NDCG:\t\t {eval_ndcg:f}",
f"Precision@K:\t {eval_precision:f}",
f"Recall@K:\t {eval_recall:f}", sep='\n')
# Record results for tests - ignore this cell
store_metadata("map", eval_map)
store_metadata("ndcg", eval_ndcg)
store_metadata("precision", eval_precision)
store_metadata("recall", eval_recall)
四、主程序其他相关代码解析
sar_singlenode.py 文件详细解析
以下是 sar_singlenode.py 文件中SARSingleNode 类的详细解释:
类定义和初始化
class SARSingleNode:
def __init__(
self,
remove_seen=True,
similarity_type="jaccard",
time_decay_coefficient=30,
time_now=None,
timedecay_formula=True,
threshold=1,
normalize=True,
**kwargs
):
self.remove_seen = remove_seen
available_similarity_types = [
"jaccard",
"lift",
"mutual_information",
]
if similarity_type not in available_similarity_types:
raise ValueError(
'Similarity type must be one of ["'
+ '" | "'.join(available_similarity_types)
+ '"]'
)
self.similarity_type = similarity_type
self.time_decay_half_life = (
time_decay_coefficient * 24 * 60 * 60
) # convert to seconds
self.time_decay_flag = timedecay_formula
self.time_now = time_now
self.threshold = threshold
self.user_affinity = None
self.item_similarity = None
self.item_frequencies = None
self.user_frequencies = None
# threshold - items below this number get set to zero in co-occurrence counts
if self.threshold <= 0:
raise ValueError("Threshold cannot be < 1")
# set flag to capture unity-rating user-affinity matrix for scaling scores
self.normalize = normalize
self.col_unity_rating = "_unity_rating"
self.unity_user_affinity = None
# column for mapping user / item ids to internal indices
self.col_item_id = "_indexed_items"
self.col_user_id = "_indexed_users"
# obtain all the users and items from both training and test data
self.n_users = None
self.n_items = None
# The min and max of the rating scale, obtained from the training data.
self.rating_min = None
self.rating_max = None
# mapping for item to matrix element
self.user2index = None
self.item2index = None
# the opposite of the above maps - map array index to actual string ID
self.index2item = None
self.index2user = None
1.初始化参数:
- remove_seen: 是否移除已经看过的项目。设为True 表示移除。
- similarity_type: 相似度类型,可选值[“jaccard”, “lift”, “mutual_information”]。
- time_decay_coefficient: 时间衰减系数,默认值为 30。
- time_now: 当前时间,默认值为 None。
- timedecay_formula: 是否使用时间衰减公式,默认值为 True。
- threshold: 阈值,默认值为 1,不能小于 1。
- normalize: 是否归一化评分,默认值为 True。
2.内部变量:
- self.time_decay_half_life: 时间衰减半衰期,转换为秒。
- self.user_affinity,self.item_similarity,self.item_frequencies, self.user_frequencies: 初始化为空。
- self.col_unity_rating: 统一评分列。
- self.col_item_id, self.col_user_id: 内部索引列。
- self.n_users, self.n_items: 用户和项目数量。
- self.rating_min, self.rating_max: 评分范围。
- self.user2index, self.item2index: 用户和项目的索引映射。
- self.index2item, self.index2user: 索引到实际 ID 的映射。
方法定义
compute_affinity_matrix 方法
def compute_affinity_matrix(self, df, rating_col):
"""Affinity matrix.
The user-affinity matrix can be constructed by treating the users and items as
indices in a sparse matrix, and the events as the data. Here the affinity
is simply the count of how many times a user has interacted with an item.
