






目录
Apache Hadoop的介绍
搭建Hadoop集群
启动Hadoop集群(重要)
了解Hadoop集群的辅助功能
历史服务器
垃圾回收机制
一、Apache Hadoop入门
1.1、Hadoop介绍
Apache软件基金会(Apache Software Foundation,简称 ASF)是专门为运作一个开源软件项目的 Apache 的团体提供支持的非盈利性组织,这个开源软件的项目就是 Apache 项目。
狭义上:hadoop指的是Apache一款java开源软件,是一个大数据分析处理平台。
Hadoop HDFS: 分布式文件存储系统,解决的是海量数据的存储问题.
Hadoop MapReduce: 分布式计算框架,解决的是海量数据怎么算的问题
Hadoop YARN: 分布式资源调度软件,解决的是海量数据的计算资源分配和调度权重问题.
目前Yarn只能分配cpu和内存资源.
广义上:Hadoop指的是hadoop生态圈。
因为Hadoop有良好的扩展性,支持多种计算框架(spark,flink,taz.......)
Yarn是通用的资源调度服务,可以辅助其他服务完成资源调度
Hdfs也可以给其他服务提供存分布式储方案

1.2、Hadoop起源发展
Hadoop之父(Doug Cutting)卡大爷
起源项目Apache Nutch。 致力于构建一个全网搜索引擎。(全网搜索引擎面临的问题也是海量网页的存储和计算问题)
Google也在做搜索,也遇到这些问题,内部解决了。
Google前后写了3篇论文(谷歌是使用c实现的)。
后续被人们成为大数据发展的三驾马车
谷歌分布式文件系统(GFS)------>HDFS
谷歌版MapReduce 系统------>Hadoop MapReduce
bigtable---->HBase基于论文的影响 Nutch团队实现了相应的java版本开源组件。
使用java开发更易于推广
Nutch团队把HDFS和MapReduce抽取独立成为单独软件在2008年贡献给了Apache(开源)。
Doug Cutting 看到他儿子在牙牙学语时,抱着黄色小象,亲昵的叫hadoop,他灵光一闪,就把这技术命名为 Hadoop,而且还用了黄色小象作为标示 Logo。
1.3、Hadoop特性优点(重要)
分布式、扩容能力
Hadoop可以轻易扩展到几千个服务(可以让几千台计算机同时进行计算)
可以随时在不关闭服务的基础上扩容或者缩容.
扩容能力,代表的就是企业发展初期我们的低投入,和企业上升阶段的极高上限
成本低
购买1000台服务器也比买一台超级计算机便宜多了.
可以随着业务的增长和萎缩,随时调节资本投入
可以利用不同服务的不同特性.如果需要高内存,我们就让任务在内存 大的服务上运行, 需要高存储空间,就将数据存储到存储空间较大的服务上.
高效率 并行能力
三个臭皮匠顶个诸葛亮, 我们将计算任务分发到多个服务上同时进行计算,计算效率一定会更高
并且我们可以在多个服务器上同时运行不同的任务,实现任务的并行
可靠性
存储可靠: 分布式存储,采用的是冗余存储机制
冗余存储: 一个数据存储多份,如果其中一个服务器宕机了,数据不会丢失,直接备份一份即可
计算可靠: 计算出现问题,会重新执行任务,或者输出日志
通用性
谁都会用(允许使用简单的编程模型在大量计算机集群上对大型数据集进行分布式处理)
Hdoop巧妙的将技术和业务进行了拆分
Hadoop的出现,大大降低了开发门槛,使你我这样的普通人也能接触大数据开发
二、Apache Hadoop集群搭建
2.1、发行版本
官方社区版本 Apache基金会官方
版本新 功能最全的
不稳定 兼容性需要测试 bug多
在企业中如果使用的是社区版Hadoop需要进行各种测试,或者源码修改,相对来说比较麻烦
商业版本 商业公司在官方版本之上进行商业化发行。著名:Cloudera、hotonWorks、MapR
稳的一批 兼容性极好 技术支持 本地化支持 一键在线安装 但需要支付培训费用
版本不一定是最新的 辅助工具软件需要收费
Cloudera发行的hadoop生态圈软件叫做CDH版本。
Cloudera’s Distribution Including Apache Hadoop。
https://www.cloudera.com/products/open-source/apache-hadoop/key-cdh-components.html
Hortonworks Data Platform (HDP)Hadoop本身版本变化
hadoop 1.x
只有两个组件(由于架构老旧已经被淘汰了)
分布式文件存储系统 HDFS
分布式计算框架 MapReduce (既负责资源调度, 又负责计算)
压力巨大,计算效率低
只能使用mr计算引擎,可扩展性极差
hadoop 2.x(市场上使用最多)
此时有三个组件
HDFS 只负责存储
MR 只负责计算
YARN 负责资源调度(他的出现也是Hadoop成就生态圈的起点)
可以兼容更多的计算引擎
可以同时协助更多的组件进行资源调度,
性能更好,可扩展性更强
hadoop 3.x
技术架构与hadoop2.x版本一致
在hadoop2.x版本的基础上进行了性能,安全性和兼容性的全面升级.
