






目录
Apache Hadopp概述
Hadoop介绍
-
狭义上Hadoop指的是Apache软件基金会的一款开源软件。
-
用java语言实现,开源
-
允许用户使用简单的编程模型实现跨机器集群对海量数据进行分布式计算
-
-
Hadoop核心组件
-
Hadoop HDFS(分布式文件存储系统):解决海量数据存储
-
Hadoop YARN(集群资源管理和任务调度框架):解决资源任务调度
-
Hadoop MapReduce(分布式计算框架):解决海量数据计算
-
-
广义上Hadoop指的是围绕Hadoop打造的大数据生态圈

Hadoop现状
-
HDFS作为分布式文件存储系统,在生态圈的底层与核心地位
-
YARN作为分布式通用的集群资源管理系统和任务调度平台,支撑各种计算引擎运行
-
MapReduce作为大数据生态圈第一代分布式计算引擎,由于自身设计模型所产生的弊端,导致企业一线几乎不再直接使用MapReduce进行编程处理,但是很多软件的底层仍然在使用MapReduce引擎来处理数据
Hadoop特性优点
-
扩容能力强
-
成本低
-
效率高
-
可靠
Hadopp架构变迁
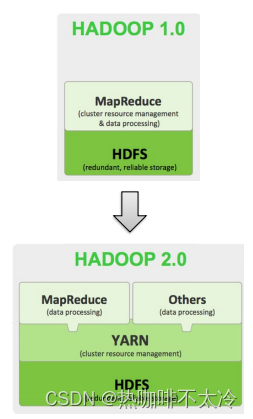
Hadoop3.0架构组件和Hadoop2.0类似,3.0着重于性能优化。
Apache Hadopp集群搭建
Hadopp集群简介
-
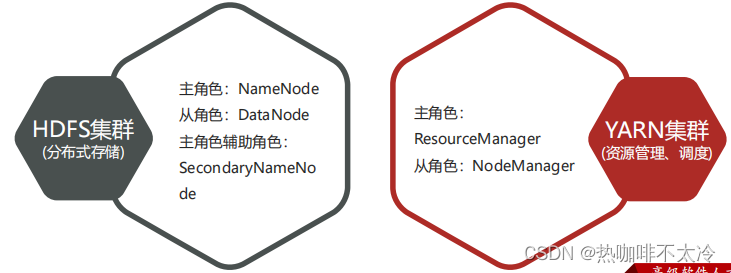
Hadoop集群包括两个集群:HDFS集群、YARN集群
-
两个集群逻辑上分离,两个集群之间没有依赖、互不影响
-
两个集群物理上在一起,某些角色进程往往部署在同一台物理服务器上
-
MapReduce是计算框架、代码层面的组件,没有集群之说
-
两个集群都是标准的主从框架
Hadoop集群模式安装
-
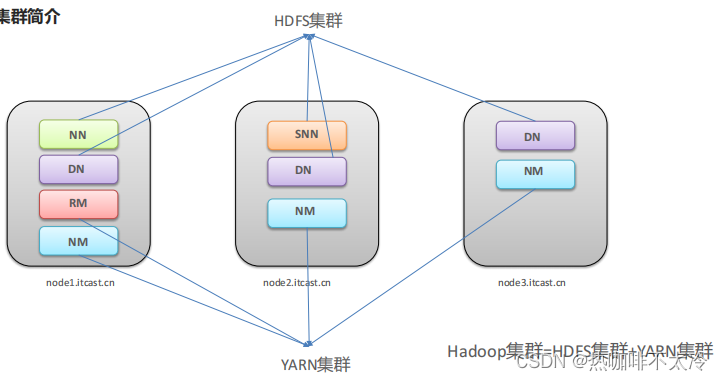
集群规划
-
node1:NN DN RM NM
-
node2:SNN DN NM
-
node3:DN NM
-
-
基础环境
#主机名(3台机器)
cat /etc/hostname
#hosts映射(3台机器)
cat /etc/hosts
192.168.88.151 node1.itcast.cn node1
192.168.88.152 node2.itcast.cn node2
192.168.88.153 node3.itcast.cn node3
#集群时间同步(3台机器)
yum -y install ntpdate
ntpdate ntp5.aliyun.com
#创建统一工作目录(3台机器)
mkdir -p /export/server/ #软件安装路径
mkdir -p /export/data/ #数据存储路径
mkdir -p /export/software/ #安装包存放路径
#防火墙关闭(3台机器)
firewall-cmd --state #查看防火墙状态
systemctl stop firewalld.service #停止firewalld服务
systemctl disable firewalld.service #开机禁止firewalld服务
#ssh免密登录(只需要配置node1至node1、node2、node3即可)
ssh-keygen #node1生成公钥私钥
#node1配置免密登录到node1 node2 node3
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
