










目录
🌈嗨!我是Filotimo__🌈。很高兴与大家相识,希望我的博客能对你有所帮助。
💡本文由Filotimo__✍️原创,首发于CSDN📚。
📣如需转载,请事先与我联系以获得授权⚠️。
🎁欢迎大家给我点赞👍、收藏⭐️,并在留言区📝与我互动,这些都是我前进的动力!
🌟我的格言:森林草木都有自己认为对的角度🌟。


前言
当人们提及“黑色星期五”,往往会想到各大商店推出的特卖活动。不过,这个概念也被广泛应用于数据科学领域中。这里我们使用了一个名为“black friday sale”(黑色星期五)的数据集,其收集了有关商品销售信息的大量数据,可用于进行市场营销、数据挖掘和机器学习等方面的研究。
该数据集由Kaggle平台上的Mehak Mittal提供,收集了2012年度black friday sale(黑色星期五)期间的购物交易数据。具体而言,数据集中包含了来自一个零售商店的大约54万条交易记录,每条记录包括了以下信息:用户ID、性别、年龄、职业、城市类别、产品ID、产品类别、购买量、单位价格和销售日期等。
一、项目概述
1.1 项目简介
项目名为:黑色星期五画像分析
本项目旨在利用Jupyter编程来分析和呈现黑色星期五购物季的消费行为和趋势。通过对大量的购物数据进行统计和可视化分析,我们将揭示黑色星期五的消费者画像和购物模式,为商家和市场营销人员提供有针对性的策略和决策支持。
1.2 项目背景
黑色星期五是美国传统的购物狂欢日,标志着购物季的开始。消费者通常在此时享受到各种折扣和促销活动,商家也通过此次活动刺激销售和推广产品。随着互联网和电商的发展,黑色星期五变得更加国际化,各个国家和地区都参与其中。购物数据的规模庞大,为深入了解消费者行为和趋势提供了机会。
1.3 项目目标
1. 分析消费者画像:通过购物数据分析,揭示不同人群的消费偏好、购买习惯和兴趣爱好等。比如,不同年龄段、性别和地域的消费者在黑色星期五的购物行为有何异同。
2. 探索购物模式:研究消费者在购物季的消费决策模式、选购行为和购物渠道等,帮助商家了解消费者思维和行动路径,优化产品定位和促销策略。
3. 可视化数据分析:利用Jupyter的强大可视化能力,将分析结果以图表、图像和动态展示的形式呈现,使数据更具直观性和可理解性,帮助更多人快速理解和应用分析结果。
二、数据分析
2.1 导入库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib.patches as mpatches
import matplotlib
plt.rcParams["font.sans-serif"]=["SimHei"]#设置字体为黑体以支持中文显示
plt.rcParams["axes.unicode_minus"]=False # 解决负号显示问题
import plotly.graph_objects as go
import plotly.express as px
from plotly.subplots import make_subplots
from plotly.offline import init_notebook_mode,iplot
import warnings
