






引言
1.了解前馈神经网络
1.1前馈神经网络简介
前馈神经网络(FeedforwardNeuralNetwork,FNN)是一种最简单的神经网络结构,广泛应用于各种领域。以下是关于前馈神经网络的详细介绍:
>结构特点:前馈神经网络采用单向多层结构,各神经元分层排列,每个神经元只与前一层的神经元相连,接收前一层的输出,并输出给下一层,各层间没有反馈。这种结构使得信息在网络中只能单向流动,从输入层依次传递到输出层。
>工作原理:在前馈神经网络中,输入层接收外部输入的数据,并将其传递给下一层。隐层(或称为隐藏层、隐含层)位于输入层和输出层之间,负责对输入数据进行非线性变换和特征提取。输出层接收隐层的输出,并将最终的结果输出。在每个神经元中,输入信号和对应的权重进行加权求和,然后经过激活函数进行非线性变换。这样,通过多层神经元的传递,网络可以学习到输入数据的复杂特征,并最终输出相应的结果。
1.2前馈神经网络类型
前馈神经网络可以根据其结构和特性进一步细分为多种类型。以下是一些常见的前馈神经网络类型:
>单层前馈神经网络:这是最简单的人工神经网络类型,它仅包含一个输出层。输出层节点的值(即输出值)是通过将输入值乘以对应的权重值直接得到的。
>多层前馈神经网络:多层前馈神经网络具有一个输入层,一个或多个隐含层,以及一个输出层。每个隐含层都可以对输入模式进行线性分类,但由于多层的组合,最终可以实现对输入模式的较复杂的分类。
>感知器网络:感知器(或感知机)是最简单的前馈网络,主要用于模式分类。感知器网络通过计算加权输入和并应用激活函数(如阈值函数)来产生输出。
>BP神经网络:BP(BackPropaqation)神经网络是一种多层前馈网络,其特点是在训练过程中使用反向传播算法来调整权重,以最小化输出误差。
>RBF神经网络:RBF(RadialBasisFunction)神经网络使用径向基函数作为隐含层的激活函数。这种网络在处理非线性问题和函数逼近方面表现出色。
>卷积神经网络:卷积神经网络具有表征学习能力,能够按其阶层结构对输入信息进行平移不变分类(shift-invariantclassification)。这种网络通过卷积运算,可以有效地减小模型参数量,提取稳定的特征,并且对平移、旋转、缩放等图形变换具有一定的不变性。
本实验研究的前馈神经网络——卷积神经网络,在处理数字信号时深受窗口滤波器的启发。通过这种窗口特性,卷积神经网络能够在输入中学习局部化模式,这不仅使其成为计算机视觉的主轴,而且是检测单词和句子等序列数据中的子结构的理想候选。在本实验中,多层感知器和卷积神经网络被分组在一起,因为它们都是前馈神经网络,并且与另一类神经网络——递归神经网络(RNNs)形成对比,递归神经网络(RNNs)允许反馈(或循环),这样每次计算都可以从之前的计算中获得信息。
2.在Pytorch下分别通过MLP和CNN实现姓氏分类
2.1实验要点
>通过“示例:带有多层感知器的姓氏分类”,掌握多层感知器在多层分类中的应用
>掌握每种类型的神经网络层对它所计算的数据张量的大小和形状的影响
2.2开发环境
Python3.6.7(Pytorch)
2.3实验所需数据来源
https://course.educg.net/3988f8e79b250f1a05f89db3711515df/files/surnames.csv
处理原始数据:
import collections
import numpy as np
import pandas as pd
import re
from argparse import Namespace
args = Namespace(
raw_dataset_csv="/home/jovyan/surnames.csv",
train_proportion=0.7,
val_proportion=0.15,
test_proportion=0.15,
output_munged_csv="/home/jovyan/surnames_with_splits.csv",
seed=1337
)
surnames = pd.read_csv(args.raw_dataset_csv, header=0)
surnames.head()
set(surnames.nationality)
by_nationality = collections.defaultdict(list)
for _, row in surnames.iterrows():
by_nationality[row.nationality].append(row.to_dict())
final_list = []
np.random.seed(args.seed)
for _, item_list in sorted(by_nationality.items()):
np.random.shuffle(item_list)
n = len(item_list)
n_train = int(args.train_proportion*n)
n_val = int(args.val_proportion*n)
n_test = int(args.test_proportion*n)
# Give data point a split attribute
for item in item_list[:n_train]:
item['split'] = 'train'
for item in item_list[n_train:n_train+n_val]:
item['split'] = 'val'
for item in item_list[n_train+n_val:]:
item['split'] = 'test'
# Add to final list
final_list.extend(item_list)
final_surnames = pd.DataFrame(final_list)
final_surnames.split.value_counts()得到

进行最后一步处理:
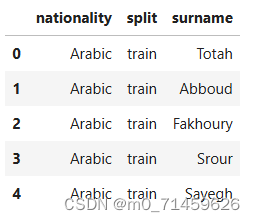
final_surnames.head()
final_surnames.to_csv(args.output_munged_csv, index=False)得到输出结果并生成新的实验数据:
3.代码实现(MLP)
3.1数据预处理
3.1.1初始化
导入所需的库
from argparse import Namespace
from collections import Counter
import json
import os
import string
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from tqdm import tqdm_notebook3.1.2数据集(部分代码)