#JDK 1.8安装(3台机器) 上传 jdk-8u241-linux-x64.tar.gz到/export/server/目录下
cd /export/server/
tar zxvf jdk-8u241-linux-x64.tar.gz
#配置环境变量
vim /etc/profile
export JAVA_HOME=/export/server/jdk1.8.0_241
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
#重新加载环境变量文件
source /etc/profile
#将node1上安装的JDK分发到node2和node3上
scp -r /export/server/jdk1.8.0_241/ root@node2:/export/server/
scp -r /export/server/jdk1.8.0_241/ root@node3:/export/server/
#在node1上加载node2和node3的环境变量文件
scp /etc/profile root@node2:/etc
scp /etc/profile root@node3:/etc
#查看Java版本号
java -version-
上传Hadoop安装包到node1 /export/server
cd /export/server/
tar zxvf hadoop-3.3.0-Centos7-64-with-snappy.tar.gz-
Hadoop安装包目录结构
| 目录 | 说明 |
|---|---|
| bin | Hadoop最基本的管理脚本和使用脚本的目录,这些脚本是sbin目录下管理脚本的基础实现,用户可以直接使用这些脚本管理和使用Hadoop |
| etc | Hadoop配置文件所在的目录 |
| include | 对外提供的编程库头文件,这些头文件均是C++定义的,通常用于C++程序访问HDFS或者编写MapReduce程序 |
| lib | 该目录包含了Hadoop对外提供的编程动态库和静态库,与include目录中的头文件结合使用 |
| libexec | 各个服务对用的shell配置文件所在的目录,可用于配置日志输出、启动参数(比如JVM参数)等基本信息。 |
| sbin | Hadoop管理脚本所在的目录,主要包含HDFS和YARN中各类服务的启动/关闭脚本 |
| share | Hadoop各个模块编译后的jar包所在的目录 |
-
配置文件概述
-
第一类:hadoop-env.sh
-
第二类:xxx.site.xml,site表示的是用户定义的配置,会覆盖default中的默认配置
-
core-site.xml 核心模块配置
-
hdfs-site.xml hdfs文件系统模块配置
-
mapred-site.xml MapReduce模块配置
-
yarn-site.xml yarn模块配置
-
-
第三类:workers
-
所有的配置文件目录:/export/server/hadoop-3.3.0/etc/hadoop
-
-
修改配置文件(配置文件路径 hadoop-3.3.0/etc/hadoop)
-
hadoop-env.sh
#文件最后添加 export JAVA_HOME=/export/server/jdk1.8.0_241 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root -
core-site.xml
