






 本文介绍了如何使用Python的requests和lxml库爬取长沙链家二手房网站的房源数据,包括房源名称、地点、单价和总价,并利用XPath解析HTML,将数据保存到CSV文件中。首先,安装必要的库,然后分析网页结构,确定请求头和数据获取方式,最后编写爬虫代码实现数据抓取和保存。
本文介绍了如何使用Python的requests和lxml库爬取长沙链家二手房网站的房源数据,包括房源名称、地点、单价和总价,并利用XPath解析HTML,将数据保存到CSV文件中。首先,安装必要的库,然后分析网页结构,确定请求头和数据获取方式,最后编写爬虫代码实现数据抓取和保存。
爬取前需要安装的库:requests,lxml,csv
安装方式:
pip install requests
pip install lxml
pip install csv
一、需求分析:
目标:熟悉xpath解析数的方式
需求:爬取二手房的房源名称,房源地点,房源单价,房源总价,爬取前5页数据,并保存到csv表格当中
二、前序操作步骤准备:
2.1 找到目标网站的url(长沙二手房房源_长沙二手房出售|买卖|交易信息(长沙链家))
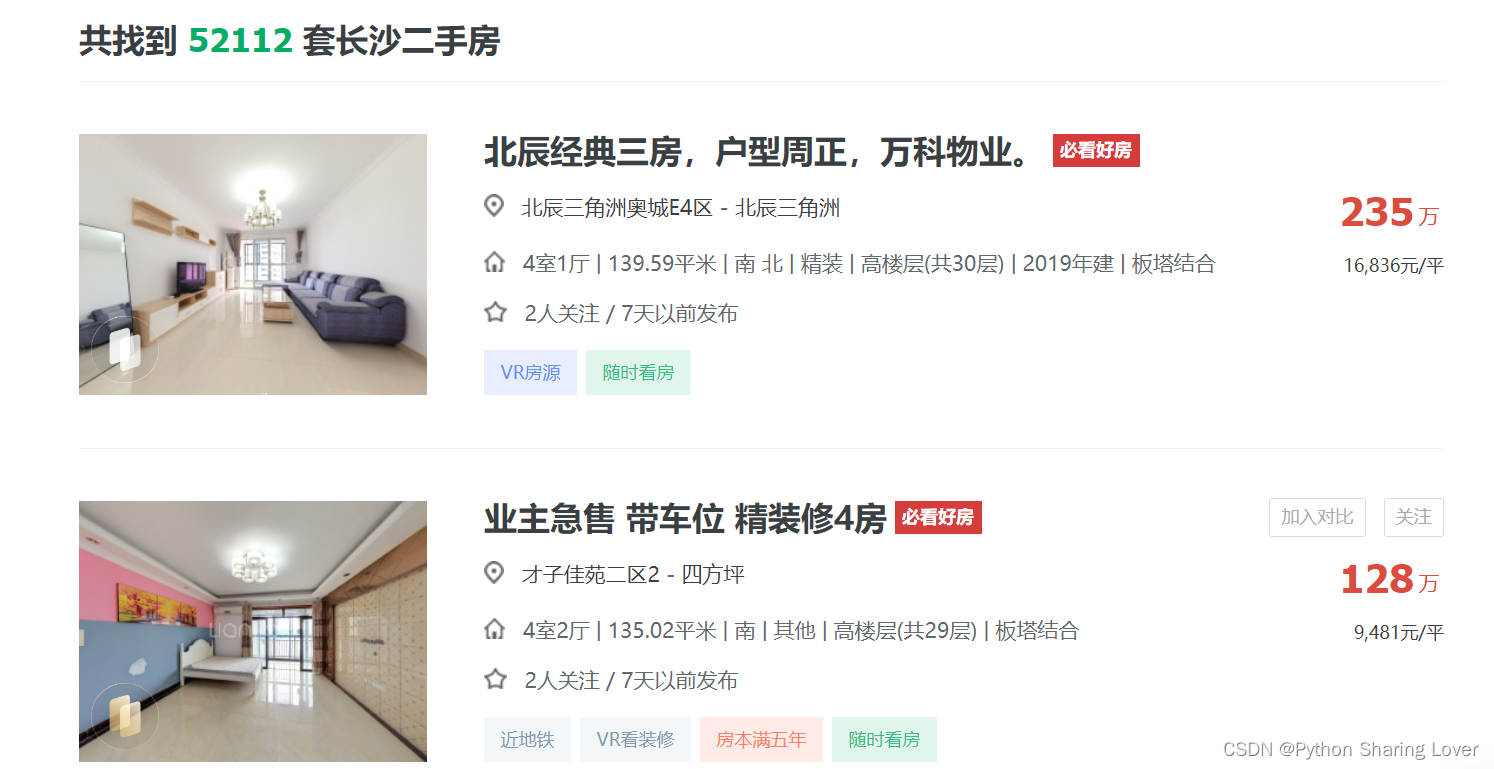
2.2 右键点击查看网页源代码
查看源代码中是否有“北辰经典三房”这一数据,这是用来判断我们此时看到的数据是否是ajax加载的数据,如果是ajax加载的数据那么我们就需要使用别的办法来解决。(按ctrl+F用于快速查找)

我们可以发现该数据可以在源代码中找到,因此我们就可以直接对该网站进行操作。
2.3 网络请求头查找:
回到网页界面,按F12打开开发者工具,选中“网络”,然后找到网页源代码文档:
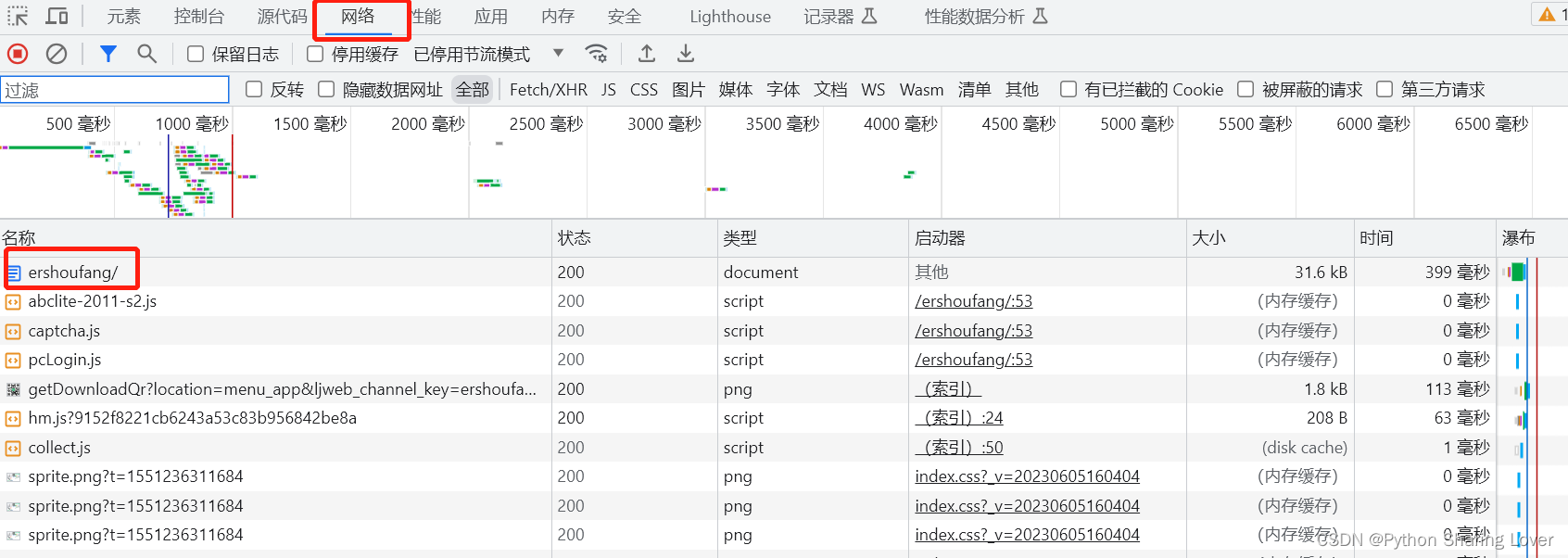
点击该文档之后往下划找到User-Agent,这个就是我们需要的请求头参数

那我们该如何检验该网站是否为我们所需要的那一个网站呢?