"""
user_indices = df[self.col_user].map(self.user2index).values
item_indices = df[self.col_item].map(self.item2index).values
ratings = df[rating_col].values
self.user_affinity = sparse.csr_matrix(
(ratings, (user_indices, item_indices)),
shape=(self.n_users, self.n_items),
)
return self.user_affinity
- 功能:构建用户-项目亲和矩阵。
映射用户和项目到内部索引:
user_indices = df[self.col_user].map(self.user2index).values
item_indices = df[self.col_item].map(self.item2index).values
- df[self.col_user].map(self.user2index).values:将用户 ID 映射到内部索引。
- df[self.col_item].map(self.item2index).values:将项目 ID 映射到内部索引。
创建稀疏矩阵:
ratings = df[rating_col].values
self.user_affinity = sparse.csr_matrix(
(ratings, (user_indices, item_indices)),
shape=(self.n_users, self.n_items),
)
- ratings = df[rating_col].values:获取评分列的值。
- sparse.csr_matrix(…):创建稀疏矩阵,其中值为用户与项目交互的评分,矩阵的形状为 (self.n_users, self.n_items)。
fit 方法
def fit(self, df):
"""Train the model.
Args:
df (pandas.DataFrame): DataFrame that contains user-item interactions
Returns:
self
"""
self.n_users = df[self.col_user].nunique()
self.n_items = df[self.col_item].nunique()
self.user2index = {user: index for index, user in enumerate(df[self.col_user].unique())}
self.item2index = {item: index for index, item in enumerate(df[self.col_item].unique())}
self.index2user = {index: user for user, index in self.user2index.items()}
self.index2item = {index: item for item, index in self.item2index.items()}
self.rating_min = df[self.col_rating].min()
self.rating_max = df[self.col_rating].max()
self.compute_affinity_matrix(df, self.col_rating)
self.item_similarity = self.compute_item_similarity(self.user_affinity)
return self
功能: 训练模型。
计算唯一用户和项目数量:
self.n_users = df[self.col_user].nunique()
self.n_items = df[self.col_item].nunique()
- df[self.col_user].nunique():计算唯一用户数量。
- df[self.col_item].nunique():计算唯一项目数量。
创建用户和项目的索引映射:
self.user2index = {user: index for index, user in enumerate(df[self.col_user].unique())}
self.item2index = {item: index for index, item in enumerate(df[self.col_item].unique())}
self.index2user = {index: user for user, index in self.user2index.items()}
self.index2item = {index: item for item, index in self.item2index.items()}
- 创建从用户 ID 到内部索引的映射 (self.user2index)。
- 创建从项目 ID 到内部索引的映射 (self.item2index)。
- 创建从内部索引到用户 ID 的映射 (self.index2user)。
- 创建从内部索引到项目 ID 的映射 (self.index2item)。
获取评分的最小值和最大值:
self.rating_min = df[self.col_rating].min()
self.rating_max = df[self.col_rating].max()
- df[self.col_rating].min():获取评分的最小值。
- df[self.col_rating].max():获取评分的最大值。
计算亲和矩阵和项目相似度矩阵:
self.compute_affinity_matrix(df, self.col_rating)
self.item_similarity = self.compute_item_similarity(self.user_affinity)
- self.compute_affinity_matrix(df,self.col_rating):调用compute_affinity_matrix 方法,计算用户-项目亲和矩阵和项目相似度矩阵。
SARSingleNode 类的方法定义
compute_item_similarity 方法
def compute_item_similarity(self, user_affinity):
"""Compute item similarity matrix.
Args:
user_affinity (csr_matrix): User-item affinity matrix
Returns:
csr_matrix: Item similarity matrix
"""
if self.similarity_type == "jaccard":
item_similarity = self.jaccard(user_affinity)
elif self.similarity_type == "lift":
item_similarity = self.lift(user_affinity)
elif self.similarity_type == "mutual_information":
item_similarity = self.mutual_information(user_affinity)
return item_similarity
功能: 计算项目相似度矩阵。
- 步骤:
- 根据相似度类型(jaccard、lift、mutual_information)调用相应的相似度计算方法。
- 返回计算得到的项目相似度矩阵。
相似度计算方法(以 jaccard 为例)
def jaccard(self, user_affinity):
"""Compute Jaccard similarity.