<!-- 设置默认使用的文件系统 Hadoop支持file、HDFS、GFS、ali|Amazon云等文件系统 --> <property> <name>fs.defaultFS</name> <value>hdfs://node1:8020</value> </property> <!-- 设置Hadoop本地保存数据路径 --> <property> <name>hadoop.tmp.dir</name> <value>/export/data/hadoop-3.3.0</value> </property> <!-- 设置HDFS web UI用户身份 --> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> <!-- 整合hive 用户代理设置 --> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> <!-- 文件系统垃圾桶保存时间 --> <property> <name>fs.trash.interval</name> <value>1440</value> </property> -
hdfs-site.xml
<!-- 设置SNN进程运行机器位置信息 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>node2:9868</value> </property> -
mapred-site.xml
<!-- 设置MR程序默认运行模式: yarn集群模式 local本地模式 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- MR程序历史服务地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>node1:10020</value> </property> <!-- MR程序历史服务器web端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>node1:19888</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> -
yarn-site.xml
<!-- 设置YARN集群主角色运行机器位置 --> <property> <name>yarn.resourcemanager.hostname</name> <value>node1</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 是否将对容器实施物理内存限制 --> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <!-- 是否将对容器实施虚拟内存限制。 --> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> <!-- 开启日志聚集 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置yarn历史服务器地址 --> <property> <name>yarn.log.server.url</name> <value>http://node1:19888/jobhistory/logs</value> </property> <!-- 历史日志保存的时间 7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> -
workers
node1.itcast.cn node2.itcast.cn node3.itcast.cn
-
-
分发同步hadoop安装包
