







目录
4.1.3文本行输入(fgets)输出(fputs)函数(一行数据一行数据的读写)
4.1.4格式化输入函数(fscanf)和格式化输出函数(fprintf):针对带有格式的数据
4.1.5 printf scanf fprintf fscanf sscanf sprintf简单对比
4.1.6 二进制 输入函数(fread)二进制输出函数(fwrite)
1.引入文件使用的原因
如果大家看过我前面几个日期的博文,就会发现写通讯录的程序,当通讯录运行起来的时候,可以给通讯录中增加、删除数据,但是这些数据是存放在内存中,当程序退出的时候,通讯录中的数据自然就不存在了,等下次运行通讯 录程序的时候,数据又得重新录入,如果使用这样的通讯录就很难受。 我们在想既然是通讯录就应该把信息记录下来,只有我们自己选择删除数据的时候,数据才不复存在。 这就涉及到了数据持久化的问题,我们一般数据持久化的方法有,把数据存放在磁盘文件、存放到数据 库等方式。 使用文件我们可以将数据直接存放在电脑的硬盘上,做到了数据的持久化。
2.文件是什么
磁盘上的文件是文件。
当我们将数据放进文件里面,就相当于把数据放入了硬盘中,下次需要的时候读进程序就可以了。但是在程序设计中,我们一般谈的文件有两种:程序文件、数据文件(从文件功能的角度来分类的)。
2.1 程序文件
包括源程序文件(后缀为.c),目标文件(windows环境后缀为.obj),可执行程序(windows环境 后缀为.exe)。
比如我们打开我们的通讯录文件夹:
2.2 数据文件
文件的内容不一定是程序,而是程序运行时读写的数据,比如程序运行需要从中读取数据的文件, 或者输出内容的文件。
本篇内容的陈述对象就是我们的数据文件,如何利用我们的C语言代码读取数据文件中的数据和如何用C语言代码将数据写入我们的C语言程序
在以前所处理数据的输入输出都是以终端为对象的,即从终端的键盘输入数据,运行结果显示到显示器(屏幕)上。这章过后,我们可以把信息输出到磁盘上,当需要的时候再从磁盘上把数据读取到内存中使用,这里处理的就是磁盘上文件。
2.3 文件名
一个文件要有一个唯一的文件标识(同一路径下不会同时出现两个相同的文件名),以便用户识别和引用。
文件名包含3部分:文件路径+文件名主干+文件后缀
例如:
文件名为:"D:\c-language\课程学习代码C语言\通讯录项目\通讯录项目\contact.c"
D:\c-language\课程学习代码C语言\通讯录项目\通讯录项目\为文件路径
contact 为文件名
.c是文件后缀,表示文件的类型
为了方便起见,文件标识常被称为文件名。

3. 文件的打开和关闭
我们知道对于文件进行操作的完整步骤是:
1.打开文件
2.读写文件
3.关闭文件
如果对比一下我们的scanf和printf我们发现,在我们使用这二者对标准的流进行读写也就是输入输出的时候我们并没有说要打开屏幕,打开键盘这个操作。
这是因为:
C语言程序只要运行起来,就默认打开了三个流:
标准输入流:stdio 可以使用getchar scanf这样的操作
标准输出流:stdout 可以使用printf和putchar这类操作
标准错误流:stderr
三者的类型都是FILE*
那么对于文件来说,不可以当我们的程序运行起来就默认打开那个文件,所以要操作文件就需要自己打开和关闭。
3.1 文件指针
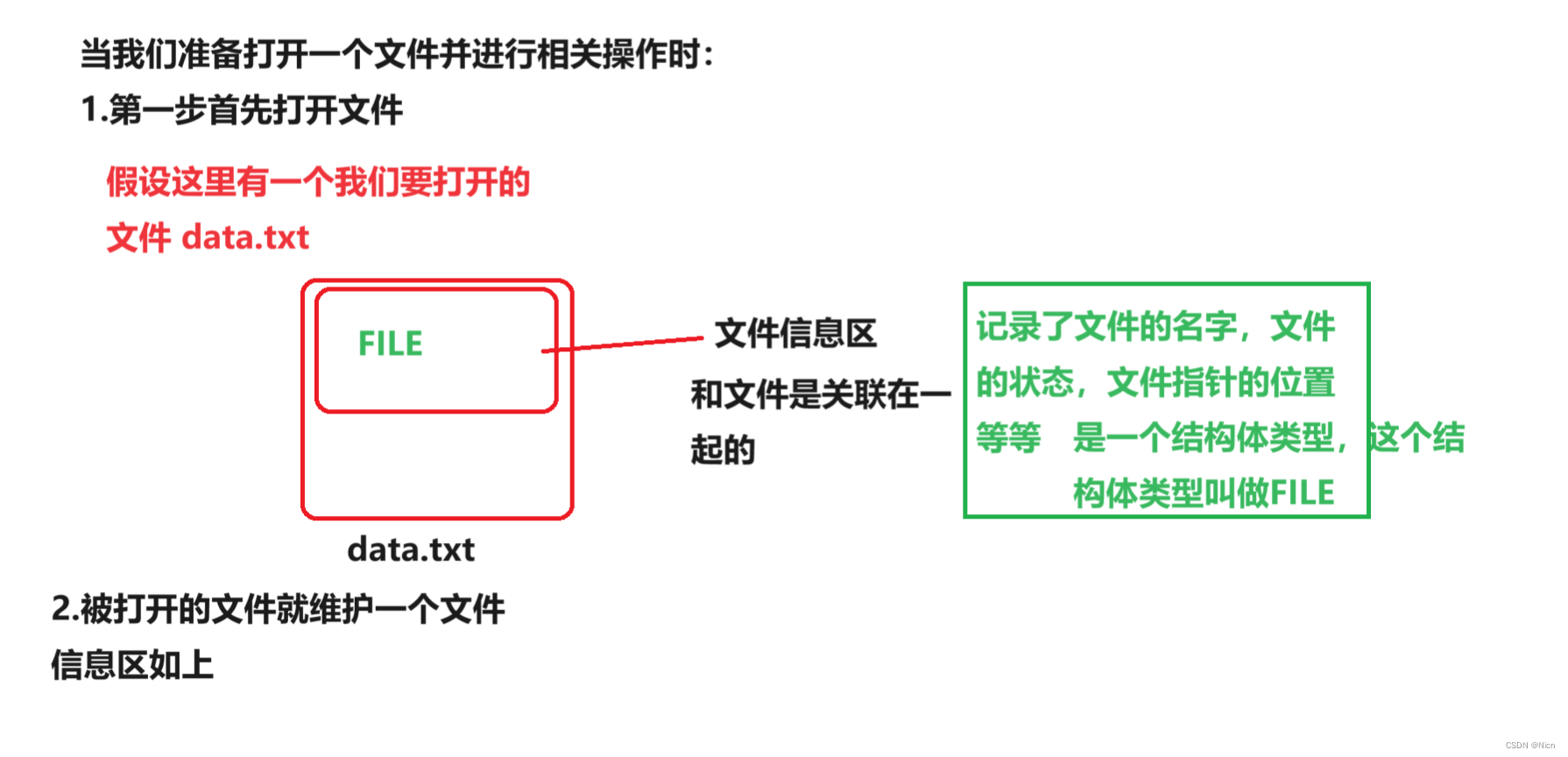
缓冲文件系统中,关键的概念是“文件类型指针”,简称“文件指针”。
每个被使用的文件都在内存中开辟了一个相应的文件信息区,用来存放文件的相关信息(如文件的名 字,文件状态及文件当前的位置等)。这些信息是保存在一个结构体变量中的。该结构体类型是由系统 声明的,取名FILE.