Args:
user_affinity (csr_matrix): User-item affinity matrix
Returns:
csr_matrix: Item similarity matrix
"""
# 将亲和矩阵二值化,即将所有非零值设置为1
binary_affinity = user_affinity.copy()
binary_affinity.data = np.ones(len(binary_affinity.data))
# 计算交集矩阵
intersect = binary_affinity.T.dot(binary_affinity)
# 计算项目交集的平方和
sum_square = binary_affinity.sum(axis=0)
# 计算Jaccard相似度矩阵
jaccard_similarity = intersect / (sum_square + sum_square.T - intersect)
return jaccard_similarity
功能: 计算 Jaccard 相似度。
二值化亲和矩阵:
binary_affinity = user_affinity.copy()
binary_affinity.data = np.ones(len(binary_affinity.data))
- 将用户-项目亲和矩阵 user_affinity 复制为binary_affinity,并将所有非零值设置为 1。
计算交集矩阵:
intersect = binary_affinity.T.dot(binary_affinity)
- 计算二值化后的亲和矩阵的转置与自身的点积得到项目之间的交集矩阵intersect。
计算项目交集的平方和:
sum_square = binary_affinity.sum(axis=0)
- 计算二值化后的亲和矩阵在每一列上的和,得每个项目的交集和 sum_square。
计算 Jaccard 相似度矩阵:
jaccard_similarity = intersect / (sum_square + sum_square.T - intersect)
-
计算 Jaccard 相似度矩阵 jaccard_similarity,公式为:
J ( A , B ) = ∣ A ∩ B ∣ ∣ A ∪ B ∣ J(A, B) = \frac{|A \cap B|}{|A \cup B|} J(A,B)=∣A∪B∣∣A∩B∣
其中:- ( |A \cap B| ): 集合 A 和 B 的交集大小。
- ( |A \cup B| ): 集合 A 和 B 的并集大小。
-
返回计算得到的 Jaccard 相似度矩阵。
在SARSingleNode类的相似度计算方法如下:
lift 方法
def lift(self, user_affinity):
"""Compute Lift similarity.
Args:
user_affinity (csr_matrix): User-item affinity matrix
Returns:
csr_matrix: Item similarity matrix
"""
binary_affinity = user_affinity.copy()
binary_affinity.data = np.ones(len(binary_affinity.data))
intersect = binary_affinity.T.dot(binary_affinity)
item_freq = binary_affinity.sum(axis=0)
lift_similarity = intersect / (item_freq.T * item_freq)
return lift_similarity
功能: 计算 Lift 相似度。
二值化亲和矩阵
binary_affinity = user_affinity.copy()
binary_affinity.data = np.ones(len(binary_affinity.data))
- 将用户-项目亲和矩阵 user_affinity 复制为 binary_affinity,并将所有非零值设置为 1。
计算交集矩阵
intersect = binary_affinity.T.dot(binary_affinity)
- 计算二值化后的亲和矩阵的转置与自身的点积,得到项目之间的交集矩阵 intersect。
计算项目频率
item_freq = binary_affinity.sum(axis=0)
计算每个项目在用户中的出现次数,得到项目频率 item_freq。
计算 Lift 相似度矩阵
lift_similarity = intersect / (item_freq.T * item_freq)
- 计算 Lift 相似度矩阵 lift_similarity,公式为:
L i f t ( A , B ) = P ( A ∩ B ) P ( A ) P ( B ) Lift(A, B) = \frac{P(A \cap B)}{P(A)P(B)} Lift(A,B)=P(A)P(B)P(A∩B)
其中:
- ( P(A \cap B) ): A 和 B 同时出现的概率。
- ( P(A) ): A 出现的概率。
- ( P(B) ): B 出现的概率。
- 返回计算得到的 Lift 相似度矩阵。
mutual_information 方法
def mutual_information(self, user_affinity):
"""Compute Mutual Information similarity.
