







在day12下创建一个名为08-request的使用的代码文件
requests作用:requests从本机(本地网络IP地址)向目标网站服务器发送请求,目标网站服务器给本机返回响应结果。
模块(包、库)的使用都需要导包
import requests
访问服务器,得有目标网站网址,以百度为例
URL = 'https://www.baidu.com/'
发送请求,得到响应结果
requests模块有个get方法,get方法中有个参数叫做url,让url等于URL(指定的网址),我们后期讲函数的时候再解释为什么这样写,变量名叫做response,response变量中存储了目标网站服务器返回给我们的所有信息
response = requests.get(url=URL)
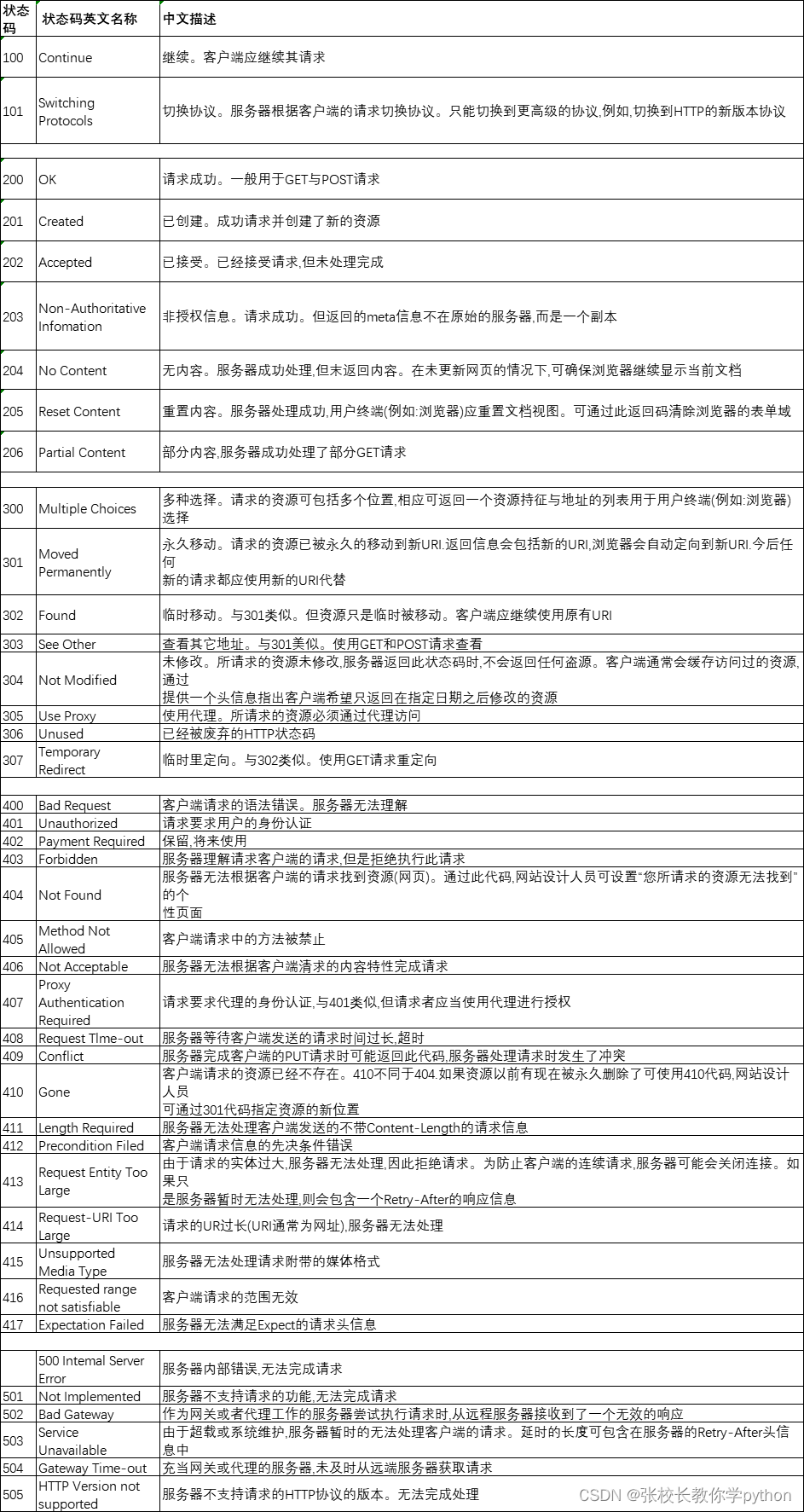
print(response.status_code)
查看状态码:status_code。 利用变量response去调用status_code(状态码是整数)
打印结果为200,表示爬虫可用
状态码可以查看此时目标网站服务器的状态
200:表示爬虫可用(此处的网站不一定没发现你是爬虫)。
403:表示服务器知道我们的请求,但是拒绝了我们(服务器发现我们是爬虫,拒绝了我们)