解释:
例如,VS2013编译环境提供的 stdio.h 头文件中有以下的文件类型申明:
struct _iobuf { char *_ptr; int _cnt; char *_base; int _flag; int _file; int _charbuf; int _bufsiz; char *_tmpfname; }; typedef struct _iobuf FILE;不同的C编译器的FILE类型包含的内容不完全相同,但是大同小异。 每当打开一个文件的时候,系统会根据文件的情况自动创建一个FILE结构的变量,并填充其中的信息, 使用者不必关心细节。 一般都是通过一个FILE的指针来维护这个FILE结构的变量(相当于这个FILE*的指针指向了我们的文件信息区,我们并不是直接操作文件,而是通过文件信息区这个抓手),这样使用起来更加方便。
那么下面我们就可以创建一个FILE*的指针变量:
FILE* pf;//文件指针变量pf是一个指向FILE类型数据的指针变量。可以使pf指向某个文件的文件信息区(是一个结构体变 量)。通过该文件信息区中的信息就能够访问该文件。也就是说,通过文件指针变量能够找到与它关联 的文件。
接下来我们就在代码中来体验一下:

3.2 文件的打开和关闭
3.2.1文件的打开
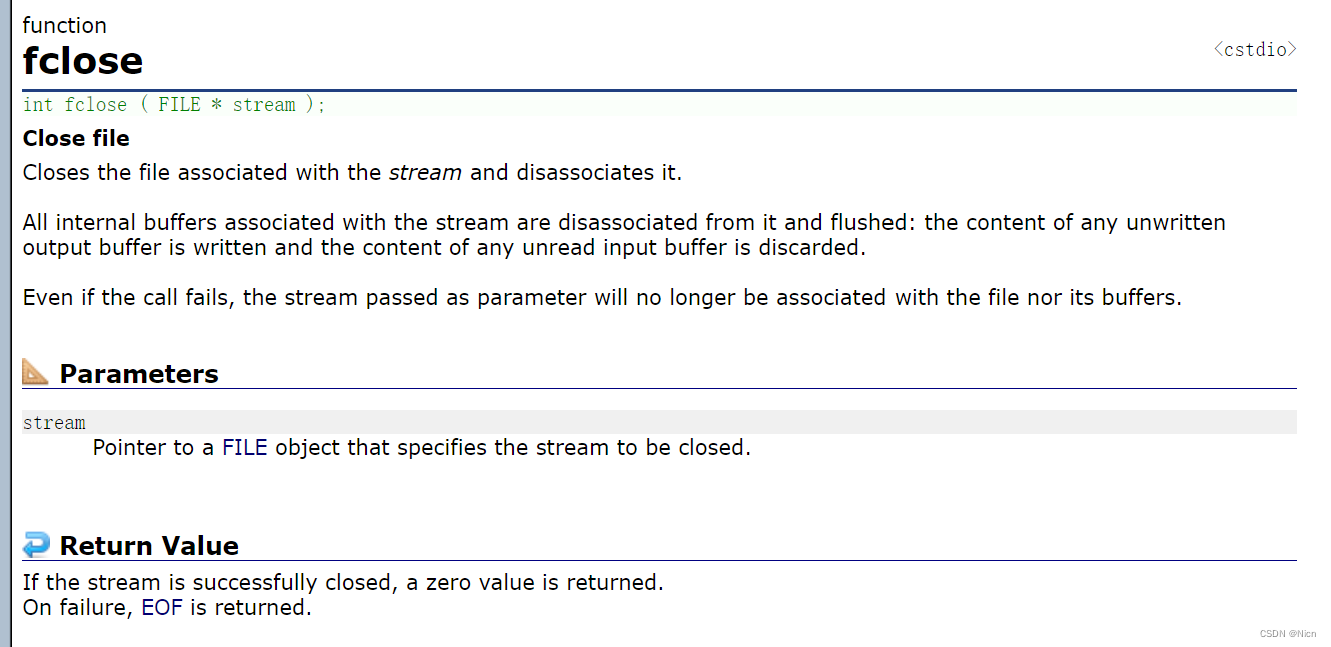
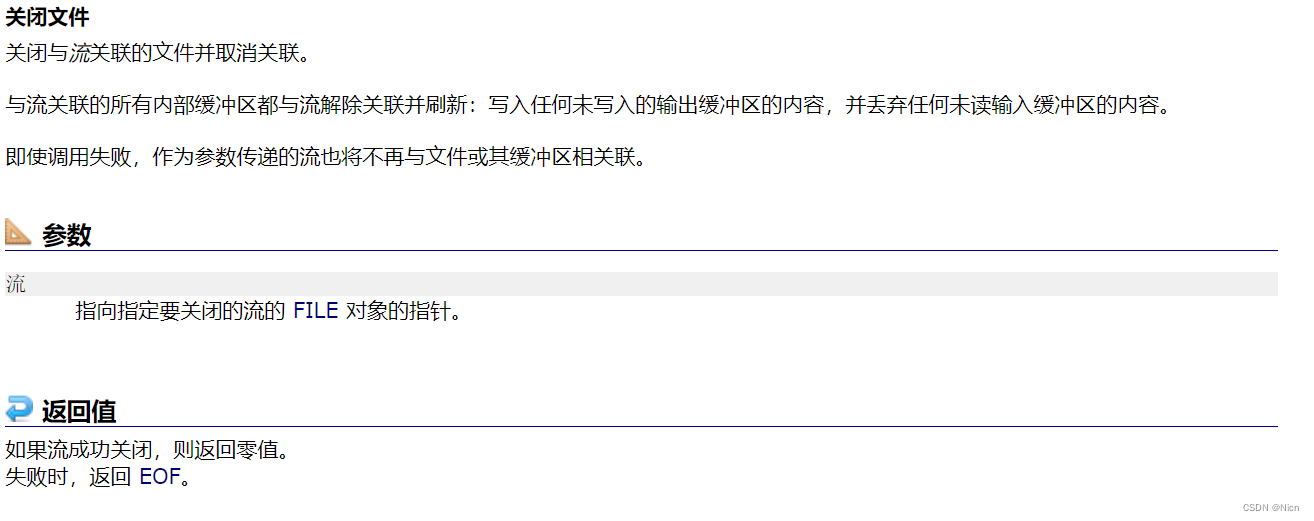
文件在读写之前应该先打开文件,在使用结束之后应该关闭文件。 在编写程序的时候,在打开文件的同时,都会返回一个FILE*的指针变量指向该文件,也相当于建立了指 针和文件的关系。 ANSIC (C语言标准)规定使用fopen函数来打开文件,fclose来关闭文件。
,
打开文件函数:
函数参数:第一个参数是文件名
第二个参数是打开的方式:一共有这些打开方式:
文件使用方式 含义 如果指定文件不存在
“r”(只读) 为了输入数据,打开一个已经存在的文本文件 出错
“w”(只写) 为了输出数据,打开一个文本文件 建立一个新的文件
“a”(追加) 向文本文件尾添加数据 建立一个新的文件
“rb”(只读) 为了输入数据,打开一个二进制文件 出错
“wb”(只写) 为了输出数据,打开一个二进制文件 建立一个新的文件