Args:
user_affinity (csr_matrix): User-item affinity matrix
Returns:
csr_matrix: Item similarity matrix
"""
binary_affinity = user_affinity.copy()
binary_affinity.data = np.ones(len(binary_affinity.data))
intersect = binary_affinity.T.dot(binary_affinity)
item_freq = binary_affinity.sum(axis=0)
total_interactions = binary_affinity.sum()
mutual_info = (
intersect / total_interactions * np.log((total_interactions * intersect) / (item_freq.T * item_freq))
)
return mutual_info
功能: 计算 Mutual Information 相似度。
二值化亲和矩阵
binary_affinity = user_affinity.copy()
binary_affinity.data = np.ones(len(binary_affinity.data))
- 将用户-项目亲和矩阵 user_affinity 复制为 binary_affinity,并将所有非零值设置为 1。
计算交集矩阵
intersect = binary_affinity.T.dot(binary_affinity)
- 计算二值化后的亲和矩阵的转置与自身的点积,得到项目之间的交集矩阵intersect。
计算项目频率
item_freq = binary_affinity.sum(axis=0)
- 计算每个项目在用户中的出现次数,得到项目频率 item_freq。
计算总交互次数
total_interactions = binary_affinity.sum()
- 计算所有用户-项目交互的总次数 total_interactions。
计算 Mutual Information 相似度矩阵
mutual_info = (
intersect / total_interactions * np.log((total_interactions * intersect) / (item_freq.T * item_freq))
)
movielens.py 文件解析
movielens.py 文件主要负责加载和预处理Movielens 数据集。以下是文件中关键部分的解释:
计算 Mutual Information 相似度矩阵 mutual_info,公式为:
M
I
(
A
,
B
)
=
∑
a
∈
A
∑
b
∈
B
p
(
a
,
b
)
log
p
(
a
,
b
)
p
(
a
)
p
(
b
)
MI(A, B) = \sum_{a \in A} \sum_{b \in B} p(a, b) \log \frac{p(a, b)}{p(a)p(b)}
MI(A,B)=a∈A∑b∈B∑p(a,b)logp(a)p(b)p(a,b)
其中:
- ( p(a, b) ): A 和 B 同时出现的概率。
- ( p(a) ): A 出现的概率。
- ( p(b) ): B 出现的概率。
数据加载
import os
import pandas as pd
DATA_FORMAT = {
"100k": {
"url": "http://files.grouplens.org/datasets/movielens/ml-100k.zip",
"path": "ml-100k",
"rating_file": "u.data",
"item_file": "u.item",
"has_header": False,
"separator": "\t",
},
"1m": {
"url": "http://files.grouplens.org/datasets/movielens/ml-1m.zip",
"path": "ml-1m",
"rating_file": "ratings.dat",
"item_file": "movies.dat",
"has_header": False,
"separator": "::",
},
# Add more formats as needed
}
def load_movielens_data(size="1m", local_cache_path=None):
"""Loads the Movielens dataset
Args:
size (str): the size of dataset: one of "100k", "1m"
local_cache_path (str): path to the local cache
Returns:
pd.DataFrame: the dataset
"""
data_format = DATA_FORMAT[size]
rating_path = os.path.join(local_cache_path, data_format["path"], data_format["rating_file"])
item_path = os.path.join(local_cache_path, data_format["path"], data_format["item_file"])
ratings = pd.read_csv(
rating_path,
sep=data_format["separator"],
header=0 if data_format["has_header"] else None,
names=["userId", "movieId", "rating", "timestamp"],
)
items = pd.read_csv(
item_path,
sep=data_format["separator"],
header=0 if data_format["has_header"] else None,
names=["movieId", "title", "genres"],
)
return ratings.merge(items, on="movieId")
数据格式:
DATA_FORMAT = {
"100k": {
"url": "http://files.grouplens.org/datasets/movielens/ml-100k.zip",
"path": "ml-100k",
"rating_file": "u.data",
"item_file": "u.item",
"has_header": False,
"separator": "\t",
},
"1m": {
"url": "http://files.grouplens.org/datasets/movielens/ml-1m.zip",
"path": "ml-1m",
"rating_file": "ratings.dat",
"item_file": "movies.dat",
"has_header": False,
"separator": "::",
},
