






参考文献
[1]吴非,胡慧芷,林慧妍,任晓怡.企业数字化转型与资本市场表现——来自股票流动性的经验证[J].管理世界,2021,37(07)
[2]韩峰,姜竹青.集聚网络视角下企业数字化的生产率提升效应研究[J].管理世界,2023,39(11)
复刻论文缘由
本人为大二学生,上数据科学导论的文本分析课程时,希望顺手锻炼一下学术能力,遂选取以上两篇论文进行参考,希望复刻企业数字化的数据提取过程。
然而在上网搜索的过程中,遇到的很多问题无法得以解决,或者说,有分享出来的都是直接分享爬取好的excel结果,没有看到直接分享代码的;或者说,都是需要收费的。
基于此,本人希望把整个作业结果分享出来,和大家共同研究探讨。
遇到的问题主要如下:
1、如何爬取上市公司年报数据
--> 参考了社区里面另一个大佬的:巨潮资讯网年报爬虫_爬取巨潮资讯网年报-CSDN博客
2、如何将pdf转换成txt
--> 自行探索综合了几个方案,再调整得出的可运行的版本
3、在此基础上,剔除关键词前存在“没”“无”“不”等否定词语的表述,同时也剔除非本公司(包括公司的股东、客户、供应商、公司高管简介介绍在内)的“数字化转型”关键词
--> 本人只剔除了否定表述,对于后者,希望有大佬指点一番
词典
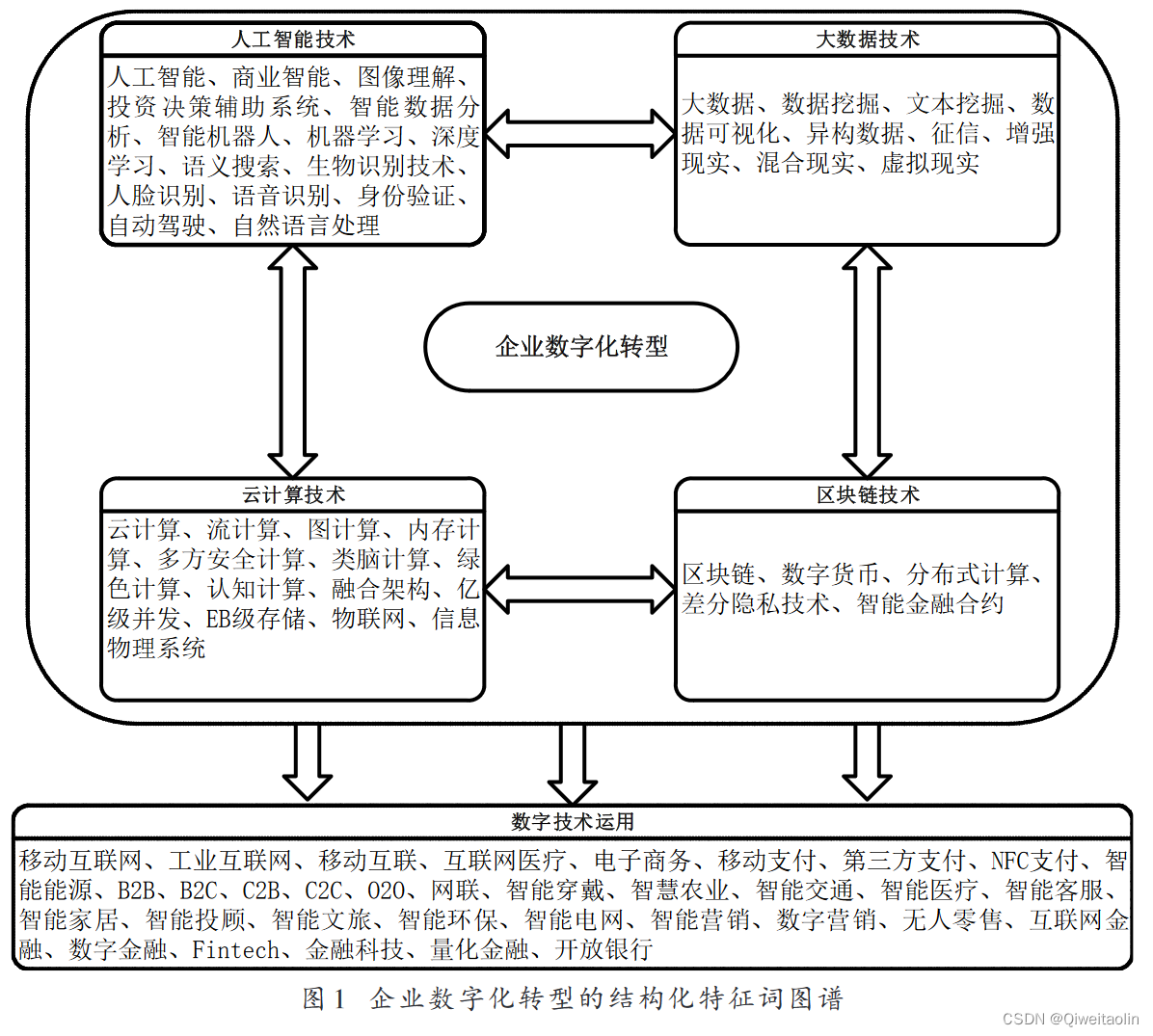
数据说明
本文基于文本挖掘的数字经济词频方法来测算企业数字化水平。
本文根据吴非等(2021)的方法,利用爬虫技术批量搜索了中国沪深A股上市制造业企业2010~2022年期间的年报文本数据,并且使用其词典进行词频统计。
进而借鉴洛克伦和麦克唐纳(2014)及阿西莫格鲁等(2021)的研究,利用上市公司年报文本数据和基于机器学习的“词频—逆文本频率”方法测算企业数字化水平。
企业数字化指标可以表示为:

1、爬取年报
在CSMAR上自行下载所你需要的股票代码,将文件命名为“stockcode.xlsx”,表格内容如图所示:
调整文件夹路径,即可直接运行代码。我这里爬取的是巨潮资讯网的年报数据。
import os
os.chdir(r"E:\大学课程相关\大二下学期\5 数据科学导论\文本分析")
os.getcwd()import requests,time,random,json
import pandas as pd
def req(stock,year,org_dict):
# post请求地址(巨潮资讯网的那个查询框实质为该地址)
url = "http://www.cninfo.com.cn/new/hisAnnouncement/query"
# 表单数据,需要在浏览器开发者模式中查看具体格式
data = {
"pageNum":"1",
"pageSize":"30",
"tabName":"fulltext",
"stock":stock + "," + org_dict[stock] ,# 按照浏览器开发者模式中显示的参数格式构造参数
"seDate":f"{str(int(year)+1)}-01-01~{str(int(year)+1)}-12-31",
"column":"szse",
"category":"category_ndbg_szsh",
"isHLtitle": "true",
"sortName":"time",
"sortType": "desc"
}
# 请求头
headers = {"Content-Length": "201","Content-Type":"application/x-www-form-urlencoded"}
# 发起请求
req = requests.post(url,data=data,headers=headers)
if json.loads(req.text)["announcements"]:# 确保json.loads(req.text)["announcements"]非空,是可迭代对象
for item in json.loads(req.text)["announcements"]:# 遍历announcements列表中的数据,目的是排除英文报告和报告摘要,唯一确定年度报告或者更新版
if "摘要" not in item["announcementTitle"]:
if "英文" not in item["announcementTitle"]:
if "修订" in item["announcementTitle"] or "更新" in item["announcementTitle"]:
adjunctUrl = item["adjunctUrl"] # "finalpage/2019-04-30/1206161856.PDF" 中间部分便为年报发布日期,只需对字符切片即可
pdfurl = "http://static.cninfo.com.cn/" + adjunctUrl
