






 本文展示了如何使用Python的requests库从指定URL获取碳交易数据,并将其保存为CSV文件的过程,目标是每日交易信息,包括日期、市场、成交量和价值。
本文展示了如何使用Python的requests库从指定URL获取碳交易数据,并将其保存为CSV文件的过程,目标是每日交易信息,包括日期、市场、成交量和价值。
代码:
import requests
import csv
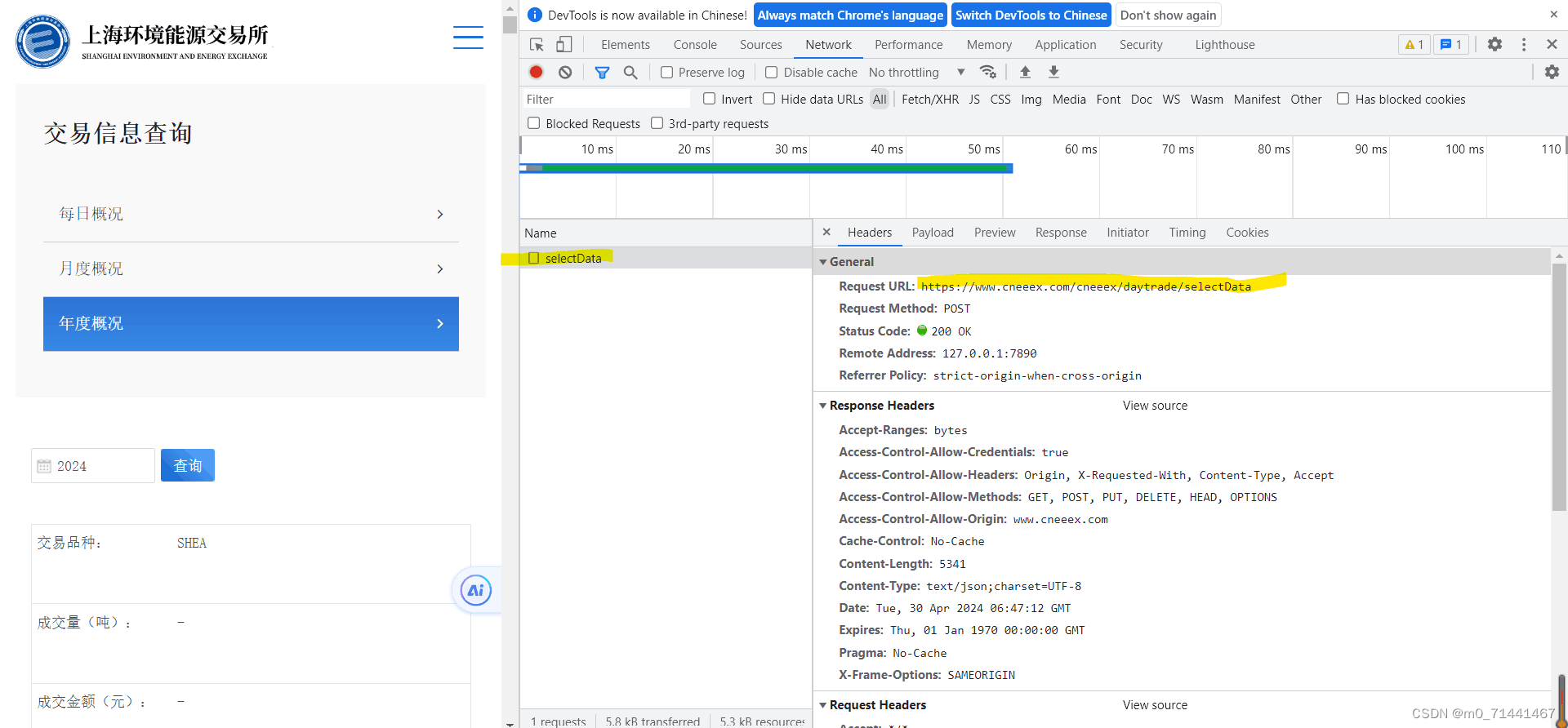
url = "https://www.cneeex.com/cneeex/daytrade/selectData"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Referer': 'https://www.cneeex.com/cneeex/daytrade/detail?SiteID=122'
}
cookies = {
'UniqueID': 'aCSm1XkwJNcsaF6i1714446391597',
'Sites': '_122',
'122_vq': '53'
}
response = requests.post(url=url, headers=headers, cookies=cookies)
# 打印状态码和响应文本,以便调试
print('Status Code:', response.status_code)
print('Response Text:', response.text)
if response.status_code == 200 and response.text:
try:
data = response.json()
print(data)
# 假设response.text就是你显示的JSON格式的数据
csv_file = 'output.csv'
with open(csv_file, mode='w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(['Date', 'Market', 'Volume', 'Value'])
for item in data:
writer.writerow(item)
print(f"Data saved to {csv_file}")
except ValueError as e:
print('Failed to decode JSON:', e)
else:
print('Request failed or returned no data')
运行结果(能响应,但是为空):
这是爬取网页(想要爬取每年的碳交易):















 3188
3188











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