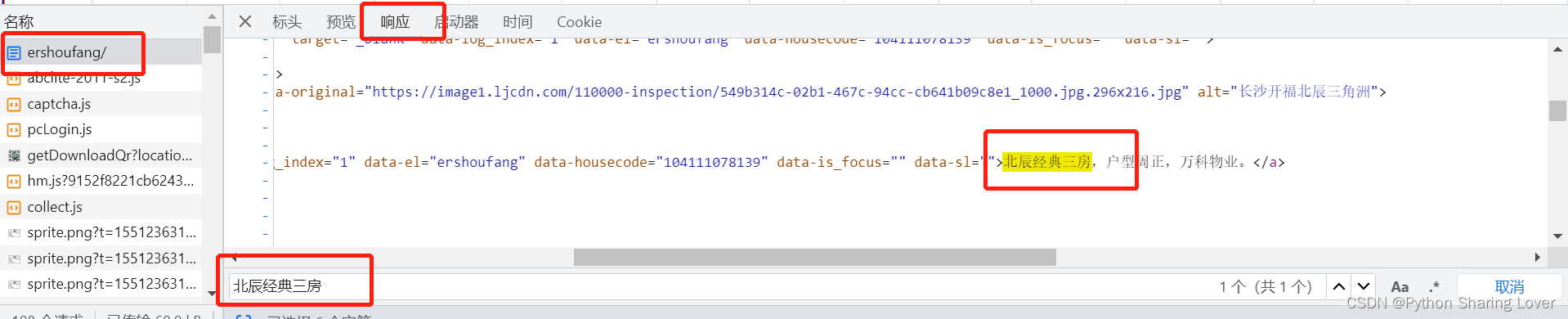
我们点击在该文档中点击相应,然后使用快捷方式 ctrl+F 输入北辰经典三房,然后我们就可以在里面看到跟源代码一样的内容,因此这个文档就是我们需要的文档。
2.4 查看网页源代码的编码格式:
我们在网页源代码中进行查看,找到charset确定其编码格式:

2.5 确定网页的请求方式(很重要)
不同的网站可能有不同的请求方式,因此我们对于一个确定的网站需要找到其请求方式我们才能进行获取数据:
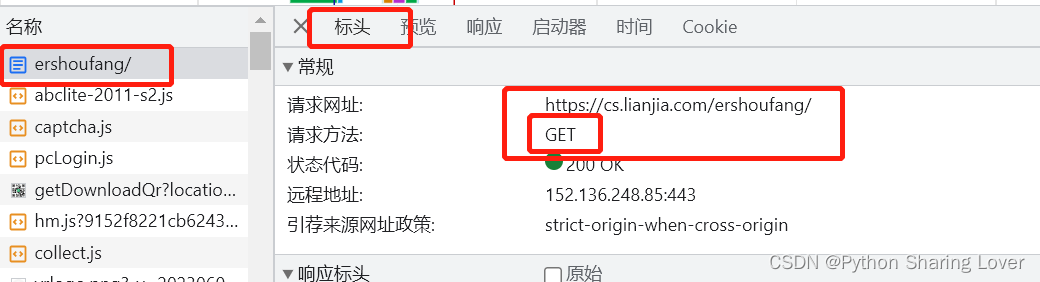
我们通过在标头中找到其请求方法为get请求。
因此我们即可完成对该网站爬取的基本的前序步骤。
三、代码分析展示(以函数的形式):
3.1 确定url以及请求头:
url = 'https://cs.lianjia.com/ershoufang/'
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}3.2 获取网页源代码数据:
def get_data_index():
response = requests.get(url=url,headers=headers) # 获取网页源代码
response.encoding = 'utf-8' # 将编码格式改成utf-8
print(response) # 打印一下看看是否爬取,用于检验,后续我们不需要这个打印结果
return response.text # 返回源代码的文本属性3.3 解析网页源代码数据(使用xpath解析):
在开发者工具中我们可以找到指定内容在网页源代码的位置,通过这个位置我们就可以获取到网页源代码的内容。
在元素栏中点击那个左上角的标识,然后点击我们需要爬取的内容。
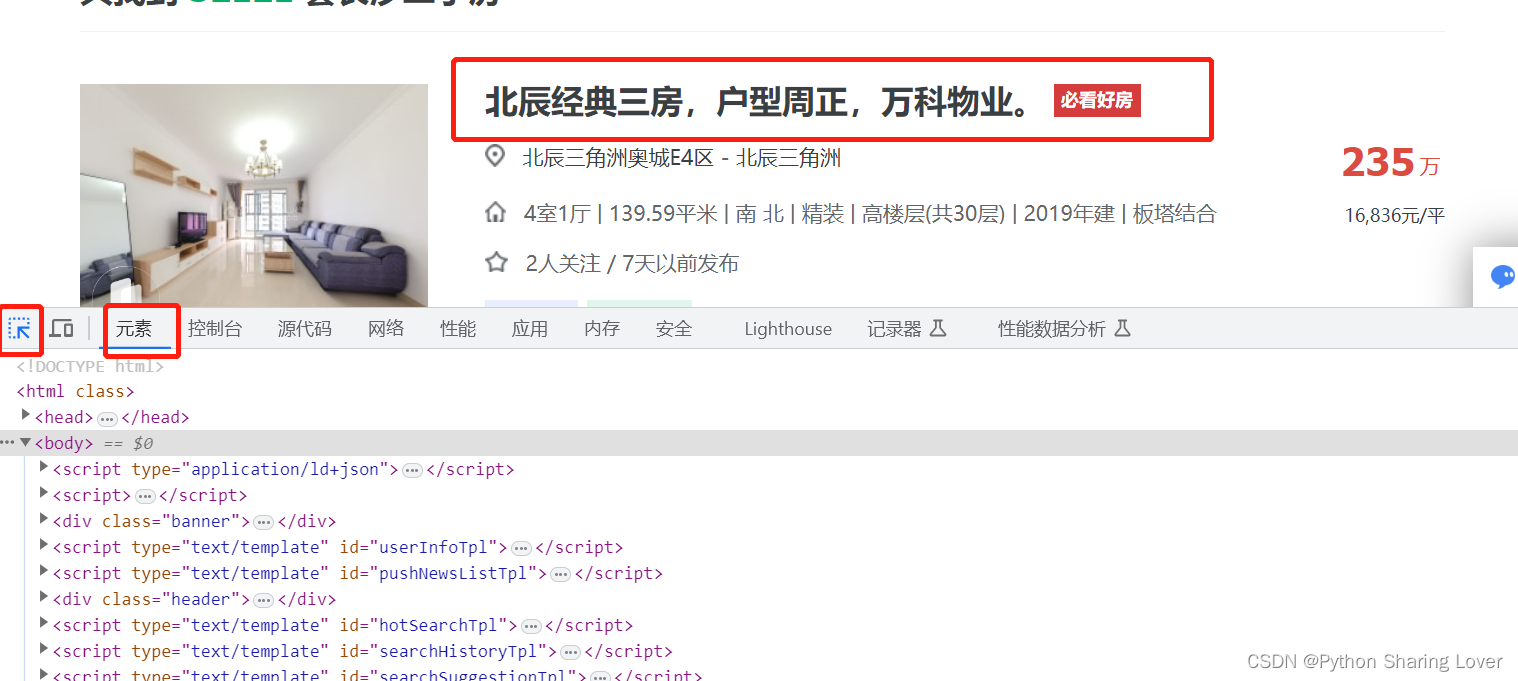
我们找到这个内容之后,右击就可以找到其xpath的路径。
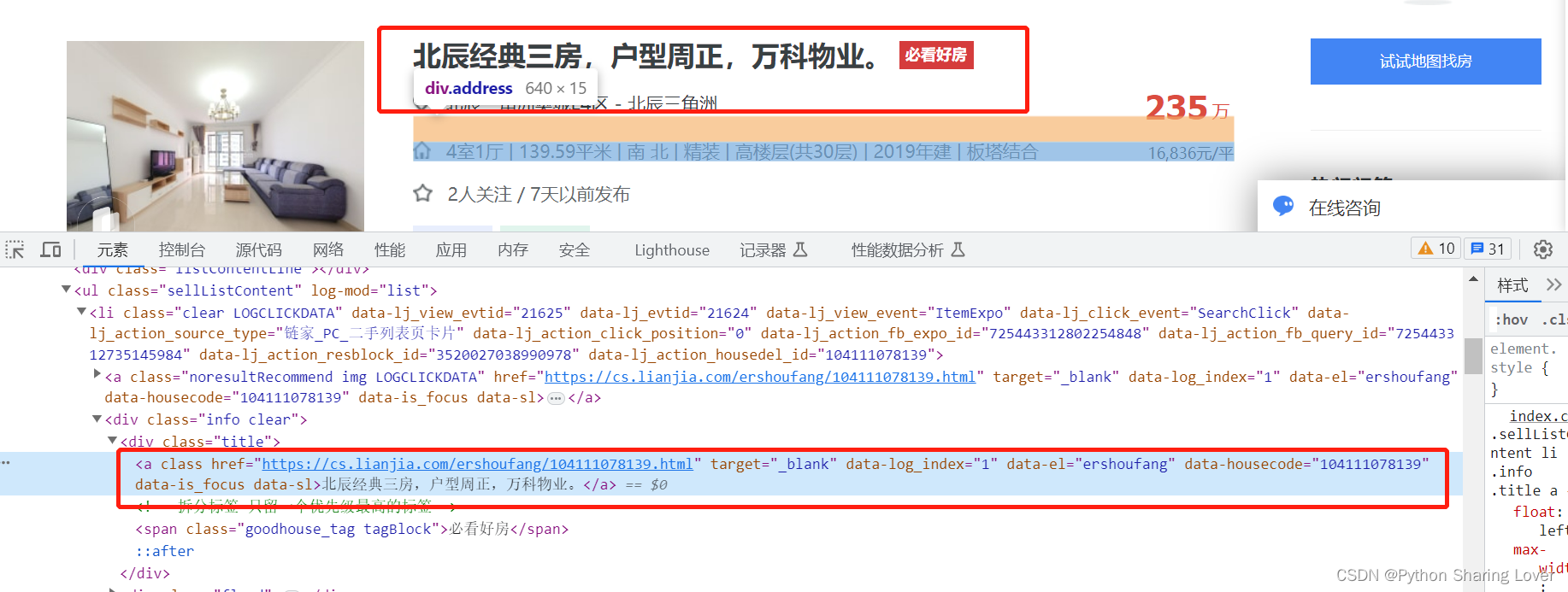