warnings.filterwarnings("ignore") # 忽略警告信息说明:我是在学校机房,使用jupyter(ml)操作的,导入库时发现缺少了plotly库,然后我在jupyter文件夹下打开了cmd命令行,输入了pip install plotly -i https://pypi.tuna.tsinghua.edu.cn/simple/,成功下载了plotly库,这里使用的是清华镜像源。
2.2 数据基本信息
(1)导入数据
df = pd.read_csv("C:/Users/Administrator/Desktop/black friday sale/train.csv") # 从CSV文件中读取数据并存储在DataFrame中
df # 打印DataFrame中的数据截图:
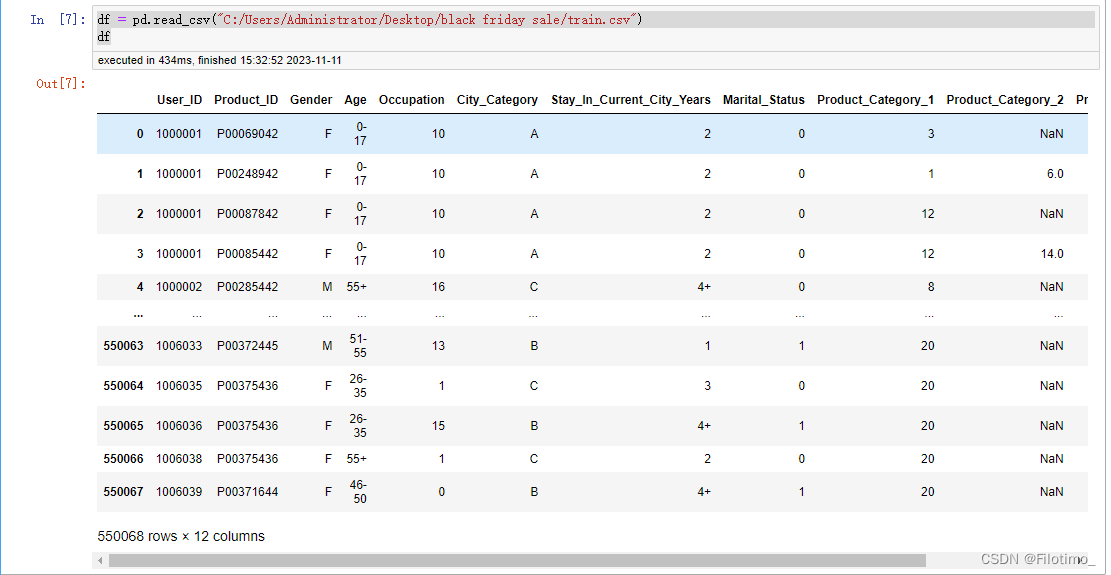
说明:这里要下载我上传的资源"black friday sale(黑色星期五)数据集",然后要修改一下代码中的文件路径。
(2)基本信息
df.shape # 显示DataFrame的形状(行数和列数)df.dtypes # 显示每一列的数据类型df.isnull().sum()#统计每一列的空值数量df.info()#显示DataFrame的基本信息,包括索引、数据类型和内存信息(3)缺失值可视化
import missingno
df.isna().sum()/df.shape[0]#计算每一列的缺失值占比missingno.matrix(df) #绘制缺失值矩阵图
plt.show()#显示图形missingno.bar(df, color="blue")#绘制缺失值条形图
plt.show()#显示图形说明:我操作时缺少了missingno库,然后我仍在jupyter文件夹下打开了cmd命令行,输入pip install missingno -i https://pypi.tuna.tsinghua.edu.cn/simple/,成功下载了missingno库,这里使用的还是清华镜像源。
(4)总信息
df["User_ID"].nunique()#统计"User_ID"列的唯一值数量df["Product_ID"].nunique()#统计"Product_ID"列的唯一值数量sum(df["Purchase"])#计算"Purchase"列的总和(5)商品类别
df["Product_Category_1"].nunique()#统计"Product_Category_1"列的唯一值数量df["Product_Category_2"].nunique()#统计"Product_Category_2"列的唯一值数量三、画像分析
3.1 画像1:消费金额Top10
df1 = df.groupby("User_ID")["Purchase"].sum().reset_index()#按照用户分组,计算消费金额总和
df2 = df1.sort_values("Purchase", ascending=False)#按照消费金额进行降序排列