“ab”(追加) 向一个二进制文件尾添加数据 建立一个新的文件
“r+”(读写) 为了读和写,打开一个文本文件 出错
“w+”(读写) 为了读和写,建议一个新的文件 建立一个新的文件
“a+”(读写) 打开一个文件,在文件尾进行读写 建立一个新的文件
“rb+”(读写) 为了读和写打开一个二进制文件 出错
“wb+”(读写) 为了读和写,新建一个新的二进制文件 建立一个新的文件
“ab+”(读写) 打开一个二进制文件,在文件尾进行读和写 建立一个新的文件
,
接下来,我们就举例示范一下这个函数的实现代码:
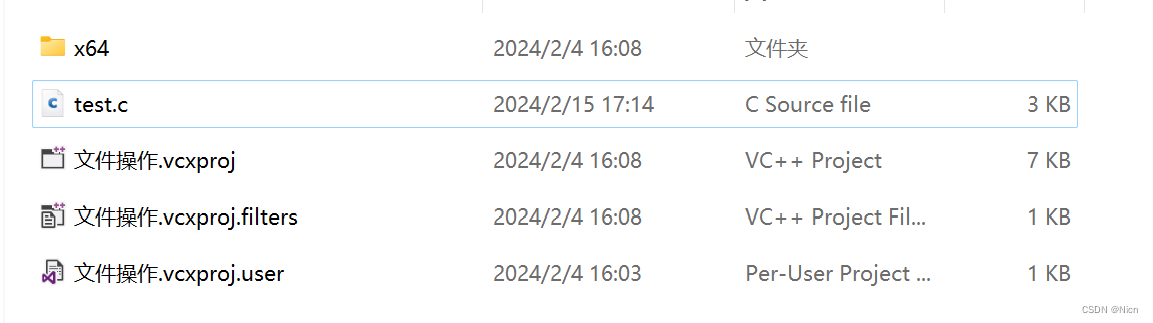
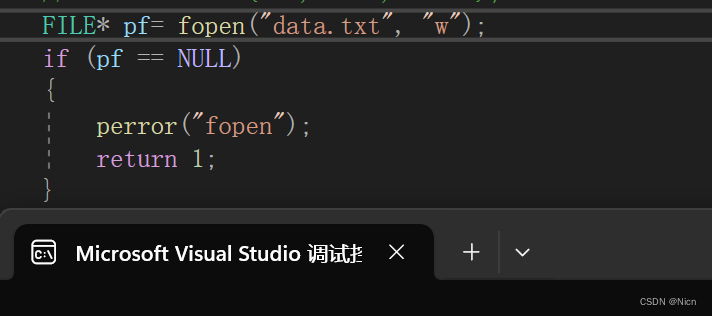
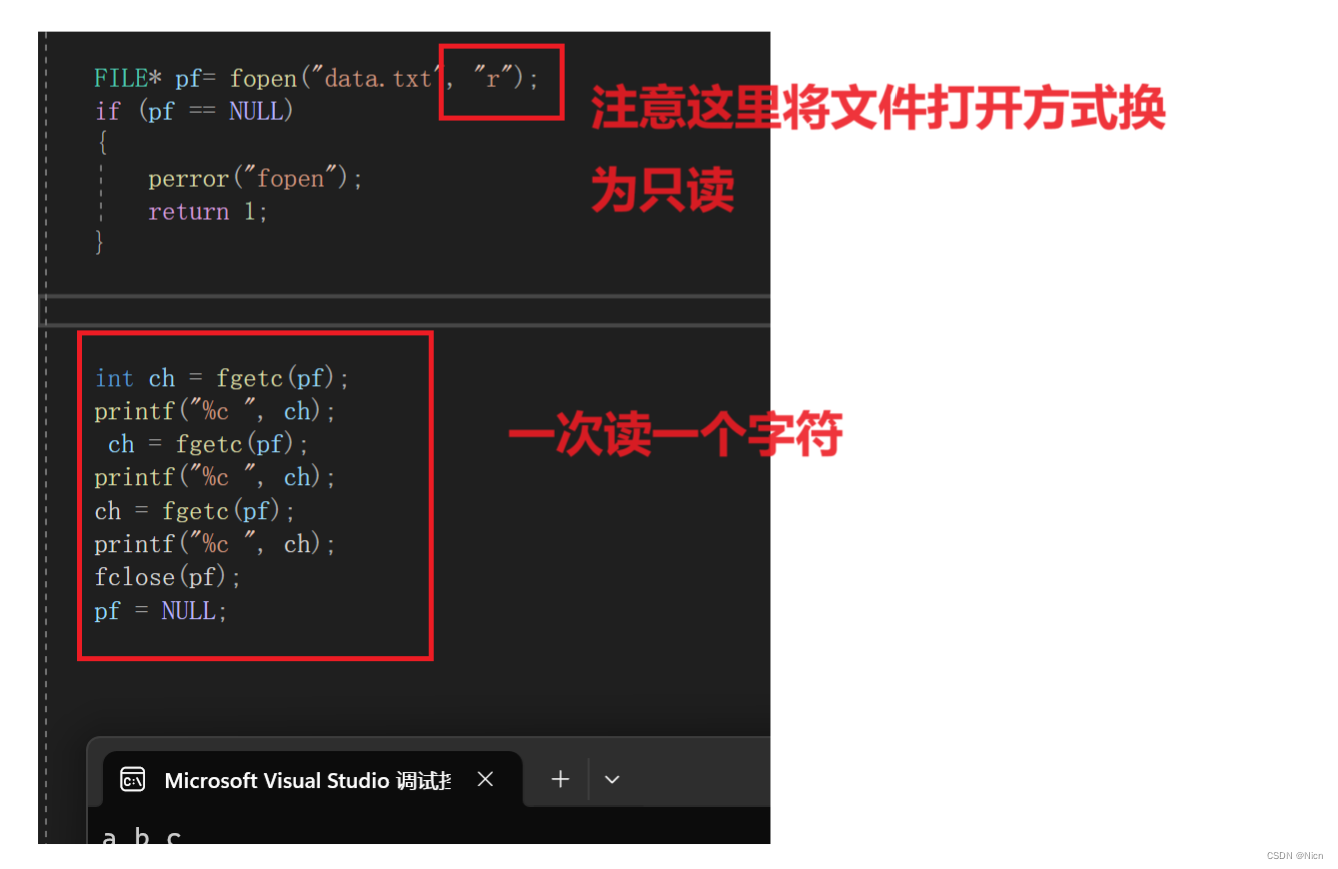
首先当我们的路径地下没有我们程序要打开的文件,我们用只读“r”的方式来打开文件:FILE* pf= fopen("data.txt", "r"); if (pf == NULL) { perror("fopen"); return 1; }由于我们.c文件路径下面没有我们要打开的文件:
所以函数返回一个空指针然后报错:
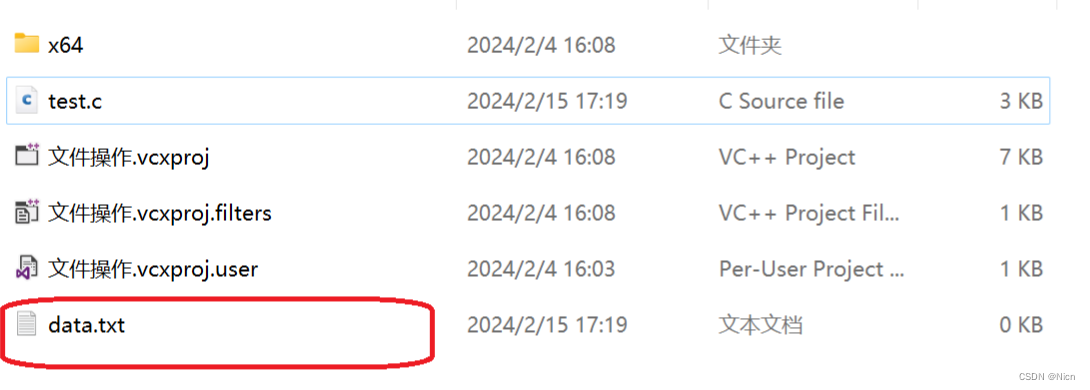
当我们用“w”方式来打开这个文件,没有这个文件就会创建一个同名文件在当前路径下:
首先:当前文件路径下没有我们的data.txt文件,让我们用W的方式来执行代码:
程序没有报错,然后在我们的文件路径底下:多了一个data。txt的文件。




3.2.2文件的相对路径和绝对路径
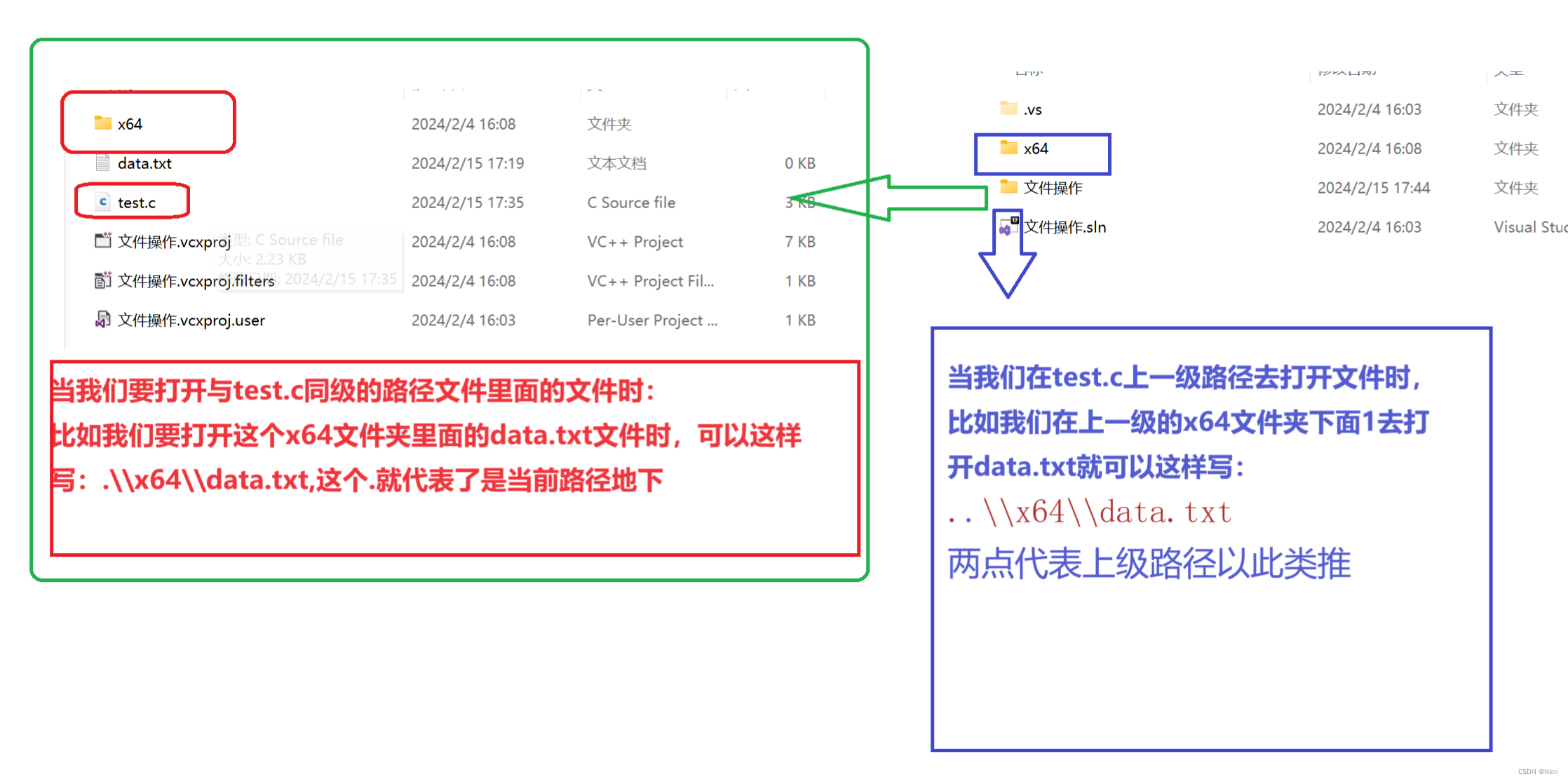
①像上面的data.txt和我们的程序文件同级的,我们在代码中写入的叫做相对路径
相对路径还可以使用我们的.代表同一级路径:
运行一下:
..->两点就代表上一级路径:
运行一下:
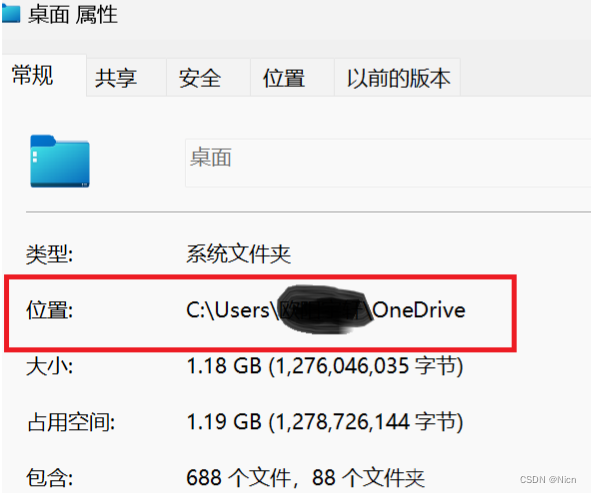
②文件的具体路径就叫做绝对路径,绝对路径可以帮助我们的程序找到任何文件,不论桌面文件还是上级文件。,比如我们用决定路径在桌面上创建一个文件:
这就是我们的绝对路径,我们将其复制下来:
由于存在\转义字符,所以应该在\前面在加上\:
FILE* pf= fopen("C:\\Users\\OneDrive\\data.txt", "w"); if (pf == NULL) { perror("fopen"); return 1; }然后我们运行:
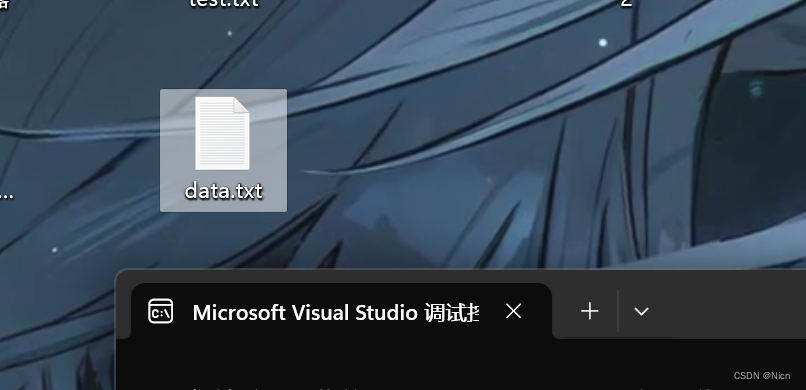
就在我们的桌面上创建了这个文件
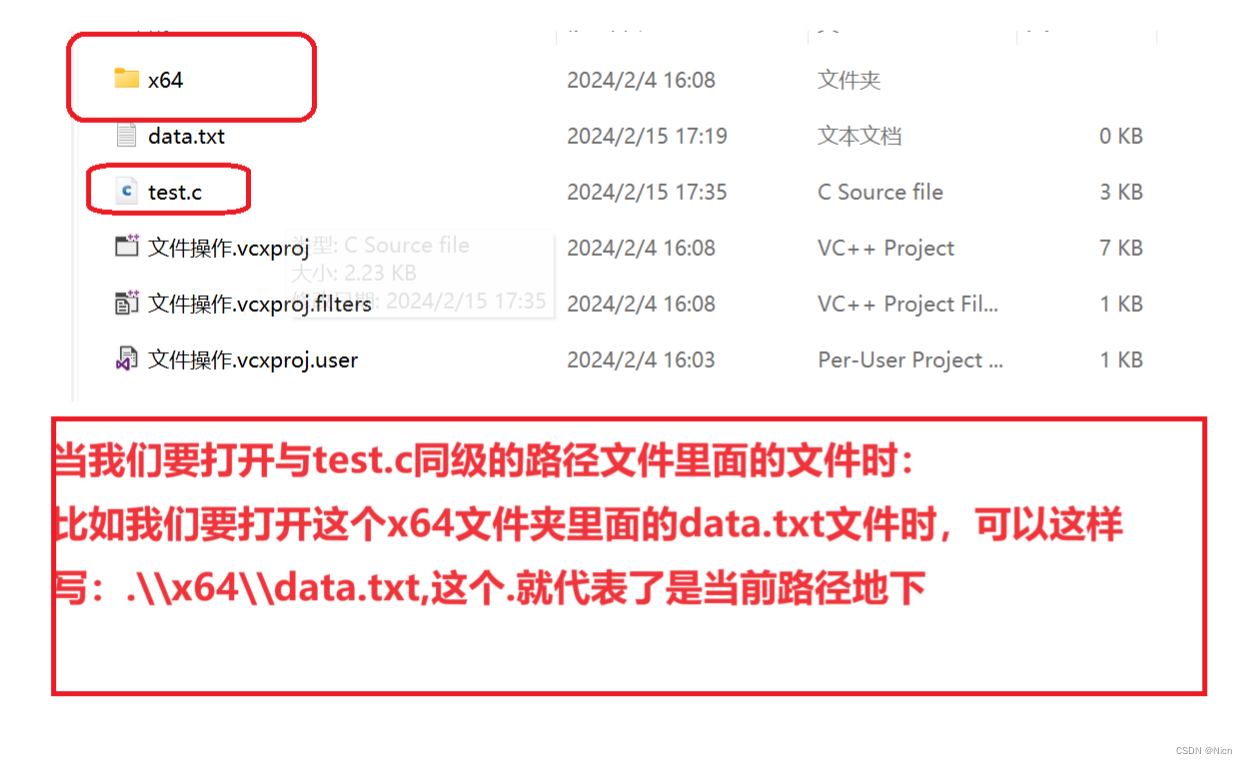

3.2.3文件的关闭
C语言中提供文件关闭的函数fclose:
关于文件关闭函数的具体使用:
int main() { FILE* pf= fopen(".\\x64\\data.txt", "w"); if (pf == NULL) { perror("fopen"); return 1; } fclose(pf); pf = NULL; return 0; }很简单,操作对象为对应文件的文件指针,然后关闭后将文件指针置空。
可以打开关闭文件过后,接下来就是如何将我们文件里保存的数据拿到我们的程序中,或者如何将我们程序中产生的数据写入文件或者叫做输出到文件呢?两种方式:
顺序读写和随机读写我们挨个介绍:
4. 文件的顺序读写
补充‘流’:因为接下来的函数会涉及到流这个概念,所以就补充一下,我们很早就一直再说这个标准输入输出流,那么什么是流呢。流是一个很抽像的概念
就像水流,我们可以认为我们写程序处理的是数据流。我们在读数据或者写数据的时候计算机的外部设备是非常多的,比如我们键盘、屏幕、摄像头也可以输入图像数据等等,简单来说就是可以由不同的外部设备写入数据,也可以输出到不同的外部设备,那么这样的话,直接处理数据对于我们程序员来说难度就有点大了,我们得考虑和熟悉各种各样的输入输出设备的读取情况,那么为了方便就有了流这个概念。就把数据流淌这个过程抽象成流这个概念。所以就不管外部设备是什么,当我们要读取数据的时候,我们都说把数据读取到流里面,程序员就只用关心怎么和流之间的交互就OK,其他的不关心,比如怎么输入输出到什么样的设备等
4.1 顺序读写函数介绍
4.1.1字符输入函数 fgetc 适用于所有输入流
适用于所有输入流的意思就是,既可以从键盘这种标准输入流里读取数据,也可以从我们的文件流里读取数据.