cd /export/server scp -r hadoop-3.3.0 root@node2:$PWD scp -r hadoop-3.3.0 root@node3:$PWD
-
将hadoop添加到环境变量(3台机器)
vim /etc/profile export HADOOP_HOME=/export/server/hadoop-3.3.0 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin source /etc/profile #别忘了scp给其他两台机器哦
Hadoop集群启停命令、Web UI
-
Hadoop集群启动
-
首次启动HDFS时,必须对其进行格式化操作
-
hdfs namenode -format
-
format本质上时初始化工作,进行HDFS清理和准备工作
-
format只能进行一次,后续不再需要
-
如果多次format除了造成数据丢失外,还会导致HDFS集群主从角色之间互不识别。
-
-
脚本一键启停
-
在node1上,使用软件自带的shell脚本一键启动。前提:配置好机器之间的SSH免密登录和workers文件。
#HDFS集群 start-dfs.sh stop-dfs.sh #YARN集群 start-yarn.sh stop-yarn.sh #Hadoop集群 start-all.sh stop-all.sh -
启动完毕之后可以使用jps命令查看进程是否启动成功
-
Hadoop启动日志路径:/export/server/hadoop-3.3.0/logs/
-
HDFS集群UI页面:http://node1:9870
-
YARN集群UI页面:http://node1:8088
-
HDFS分布式文件系统基础
分布式存储系统的核心属性及功能含义
分布式存储系统核心属性
-
分布式存储
-
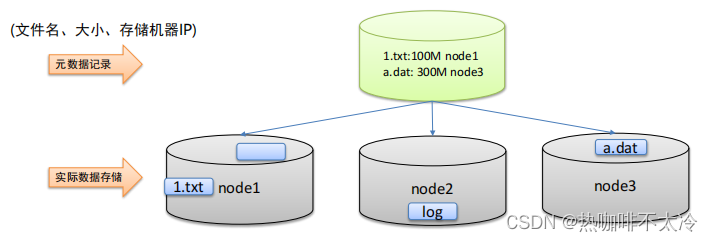
元数据记录
-
分块存储
-
副本机制
分布式存储的优点
-
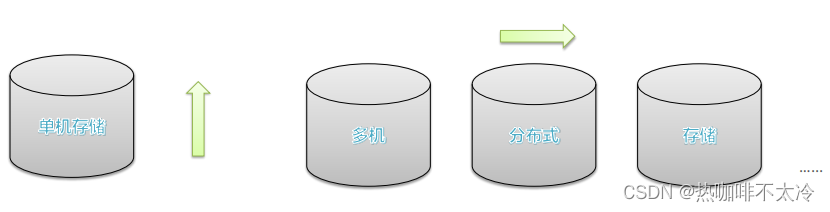
问题:数据量大,单机存储遇到瓶颈
-
解决:
-
单机纵向扩展:磁盘不够加磁盘,有上限瓶颈限制
-
多机横向扩展:机器不够加机器,理论上无限扩展
-
元数据记录的功能
-
问题:文件分布在不同机器上不利于寻找
-
解决:元数据记录文件及其存储位置信息,快速定位文件位置
分块存储好处
-
问题:文件过大导致单机存不下、上传下载效率低
-
解决:文件分块存储在不同机器上,针对块并行操作提高效率

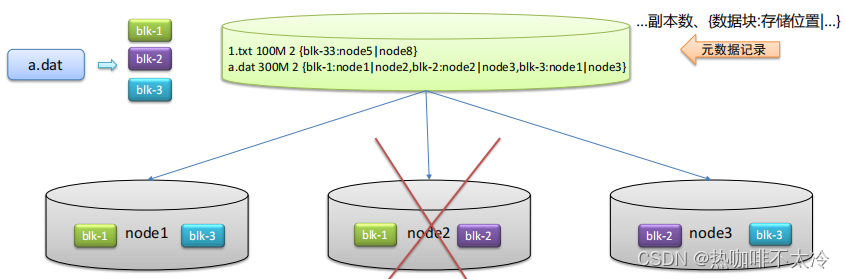
副本机制的作用
-
问题:硬件故障难以避免,数据容易丢失
-
解决:不同机器设备备份,冗余存储,保障数据安全
HDFS简介
-
HDFS意为:Hadoop分布式文件系统,是Hadoop核心组件之一,是大数据生态圈的最底层。也可以说大数据首先要解决的问题就是海量数据的存储问题。
-
HDFS是横跨在多台计算机上的存储系统。
-
HDFS适合场景:大文件、数据流式访问、一次写入多次读取、低成本部署、廉价PC、高容错
-
HDFS不适合场景:小文件、数据交互式访问、频繁任意修改、低延迟处理
HDFS重要特性
整体概述
-
主从架构
-
分块存储
-
副本机制
-
元数据记录
-
抽象统一的目录树结构(namespace)
主从架构
-
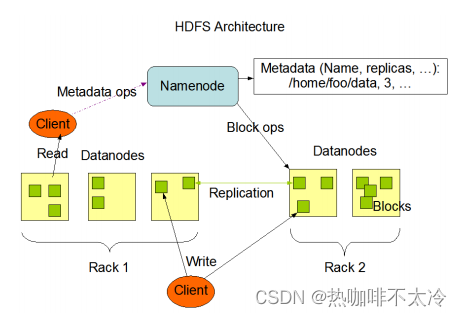
HDFS集群式标准的master/slave主从架构集群
-
一般一个HDFS集群由一个namenode和多个datanode组成
-