df2["User_ID"] = df2["User_ID"].apply(lambda x: "id_" + str(x))#将User_ID转换成字符串格式,并加上前缀"id_"df2 #打印处理后的数据框df2#使用Plotly创建条形图
fig = px.bar(df2[:10],#仅显示前10名用户
x="User_ID",#x轴为User_ID
y="Purchase",#y轴为Purchase
text="Purchase")#设置显示文本为Purchase列的值
fig.show()#显示图形这段代码首先按照用户ID分组,计算了每个用户的消费总金额,并按照消费总金额进行降序排列。然后使用Plotly库创建了一个条形图,显示了消费金额排名前10的用户。

从图中可以看到,id_1004277的用户消费最高,达到了1千多万。
3.2 画像2:高频消费Top10
df3 = df.groupby("User_ID").size().reset_index()#按照用户分组,计算每个用户的购买次数
df3.columns = ["User_ID", "Number"]#重命名列名为"User_ID"和"Number"
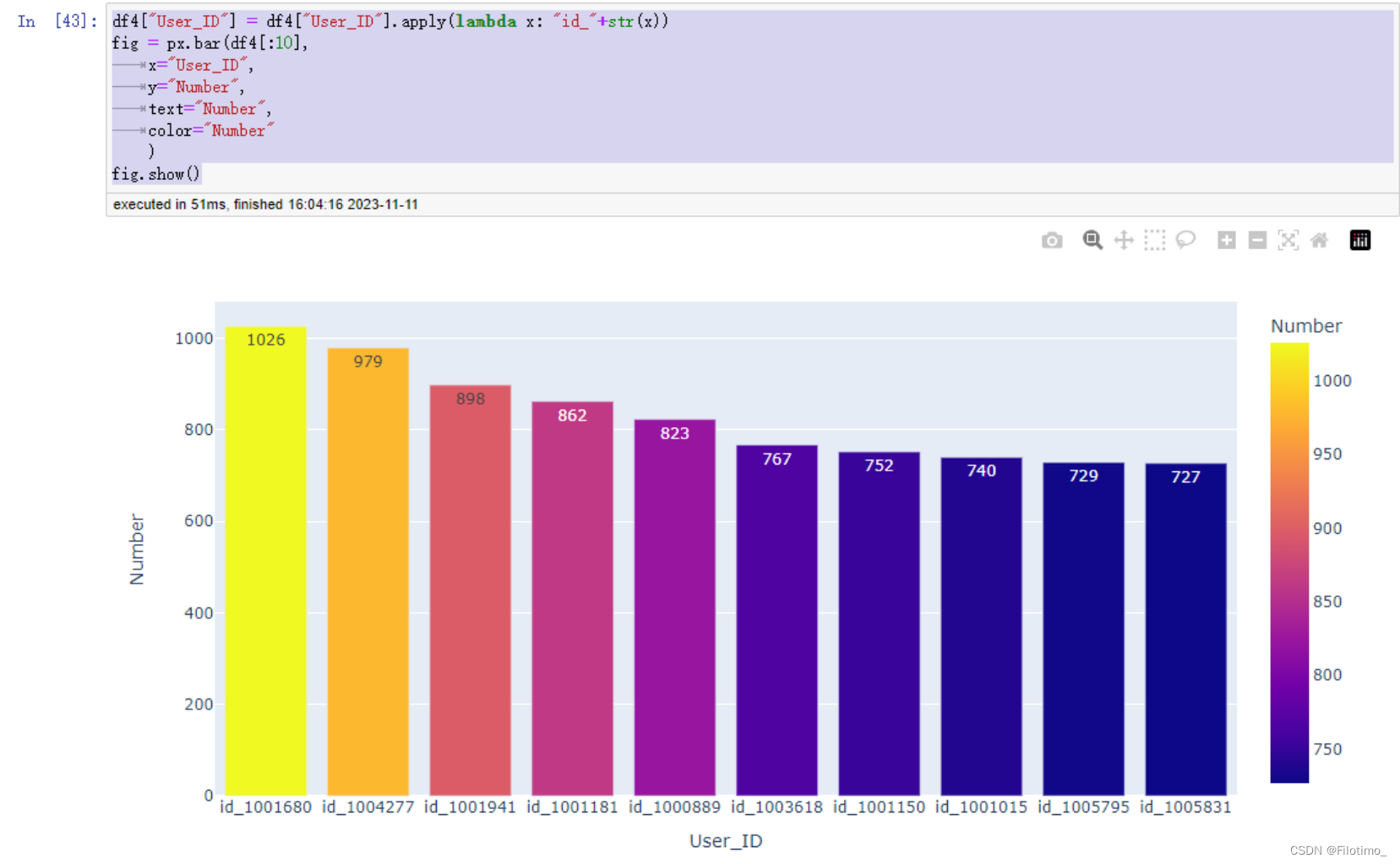
df4 = df3.sort_values("Number", ascending=False)#按照购买次数进行降序排列
df4.head(10)#显示排名前10的高频消费用户信息df4["User_ID"] = df4["User_ID"].apply(lambda x: "id_" + str(x))#将User_ID转换成字符串格式,并加上前缀"id_"
#使用Plotly创建带颜色的条形图
fig = px.bar(df4[:10],#仅显示前10名用户
x="User_ID",#x轴为User_ID
y="Number",#y轴为Number(购买次数)
text="Number",#设置显示文本为Number列的值
color="Number")#设置颜色为Number列的值
fig.show()#显示图形这段代码首先按照用户ID分组,计算了每个用户的购买次数,并按照购买次数进行降序排列。然后使用Plotly库创建了一个带颜色的条形图,显示了购买次数排名前10的用户。不同的购买次数会用不同的颜色表示。
3.3 画像3:人均消费金额Top10
df5 = pd.merge(df2, df4) # 合并df2和df4,根据User_ID字段进行合并
df5["Average"] = df5["Purchase"] / df5["Number"] # 计算人均消费金额,即每位用户的总消费金额除以购买次数
df5["Average"] = df5["Average"].apply(lambda x: round(x, 2)) # 将人均消费金额保留两位小数
df5.head() # 显示合并后的数据框df5的前几行,可选# 使用Plotly创建散点图
fig = px.scatter(df5,
x="User_ID", # x轴为User_ID
y="Average", # y轴为Average(人均消费金额)
color="Average") # 按照人均消费金额进行颜色编码