使用上2,x和3.x没有本质上的区别,我们这里学习3.3版本 你也就会使用2.x版本了
2.2、Hadoop集群(一定记住只有两个集群yarn和hdfs)
通常是有hdfs集群和yarn集群组成。两个集群都是标准的主从架构集群。
可以理解为hdfs是存储集群, yarn是一个资源调度集群,而MapReduce是一个计算框架,只提供了一些API接口(相当于python中的一些模块)
hdfs负责海量数据的存储,
存储数据的服务,有一个特点,就是必须运行起来才能存储数据. 例如: mysql , ZooKeeper
hdfs也是一样的,必须运行该服务构成集群才能分布式存储数据.
yarn负责资源调度
因为其他服务或者任务想要运行,需要从yarn上申请资源,相当于一个服务端,而服务端提供响应的前提是服务必须启动
MapReduce负责制定计算规则
我们可以理解为mr就是一个计算代码,yarn给其申请了资源,我们将这段计算代码发到yarn指定资源的服务器上,运行即可
如果没有执行任务的时候,MapReduce就不需要运行.
可以类比thread模块, 这个模块是一个服务么? 不是,不需要一直运行,但是我们可以调用其创建一个线程.并执行
两个集群逻辑上分离 物理上在一起。
本身两个集群运行互不相干,但是都在一个服务器上运行
举例: windows电脑上的QQ 和 微信
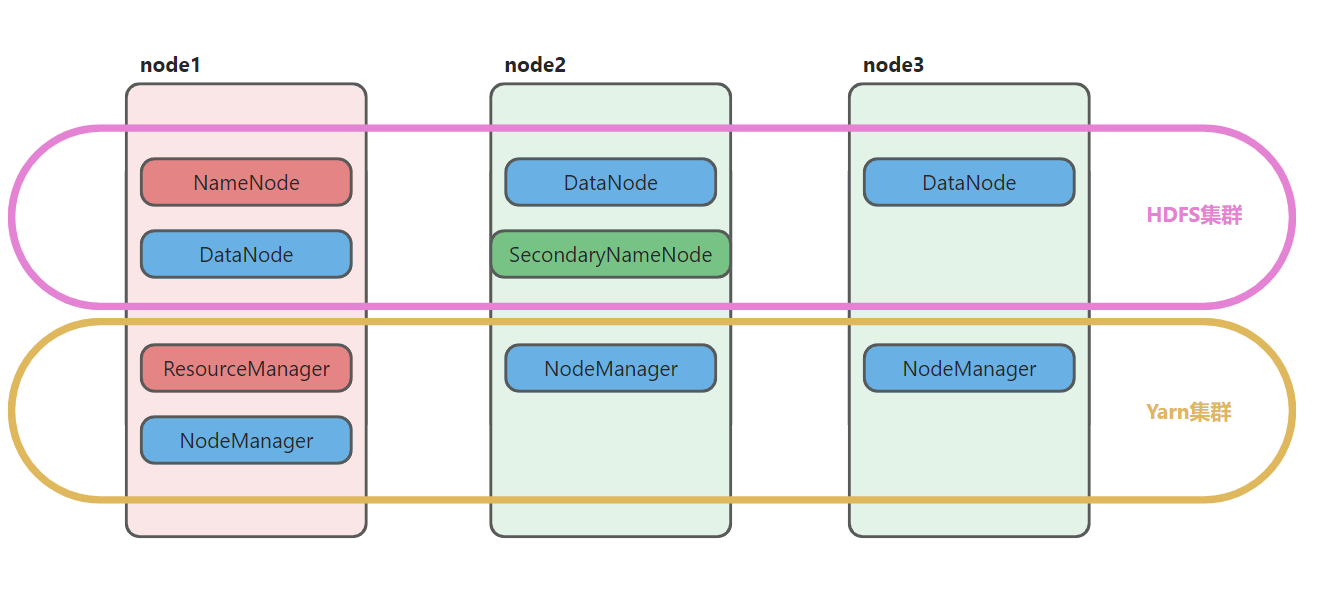
HDFS集群:解决了海量数据存储 分布式存储系统
主角色:namenode(NN)负责元数据的管理
从角色:datanode(DN)负责数据的存储工作
主角色辅助角色"秘书角色":secondarynamenode (SNN)帮助主角色完成元数据管理工作
元数据: 描述数据的数据
举例: HDFS中存储了一个1.txt文件 数据 1.txt 这个文件的 名称,大小,位置,备份数量,创建时间,修改时间.... 这些就是元数据
YARN集群:集群资源管理 任务调度
主角色:resourcemanager(RM)分配资源(给任务一个合适大小的内存和cpu资源),调度任务(多个任务谁先执行谁后执行, 资源不足时,谁占用的多,谁占用的少)
从角色:nodemanager(NM)汇报本机资源,使用本机资源
2.3、Hadoop部署模式、集群规划
单机模式 Standalone
一台机器,所有的角色在一个java进程中运行。 适合体验。伪分布式
一台机器 每个角色单独的java进程。 适合测试分布式 cluster
多台机器 每个角色运行在不同的机器上 生产测试都可以高可用(持续可用)集群 HA
在开发中我们使用的几乎都是高可用模式
但是在学习中高可用模式占用内存太多了,所以我们不用
使用时,无论是否是高可用使用方式完全一致.
在分布式的模式下 给主角色设置备份角色 实现了容错的功能 解决了单点故障
保证集群持续可用性。Hadoop集群的规划(重要)
根据软件和硬件的特性 合理的安排各个角色在不同的机器上。
有冲突的尽量不部署在一起
有工作依赖尽量部署在一起
nodemanager 和datanode是基友
node1: namenode datanode | resourcemanager nodemanger
node2: datanode secondarynamenode| nodemanger
node3: datanode | nodemangerQ:如果后续需要扩容hadoop集群,应该增加哪些角色呢?
node4: datanode nodemanger
node5: datanode nodemanger
node6: datanode nodemanger
.....三、Hadoop具体安装部署(安装的是分布式模式)
3.1、服务器基础环境准备
ip、主机名
hosts映射 别忘了windows也配置
防火墙关闭
时间同步
免密登录 node1---->node1 node2 node3
JDK安装3.2、安装包目录结构
#上传安装包到/export/software 解压 /export/server
tar zxvf /export/software/hadoop-3.3.0-Centos7-64-with-snappy.tar.gz -C /export/server/