函数功能:从流中读取一个字符,读到文件末尾或者读取失败会返回一个EOF
函数头文件:stdio.h
函数参数:FIlE*类型的指针
为了方便举例使用,和fputc一起介绍完使用举例。


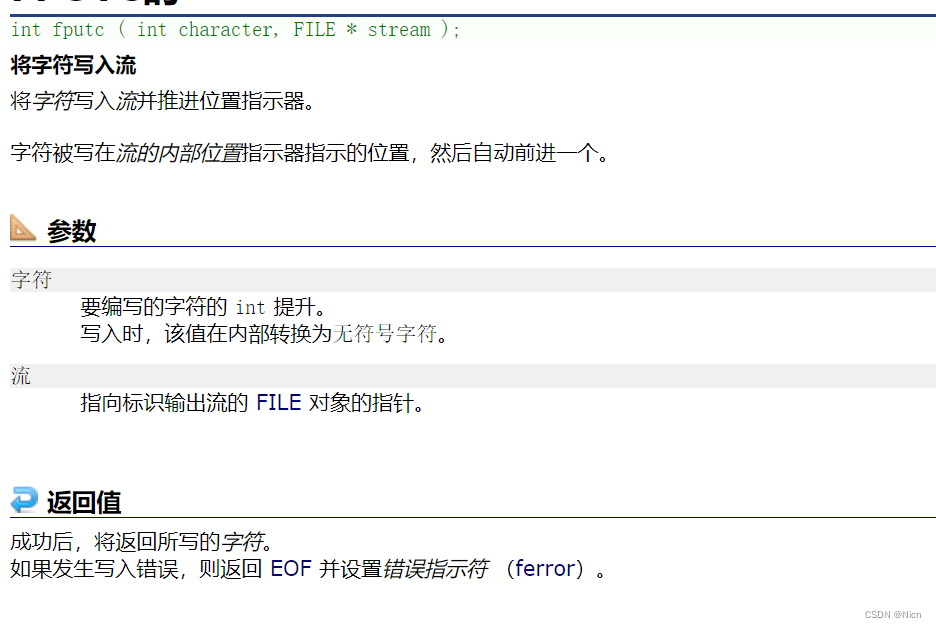
4.1.2字符输出函数 fputc 适用所有输出流
按照程序写入顺序写入一个字符到流里面去:
举例使用:
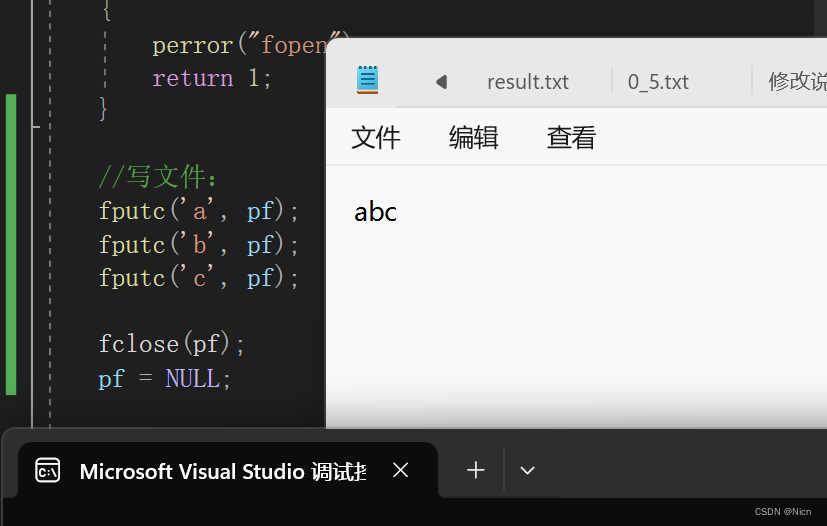
int main() { FILE* pf= fopen("data.txt", "w"); if (pf == NULL) { perror("fopen"); return 1; } //写文件: fputc('a', pf); fputc('b', pf); fputc('c', pf); fclose(pf); pf = NULL; return 0; }运行成功后,在我们指定的文件里面写入了数据:
也可以循环写入
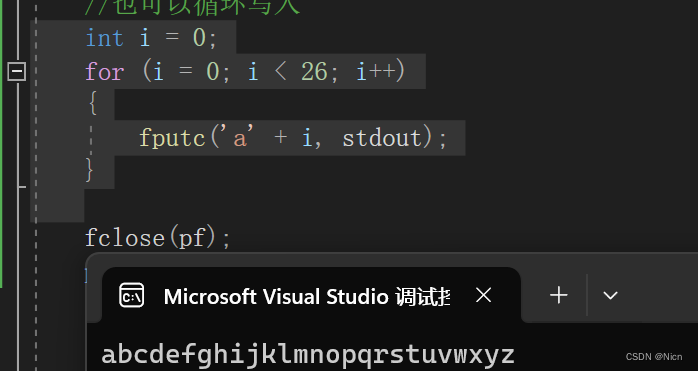
int i = 0; for (i = 0; i < 26; i++) { fputc('a' + i, pf); }
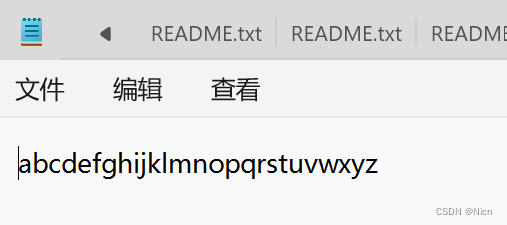
刚才说了,fput函数,适用于所有输入输出流,不仅可以把我们程序的数据输出到文件流也可以输出到我们的屏幕,我们看一下:将我们的pf指针换为我们的stdout