fig.show() # 显示散点图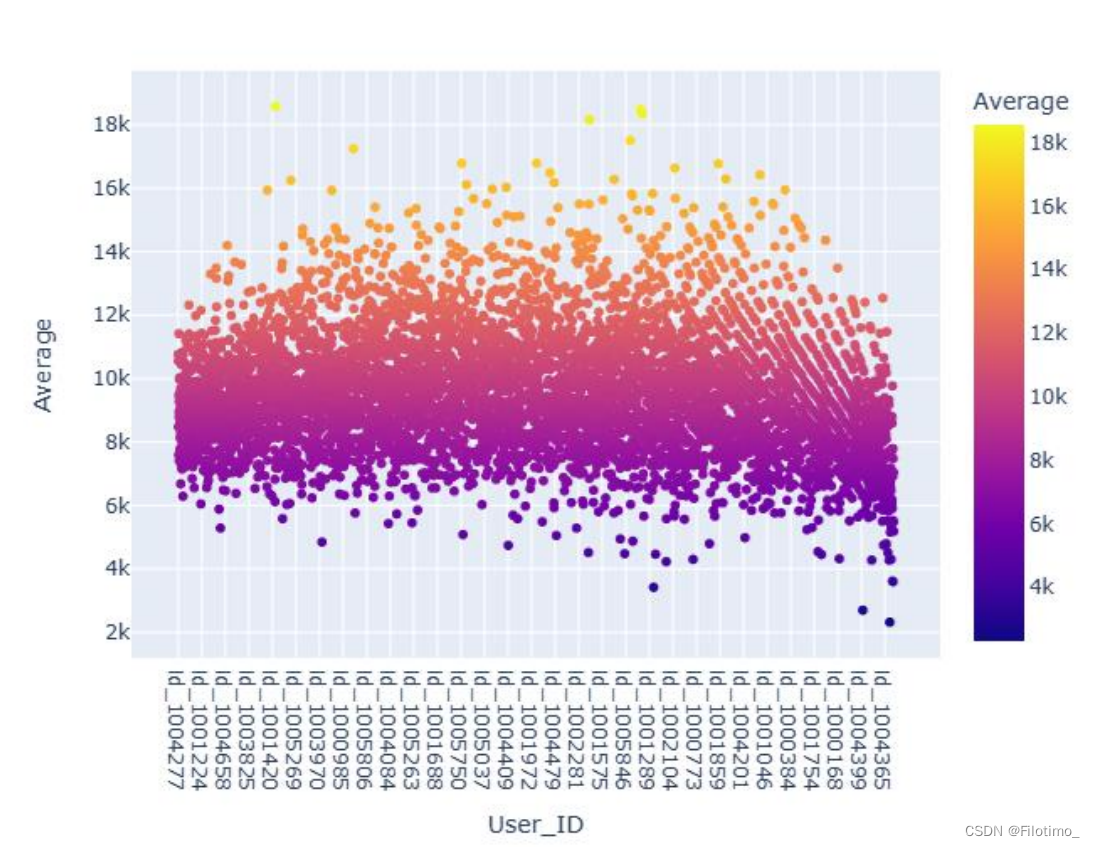
# 使用Plotly创建小提琴图
px.violin(df5["Average"]) # 传入人均消费金额数据绘制小提琴图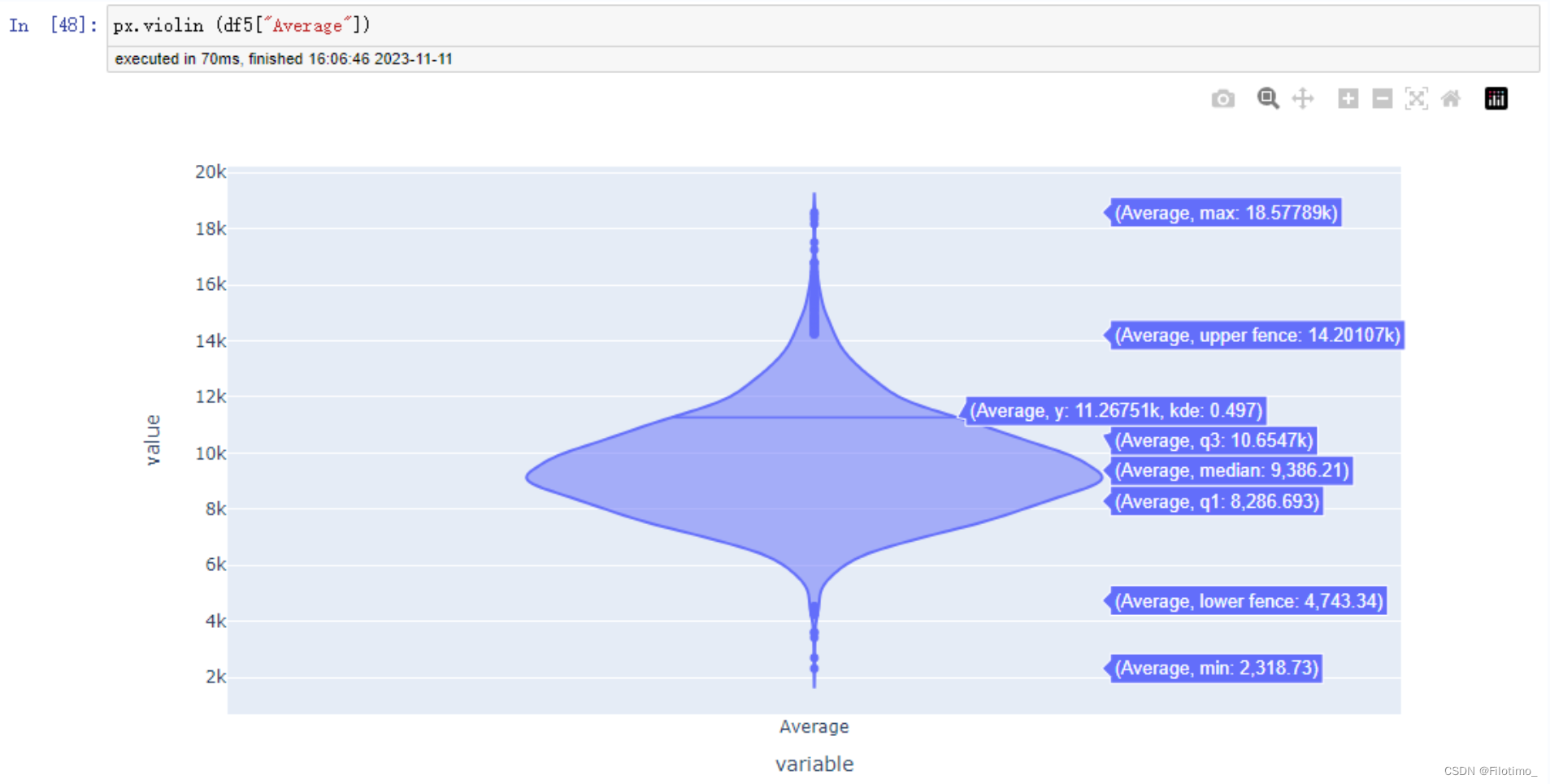
这段代码首先将df2和df4两个数据框根据User_ID字段进行合并,得到df5。然后计算了每位用户的人均消费金额,即每位用户的总消费金额除以购买次数,并保留两位小数。接着使用Plotly库创建了一个人均消费金额Top10的散点图,图中的颜色表示不同的人均消费金额。还使用Plotly库创建了一个小提琴图,展示整体的人均消费金额分布情况。
从上面的两张图中可以分析出,用户的平均消费金额大约是在8k至10k之间。
3.4 画像4:男女消费对比
# 对数据进行分组,计算不同性别的用户数量和消费金额总和
df6 = df.groupby("Gender").agg({"User_ID": "nunique", "Purchase": "sum"}).reset_index()
df6labels = df6['Gender'].tolist() # 将性别转换为标签列表
# 创建包含两个子图的饼图
fig = make_subplots(rows=1,
cols=2,
subplot_titles=["男女消费次数", "男女消费金额"],
specs=[[{'type': 'domain'}, {'type': 'domain'}]]
)
# 添加第一个饼图,显示男女用户的消费次数
fig.add_trace(go.Pie(
labels=labels,
values=df6['User_ID'].tolist(),
name='UserID'),
row=1,
col=1
)
# 添加第二个饼图,显示男女用户的消费金额
fig.add_trace(go.Pie(
labels=labels,
values=df6['Purchase'].tolist(),
name=' Purchase'),
1, 2)
fig.show() # 显示图形这段代码首先对数据按照性别进行分组,使用agg函数计算了不同性别的用户数量和消费金额总和,并将结果保存在df6中。然后将性别转换为标签列表。接着使用Plotly库的make_subplots函数创建一个包含两个子图的饼图对象,分别用于展示男女用户的消费次数和消费金额。使用go.Pie函数创建了两个饼图的数据,并通过add_trace方法将它们添加到对应的子图中。最后使用fig.show()方法显示图形。
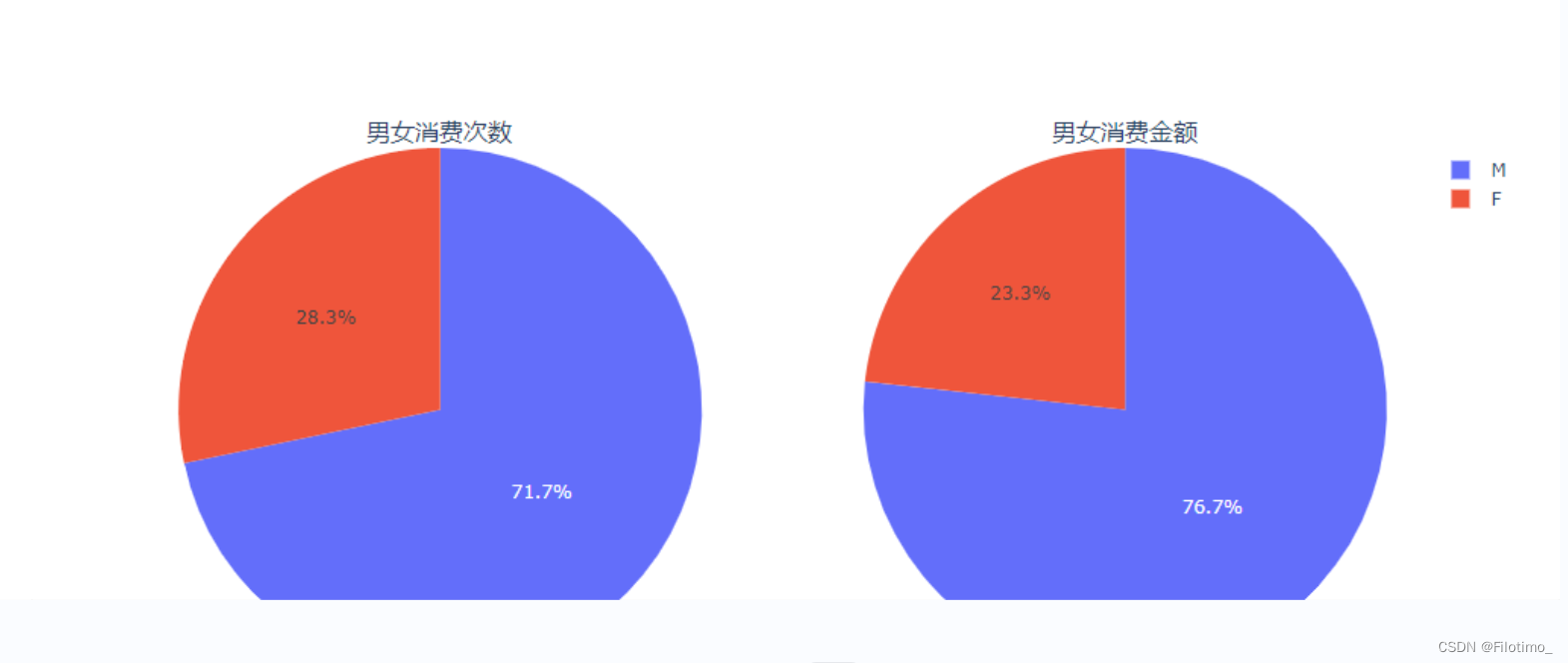
从图中(F红色代表女性,M蓝色代表男性)可以看到,男性是消费的主力军。
3.5 画像5:不同年龄的消费人数和金额
df7 = df.groupby("Age").agg({"User_ID" :"nunique" ,"Purchase" :"sum"}).reset_index()
df7labels = df7['Age'].tolist()
fig = make_subplots(rows=1, cols=2,
