






python代码:基于DDPG(深度确定性梯度策略)算法的售电公司竞价策略研究
关键词:DDPG 算法 深度强化学习 电力市场 发电商 竞价
说明文档:完美复现英文文档
主要内容:
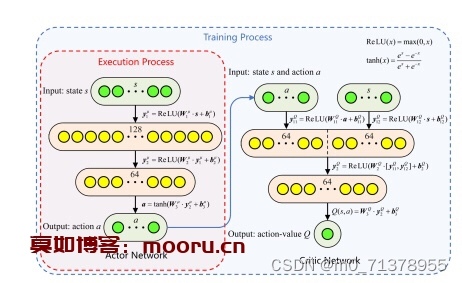
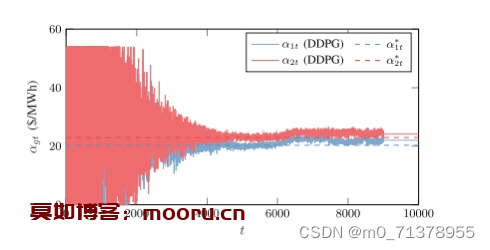
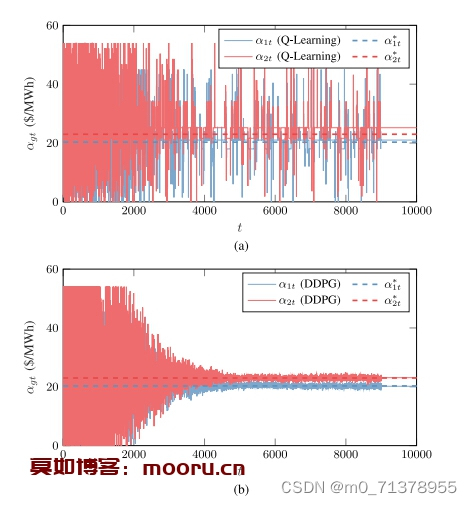
代码主要研究的是多个售电公司的竞标以及报价策略,属于电力市场范畴,目前常用博弈论方法寻求电力市场均衡,但是此类方法局限于信息完备的简单市场环境,难以直观地反映竞争性的市场环境,因此,本代码通过深度确定性梯度策略算法(DDPG)对发电公司的售价进行建模,解决了传统的RL算法局限于低维离散状态空间和行为空间,收敛性不稳的问题,实验表明,该方法比传统的RL算法具有更高的精度,即使在不完全信息环境下也能收敛到完全信息的纳什均衡。
此外,该方法通过定量调整发电商的耐心参数,可以直观地反映不同的默契合谋程度,是分析市场策略的有效手段。
目前深度强化学习非常火热,很容易出成果,非常适合在本代码的基础上稍微加点东西,即可形成自己的成果,非常适合深度强化学习方向的人学习!

ID:69180 647355363555
647355363555















 1181
1181











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