namenode是HDFS的主节点,datanode是HDFS从节点,两种角色各司其职,共同协调完成分布式文件存储服务
分块存储
-
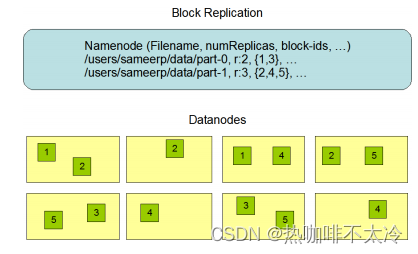
HDFS中的文件在物理上是分块存储(block)的,默认大小是128M,不足128M则本身就是一块
-
块的大小可以通过配置参数来规定,参数位于hdfs-default.xml中:dfs.blocksize
副本机制
-
文件中的所有block都会有副本
-
副本数由参数dfs.replication控制,默认是3,也就是说会额外复制2份,连同本身共3份
元数据管理
在HDFS中,namenode管理的元数据具有两种类型:
-
文件自身属性信息:文件名称、权限、修改时间、文件大小、复制因子、数据块大小

-
文件块位置映射信息:记录文件块和datanode之间的映射信息,即哪个块位于哪个节点上
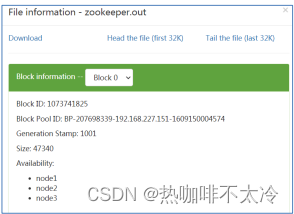
数据块存储
-
文件的各个block的具体存储管理由datanode节点承担
-
每一个block都可以在多个datanode上存储
HDFS shell操作
HDFS shell命令行解释说明
-
命令行界面(CLI),是指用户通过键盘输入指令,计算机接收到指令后,予以执行一种人际交互方式。
-
#操作本地文件系统 hadoop fs -ls file:/// #操作HDFS分布式文件系统 hadoop fs -ls hdfs://node1:8020/ #直接根目录,没有指定协议,将加载读取fs.defaultFS值 hadoop fs -ls / -
hadoop dfs 只能操作HDFS文件系统,不过已经过时
-
hdfs dfs 只能操作HDFS文件系统相关,常用
-
hadoop fs 可操作任意文件系统,不仅仅是hdfs文件系统,使用范围更广
-
可以通过hadoop fs -help 命令来查看每个命令的详细用法
-
HDFS文件系统的操作命令很多和Linux类似,因此学习成本较低
HDFS shell命令行常用操作
1.创建文件夹
hadoop fs -mkdir [-p] <path>
hadoop fs -mkdir /itcast2.查看指定目录下的内容
hadoop fs -ls [-h] [-R] [<path>]
-h 人性化显示文件size
-R 递归查看指定目录及其子目录
hadoop fs -ls /3.上传文件到HDFS指定目录下
hadoop fs -put [-f] [-p] <localsrc> ... <dst>
-f 覆盖目标文件
-p 保留访问和修改时间,所有权和权限
localsrc 本地文件系统
dst 目标文件系统(HDFS)
hadoop fs -put zookeeper.out /itcast
hadoop fs -put file:///etc/profile hdfs://node1:8020/itcast4.查看HDFS文件内容
hadoop fs -cat <src> ...
读取指定文件全部内容,显示在标准输出控制台
注意:对大文件内容读取时要慎重
hadoop fs -cat /itcast/zookeeper.out5.下载HDFS文件
hadoop fs -get [-f] [-p] <src> ... <localdst>
下载文件到本地文件系统指定目录,localdst必须是目录
-f 覆盖目标文件(已存在下)
-p 保留访问和修改时间,所有权和权限。
[root@node2 ~]# mkdir test
[root@node2 ~]# cd test/