我们访问的网页都是挂在云平台的,有那么几家公司提供云平台,如阿里云、腾讯云、百度云……就像我们使用的阿里云盘、百度云盘能够在对应服务上提供的空间中存放东西,云服务器是这么一回事。首先需要在云端花钱买一台服务器;其次将网页挂上去。但是如果你想让其他用户通过网络访问到你挂在这台服务器上的网页,这个过程你得花钱买流量。我们正常访问网页,是需要消耗对方花钱买的流量,爬虫也是通过网络访问对方的服务器,爬虫的执行效率是很高的,一分钟几百个几千个页面浏览完了,访问一个页面花点浏览,访问一个页面花点流量,确实有点气人。因为这个所有网站所有服务器都是讨厌爬虫这个东西的。所以就有了反爬虫机制,会用各种形式来阻碍这个爬虫来访问这个网站。但是没关系,后面会讲如何针对这个反爬虫机制来做相应的破解,相应的措施
400:网页没找到。
500:服务器崩了。
我们默认写的程序都是单线程爬虫,也可以写多线程爬虫。我们先记住这四个状态码如果还遇到其他的状态码就从图片中找一找,看看的对应的中文原因是什么(图片上没有的话上百度搜搜这个状态码怎么去解决、处理)
查看字符串类型的网页源代码:text
(网页源代码就是拿 html、css、 Javascript三要素组成的)
print(response.text) #得到百度网页源代码
1、我们现在打开百度网页来对比一下。注意:打开百度网页后不要登录账号,如果用户登录记得退出登录,任意界面右键选择“显示网页源代码”,打开新的界面。正常情况下,requests请求到的字符串类型的网页源代码,就是此处打开的页面