r = requests.get(pdfurl)
f = open("年报" +"/"+ stock + "-" + year + "年度报告" + ".pdf", "wb")
f.write(r.content)
print(f"{stock}-{year}年报下载完成!") # 打印进度
break
else:
adjunctUrl = item["adjunctUrl"] # "finalpage/2019-04-30/1206161856.PDF" 中间部分便为年报发布日期,只需对字符切片即可
pdfurl = "http://static.cninfo.com.cn/" + adjunctUrl
r = requests.get(pdfurl)
f = open("年报" +"/"+ stock + "-" + year + "年度报告" + ".pdf", "wb")
f.write(r.content)
print(f"{stock}-{year}年报下载完成!") # 打印进度
break
# 该函数主要是通过http://www.cninfo.com.cn/new/data/szse_stock.json该json数据,找到每个stock对应的orgid,并存储在字典org_dict中
def get_orgid():
org_dict = {}
org_json = requests.get("http://www.cninfo.com.cn/new/data/szse_stock.json").json()["stockList"]
for i in range(len(org_json)):
org_dict[org_json[i]["code"]] = org_json[i]["orgId"]
return org_dict
# 获取年报PDF的路径
def load_pdf(code, year):
file_path = r'E:\大学课程相关\大二下学期\5 数据科学导论\文本分析\年报' # 自行修改
file_name = "{}-{}年度报告".format(code,year)
pdf_path = os.path.join(file_path,file_name)
return pdf_pathimport pandas as pd
import time
import random
import os
if __name__ == "__main__":
# 读取股票代码信息
data = pd.read_excel("stockcode.xlsx", converters={'stockcode': str})
stockcodes = data['stockcode'].tolist()
org_dict = get_orgid()
# 年份范围从2010到2022
years = [str(year) for year in range(2010, 2023)]
# 遍历股票代码及年份列表
for stock in stockcodes:
for year in years:
pdf_path = load_pdf(stock, year) + ".pdf"
txt_path = load_pdf(stock, year) + ".txt"
# 检查对应的PDF文件是否已经存在,如果存在则跳过下载步骤
if os.path.exists(pdf_path):
print("PDF文件已存在,跳过下载步骤。")
else:
req(stock, year, org_dict)
time.sleep(random.randint(0, 2))
2、文件转换:将PDF转换成TXT文件
import pandas as pd
import os
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import *
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfpage import PDFPage,PDFTextExtractionNotAllowed
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter# 获取年报PDF的路径
def load_pdf(code, year):
file_path = r'E:\大学课程相关\大二下学期\5 数据科学导论\文本分析\年报' # 自行修改
file_name = "{}-{}年度报告".format(code,year)
pdf_path = os.path.join(file_path,file_name)
return pdf_pathdef parsePDF(pdf_path,txt_path):
# 以二进制读模式打开pdf文档
fp = open(pdf_path,'rb')
