









2000-2022年上市公司数字化转型数据(年报词频、文本统计)
1、时间:2000-2022年
2、来源:上市公司年报、巨潮资讯网
3、方法说明:参考管理世界中吴非(2021)的做法,对人工智能技术、大数据技术、云计算技术、区块链技术、数字技术运用五个维度相关词频进行统计。
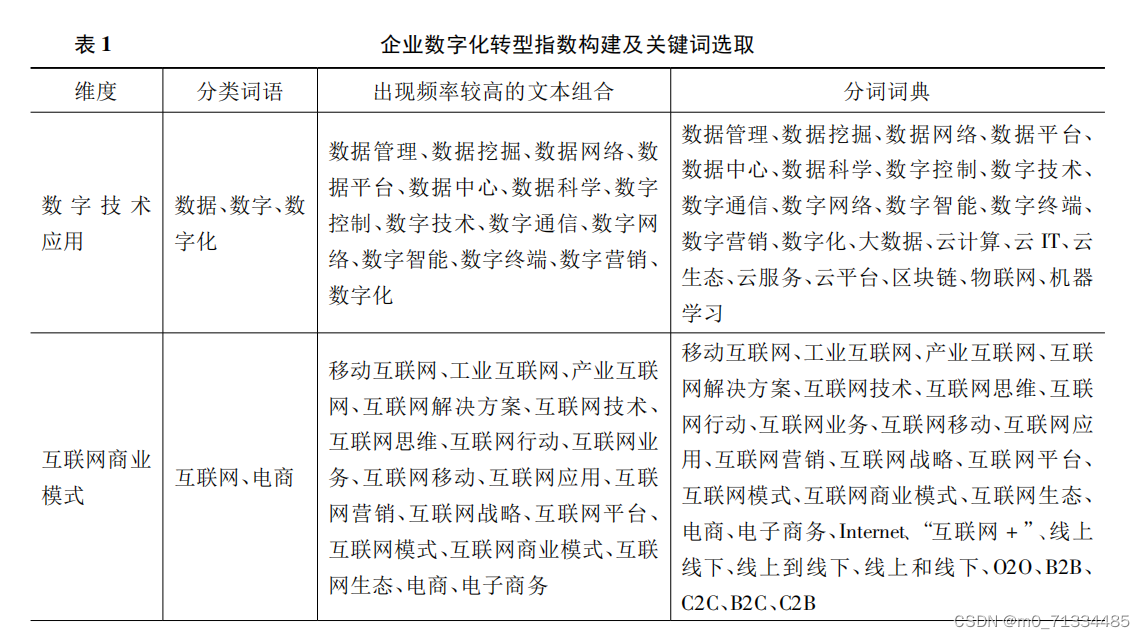
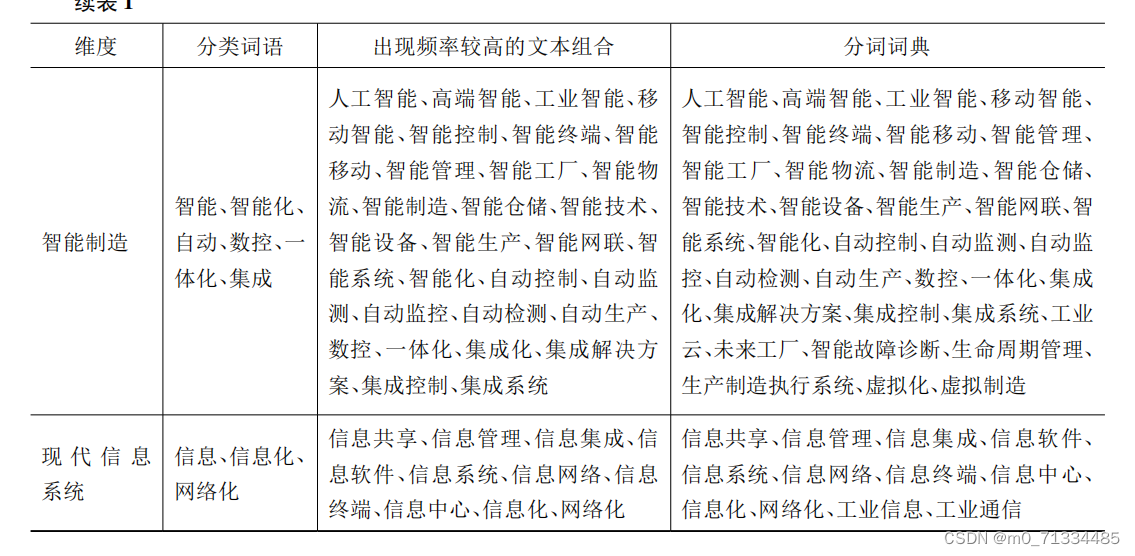
参考财贸经济中赵宸宇(2021)的做法,对数字技术应用、互联网商业模式、智能制造、现代信息系统四个维度相关词频进行统计。
4、指标及具体词频:类别、股票代码、股票简称、年报标题、年份、全文-文本总长度、仅中英文-文本总长度、数字化转型程度-A、数字化转型程度-B、人工智能技术-A、大数据技术-A、云计算技术-A、区块链技术-A、数字技术运用-A、数字技术应用-B、互联网商业模式-B、智能制造-B、现代信息系统-B、人工智能、商业智能、图像理解、投资决策辅助系统、智能数据分析、智能机器人、机器学习、深度学习;
语义搜索、生物识别技术、人脸识别、语音识别、身份验证、自动驾驶、自然语言处理、大数据、数据挖掘、文本挖掘、数据可视化、异构数据、征信、增强现实、混合现实、虚拟现实、云计算、流计算、图计算、内存计算、多方安全计算、类脑计算、绿色计算、认知计算、融合架构、亿级并发、EB级存储、物联网、信息物理系统、区块链、数字货币、分布式计算、差分隐私技术、智能金融合约、移动互联网;
工业互联网、移动互联、互联网医疗、电子商务、移动支付、第三方支付、NFC支付、智能能源、B2B、B2C、C2B、C2C、O2O、网联、智能穿戴、智慧农业、智能交通、智能医疗、智能客服、智能家居、智能投顾、智能文旅、智能环保、智能电网、智能营销、数字营销、无人零售、互联网金融、数字金融、Fintech、金融科技、量化金融、开放银行、数据管理、数据挖掘、数据网络、数据平台、数据中心;