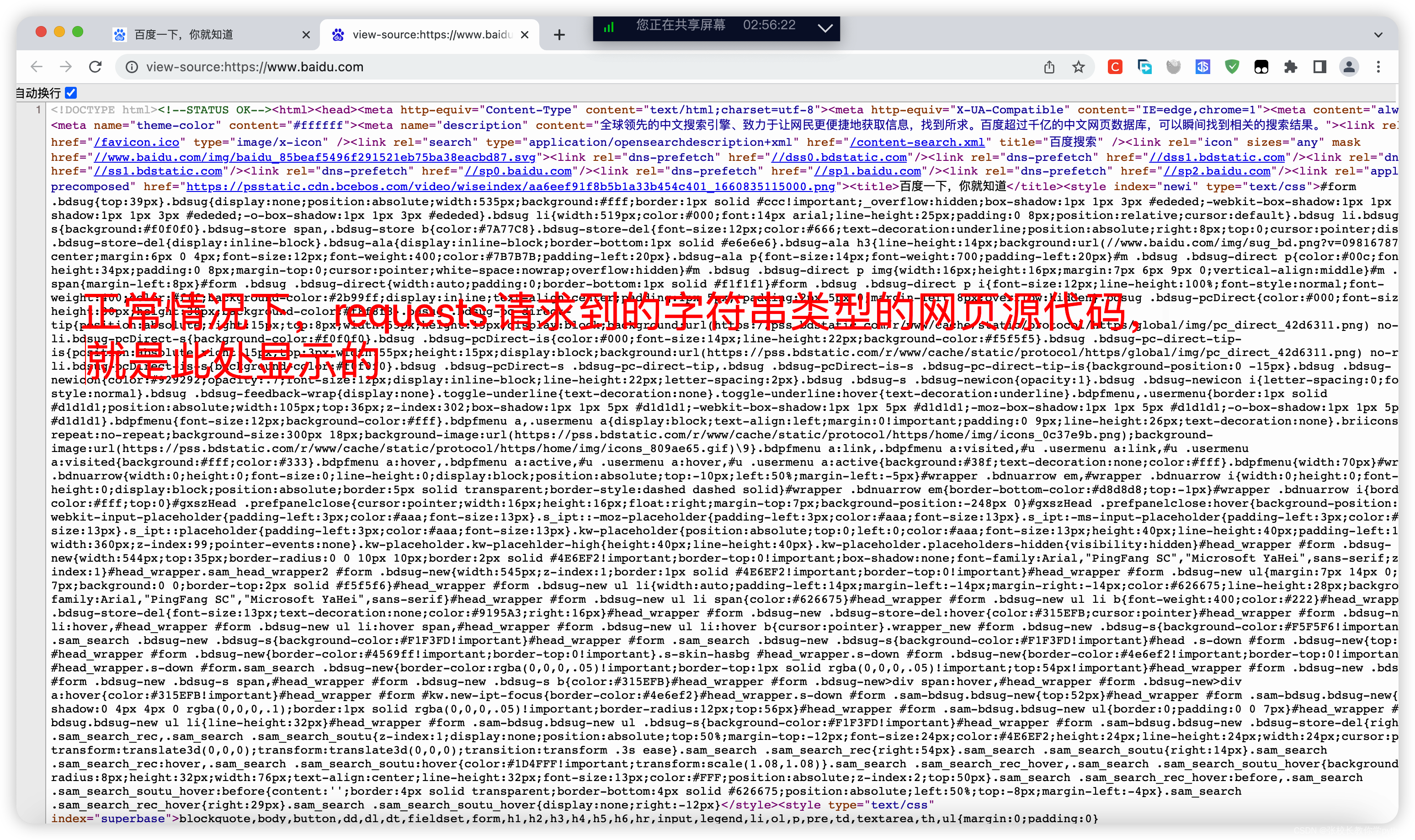
2、为什么Pycharm打印出来的就一点点? 而在浏览器上却有上千行代码,这是为什么呢?这就回到了前面说的即使状态码为200,但是此处百度的网站发现你是爬虫,故意使坏

3、 这应该怎么办呢? --> 在发送请求前,我们加点猛料
有个字典Headers,找到键User-Agent对应的值,这个值不用我们记,知道从哪找就行了,后期用到了再从网站上找就好了。
简单回顾一下,字典中的元素是以键值对(Key: value)形式存在,字典中的键必须是不可变的数据类型,键是解释说明的作用,字典中的值可以是任意数据,值是最终想要的数据。
怎么找呢? 打开百度首页,右键 “检查” --> 点击上方“Network” -->
在
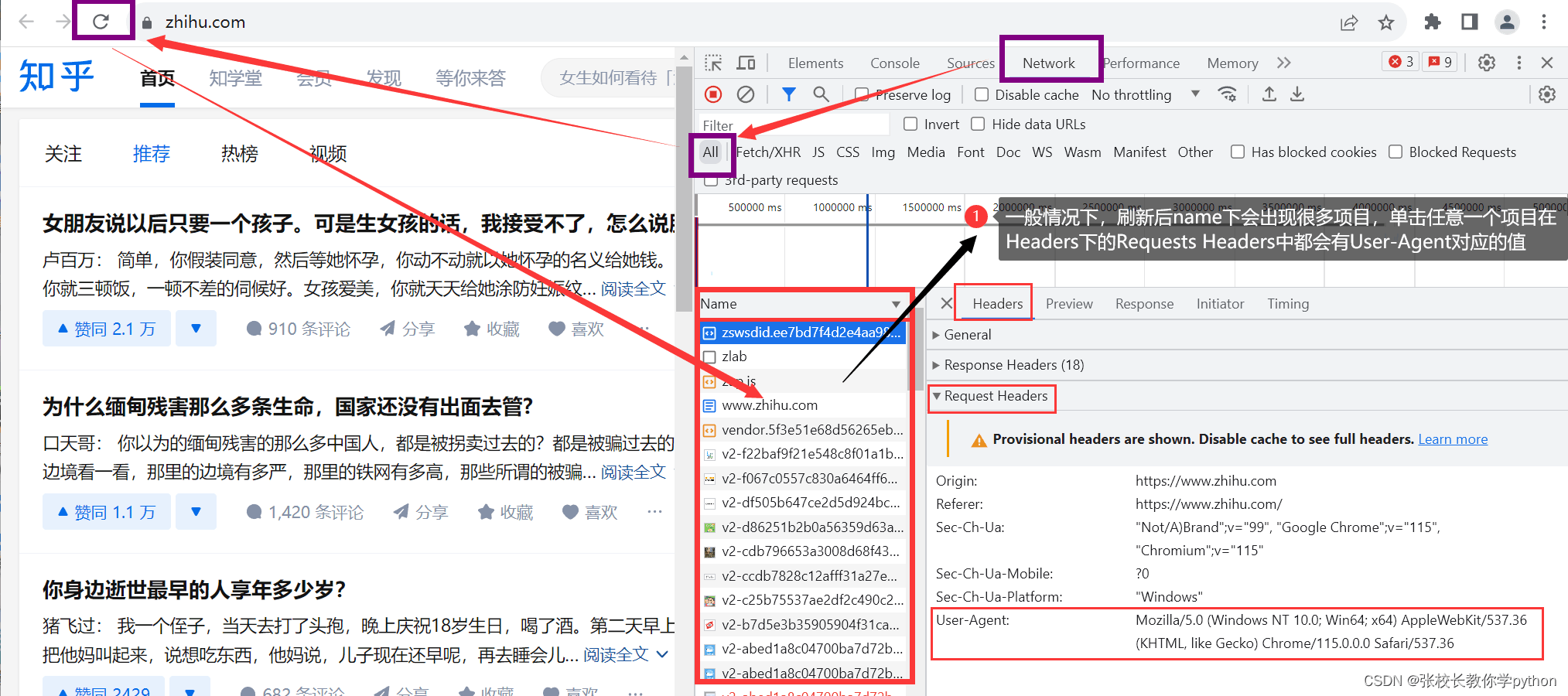
点击Network时本来是空白的,刷新后会加载出一些文件,这是网页加载过程中加载出来的资源文件,在Header下找到
www.baidu.com并打开
最后一段代码就是我们找的键User-Agent对应的值,我们将其复制放到字典headers中。
Headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36'