# 用文件对象来创建一个pdf文档分析器
parser = PDFParser(fp)
# pdf文档的对象,与分析器连接起来
doc = PDFDocument(parser=parser)
parser.set_document(doc=doc)
# 如果是加密pdf,则输入密码,新版好像没有这个属性
# doc._initialize_password()
# 创建pdf资源管理器 来管理共享资源
resource = PDFResourceManager()
# 参数分析器
laparam=LAParams()
# 创建一个聚合器
device = PDFPageAggregator(resource,laparams=laparam)
# 创建pdf页面解释器
interpreter = PDFPageInterpreter(resource,device)
# 用来计数页面,图片,曲线,figure,水平文本框等对象的数量
num_page, num_image, num_curve, num_figure, num_TextBoxHorizontal = 0, 0, 0, 0, 0
# 获取页面的集合
for page in PDFPage.get_pages(fp):
num_page += 1 # 页面增一
# 使用页面解释器来读取
interpreter.process_page(page)
# 使用聚合器来获取内容
layout = device.get_result()
# 这里layout是一个LTPage对象 里面存放着 这个page解析出的各种对象 一般包括LTTextBox, LTFigure, LTImage, LTTextBoxHorizontal 等等 想要获取文本就获得对象的text属性,
for x in layout:
if isinstance(x,LTImage): # 图片对象
num_image += 1
if isinstance(x,LTCurve): # 曲线对象
num_curve += 1
if isinstance(x,LTFigure): # figure对象
num_figure += 1
if isinstance(x, LTTextBoxHorizontal): # 获取文本内容
num_TextBoxHorizontal += 1 # 水平文本框对象增一
# 保存文本内容
with open(txt_path, 'a',encoding='UTF-8',errors='ignore') as f:
results = x.get_text()
f.write(results + '\n')# 读取股票代码信息
rawdata = pd.read_excel(r'E:\大学课程相关\大二下学期\5 数据科学导论\文本分析\stockcode.xlsx', sheet_name=0, dtype={'stockcode': str})
# 获取DataFrame的行数
num_rows = len(rawdata)
print(num_rows)
# 年份范围从2010到2022
years = [str(year) for year in range(2010, 2023)]
for iloc in range(num_rows):
code = rawdata.loc[iloc, 'stockcode']
print(code)
# 遍历固定的年份范围
for year in years:
print(year)
pdf_path = load_pdf(code, year) + ".pdf"
txt_path = load_pdf(code, year) + ".txt"
# 检查对应的TXT文件是否已经存在,如果存在则跳过转换步骤
if not os.path.exists(txt_path):
print(pdf_path)
parsePDF(pdf_path, txt_path)
else:
print("TXT文件已存在,跳过转换步骤。")3、计算指标
import jieba
import pandas as pd
from collections import Counter
import re
import os
import numpy as np
def remove_negations(words):
negations = set(['非','别','不','没','无','忽','莫','否','没有','还没','毫无','无需','无关'])
filtered_words = []
skip = False
for word in words:
if word in negations:
skip = True
elif skip:
skip = False
else:
filtered_words.append(word)