class SurnameDataset(Dataset):
def __init__(self, surname_df, vectorizer):
self.surname_df = surname_df
self._vectorizer = vectorizer
self.train_df = self.surname_df[self.surname_df.split=='train']
self.train_size = len(self.train_df)
self.val_df = self.surname_df[self.surname_df.split=='val']
self.validation_size = len(self.val_df)
self.test_df = self.surname_df[self.surname_df.split=='test']
self.test_size = len(self.test_df)
self._lookup_dict = {'train': (self.train_df, self.train_size),
'val': (self.val_df, self.validation_size),
'test': (self.test_df, self.test_size)}
self.set_split('train')
# Class weights
class_counts = surname_df.nationality.value_counts().to_dict()
def sort_key(item):
return self._vectorizer.nationality_vocab.lookup_token(item[0])
sorted_counts = sorted(class_counts.items(), key=sort_key)
frequencies = [count for _, count in sorted_counts]
self.class_weights = 1.0 / torch.tensor(frequencies, dtype=torch.float32)利用DataLoader将数据集打包进行后续训练
dataloader = DataLoader(dataset=dataset, batch_size=batch_size,
shuffle=shuffle, drop_last=drop_last)
3.1.3词汇表、向量化器和DataLoader
为了使用字符对姓氏进行分类,我们使用词汇表、向量化器和DataLoader将姓氏字符串转换为向量化的minibatches。
class Vocabulary(object):
def __init__(self, token_to_idx=None, add_unk=True, unk_token="<UNK>"):
if token_to_idx is None:
token_to_idx = {}
self._token_to_idx = token_to_idx
self._idx_to_token = {idx: token
for token, idx in self._token_to_idx.items()}
self._add_unk = add_unk
self._unk_token = unk_token
self.unk_index = -1
if add_unk:
self.unk_index = self.add_token(unk_token) class SurnameVectorizer(object):
def __init__(self, surname_vocab, nationality_vocab):
self.surname_vocab = surname_vocab
self.nationality_vocab = nationality_vocab
def vectorize(self, surname):
vocab = self.surname_vocab
one_hot = np.zeros(len(vocab), dtype=np.float32)
for token in surname:
one_hot[vocab.lookup_token(token)] = 1
return one_hot3.2训练模型
3.2.1模型构建
第一个线性层将输入向量映射到中间向量,并对该向量应用非线性。第二线性层将中间向量映射到预测向量。
class SurnameClassifier(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(SurnameClassifier, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x_in, apply_softmax=False):
intermediate_vector = F.relu(self.fc1(x_in))
prediction_vector = self.fc2(intermediate_vector)
if apply_softmax:
prediction_vector = F.softmax(prediction_vector, dim=1)
return prediction_vector参数部分:
args = Namespace(
# Data and path information
surname_csv="/home/jovyan/surnames_with_splits.csv",
vectorizer_file="vectorizer.json",
model_state_file="model.pth",
save_dir="model_storage/ch4/surname_mlp",
# Model hyper parameters
hidden_dim=300,
# Training hyper parameters
seed=1337,
num_epochs=100,
early_stopping_criteria=5,
learning_rate=0.001,
batch_size=64,
# Runtime options
cuda=False,
reload_from_files=False,
expand_filepaths_to_save_dir=True,
)3.2.2循环训练
利用训练数据,计算模型输出、损失和梯度。然后,使用梯度来更新模型。
获取数据
if args.reload_from_files:
# training from a checkpoint
print("Reloading!")