subplot_titles=["不同age消费次数","不同age消费金额"],
specs=[[{'type':'domain'}, {'type':'domain'}]]
)
fig.add_trace(go.Pie(
labels=labels,
values=df7['User_ID'].tolist(),
name='UserID'),
row=1,
col=1
)
fig.add_trace(go.Pie(
labels=labels,
values=df7['Purchase'].tolist(),
name='Purchase'),
row=1,
col=2
)
fig.update_layout(height=500, width=800)
fig.show()这段代码首先对数据按照年龄进行分组,使用agg函数计算了不同年龄段的用户数量和消费金额总和,并将结果保存在df7中。然后将年龄转换为标签列表。接着使用Plotly库的make_subplots函数创建一个包含两个子图的饼图对象,分别用于展示不同年龄段用户的消费次数和消费金额。使用go.Pie函数创建了两个饼图的数据,并通过add_trace方法将它们添加到对应的子图中。最后使用fig.update_layout方法更新图形的高度和宽度,并使用fig.show()方法显示图形。

从上面两张图可以看到,26-25这个年龄段消费占比最高,这可能是因为这个年龄段的人,大多都已经有了一个稳定的工作、稳定的收入,所以他们可以放心大胆的去消费。
3.6 画像6:不同性别+年龄的消费人数和金额
# 对数据进行分组,计算不同性别和年龄段的用户数量和消费金额总和
df8 = df.groupby(["Gender", "Age"]).agg({"User_ID": "nunique", "Purchase": "sum"}).reset_index()
df8# 创建树状图,展示不同性别和年龄段的用户消费金额
fig = px.treemap(df8, path=[px.Constant("all"), "Gender", "Age"], values="Purchase")
fig.update_traces(root_color="lightskyblue") # 设置树状图的根节点颜色
fig.update_layout(margin=dict(t=30, l=20, r=25, b=30)) # 更新图形的边距
fig.show() # 显示图形这段代码首先对数据按照性别和年龄段进行分组,使用agg函数计算了不同性别和年龄段的用户数量和消费金额总和,并将结果保存在df8中。接着,使用px.treemap函数创建一个树状图,设置了路径为[“all”, “Gender”, “Age”],表示树状图中的层级关系。在树状图中,不同性别和年龄段将根据消费金额的大小显示为不同的颜色和大小。根据图的展示,可以直观地比较不同性别和年龄段的用户消费金额。最后,使用fig.show()函数显示图形。
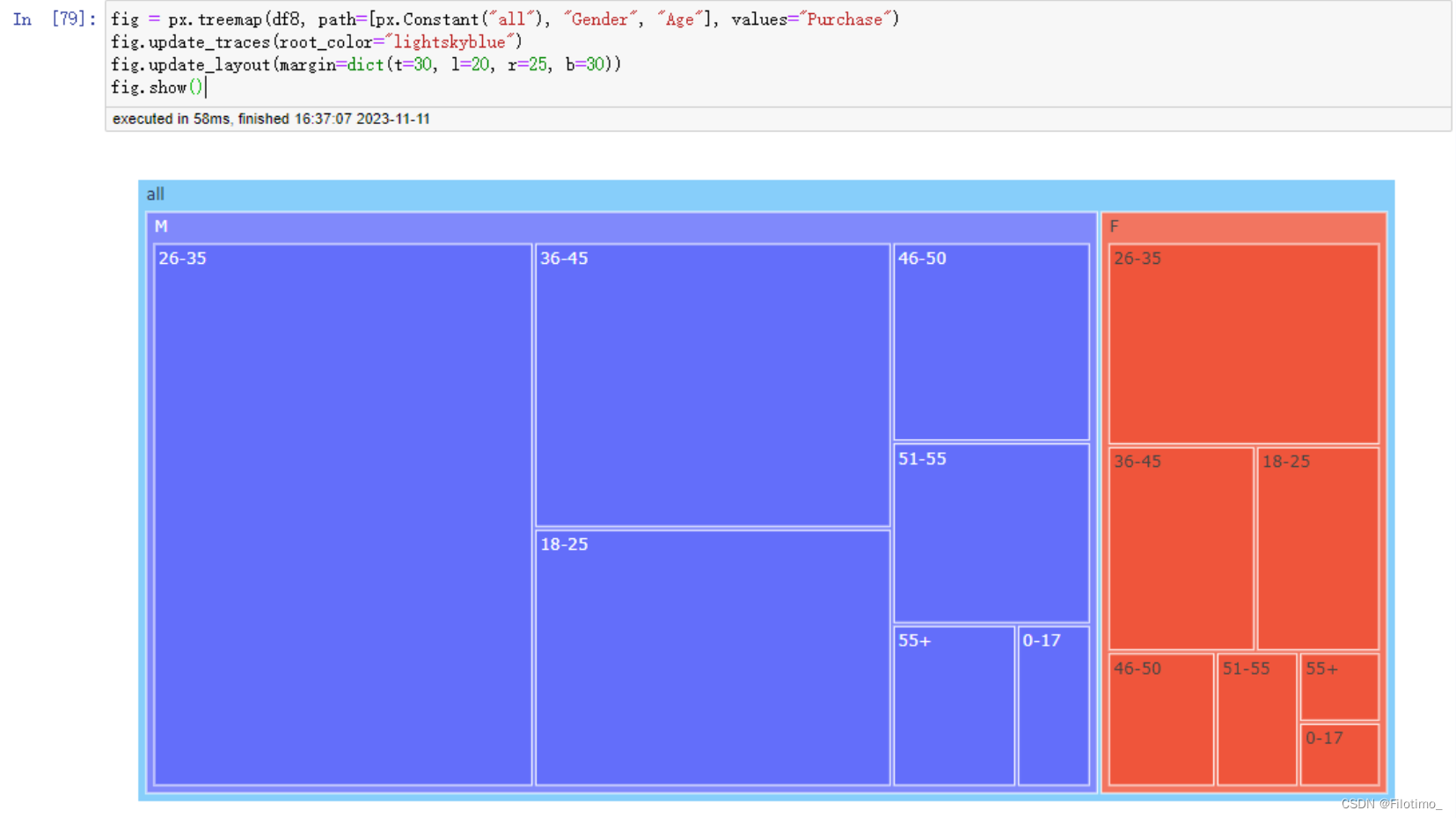
3.7 画像7:不同城市,年龄消费金额