bin #hadoop核心脚本 最基础最底层脚本
etc #配置目录
include
lib
libexec
LICENSE.txt
NOTICE.txt
README.txt
sbin #服务启动 关闭 维护相关的脚本
share #官方自带实例 hadoop相关依赖jar3.3、配置文件的修改
第一类 1个 hadoop-env.sh 配置hadoop运行的环境(java环境)
第二类 4个 core|hdfs|mapred|yarn-site.xml 配置所有组件的参数
site表示的是用户定义的配置,会覆盖default中的默认配置。
core-site.xml 核心模块配置
hdfs-site.xml hdfs文件系统模块配置
mapred-site.xml MapReduce模块配置
yarn-site.xml yarn模块配置
第三类 1个 workers 配置集群中的各个服务地址
修改配置文件(配置文件路径 hadoop-3.3.0/etc/hadoop)
hadoop-env.sh
export JAVA_HOME=/export/server/jdk1.8.0_65
#文件最后添加
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root core-site.xml
<!-- 设置默认使用的文件系统 Hadoop支持file、HDFS、GFS、ali|Amazon云等文件系统 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<!-- 设置Hadoop本地保存数据路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop-3.3.0</value>
</property>
<!-- 设置HDFS web UI用户身份 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 整合hive 用户代理设置 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 开启垃圾桶机制 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>hdfs-site.xml
<!-- 设置SNN进程运行机器位置信息 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node2:9868</value>
</property>mapred-site.xml
<!-- 设置MR程序默认运行模式: yarn集群模式 local本地模式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR程序历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>yarn-site.xml
<!-- 设置YARN集群主角色运行机器位置 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否将对容器实施物理内存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否将对容器实施虚拟内存限制。 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
</property>
<!-- 保存的时间7天, 以秒为单位 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>workers
这里应该写的是ip ,如果你配置了主机映射,就可以使用node1,node2,node3代替相应的ip地址,否则必须将ip写全
node1
node2
node33.4、scp安装包到其他机器
cd /export/server
scp -r hadoop-3.3.0 root@node2:$PWD
scp -r hadoop-3.3.0 root@node3:$PWD
注释:
1. 由于hadoop-3.3.0是文件夹,所以一定要使用-r进行递归复制.