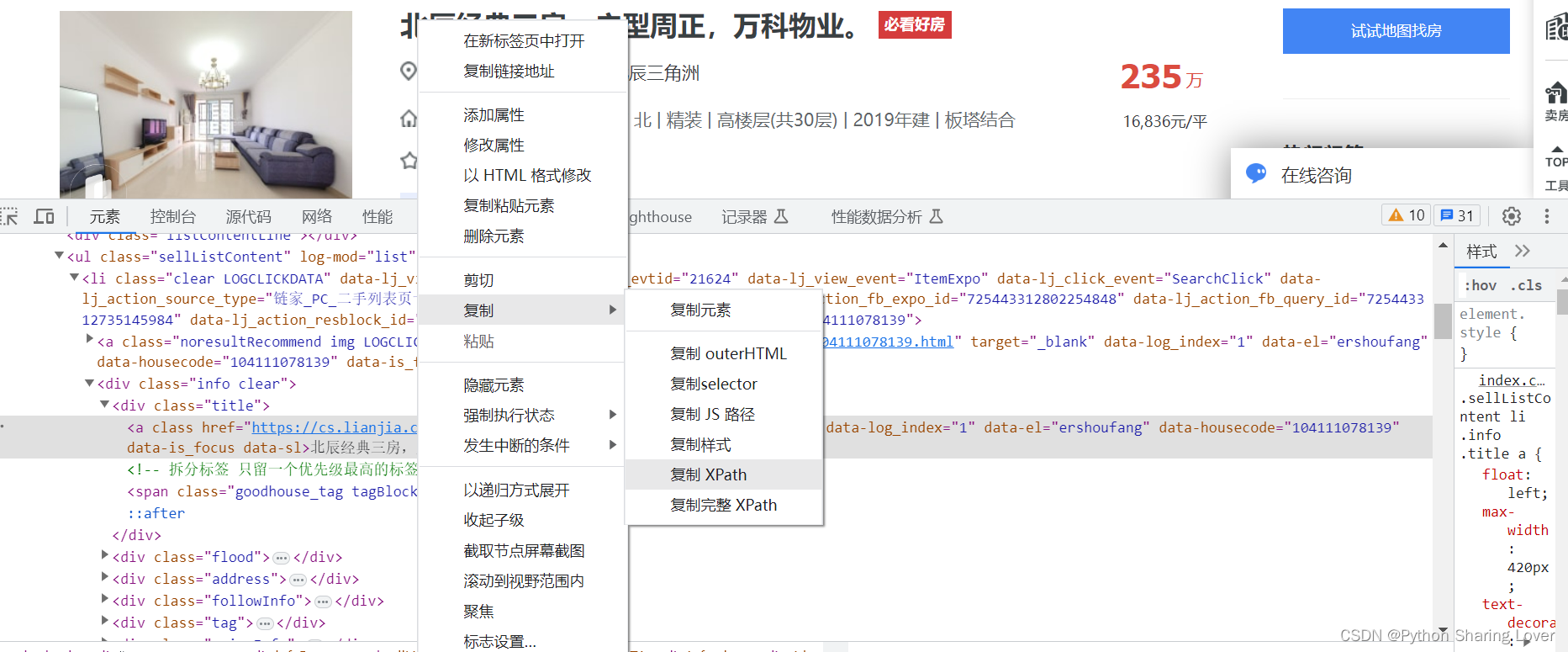
通过以上方法,我们就可以找到我们需要爬取的所有数据以及其xpath路径,这样我们就可以展开我们的代码了。
def parse_data_index(self,response):
html = etree.HTML(response) # 传入response参数,使用etree方法将其转化为文档树
data_list = html.xpath('//*[@id="content"]/div[1]/ul/li') # 找到所有数据的xpath路径
content_data = [['标题','位置','单价','总价']] # 后续进行表格保存的处理
for data in data_list:
add_data = []
try:
title = data.xpath('./div[1]/div[1]/a/text()')[0]
location ='-'.join(data.xpath('./div[1]/div[2]/div/a/text()'))
dan_price = data.xpath('./div[1]/div[6]/div[2]/span/text()')[0]
all_price = data.xpath('./div[1]/div[6]/div[1]/span/text()')[0] + '万'
# print(title,location,dan_price,all_price) # 用于检验是否保存成功
add_data.extend([title,location,dan_price,all_price])
content_data.append(add_data)
except(IndexError):
continue
return content_data3.4 保存爬取数据到csv表格中:
def write_data_index(content_data):
# 指定保存的文件路径和文件名
filename = 'data.csv'