dataset = SurnameDataset.load_dataset_and_load_vectorizer(args.surname_csv,
args.vectorizer_file)
else:
# create dataset and vectorizer
print("Creating fresh!")
dataset = SurnameDataset.load_dataset_and_make_vectorizer(args.surname_csv)
dataset.save_vectorizer(args.vectorizer_file)
vectorizer = dataset.get_vectorizer()
classifier = SurnameClassifier(input_dim=len(vectorizer.surname_vocab),
hidden_dim=args.hidden_dim,
output_dim=len(vectorizer.nationality_vocab))开始训练
try:
for epoch_index in range(args.num_epochs):
train_state['epoch_index'] = epoch_index
# Iterate over training dataset
# setup: batch generator, set loss and acc to 0, set train mode on
dataset.set_split('train')
batch_generator = generate_batches(dataset,
batch_size=args.batch_size,
device=args.device)
running_loss = 0.0
running_acc = 0.0
classifier.train()
for batch_index, batch_dict in enumerate(batch_generator):
# the training routine is these 5 steps:
# --------------------------------------
# step 1. zero the gradients
optimizer.zero_grad()
# step 2. compute the output
y_pred = classifier(batch_dict['x_surname'])
# step 3. compute the loss
loss = loss_func(y_pred, batch_dict['y_nationality'])
loss_t = loss.item()
running_loss += (loss_t - running_loss) / (batch_index + 1)
# step 4. use loss to produce gradients
loss.backward()
# step 5. use optimizer to take gradient step
optimizer.step()
# -----------------------------------------
# compute the accuracy
acc_t = compute_accuracy(y_pred, batch_dict['y_nationality'])
running_acc += (acc_t - running_acc) / (batch_index + 1)
# update bar
train_bar.set_postfix(loss=running_loss, acc=running_acc,
epoch=epoch_index)
train_bar.update()
train_state['train_loss'].append(running_loss)
train_state['train_acc'].append(running_acc)
展示训练过程:
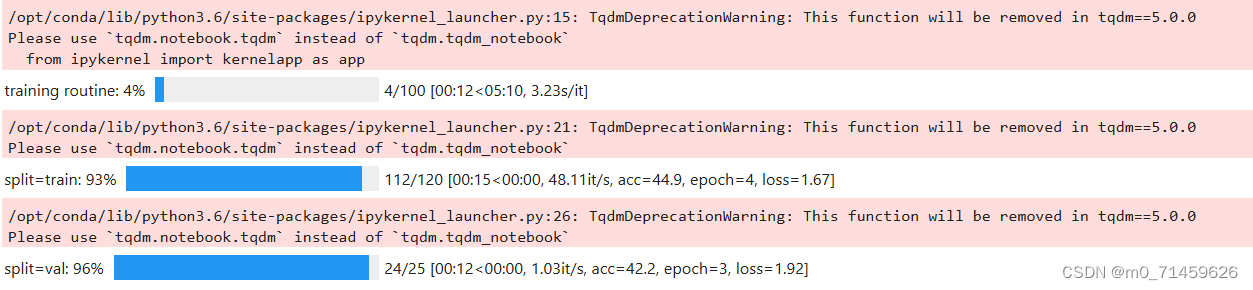
训练结果:
train_state['test_loss'] = running_loss
train_state['test_acc'] = running_acc
print("Test loss: {};".format(train_state['test_loss']))
print("Test Accuracy: {}".format(train_state['test_acc']))
3.3模型预测
def predict_nationality(surname, classifier, vectorizer):
vectorized_surname = vectorizer.vectorize(surname)
vectorized_surname = torch.tensor(vectorized_surname).unsqueeze(0)
result = classifier(vectorized_surname, apply_softmax=True)
probability_values, indices = result.max(dim=1)
index = indices.item()
predicted_nationality = vectorizer.nationality_vocab.lookup_index(index)
probability_value = probability_values.item()
return {'nationality': predicted_nationality, 'probability': probability_value}
new_surname = input("Enter a surname to classify: ")
classifier = classifier.cpu()
prediction = predict_nationality(new_surname, classifier, vectorizer)
print("{} -> {} (p={:0.2f})".format(new_surname,
prediction['nationality'],
prediction['probability']))预测结果:

采用k-best预测并使用另一个模型对它们重新排序:
def predict_topk_nationality(surname, classifier, vectorizer, k=5):
vectorized_surname = vectorizer.vectorize(surname)
vectorized_surname = torch.tensor(vectorized_surname).unsqueeze(dim=0)
prediction_vector = classifier(vectorized_surname, apply_softmax=True)