}
headers:标头,将headers赋给爬虫,是为了将爬虫伪装成浏览器(让你的爬虫更像一个真的浏览器)
User-Agent:对应的值包含了浏览器、操作系统的各项信息。如果没有User-Agent,就相当于赤裸裸的去访问对方服务器,只要对方有反爬虫机制,就能发现你是爬虫。
将字典Headers放到requests.get这个方法中,让其携带这个参数get方法有个参数headers,让其等于Headers(记得将前面的response = requests.get(url=URL)以及相关内容注释掉)
response = requests.get(url=URL, headers=Headers)
print(response.text)
打印对比发现网页源代码一致,那么到现在网站使坏的问题已经解决
接下来,我们换一个网站中国新闻网请求访问
URL = 'https://www.chinanews.com/'
(相应的,把URL = 'https://www.baidu.com/'注释掉)
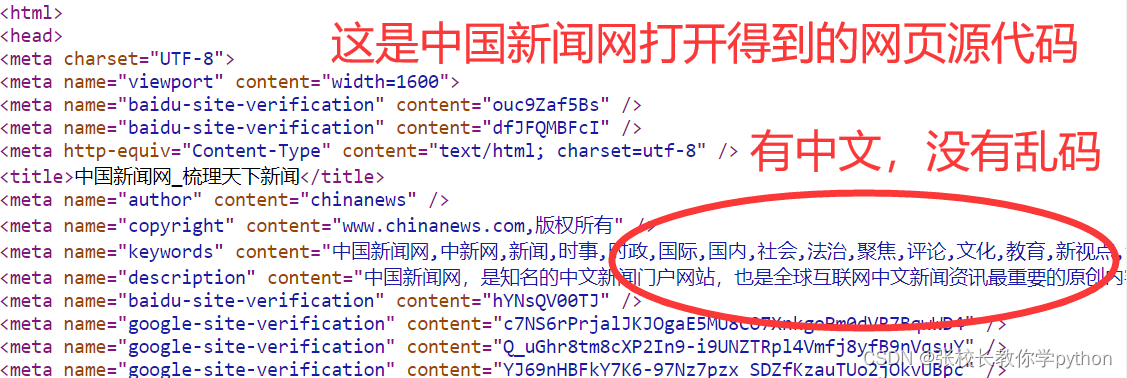
打印发现Pycharm中显示中国新闻网的网页源代码没有中文!!!一个中文网站网页源代码没有中文?!有些网站爬的过程中,拿到源代码会乱码,就是因为这些稀奇古怪的符号是中文乱码。

怎么解决呢?