数据科学、数字控制、数字技术、数字通信、数字网络、数字智能、数字终端、数字营销、数字化、大数据、云计算、云IT、云生态、云服务、云平台、区块链、物联网、机器学习、移动互联网、工业互联网、产业互联网、互联网解决方案、互联网技术、互联网思维、互联网行动、互联网业务、互联网移动;
互联网应用、互联网营销、互联网战略、互联网平台、互联网模式、互联网商业模式、互联网生态、电商、电子商务、Internet、互联网+、线上线下、线上到线下、线上和线下、O2O、B2B、C2C、B2C、C2B、人工智能、高端智能、工业智能、移动智能、智能控制、智能终端、智能移动、智能管理、智能工厂;
智能物流、智能制造、智能仓储、智能技术、智能设备、智能生产、智能网联、智能系统、智能化、自动控制、自动监测、自动监控、自动检测、自动生产、数控、一体化、集成化、集成解决方案、集成控制、集成系统、工业云、未来工厂、智能故障诊断、生命周期管理、生产制造执行系统、虚拟化、虚拟制造、信息共享、信息管理、信息集成、信息软件、信息系统、信息网络、信息终端、信息中心、信息化、网络化、工业信息、工业通信
5、参考文献:
吴非,胡慧芷,林慧妍,任晓怡.企业数字化转型与资本市场表现——来自股票流动性的经验证据[J].管理世界,2021,37(07):130-144+10.D
赵宸宇,王文春,李雪松.数字化转型如何影响企业全要素生产率[J].财贸经济,2021,42
6、范围:5331家上市公司,
7、样本量:5.5W+
8、下载链接:
2000-2022年上市公司数字化转型数据(年报词频、文本统计)![]() https://download.csdn.net/download/m0_71334485/88623038
https://download.csdn.net/download/m0_71334485/88623038

















 1075
1075











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