probability_values, indices = torch.topk(prediction_vector, k=k)
# returned size is 1,k
probability_values = probability_values[0].detach().numpy()
indices = indices[0].detach().numpy()
results = []
for kth_index in range(k):
nationality = vectorizer.nationality_vocab.lookup_index(indices[kth_index])
probability_value = probability_values[kth_index]
results.append({'nationality': nationality,
'probability': probability_value})
return results
new_surname = input("Enter a surname to classify: ")
k = int(input("How many of the top predictions to see? "))
if k > len(vectorizer.nationality_vocab):
print("Sorry! That's more than the # of nationalities we have.. defaulting you to max size :)")
k = len(vectorizer.nationality_vocab)
predictions = predict_topk_nationality(new_surname, classifier, vectorizer, k=k)
print("Top {} predictions:".format(k))
print("===================")
for prediction in predictions:
print("{} -> {} (p={:0.2f})".format(new_surname,
prediction['nationality'],
prediction['probability']))预测结果:

3.4Dropout
在训练过程中,dropout有一定概率使属于两个相邻层的单元之间的连接减弱。
class MultilayerPerceptron(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(MultilayerPerceptron, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x_in, apply_softmax=False):
intermediate = F.relu(self.fc1(x_in))
output = self.fc2(F.dropout(intermediate, p=0.5))
if apply_softmax:
output = F.softmax(output, dim=1)
return output
batch_size = 2 # number of samples input at once
input_dim = 3
hidden_dim = 100
output_dim = 4
# Initialize model
mlp = MultilayerPerceptron(input_dim, hidden_dim, output_dim)
print(mlp)
y_output = mlp(x_input, apply_softmax=False)
describe(y_output)
dropout只适用于训练期间,不适用于评估期间。
4.代码实现(CNN)
4.1数据预处理
4.1.1初始化
导入库
from argparse import Namespace
from collections import Counter
import json
import os
import string
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from tqdm import tqdm_notebook4.1.2数据集
class SurnameDataset(Dataset):
def __init__(self, surname_df, vectorizer):
self.surname_df = surname_df
self._vectorizer = vectorizer
self.train_df = self.surname_df[self.surname_df.split=='train']
self.train_size = len(self.train_df)
self.val_df = self.surname_df[self.surname_df.split=='val']
self.validation_size = len(self.val_df)
self.test_df = self.surname_df[self.surname_df.split=='test']
self.test_size = len(self.test_df)
self._lookup_dict = {'train': (self.train_df, self.train_size),
'val': (self.val_df, self.validation_size),
'test': (self.test_df, self.test_size)}
self.set_split('train')
# Class weights
class_counts = surname_df.nationality.value_counts().to_dict()
def sort_key(item):
return self._vectorizer.nationality_vocab.lookup_token(item[0])
sorted_counts = sorted(class_counts.items(), key=sort_key)
frequencies = [count for _, count in sorted_counts]
self.class_weights = 1.0 / torch.tensor(frequencies, dtype=torch.float32)4.1.3词汇表、向量化器和DataLoader
为了使用字符对姓氏进行分类,我们使用词汇表、向量化器和DataLoader将姓氏字符串转换为向量化的minibatches。
class Vocabulary(object):
def __init__(self, token_to_idx=None, add_unk=True, unk_token="<UNK>"):