# 对数据进行分组,计算不同城市和年龄段的用户数量和消费金额总和
df9 = df.groupby(["City_Category", "Age"]).agg({"User_ID": "nunique", "Purchase": "sum"}).reset_index()
df9# 创建条形图,展示不同城市和年龄段的消费金额
fig = px.bar(df9, x="City_Category", y="Purchase", color="Age", barmode="group", text="Purchase")
fig.update_layout(title="不同城市不同年龄段的消费金额") # 设置图形标题
fig.show() # 显示图形这段代码首先对数据按照城市和年龄段进行分组,使用agg函数计算了不同城市和年龄段的用户数量和消费金额总和,并将结果保存在df9中。接着,使用px.bar函数创建一个条形图,设置了x轴为城市类别,y轴为消费金额,颜色编码为年龄段,以及分组模式为"group",以展示不同城市和年龄段的消费金额。使用update_layout方法设置了图形标题为"不同城市不同年龄段的消费金额"。最后使用fig.show()方法显示图形。

从3个城市来看,26-35这个年龄段的人一直是消费的主力军。
3.8 画像8:不同婚姻状态的消费次数和金额
# 对数据进行分组,计算不同婚姻状况的用户数量和消费金额总和
df10 = df.groupby(["Marital_Status"]).agg({"User_ID":"nunique", "Purchase":"sum"}).reset_index()
df10# 将婚姻状况的数值映射为对应的标签
df10["Marital_Status"] = df10["Marital_Status"].map({0:"未婚",1:"已婚"})# 创建饼图,展示婚姻状况对应的消费金额
fig = px.pie(names=df10["Marital_Status"], values=df10["Purchase"])
fig.update_traces(textposition='inside', textinfo='percent+label') # 设置标签的位置和信息
fig.show() # 显示图形这段代码首先对数据按照婚姻状况进行分组,使用agg函数计算了不同婚姻状况的用户数量和消费金额总和,并将结果保存在df10中。然后,通过map方法将婚姻状况的数值映射为对应的标签,将0映射为"未婚",将1映射为"已婚"。接着,使用px.pie函数创建一个饼图,设置了信心为婚姻状况标签,值为对应的消费金额。使用update_traces方法设置标签的位置为内部,并展示百分比和标签信息。最后使用fig.show()方法显示图形。
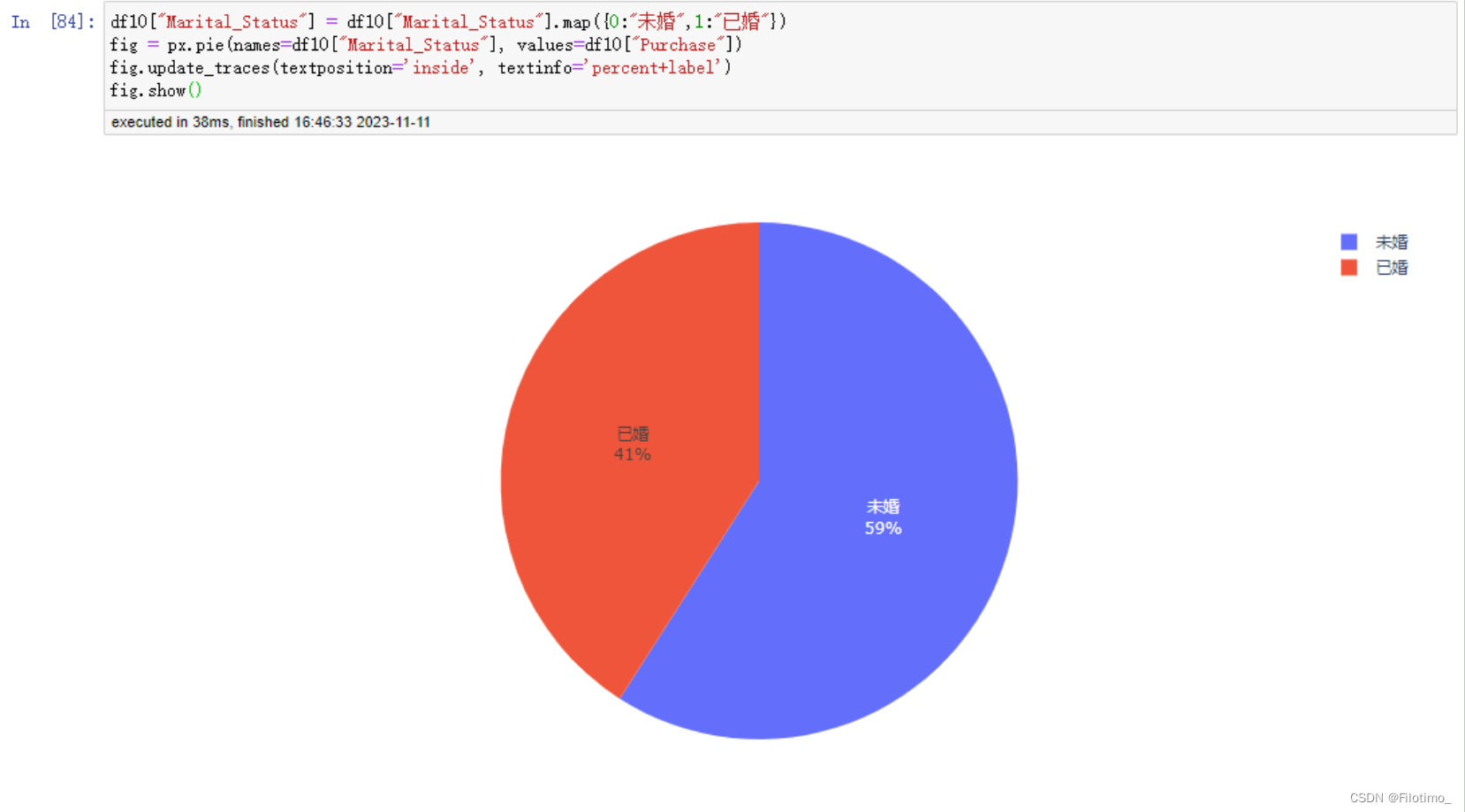
从图中可以看到,在未婚情况下,消费的力度更大。
3.9 画像9:城市停留时间
# 创建小提琴图,展示不同居住年限的购买金额分布
fig = px.violin(df,
y="Purchase",
color="Stay_In_Current_City_Years")