return filtered_words
def word_frequency_by_category(text, stopwords, custom_dict, categories):
words = jieba.cut(text)
filtered_words = [word for word in words if word not in stopwords]
filtered_words = remove_negations(filtered_words)
filtered_words = [word for word in filtered_words if word in custom_dict]
category_freq = Counter()
for word in filtered_words:
for category, words_in_category in categories.items():
if word in words_in_category:
category_freq[category] += 1
break
return category_freq
def preprocess_text(text):
# 去除非中文字符和数字
text = re.sub(r'[^\u4e00-\u9fa5]', '', text)
text = re.sub(r'\d+', '', text)
return text
# 计算指标函数
def calculate_indicators(df):
# 计算数字化关键词在上市企业 i 第 t 年的年报中的词频
df['ln(hkit+1)'] = np.log1p(df['词频'].astype(float))
# 计算第 t 年上市企业年报文本总数 Qt
total_reports = df.groupby('year').size().reset_index(name='Qt')
df = pd.merge(df, total_reports, on='year', how='left')
# 计算第 t 年包含第 k 个数字化关键词的年报文本数量 qkt
keyword_counts = df.groupby(['year']).size().reset_index(name='qkt')
df = pd.merge(df, keyword_counts, on='year', how='left')
# 计算包含第 k 个数字化关键词的逆文本频率 ln(Qt/qkt+1)
df['ln(Qt/qkt+1)'] = np.log1p(df['Qt'] / (df['qkt'] + 1).astype(float))
# 计算指标 kit =∑k[ln(hkit+1)*ln(Qt/qkt+1)]
df['k'] = df['ln(hkit+1)'] * df['ln(Qt/qkt+1)']
kit = df.groupby('year')['k'].sum().reset_index(name='kit')
df = pd.merge(df, kit, on='year', how='left')
return df
# 读取停用词表
with open('stopwords.txt', 'r', encoding='utf-8') as f:
stopwords = set(f.read().splitlines())
# 读取自定义词典
custom_dict = set([
"人工智能", "商业智能", "图像理解投资决策辅助系统", "智能数据分析", "智能机器人",
"机器学习", "深度学习", "语义搜索", "生物识别技术", "人脸识别", "语音识别",
"身份验证", "自动驾驶", "自然语言处理","大数据", "数据挖掘", "文本挖掘",
"数据可视化", "异构数据", "征信", "增强现实", "混合现实", "虚拟现实","云计算",
"流计算", "图计算", "内存计算", "多方安全计算", "类脑计算", "绿色计算",
"认知计算", "融合架构", "亿级并发", "EB级存储", "物联网", "信息物理系统","区块链",
"数字货币", "分布式计算", "差分隐私技术", "智能金融合约","移动互联网", "工业互联网",
"移动互联", "互联网医疗", "电子商务", "移动支付", "第三方支付", "NFC支付",
"智能能源", "B2B", "B2C", "C2B", "C2C", "O2O", "网联", "智能穿戴",
"智慧农业", "智能交通", "智能医疗", "智能客服", "智能家居", "智能投顾",
"智能文旅", "智能环保", "智能电网", "智能营销", "数字营销", "无人零售",
"互联网金融", "数字金融", "Fintech", "金融科技", "量化金融", "开放银行"