如果拿到的源代码出现乱码,从网页源代码中找到编码方式,拿过来改变原来的编码即可。在打印网页源代码前, 在输出区ctrl + f调出搜索框,搜索charset 显示什么就是什么,例如下面的utf-8
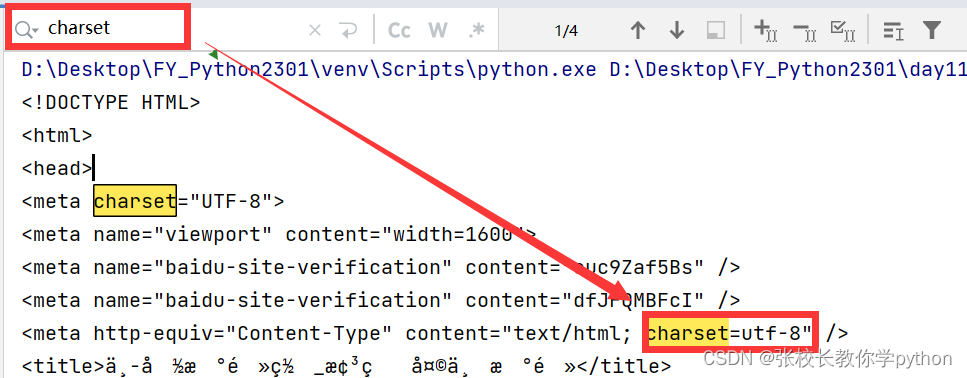
在打印网页源代码前添加下面代码即可解决乱码问题,
response.encoding = 'utf-8'
说了那么久,感觉挺复杂的?总代码如下所示:
import requests
Headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36'
}
# URL = 'https://www.baidu.com/'
URL = 'https://www.chinanews.com/'
# response = requests.get(url=URL)
response = requests.get(url=URL, headers=Headers)
# print(response.status_code)
response.encoding = 'utf-8'
print(response.text)