# 对数据进行分组,计算不同居住年限的用户数量和购买金额总和
df11 = (df.groupby(["Stay_In_Current_City_Years"])
.agg({"User_ID":"nunique", "Purchase":"sum"})
.reset_index())
df12 = df11.sort_values("User_ID", ascending=False)
df12# 将不同居住年限的阶段转换为列表
stages = df12["Stay_In_Current_City_Years"].tolist()
# 创建漏斗图,展示不同居住年限的用户数量情况
fig = px.funnel_area(values=df12["User_ID"].tolist(),
names=stages)
fig.show()这段代码首先使用px.violin函数创建了一个小提琴图,设置y轴为购买金额,颜色编码为居住年限,以展示不同居住年限下购买金额的分布情况。接着,通过对数据进行分组和聚合得到了不同居住年限的用户数量和购买金额总和,并将结果保存在df11和df12中。然后,通过sort_values方法对df12进行排序,按用户数量降序排列。在接下来的代码中,将不同居住年限的阶段转换为列表,并使用px.funnel_area函数创建了一个漏斗图,用于展示不同居住年限的用户数量情况。最后使用fig.show()方法显示图形。

从图中可以发现,在一个城市居住了1-2年的用户是消费的主力。
3.10 画像10:销售额Top20商品
# 对数据按产品ID进行分组,计算每个产品的销售额总和
df13 = df.groupby(["Product_ID"]).agg({"Purchase" :"sum"}).reset_index()
# 将销售额转换为以万为单位,并且保留两位小数
df13["Purchase"] = df13["Purchase"].apply(lambda x: round(x / 10000, 2))
# 按销售额降序排列产品
df13.sort_values("Purchase", ascending=False, inplace=True)
df13# 创建条形图,展示销售额排名前10的产品
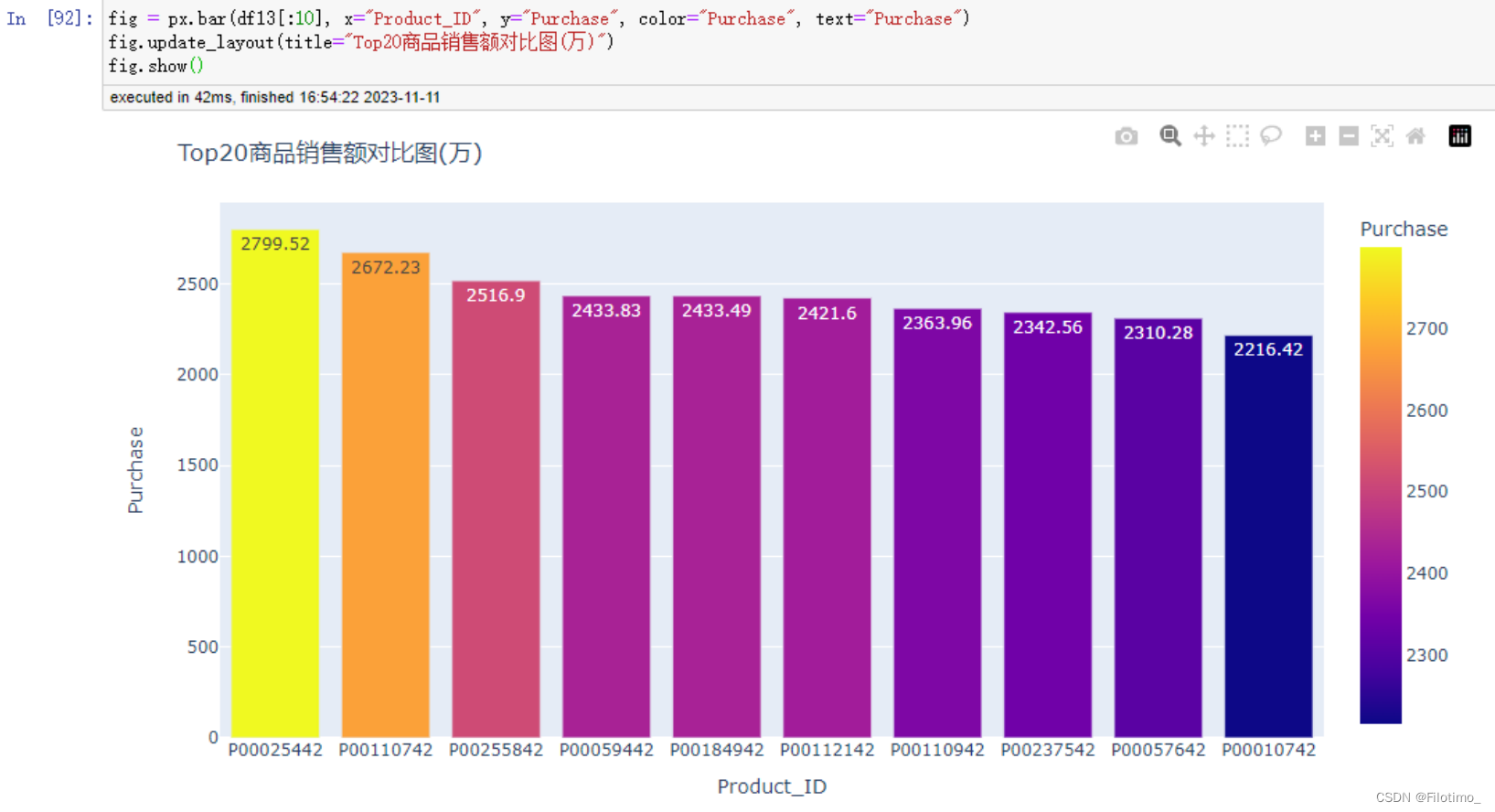
fig = px.bar(df13[:10], x="Product_ID", y="Purchase", color="Purchase", text="Purchase")
fig.update_layout(title="Top20商品销售额对比图(万)")
fig.show()
这段代码首先对数据按产品ID进行分组,使用agg函数计算了每个产品的销售额总和,并将结果保存在df13中。然后,通过apply和lambda函数将销售额转换为以万为单位,并且保留两位小数。接着,使用sort_values方法将产品按销售额降序
3.11 画像11:二八法则
# 计算销售额排名前20%的产品数量
top20 = int(df13["Product_ID"].nunique() * 0.2)