int i = 0; for (i = 0; i < 26; i++) { fputc('a' + i, stdout); }
,
,
,
下面我们来读文件,使用我们的fgetc函数:
首先我们在文件中写入一下数据:
然后我们使用函数来读取数据输出到屏幕上:
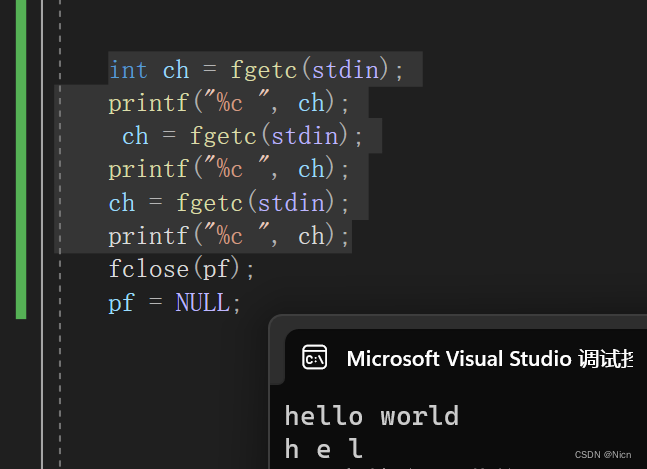
同样的我们的fgetc函数一样可以从我们的键盘数获取数据不过还是一次获取一个,我们将pf换为stdin:
int ch = fgetc(stdin); printf("%c ", ch); ch = fgetc(stdin); printf("%c ", ch); ch = fgetc(stdin); printf("%c ", ch);
由于只读取3次,所以只打印了3个字符
,
输入输出是对于程序来说,
读写分别对应的是输入和输出,这里对于我们刚开始的伙伴来说容易混淆:

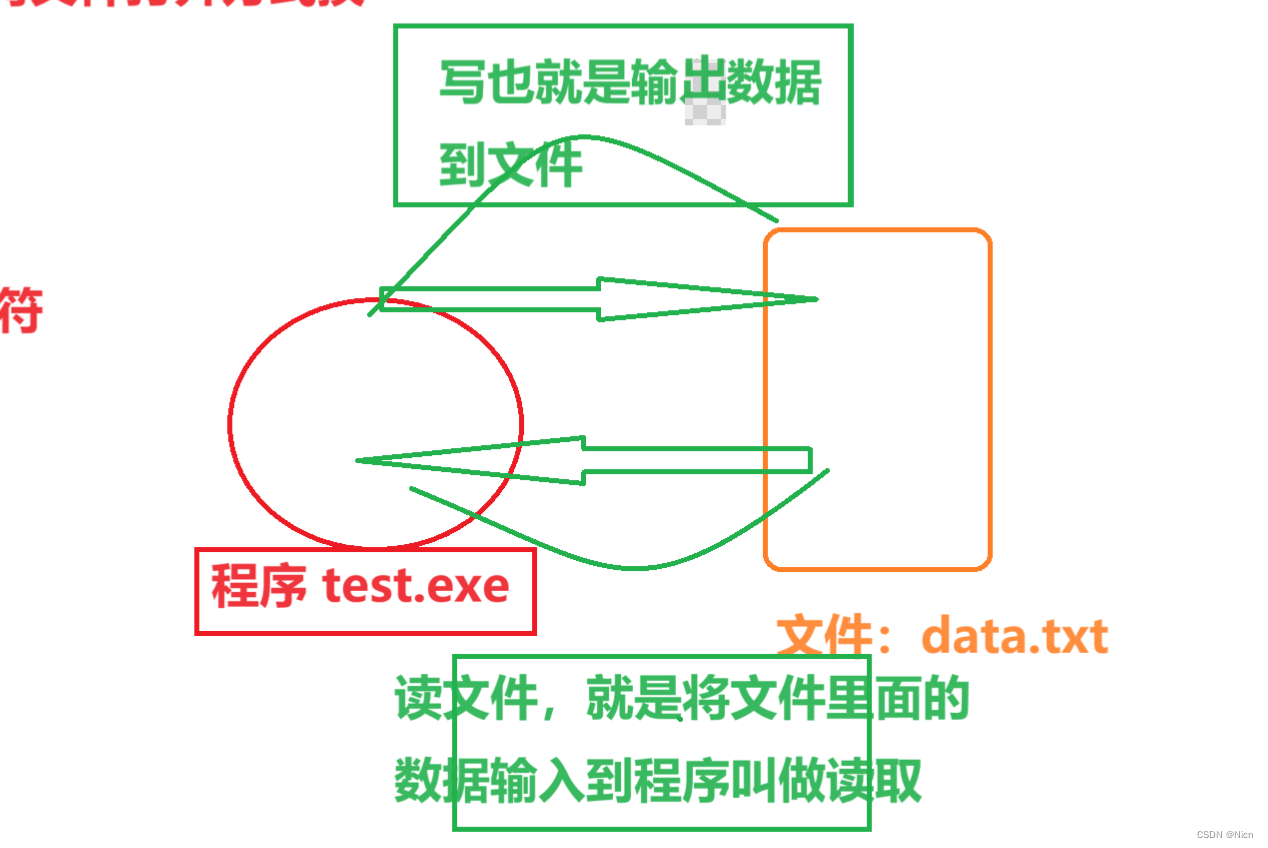
4.1.3文本行输入(fgets)输出(fputs)函数(一行数据一行数据的读写)
两个函数同样适用于所有输入输出流
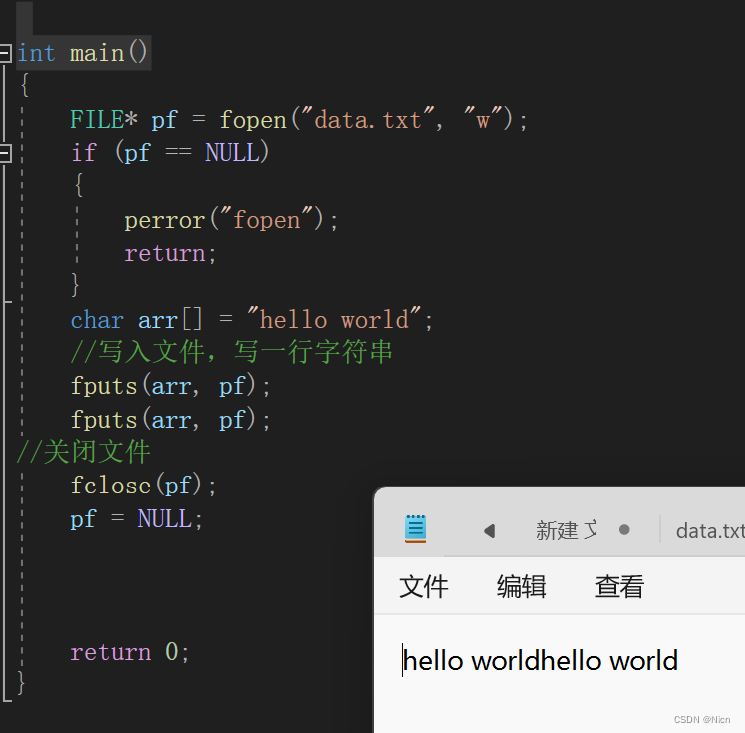
函数将一个字符串写入流中,我们需要上传的参数是字符串的起始地址,和写入流的位置
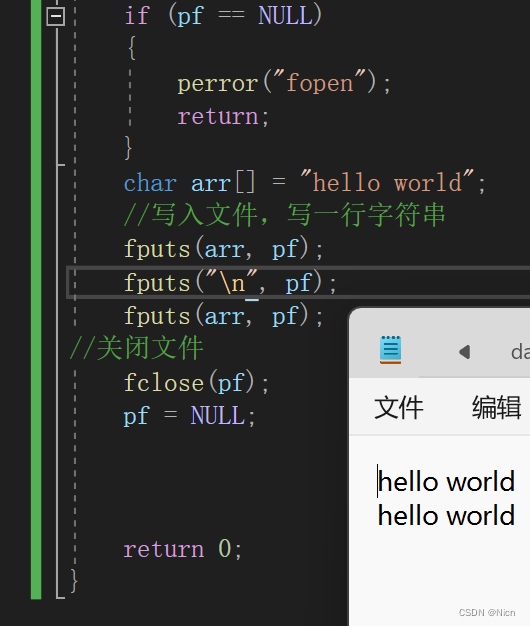
一次写一行,我们多次调用我们的写入函数只会写成一行数据,除非我们自己加上换行符。