[root@node2 test]# ll
total 0
[root@node2 test]# hadoop fs -get /itcast/zookeeper.out ./
[root@node2 test]# ll
total 20
-rw-r--r-- 1 root root 18213 Aug 18 17:54 zookeeper.out6.拷贝HDFS文件
hadoop fs -cp [-f] <src> ... <dst>
-f 覆盖目标文件(已存在下)
[root@node3 ~]# hadoop fs -cp /small/1.txt /itcast
[root@node3 ~]# hadoop fs -cp /small/1.txt /itcast/666.txt #重命令
[root@node3 ~]# hadoop fs -ls /itcast
Found 4 items
-rw-r--r-- 3 root supergroup 2 2021-08-18 17:58 /itcast/1.txt
-rw-r--r-- 3 root supergroup 2 2021-08-18 17:59 /itcast/666.txt7.追加数据到HDFS文件中
hadoop fs -appendToFile <localsrc> ... <dst>
将所有给定本地文件的内容追加到给的dst文件
dst文件如果不存在,将创建该文件
#追加内容到文件尾部 appendToFile
[root@node3 ~]# echo 1 >> 1.txt
[root@node3 ~]# echo 2 >> 2.txt
[root@node3 ~]# echo 3 >> 3.txt
[root@node3 ~]# hadoop fs -put 1.txt /
[root@node3 ~]# hadoop fs -cat /1.txt
1
[root@node3 ~]# hadoop fs -appendToFile 2.txt 3.txt /1.txt
[root@node3 ~]# hadoop fs -cat /1.txt
1
2
38.HDFS数据移动操作
hadoop fs -mv <src> ... <dst>
移动文件到指定文件夹下
可以使用该命令移动数据,重命名文件的名称HDFS shell其他命令
命令官方指导文档
https://hadoop.apache.org/docs/r3.3.0/hadoop-project-dist/hadoop-common/FileSystemShell.htmlHDFS工作流程与机制
HDFS集群角色与职责
namenode职责
-
namenode仅存储HDFS的元数据:文件系统中所有文件的目录树,并跟踪整个集群中的文件,不存储实际数据
-
namenode知道HDFS中任何给定文件的块列表及其位置。使用此信息namenode知道如何从块中构建文件
-
namenode不持久化存储每个文件中各个块所在的datanode的位置信息,这些信息会在系统启动时从datanode重建
-
namenode时Hadoop集群中的单点故障
-
namenode所在机器通常会配置有大量内存(RAM)
datanode职责
-
datanode负责最终数据块block的存储。是集群的从角色,也称为Slave
-
datanode启动时,会将自己注册到namenode并汇报自己负责持有的块列表
-
当某个datanode关闭时,不会影响数据的可用性。namenode将安排由其他datanode管理的块进行副本复制
-
datanode所在机器通常配置由大量的硬盘空间,因为实际数据存储在datanode中