top20# 计算销售额排名前20%的产品的销售额总和占总销售额的比例
top20_sales_percentage = sum(df13[:top20]["Purchase"]) / sum(df13["Purchase"])
top20_sales_percentage在这段代码中,首先计算了销售额排名前20%的产品数量,然后通过取前20%的产品销售额总和除以总销售额,计算得出了销售额排名前20%的产品所占总销售额的比例。

从计算结果可以发现,销售额排名前20%的产品占据了总销售额的73%,大致上是符合"二八法制"的。
3.12 画像12:商品种类
# 对数据按产品类别进行分组,并计算每个产品类别的销售额总和
df14 = df.groupby(["Product_Category_1"]).agg({"Purchase": "sum"}).reset_index()
# 创建饼图,展示每个产品类别的销售额占比
fig = px.pie(names=df14["Product_Category_1"],
values=df14["Purchase"],
hole=0.5)
fig.update_traces(
textposition='inside', # 将标签放置在饼图内部
textinfo='percent+label' # 标签信息包括百分比和标签
)
fig.show()
# 创建箱线图,展示不同产品类别的销售额分布情况
px.box(df,
x="Product_Category_1",
y="Purchase",
color="Product_Category_1")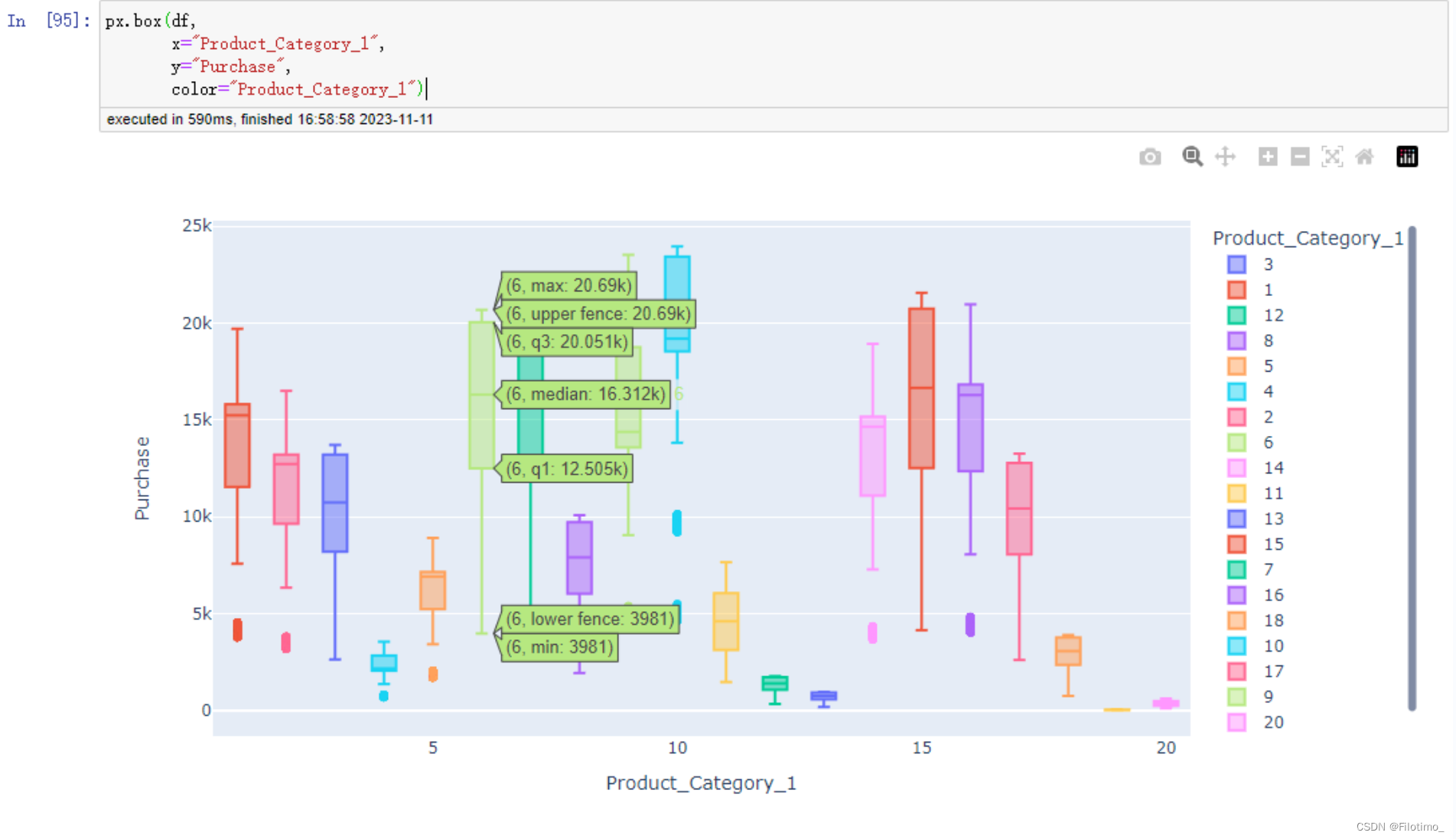
在这段代码中,首先对数据框按照"Product_Category_1"进行分组,然后使用agg函数计算每个产品类别的销售额总和,并将结果保存在df14数据框中。接下来,使用px.pie函数创建了一个饼图,其中names参数指定了产品类别的名称,values参数指定了对应的销售额,hole参数设置了饼图的内部空洞大小。使用update_traces方法将饼图的标签放置在内部,并且标签信息包括百分比和标签文本。最后使用fig.show()显示了该饼图。接下来,使用px.box函数创建了一个箱线图。在箱线图中,x参数指定了产品类别的名称,y参数指定了销售额的值,而color参数则用于给不同的产品类别区分颜色。最后,使用px.box函数创建的箱线图可以显示不同产品类别的销售额分布情况。
总结
文中所使用的数据集可用于广泛的数据研究目的。例如,我们可以利用该数据集来分析特定消费群体的购物行为。通过数据挖掘和机器学习技术,我们可以发现哪些消费者更可能购买某个产品、哪些消费群体对某一个产品类别更感兴趣等。这些信息可以向商家提供宝贵的市场营销策略,例如发布定向广告、优化产品设计、提高产品质量等。此外,还可以用该数据集研究不同城市、不同年龄和收入阶层等人群对各种产品类型的需求有何不同,了解市场的潜在需求。
















 4549
4549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