调用两次函数,只写一行,如果需要换行,需要操作者写入数据时加上换行符:
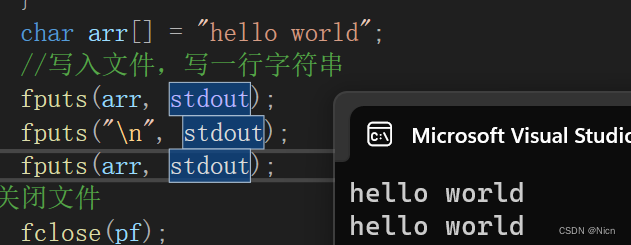
函数同样可以将数据输出到屏幕,将我们的文件指针pf换成我们的stdout:

接下来我们看一下文本行输入函数fgets():
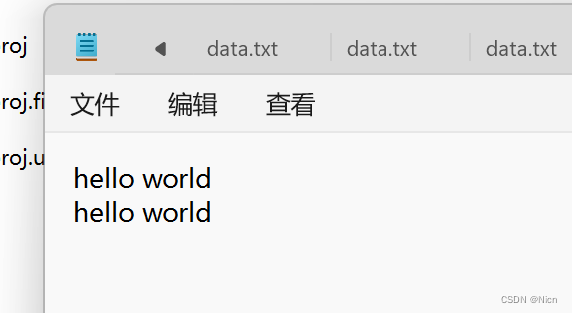
我们现在文件中写入数据:
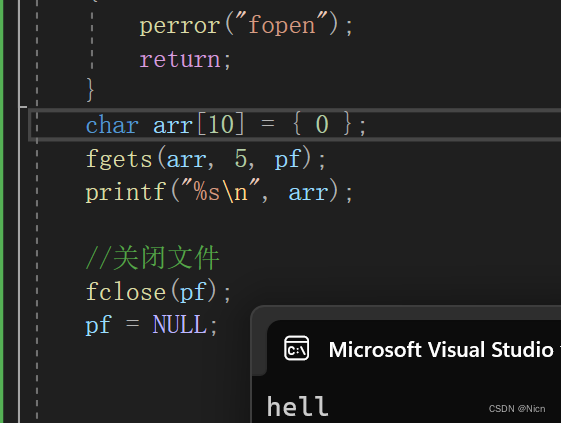
然后利用可读方式打开文件,读取文件内容输出到屏幕上:
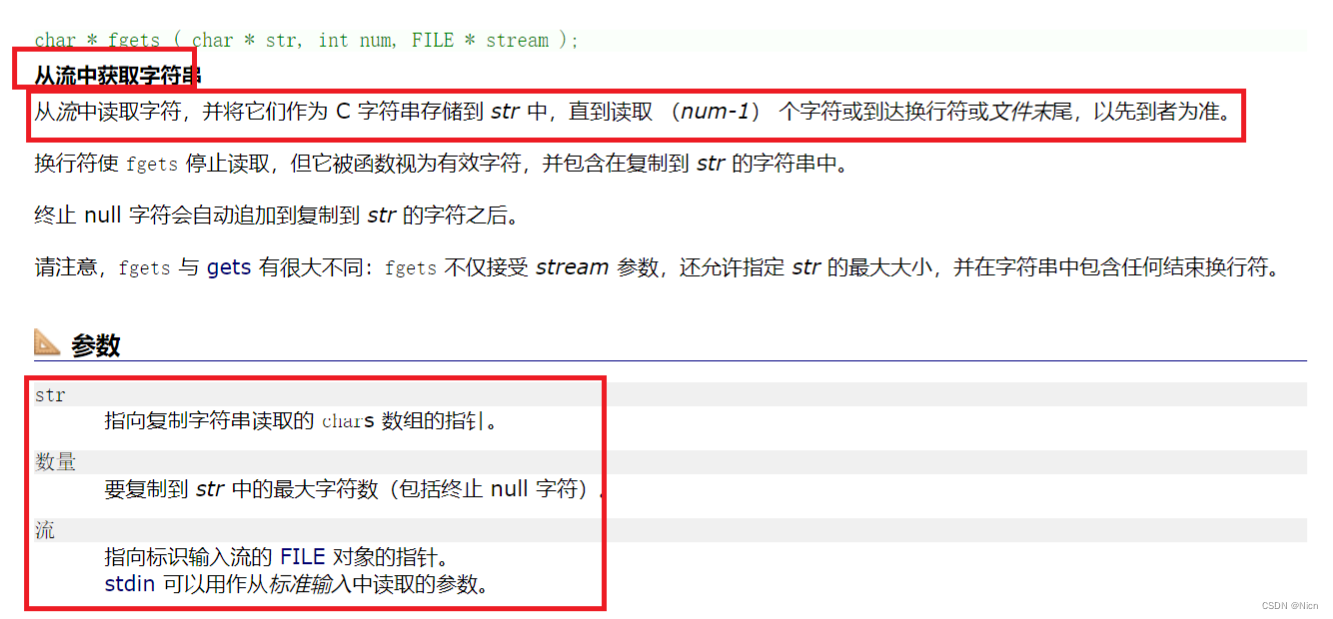

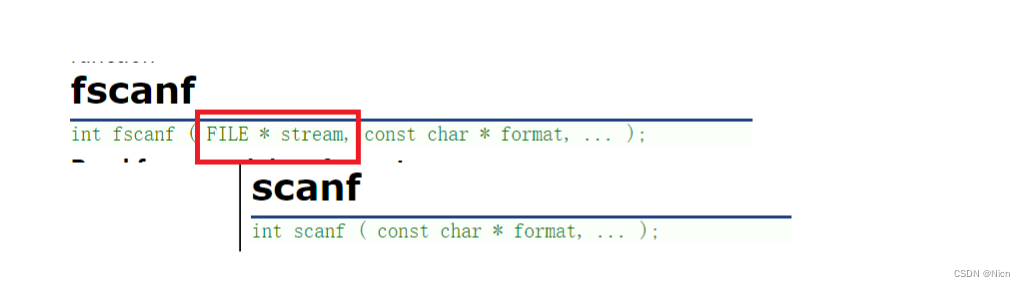
4.1.4格式化输入函数(fscanf)和格式化输出函数(fprintf):针对带有格式的数据
适用于所有流
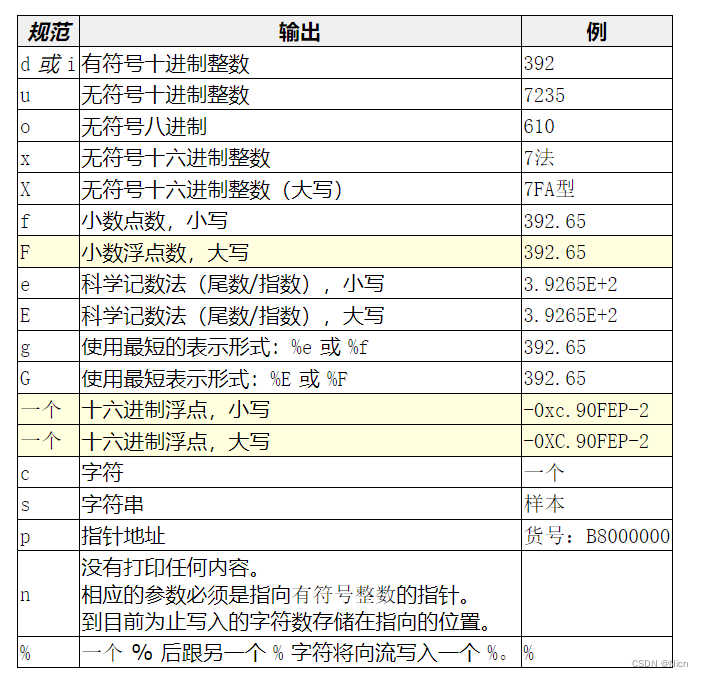
具体的格式有:
函数返回值:
①printfhefprintf对比使用
大概就知道了这个函数的用法:




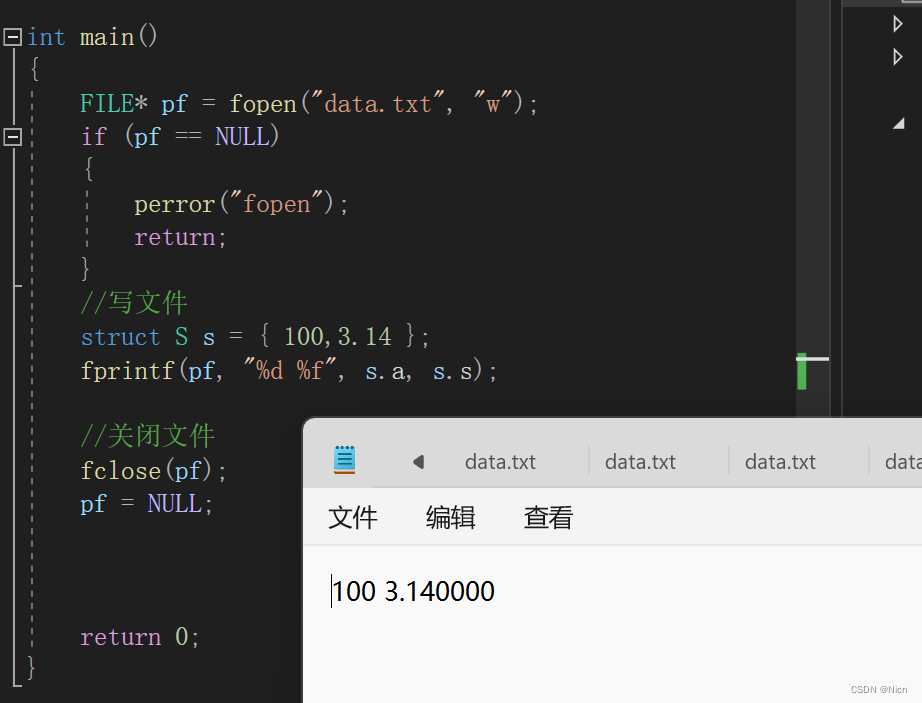
接下来我们看格式化读取输入函数
格式有
返回值:
和scanf函数对比:
用法举例:



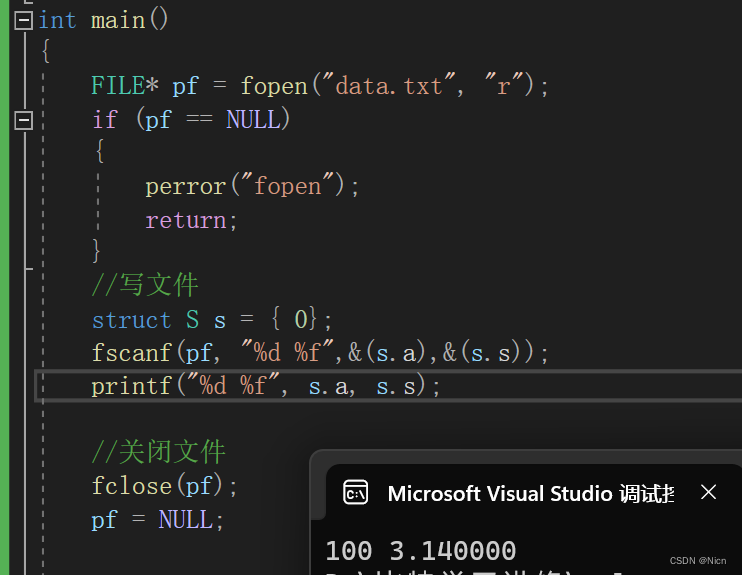
4.1.5 printf scanf fprintf fscanf sscanf sprintf简单对比