# Add more formats as needed
}
- DATA_FORMAT 字典包含不同数据集的配置信息,包括 URL、文件路径、文件名、是否有表头和分隔符。
加载 Movielens 数据集
def load_movielens_data(size="1m", local_cache_path=None):
"""Loads the Movielens dataset
Args:
size (str): the size of dataset: one of "100k", "1m"
local_cache_path (str): path to the local cache
Returns:
pd.DataFrame: the dataset
"""
data_format = DATA_FORMAT[size]
rating_path = os.path.join(local_cache_path, data_format["path"], data_format["rating_file"])
item_path = os.path.join(local_cache_path, data_format["path"], data_format["item_file"])
ratings = pd.read_csv(
rating_path,
sep=data_format["separator"],
header=0 if data_format["has_header"] else None,
names=["userId", "movieId", "rating", "timestamp"],
)
items = pd.read_csv(
item_path,
sep=data_format["separator"],
header=0 if data_format["has_header"] else None,
names=["movieId", "title", "genres"],
)
return ratings.merge(items, on="movieId")
参数:
- size: 数据集大小,可选值为 “100k”, “1m”。 local_cache_path: 本地缓存路径。
返回:
- 返回合并后的 Pandas DataFrame,包括用户评分和电影信息。
步骤:
- 从指定路径读取评分和电影信息文件。
- 使用指定分隔符和表头信息加载数据。
- 将评分数据和电影信息数据按 movieId 合并。
data_format = DATA_FORMAT[size]
rating_path = os.path.join(local_cache_path, data_format["path"], data_format["rating_file"])
item_path = os.path.join(local_cache_path, data_format["path"], data_format["item_file"])
- 从 DATA_FORMAT 字典中获取指定大小的数据集配置信息。
- 构建评分文件和电影信息文件的路径。
ratings = pd.read_csv(
rating_path,
sep=data_format["separator"],
header=0 if data_format["has_header"] else None,
names=["userId", "movieId", "rating", "timestamp"],
)
items = pd.read_csv(
item_path,
sep=data_format["separator"],
header=0 if data_format["has_header"] else None,
names=["movieId", "title", "genres"],
)
- 使用 Pandas 的 read_csv 函数分别读取评分文件和电影信息文件。
- sep: 指定文件的分隔符。
- header: 指定文件是否有表头。
- names: 指定列名。
return ratings.merge(items, on="movieId")
- 将评分数据和电影信息数据按 movieId 进行合并,并返回合并后的 DataFrame。
补充
_maybe_download_and_extract 方法
def _maybe_download_and_extract(size, dest_path):
"""Downloads and extracts MovieLens rating and item datafiles if they don’t already exist.
Args:
size (str): the size of dataset: one of "100k", "1m"
dest_path (str): path to save the downloaded files
"""
data_format = DATA_FORMAT[size]
url = data_format["url"]
path = os.path.join(dest_path, data_format["path"])
if not os.path.exists(path):
os.makedirs(path)
file_path = os.path.join(dest_path, os.path.basename(url))
urllib.request.urlretrieve(url, file_path)
with zipfile.ZipFile(file_path, 'r') as zip_ref:
zip_ref.extractall(dest_path)
os.remove(file_path)
功能: 如果 MovieLens 数据集文件不存在,则下载并解压缩这些文件。
检查文件是否存在
if not os.path.exists(path):
os.makedirs(path)
file_path = os.path.join(dest_path, os.path.basename(url))
urllib.request.urlretrieve(url, file_path)
with zipfile.ZipFile(file_path, 'r') as zip_ref:
zip_ref.extractall(dest_path)
os.remove(file_path)
- 检查指定路径 path 是否存在,如果不存在则创建目录。
- 构建文件下载路径 file_path。
- 使用 urllib.request.urlretrieve 下载数据集文件。
- 使用 zipfile.ZipFile 解压缩下载的文件到指定路径。
- 删除下载的压缩文件。
python_splitters.py 文件解析
python_splitters.py 文件主要负责将数据集进行分割,以生成训练集和测试集。以下是文件中关键部分的解释:
数据集分割
import numpy as np
def python_stratified_split(data, ratio=0.75, seed=42):
"""Stratified splitter for train/test.