我们来理一理哈,我们先获取的是百度的网页源代码,由于没有伪装(没有用User-Agent),对方有反爬虫机制,发现我们是爬虫,遭到百度网站使坏的情况,我们就在打印网页源代码前把自己做个伪装,调用了字典Headers(因为这个字典里面含有键User-Agent,它对应的值包含了浏览器、操作系统的各项信息),将headers等于Headers赋给爬虫,将爬虫伪装成浏览器,也就是让我们的爬虫更像一个浏览器。(重点是找到键User-Agent对应的值)
为了防止我们后面爬取其他网页的源代码出现这样的情况,我们要记得伪装自己。
其次是获取中国新闻网的网页源代码,出现了没有中文并且乱码的情况。由于编码方式不同,所以我们需要拿到网页源代码中的编码方式,再套用过来即可。此过程在print输出框位置ctrl + f调出搜索框搜索charset拿到网页源代码的编码方式。(重点是拿到网页源代码的编码方式)
encoding参数的作用是使计算机能够识别不同的数据格式,从而使数据具有可操作性。换句话说,encoding参数,就是指一系列用于编码或解码数据的参数,即将一个字符串或文件进行编码,使其不受其他影响。
指定编码方式的目的是告诉 Python 如何将文件中的字节解码为字符。如果你没有指定编码方式,Python 将使用默认的编码方式(在大多数情况下是 ASCII 编码)。如果文件使用的编码方式与你指定的编码方式不同,Python 可能无法正确解码文件中的字符,导致乱码问题。