if token_to_idx is None:
token_to_idx = {}
self._token_to_idx = token_to_idx
self._idx_to_token = {idx: token
for token, idx in self._token_to_idx.items()}
self._add_unk = add_unk
self._unk_token = unk_token
self.unk_index = -1
if add_unk:
self.unk_index = self.add_token(unk_token) class SurnameVectorizer(object):
def __init__(self, surname_vocab, nationality_vocab, max_surname_length):
self.surname_vocab = surname_vocab
self.nationality_vocab = nationality_vocab
self._max_surname_length = max_surname_length
def vectorize(self, surname):
one_hot_matrix_size = (len(self.surname_vocab), self._max_surname_length)
one_hot_matrix = np.zeros(one_hot_matrix_size, dtype=np.float32)
for position_index, character in enumerate(surname):
character_index = self.surname_vocab.lookup_token(character)
one_hot_matrix[character_index][position_index] = 1
return one_hot_matrix4.2训练模型
4.2.1模型构建
在最后一步中,可选地应用softmax操作,以确保输出和为1;这就是所谓的“概率”。它是可选的原因与我们使用的损失函数的数学公式有关——交叉熵损失。
class SurnameClassifier(nn.Module):
def __init__(self, initial_num_channels, num_classes, num_channels):
super(SurnameClassifier, self).__init__()
self.convnet = nn.Sequential(
nn.Conv1d(in_channels=initial_num_channels,
out_channels=num_channels, kernel_size=3),
nn.ELU(),
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=3, stride=2),
nn.ELU(),
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=3, stride=2),
nn.ELU(),
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=3),
nn.ELU()
)
self.fc = nn.Linear(num_channels, num_classes)参数部分:
args = Namespace(
# Data and Path information
surname_csv="/home/jovyan/surnames_with_splits.csv",
vectorizer_file="vectorizer.json",
model_state_file="model.pth",
save_dir="model_storage/ch4/cnn",
# Model hyper parameters
hidden_dim=100,
num_channels=256,
# Training hyper parameters
seed=1337,
learning_rate=0.001,
batch_size=128,
num_epochs=100,
early_stopping_criteria=5,
dropout_p=0.1,
# Runtime options
cuda=False,
reload_from_files=False,
expand_filepaths_to_save_dir=True,
catch_keyboard_interrupt=True
)4.2.2循环训练
获取数据:
if args.reload_from_files:
# training from a checkpoint
dataset = SurnameDataset.load_dataset_and_load_vectorizer(args.surname_csv,
args.vectorizer_file)
else:
# create dataset and vectorizer
dataset = SurnameDataset.load_dataset_and_make_vectorizer(args.surname_csv)
dataset.save_vectorizer(args.vectorizer_file)开始训练:
try:
for epoch_index in range(args.num_epochs):
train_state['epoch_index'] = epoch_index
# Iterate over training dataset
# setup: batch generator, set loss and acc to 0, set train mode on
dataset.set_split('train')
batch_generator = generate_batches(dataset,
batch_size=args.batch_size,
device=args.device)
running_loss = 0.0
running_acc = 0.0
classifier.train()
for batch_index, batch_dict in enumerate(batch_generator):
# the training routine is these 5 steps:
# --------------------------------------
# step 1. zero the gradients
optimizer.zero_grad()
# step 2. compute the output
y_pred = classifier(batch_dict['x_surname'])