2. $PWD代表该服务的当前工作目录
举例: 我们再node1上CD到了server目录下,使用root@node2:$PWD就会将文件复制到node2的server目录下3.5、Hadoop环境变量配置
vim /etc/profile
export HADOOP_HOME=/export/server/hadoop-3.3.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
#别忘了scp给其他两台机器哦
scp /etc/profile node2:/etc/profile
scp /etc/profile node3:/etc/profile3.6、hadoop namenode format(记住不能重复初始化)
format准确来说翻译成为初始化比较好。对namenode工作目录、初始文件进行生成。
hdfs其实最终是将数据存储到了每一台linux服务器中.
所以我们初始化,是为了在linux服务器上创建一个空的目录,专门用来保存hdfs的元数据资料.
在namenode所在的机器执行 执行一次。首次启动之前

#在node1 部署namenode的这台机器上执行
hadoop namenode -format
#执行成功 日志会有如下显示
21/05/23 15:38:19 INFO common.Storage: Storage directory /export/data/hadoopdata/dfs/name has been successfully formatted.
# 查询该目录的相关文件,后续元数据管理时,会将数据写入下方的文件中
[root@node1 server]# ll /export/data/hadoopdata/dfs/name/current/
total 16
-rw-r--r-- 1 root root 321 May 23 15:38 fsimage_0000000000000000000
-rw-r--r-- 1 root root 62 May 23 15:38 fsimage_0000000000000000000.md5
-rw-r--r-- 1 root root 2 May 23 15:38 seen_txid
-rw-r--r-- 1 root root 207 May 23 15:38 VERSION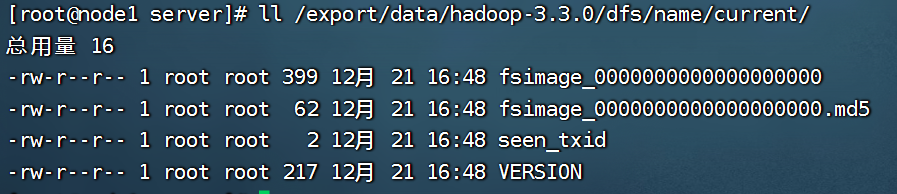
Q:如果不小心初始化了多次,如何?
初始化多次的后果: namenode 和datanode 之间互不相识. 此时hdfs集群进入瘫痪状态,无法正常使用
解决方案:
学习中: 将node1, node2, node3中的/export/data/hadoop-3.3.0目录全部删除,并且重新初始化即可. 初始化后所有的数据全部消失.
四、Hadoop集群启动(重要)
4.1、单节点单进程逐个手动启动
HDFS集群
#hadoop2.x版本命令
hadoop-daemon.sh start|stop namenode|datanode|secondarynamenode
#hadoop3.x版本命令
hdfs --daemon start|stop namenode|datanode|secondarynamenodeYARN集群
#hadoop2.x版本命令
yarn-daemon.sh start|stop resourcemanager|nodemanager
#hadoop3.x版本命令
yarn --daemon start|stop resourcemanager|nodemanager优点:精准的控制每个角色每个进程的启停。避免了群起群停(时间成本)。
使用场景: 在服务启动后,正在工作的过程中,我们需要对于某一个服务中的角色进行启停则使用单起单停
为什么单节点启停比群起群停用的多呢?
开发中,我们的集群一般不会整体进行启停,因为如果服务群停则无法提供服务,造成损失.
如果个别节点出现问题,我们一般单独对于该节点进行启停,修复bug后继续接入集群进行工作.