可以通过指定 encoding 参数来告诉 Python 如何将文件中的字节解码为字符。UTF-8 是一种常用的字符集(character set),可以表示大多数语言中的字符。它采用可变长度的编码方式,能够有效地表示各种字符。
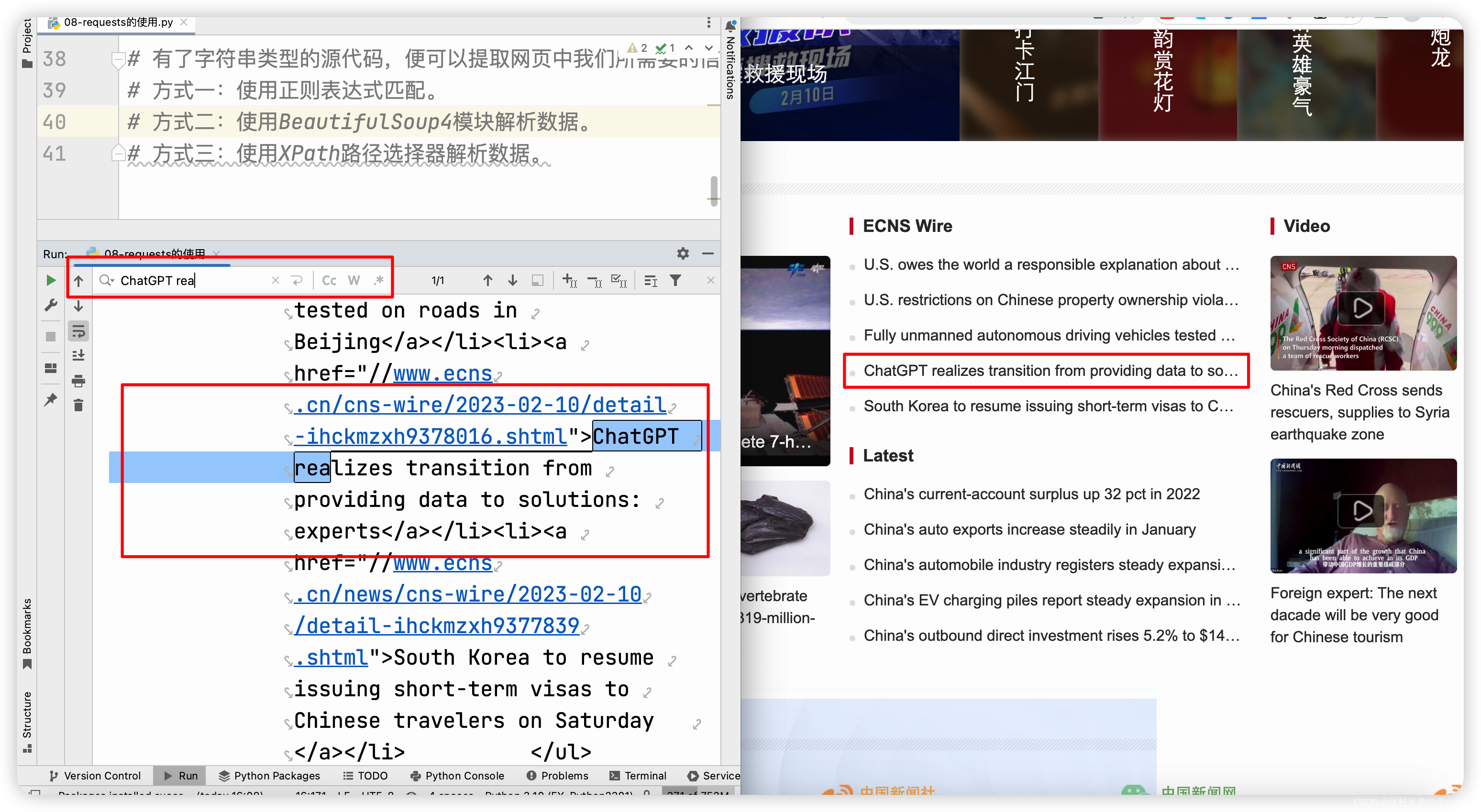
简单看一下(中国新闻网):我们在搜索框搜索网页中的敏感字眼,就能在控制台找到相应的资源以及在相应的网页中快速拿到相应的信息

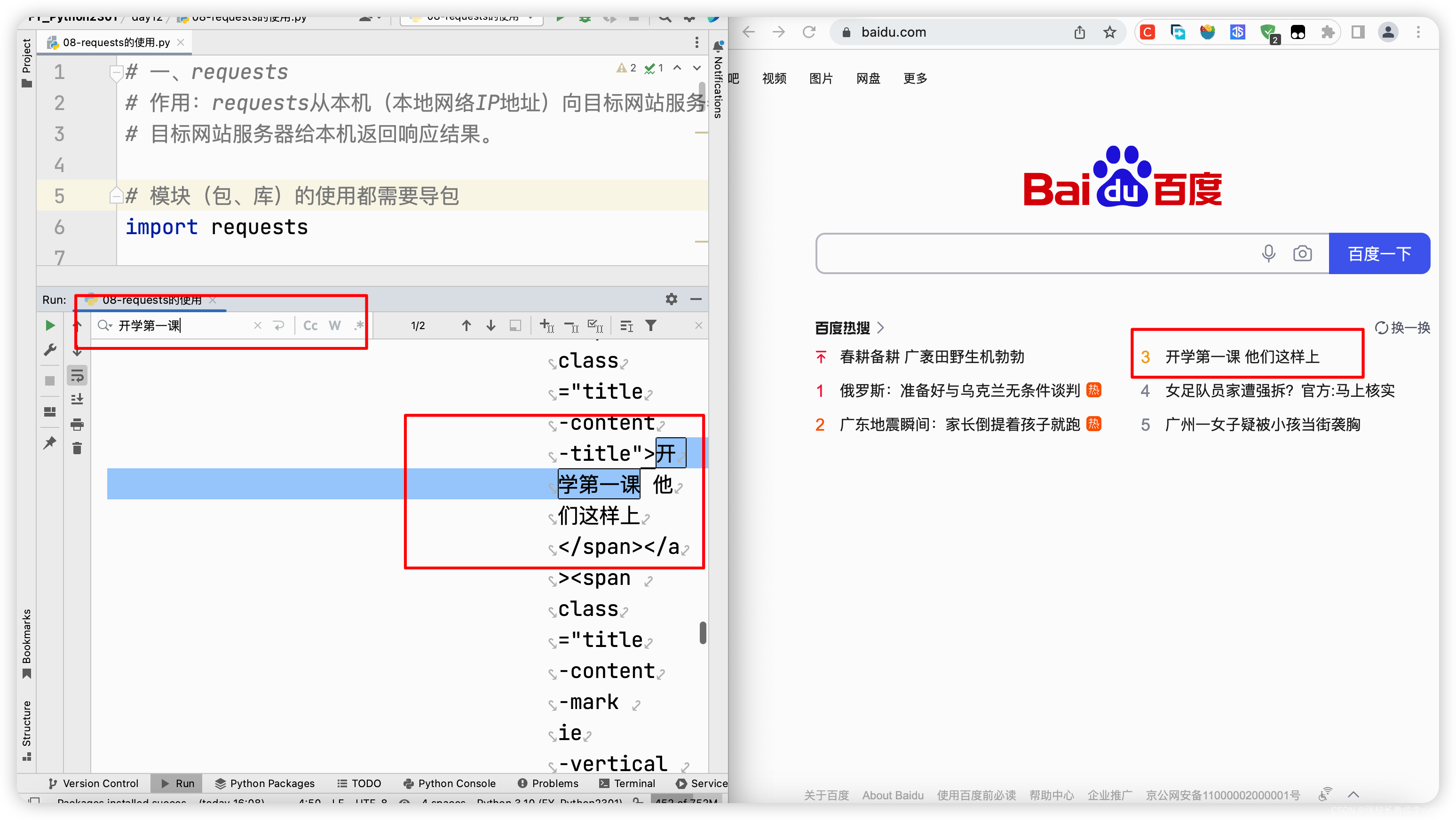
简单看一下(百度):把response.encoding = ‘utf-8’ 注释掉,因为获取百度网页源代码时并没有出现乱码情况
有了字符串类型的源代码,便可以提取网页中我们所需要的信息。
方式一:使用正则表达式匹配。
方式二:使用BeautifulSoup4模块解析数据。
方式三:使用XPath路径选择器解析数据。















 878
878











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