# 以写入模式打开文件,并创建CSV写入器
with open(filename, 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.writer(csvfile)
# 逐行写入数据
for row in content_data:
writer.writerow(row)
print('数据已成功保存到', filename)四、全部代码展示(以面向过程的方式):
# -*- coding:utf-8 -*-
import requests
from lxml import etree
import csv
class Lian_Jia(object):
def __init__(self):
self.url = 'https://cs.lianjia.com/ershoufang/pg{}/'
self.headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
def get_data_index(self,page):
new_url = self.url.format(page)
response = requests.get(url=self.url,headers=self.headers)
return response.text
def parse_data_index(self,response):
html = etree.HTML(response)
data_list = html.xpath('//*[@id="content"]/div[1]/ul/li')
content_data = [['标题','位置','单价','总价']]
for data in data_list:
add_data = []
try:
title = data.xpath('./div[1]/div[1]/a/text()')[0]
location ='-'.join(data.xpath('./div[1]/div[2]/div/a/text()'))
dan_price = data.xpath('./div[1]/div[6]/div[2]/span/text()')[0]
all_price = data.xpath('./div[1]/div[6]/div[1]/span/text()')[0] + '万'
# print(title,location,dan_price,all_price)
add_data.extend([title,location,dan_price,all_price])
content_data.append(add_data)
except(IndexError):
continue
return content_data
def write_data_index(self,content_data):
# 指定保存的文件路径和文件名
filename = 'data.csv'
# 以写入模式打开文件,并创建CSV写入器
with open(filename, 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.writer(csvfile)
# 逐行写入数据
for row in content_data:
writer.writerow(row)
print('数据已成功保存到', filename)
def run(self):
# for page in range(1,6):
response = self.get_data_index(1)
content_data = self.parse_data_index(response)
self.write_data_index(content_data)
if __name__ == '__main__':
spider = Lian_Jia()
spider.run()














 3305
3305











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