Args:
data (pd.DataFrame): input dataframe to split
ratio (float): ratio of train set
seed (int): seed for random splitting
Returns:
pd.DataFrame, pd.DataFrame: train and test dataframe
"""
np.random.seed(seed)
shuffled_data = data.sample(frac=1, random_state=seed).reset_index(drop=True)
train_size = int(ratio * len(data))
train = shuffled_data[:train_size].reset_index(drop=True)
test = shuffled_data[train_size:].reset_index(drop=True)
return train, test
详细解析:
导入库
import numpy as np
- 导入 NumPy 库,用于数值计算和随机数生成。
定义数据集分割函数
def python_stratified_split(data, ratio=0.75, seed=42):
"""Stratified splitter for train/test.
Args:
data (pd.DataFrame): input dataframe to split
ratio (float): ratio of train set
seed (int): seed for random splitting
Returns:
pd.DataFrame, pd.DataFrame: train and test dataframe
"""
- 定义函数 python_stratified_split,用于将数据集分割为训练集和测试集。
- 参数:
- data: 输入的 Pandas DataFrame 数据。
- ratio: 训练集比例,默认值为 0.75。
- seed: 随机种子,默认值为 42。
- 返回:
- 返回分割后的训练集和测试集 DataFrame。
设置随机种子
np.random.seed(seed)
- 设置随机种子,以确保分割结果可重复。
随机打乱数据顺序
shuffled_data = data.sample(frac=1, random_state=seed).reset_index(drop=True)
- 使用 Pandas 的 sample 方法随机打乱数据顺序,frac=1 表示返回所有样本。
- random_state=seed:设置随机种子,确保结果可重复。
- reset_index(drop=True):重置索引,丢弃原有索引。
计算训练集大小
train_size = int(ratio * len(data))
- 计算训练集的大小,ratio * len(data) 表示训练集所占的样本数。
分割数据集
train = shuffled_data[:train_size].reset_index(drop=True)
test = shuffled_data[train_size:].reset_index(drop=True)
- 将打乱后的数据分割为训练集和测试集。
- train = shuffled_data[:train_size]:取前 train_size 条数据作为训练集。
- test = shuffled_data[train_size:]:取剩余的数据作为测试集。
- reset_index(drop=True):重置索引,丢弃原有索引。
返回分割后的数据集
return train, test
- 返回训练集和测试集 DataFrame。
补充
stratified_split 方法
def stratified_split(data, ratio=0.75, seed=42):
"""Stratified splitter for train/test.
Args:
data (pd.DataFrame): input dataframe to split
ratio (float): ratio of train set
seed (int): seed for random splitting
Returns:
pd.DataFrame, pd.DataFrame: train and test dataframe
"""
np.random.seed(seed)
shuffled_data = data.sample(frac=1, random_state=seed).reset_index(drop=True)
train_size = int(ratio * len(data))
train = shuffled_data[:train_size].reset_index(drop=True)
test = shuffled_data[train_size:].reset_index(drop=True)
return train, test
- **功能:**将数据集按比例分割为训练集和测试集,保持数据分布的一致性。
- 步骤:
- 设置随机种子 np.random.seed(seed),确保分割结果可重复。
- 使用 sample 方法随机打乱数据顺序,frac=1 表示返回所有样本,random_state=seed 确保结果可重复。
- 重置索引 reset_index(drop=True),丢弃原有索引。
- 计算训练集大小 train_size = int(ratio * len(data))。