])
# 自定义不同板块及其对应的词语
categories = {
"人工智能技术": {"人工智能", "商业智能", "图像理解投资决策辅助系统", "智能数据分析", "智能机器人", "机器学习", "深度学习", "语义搜索", "生物识别技术", "人脸识别", "语音识别", "身份验证", "自动驾驶", "自然语言处理"},
"大数据技术": {"大数据", "数据挖掘", "文本挖掘","数据可视化", "异构数据", "征信", "增强现实", "混合现实", "虚拟现实"},
"云计算技术":{"云计算", "流计算", "图计算", "内存计算", "多方安全计算", "类脑计算", "绿色计算", "认知计算", "融合架构", "亿级并发", "EB级存储", "物联网", "信息物理系统"},
"区块链技术":{"区块链", "数字货币", "分布式计算", "差分隐私技术", "智能金融合约"},
"数据技术运用":{"移动互联网", "工业互联网", "移动互联", "互联网医疗", "电子商务", "移动支付", "第三方支付", "NFC支付", "智能能源", "B2B", "B2C", "C2B", "C2C", "O2O", "网联", "智能穿戴", "智慧农业", "智能交通", "智能医疗", "智能客服", "智能家居", "智能投顾", "智能文旅", "智能环保", "智能电网", "智能营销", "数字营销", "无人零售", "互联网金融", "数字金融", "Fintech", "金融科技", "量化金融", "开放银行"}
}
# 将自定义词典中的词语添加到分词词典中
for word in custom_dict:
jieba.add_word(word)
# 指定年报文本文件夹路径
folder_path = r'C:\Users\leon\data\03 数据科学导论\第二次小组作业数据\年报'
# 创建一个空的 DataFrame 用于存储所有词频统计结果
all_results_df = pd.DataFrame(columns=['code', 'year', '板块', '词频'])
# 定义预处理函数并计算词频
def preprocess_and_calculate(text):
text = preprocess_text(text)
freq_dict = word_frequency_by_category(text, stopwords, custom_dict, categories)
return freq_dict
# 遍历文件夹中的所有txt文件
for filename in os.listdir(folder_path):
if filename.endswith(".txt"):
file_path = os.path.join(folder_path, filename)
code, year_str = filename.split('-')
year = int(year_str[:4]) # 从文件名中提取年份
with open(file_path, 'r', encoding='utf-8') as f:
text = f.read()
# 预处理文本并计算词频
category_freq = preprocess_and_calculate(text)
# 将词频结果存入 DataFrame
df = pd.DataFrame(category_freq.items(), columns=['板块', '词频'])
# 添加股票代码和年份列
df['code'] = code
df['year'] = year
# 调整列的顺序
df = df[['code', 'year', '板块', '词频']]
# 将结果添加到 all_results_df 中
all_results_df = pd.concat([all_results_df, df], ignore_index=True)
# 存储指标数据
all_results_with_indicators = calculate_indicators(all_results_df)
# 根据公司代码和年份分组,保留每个公司每年的唯一一个 kit 数据
unique_kit = all_results_with_indicators.groupby(['code', 'year'])['kit'].first().reset_index()
# 存储带有指标的数据
unique_kit.to_excel('指标构建.xlsx', index=False)
欢迎评论区批评指正!

















 2199
2199

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