secondarynamenode职责
-
snn充当namenode的辅助节点,但不能替代namenode
-
主要时帮主角色进行元数据文件的合并动作。可以通俗的理解为主角色的秘书
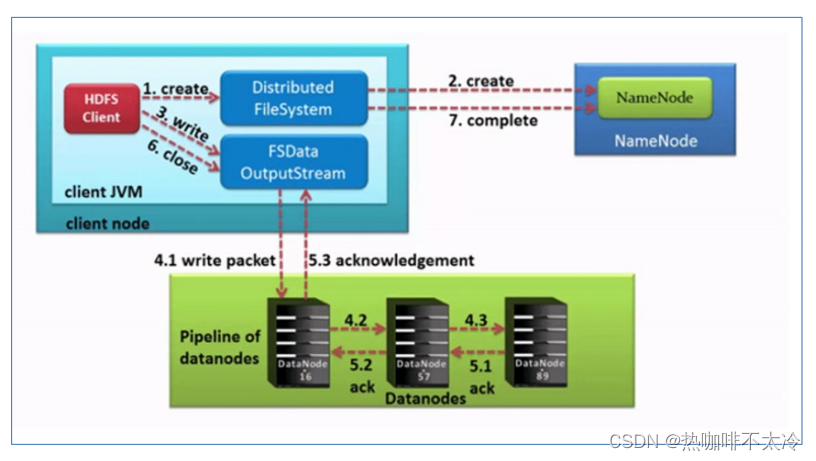
HDFS写数据流程(上传文件)
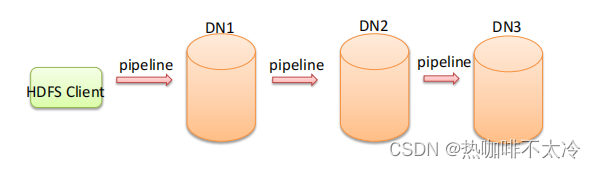
Pipeline管道
-
Pipeline,中文翻译为管道,这是HDFS在上传文件写数据过程中采用的一种数据传输方式
-
客户端将数据块写入第一个数据节点,第一个数据节点保存数据之后再将块复制到第二个数据节点,后者保存后将其复制到第三个数据节点
-
为什么datanode之间采用pipeline线性传输,而不是一次给三个datanode拓扑式传输呢?因为数据以管道的方式,顺序的沿着一个方向传输,这样能够充分利用每个机器的带宽,避免网络瓶颈和高延迟式的连接,最下化推送所有数据的延时。在线性推送模式下,每台机器所有的出口宽度都用于以最快的速度传输数据,而不是在多个接收者之间分配宽带
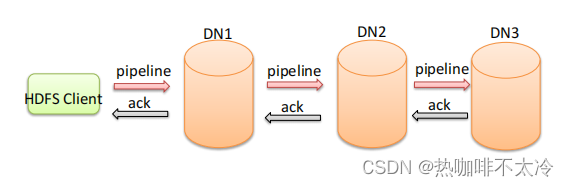
ACK应答响应
-
ACK即是确认字符,在数据通信中,接收方发给发送方的一种传输类控制字符。表示发来的数据已确认接收无误
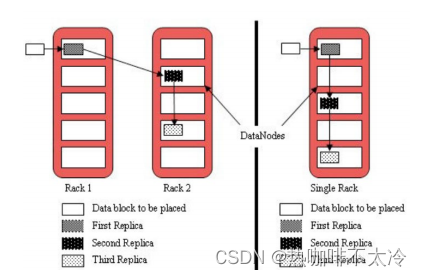
默认3副本存储策略
-
第一块副本:优先客户端本地,否则随机
-
第二块副本:不同意第一块副本的不同机架(rack)
-
第三块副本:第二块副本相同机架不同机器
过程
-
HDFS客户端创建对象实例DistributedFileSystem,该对象中封装了与HDFS文件系统操作的相关方法
-
调用DistributedFileSystem对象的create()方法,通过RPC请求namenode创建文件。namenode执行各种检查判断:目标文件是否存在、父目录是否存在、客户端是否具有创建该文件的权限。如果检查通过,namenode就会为本次请求记下一条记录,返回FSDataOutputStream输出流对象给客户端用于写数据
-
客户端通过FSDataOutputStream输出流开始写入数据
-
客户端写入数据时,将数据分成一个个数据包(packet 默认64k),内部组件DataStreamer请求namenode挑选出适合存储数据副本的一组datanode地址,默认是3副本存储。DataStreamer将数据包流式传输到pipeline的第一个DataNode,该DataNode存储数据包并将它发送到pipeline的第二个DataNode。同样,第二个DataNode存储数据包并且发送给第三个(也是最后一个)DataNode。
-
传输的反方向上,会通过ACK机制校验数据包传输是否成功
-
客户端完成数据写入后,在FSDataOutputStream输出流上调用close()方法关闭
-
DistributedFileSystem联系namenode告知其文件写入完成,等待namenode确认。因为namenode已经知道文件由哪些块组成,因此仅需等待最小复制块即可成功返回。最小复制是由参数dfs.namenode.replication.min指定,默认是1.
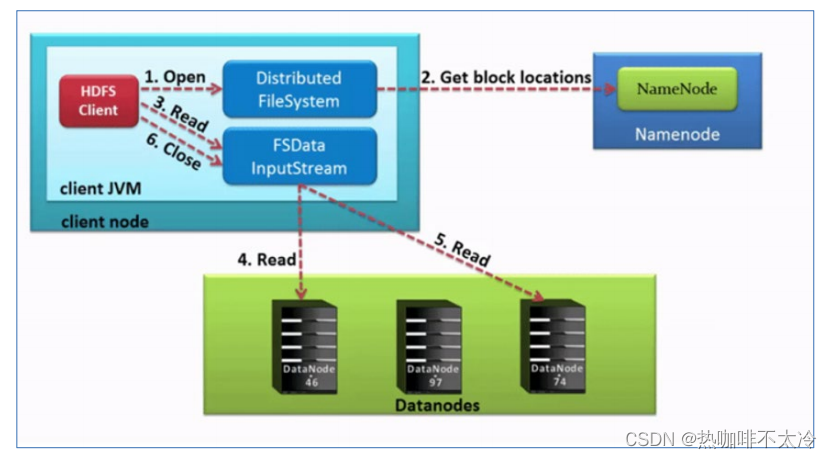
HDFS读取数据流程(下载文件)
















 312
312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