- 将数据分割为训练集 train 和测试集 test,并重置索引。
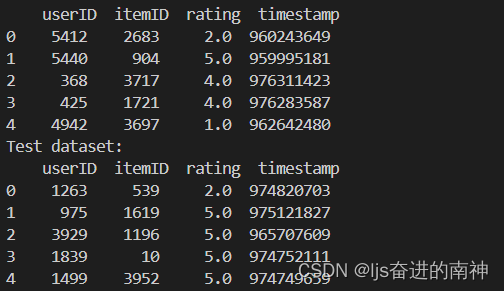
如下为部分训练集和测试集的数据:
五、相关公式以及参数设置
相关公式
时间衰减公式
在 SAR 模型中,用于计算用户与项目的亲和度的时间衰减公式为:
a i j = ∑ k w k ( 1 2 ) t 0 − t k T a_{ij} = \sum_k w_k \left(\frac{1}{2}\right)^{\frac{t_0 - t_k}{T}} aij=k∑wk(21)Tt0−tk
其中:
- ( w_k ): 事件的权重。
- ( t_0 ): 当前时间。
- ( t_k ): 事件发生时间。
- ( T ): 时间衰减系数。
Jaccard 相似度
J ( A , B ) = ∣ A ∩ B ∣ ∣ A ∪ B ∣ J(A, B) = \frac{|A \cap B|}{|A \cup B|} J(A,B)=∣A∪B∣∣A∩B∣
其中:
- ( |A \cap B| ): 集合 A 和 B 的交集大小。
- ( |A \cup B| ): 集合 A 和 B 的并集大小。
Lift 相似度
L i f t ( A , B ) = P ( A ∩ B ) P ( A ) P ( B ) Lift(A, B) = \frac{P(A \cap B)}{P(A)P(B)} Lift(A,B)=P(A)P(B)P(A∩B)
其中:
- ( P(A \cap B) ): A 和 B 同时出现的概率。
- ( P(A) ): A 出现的概率。
- ( P(B) ): B 出现的概率。
Mutual Information 相似度
M I ( A , B ) = ∑ a ∈ A ∑ b ∈ B p ( a , b ) log p ( a , b ) p ( a ) p ( b ) MI(A, B) = \sum_{a \in A} \sum_{b \in B} p(a, b) \log \frac{p(a, b)}{p(a)p(b)} MI(A,B)=a∈A∑b∈B∑p(a,b)logp(a)p(b)p(a,b)
其中:
- ( p(a, b) ): A 和 B 同时出现的概率。
- ( p(a) ): A 出现的概率。
- ( p(b) ): B 出现的概率。
平均精度 (Mean Average Precision, MAP)
M A P = 1 ∣ U ∣ ∑ u ∈ U A P ( u ) MAP = \frac{1}{|U|} \sum_{u \in U} AP(u) MAP=∣U∣1u∈U∑AP(u)
归一化折现累积增益 (Normalized Discounted Cumulative Gain, NDCG)
N D C G = D C G I D C G NDCG = \frac{DCG}{IDCG} NDCG=IDCGDCG
其中:
D C G = ∑ i = 1 p r e l i log 2 ( i + 1 ) DCG = \sum_{i=1}^{p} \frac{rel_i}{\log_2(i + 1)} DCG=i=1∑plog2(i+1)reli
精度 (Precision)
P r e c i s i o n = ∣ R e l e v a n t ∩ R e t r i e v e d ∣ ∣ R e t r i e v e d ∣ Precision = \frac{|Relevant \cap Retrieved|}{|Retrieved|} Precision=∣Retrieved∣∣Relevant∩Retrieved∣
召回率 (Recall)
R e c a l l = ∣ R e l e v a n t ∩ R e t r i e v e d ∣ ∣ R e l e v a n t ∣ Recall = \frac{|Relevant \cap Retrieved|}{|Relevant|} Recall=∣Relevant∣∣Relevant∩Retrieved∣
参数设置
在 SARSingleNode 类中,通过构造函数的参数设置来配置模型,如下:
- remove_seen=True: 是否移除已经看过的项目。
- similarity_type=“jaccard”: 相似度类型(“jaccard”, “lift”,“mutual_information”)。
- time_decay_coefficient=30: 时间衰减系数。 time_now=None: 当前时间。
- timedecay_formula=True: 是否使用时间衰减公式。
- threshold=1: 阈值。
- normalize=True: 是否归一化评分。
参考资料
1.Badrul Sarwar, et al, “Item-based collaborative filtering recommendation algorithms”, WWW, 2001.
2. Scipy (sparse matrix), url: https://docs.scipy.org/doc/scipy/reference/sparse.html
3. Asela Gunawardana and Guy Shani, “A survey of accuracy evaluation metrics of recommendation tasks”, The Journal of Machine Learning Research, vol. 10, pp 2935-2962, 2009.
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