# step 3. compute the loss
loss = loss_func(y_pred, batch_dict['y_nationality'])
loss_t = loss.item()
running_loss += (loss_t - running_loss) / (batch_index + 1)
# step 4. use loss to produce gradients
loss.backward()
# step 5. use optimizer to take gradient step
optimizer.step()
# -----------------------------------------
# compute the accuracy
acc_t = compute_accuracy(y_pred, batch_dict['y_nationality'])
running_acc += (acc_t - running_acc) / (batch_index + 1)
# update bar
train_bar.set_postfix(loss=running_loss, acc=running_acc,
epoch=epoch_index)
train_bar.update()
train_state['train_loss'].append(running_loss)
train_state['train_acc'].append(running_acc)
展示训练过程:
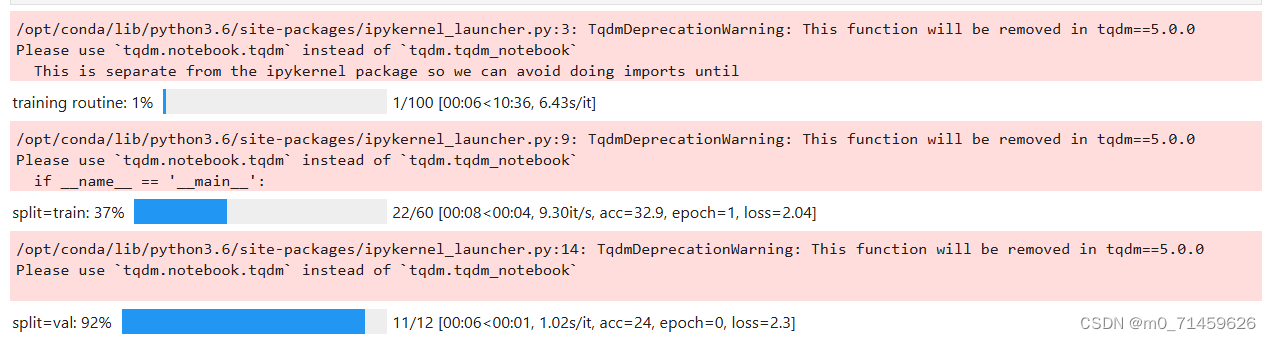
训练结果:
train_state['test_loss'] = running_loss
train_state['test_acc'] = running_acc
print("Test loss: {};".format(train_state['test_loss']))
print("Test Accuracy: {}".format(train_state['test_acc']))![]()
4.3模型预测
开始预测:
def predict_nationality(surname, classifier, vectorizer):
vectorized_surname = vectorizer.vectorize(surname)
vectorized_surname = torch.tensor(vectorized_surname).unsqueeze(0)
result = classifier(vectorized_surname, apply_softmax=True)
probability_values, indices = result.max(dim=1)
index = indices.item()
predicted_nationality = vectorizer.nationality_vocab.lookup_index(index)
probability_value = probability_values.item()
return {'nationality': predicted_nationality, 'probability': probability_value}
new_surname = input("Enter a surname to classify: ")
classifier = classifier.cpu()
prediction = predict_nationality(new_surname, classifier, vectorizer)
print("{} -> {} (p={:0.2f})".format(new_surname,
prediction['nationality'],
prediction['probability']))预测结果:

卷积和线性层实例化和规范使用批处理:
def predict_topk_nationality(surname, classifier, vectorizer, k=5):
vectorized_surname = vectorizer.vectorize(surname)
vectorized_surname = torch.tensor(vectorized_surname).unsqueeze(dim=0)
prediction_vector = classifier(vectorized_surname, apply_softmax=True)
probability_values, indices = torch.topk(prediction_vector, k=k)
# returned size is 1,k
probability_values = probability_values[0].detach().numpy()
indices = indices[0].detach().numpy()
results = []
for kth_index in range(k):
nationality = vectorizer.nationality_vocab.lookup_index(indices[kth_index])
probability_value = probability_values[kth_index]
results.append({'nationality': nationality,
'probability': probability_value})
return results
new_surname = input("Enter a surname to classify: ")
k = int(input("How many of the top predictions to see? "))
if k > len(vectorizer.nationality_vocab):
print("Sorry! That's more than the # of nationalities we have.. defaulting you to max size :)")
k = len(vectorizer.nationality_vocab)
predictions = predict_topk_nationality(new_surname, classifier, vectorizer, k=k)
print("Top {} predictions:".format(k))
print("===================")
for prediction in predictions:
print("{} -> {} (p={:0.2f})".format(new_surname,
prediction['nationality'],
prediction['probability']))预测结果:

注:本文中所述代码均为不完整的部分代码。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