4.2、脚本一键启动
前提:配置好免密登录。ssh
ssh-copy-id node1.itcast.cn
ssh-copy-id node2.itcast.cn
ssh-copy-id node3.itcast.cnHDFS集群
start-dfs.sh
stop-dfs.sh YARN集群
start-yarn.sh
stop-yarn.sh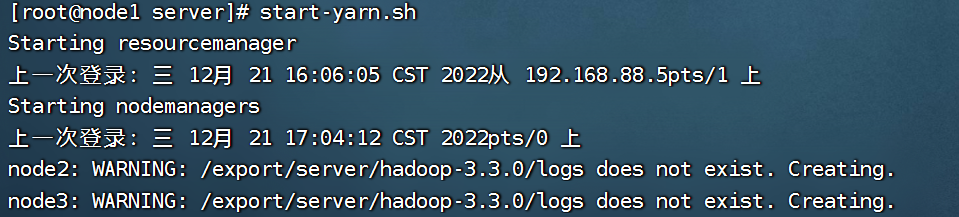
4.3、集群进程确认和错误排查
确认是否成功
[root@node1 ~]# jps
8000 DataNode
8371 NodeManager
8692 Jps
8264 ResourceManager
7865 NameNode如果进程不在 看启动运行日志!!!!!!!!!!!!!
#默认情况下 日志目录
cd /export/server/hadoop-3.3.0/logs/
#注意找到对应进程名字 以log结尾的文件
# 查询日志时,如果是出现了bug 直接查询ERROR日志即可
cat hadoop-root-namenode-node1.itcast.cn.log | grep ERROR五、Hadoop辅助功能
5.1、MapReduce jobhistory服务(正常开发中history都是打开的)
背景
默认情况下,yarn上关于MapReduce程序执行历史信息、执行记录不会永久存储;
一旦yarn集群重启 之前的信息就会消失。功能
保存yarn上已经完成的MapReduce的执行信息。配置
因为需求修改配置。重启hadoop集群才能生效。
vim mapred-site.xml
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>scp同步给其他机器
scp /export/server/hadoop-3.3.0/etc/hadoop/mapred-site.xml node2:/export/server/hadoop-3.3.0/etc/hadoop/
scp /export/server/hadoop-3.3.0/etc/hadoop/mapred-site.xml node3:/export/server/hadoop-3.3.0/etc/hadoop/重启hadoop集群
自己手动启停jobhistory服务。

#hadoop2.x版本命令
mr-jobhistory-daemon.sh start|stop historyserver
#hadoop3.x版本命令
mapred --daemon start|stop historyserver
[root@node1 ~]# jps
13794 JobHistoryServer
13060 DataNode
12922 NameNode
13436 NodeManager
13836 Jps
13327 ResourceManager5.2、HDFS 垃圾桶机制
背景 在windows叫做回收站
在默认情况下 hdfs没有垃圾桶 意味着删除操作直接物理删除文件。
[root@node1 ~]# hadoop fs -rm /itcast/1.txt
Deleted /itcast/1.txt功能:和回收站一种 在删除数据的时候 先去垃圾桶 如果后悔可以复原。
配置
在core-site.xml中开启垃圾桶机制
指定保存在垃圾桶的时间。单位分钟
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>集群同步配置 重启hadoop服务。
[root@node1 hadoop]# pwd
/export/server/hadoop-3.3.0/etc/hadoop
[root@node1 hadoop]# scp core-site.xml node2:$PWD
core-site.xml 100% 1027 898.7KB/s 00:00
[root@node1 hadoop]# scp core-site.xml node3:$PWD
core-site.xml 垃圾桶使用
如果想要使用垃圾桶机制,不能再web页面上直接删除,此时不会触发垃圾桶机制
想要使用垃圾桶机制,要使用终端指令或者api接口进行删除.
配置好之后 再删除文件 直接进入垃圾桶
[root@node1 ~]# hadoop fs -rm /itcast.txt
INFO fs.TrashPolicyDefault: Moved: 'hdfs://node1:8020/itcast.txt' to trash at: hdfs://node1:8020/user/root/.Trash/Current/itcast.txt垃圾桶的本质就是hdfs上的一个隐藏目录。
hdfs://node1:8020/user/用户名/.Trash/Current后悔了 需要恢复怎么做?
hadoop fs -cp /user/root/.Trash/Current/itcast.txt /就想直接删除文件怎么做?(慎用) 这种做法不安全
hadoop fs -rm -skipTrash /itcast.txt
[root@node1 ~]# hadoop fs -rm -skipTrash /itcast.txt
Deleted /itcast.txt














 454
454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