首先了解一下我们的sprintf函数:函数简单来说就是将我们的格式化的数据转化为字符串
然后我们从代码的使用中来了解一下这个函数的功能:
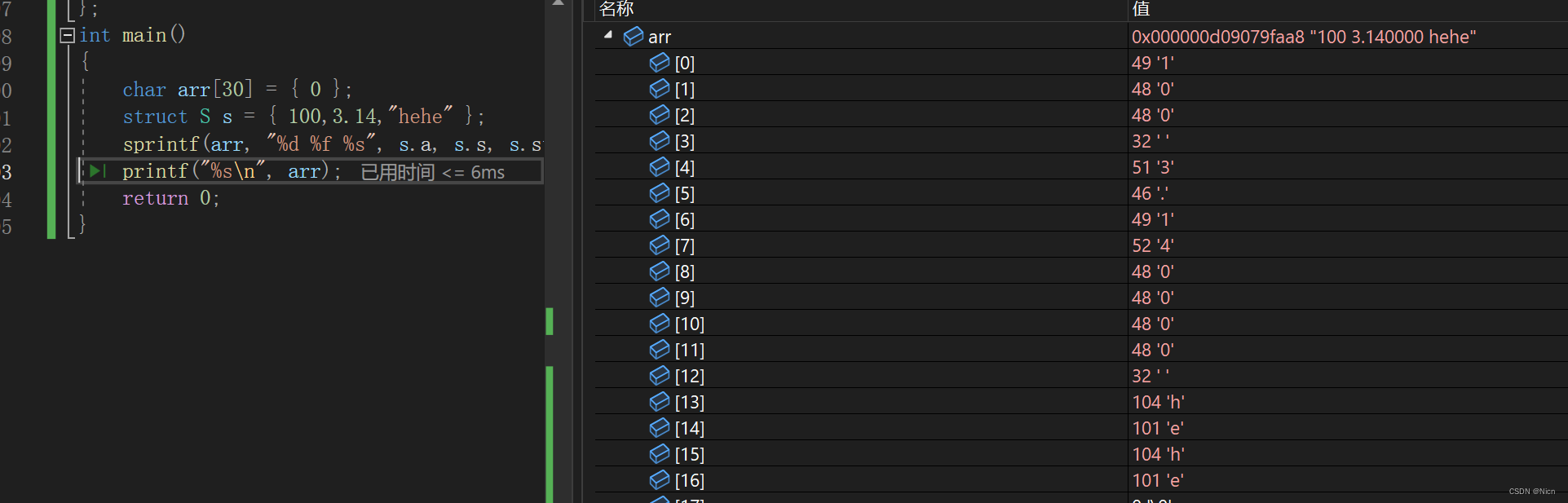
struct S { int a; float s; char str[10]; }; int main() { char arr[30] = { 0 }; struct S s = { 100,3.14,"hehe" }; sprintf(arr, "%d %f %s", s.a, s.s, s.str); printf("%s\n", arr); return 0; }将我们结构体中不同格式的数据转化为了字符串存储在arr中:
,
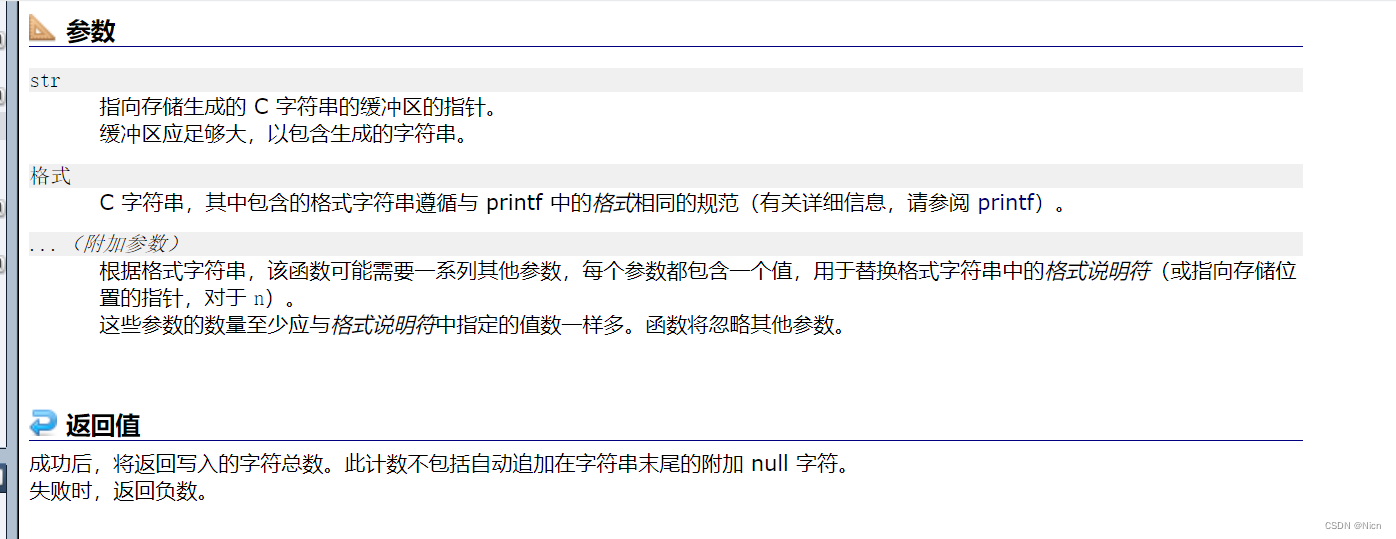
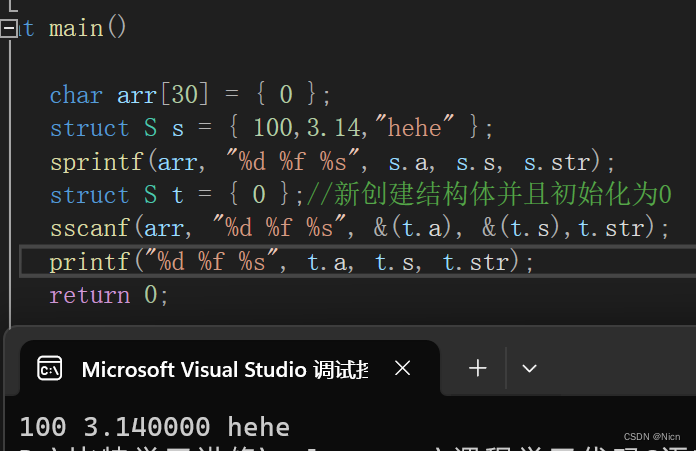
我们的sscanf函数就是将提取的字符串的数据转化为格式化的数据
我们使用代码来体会一下函数功能:




总结:
scanf:从标准输入流中读取格式化的数据
printf:向标准输出流写格式化的是数据
fscanf:适用于所有输入流的格式化输入函数
fprintf:适用于所有输出流的格式化输出函数
sscanf:从字符串中读取格式化数据
sprintf:将格式化的数据转化为字符串
上面的数据都是文本操作,人认识,接下来的函数是顺序写入二进制的数据:
4.1.6 二进制 输入函数(fread)二进制输出函数(fwrite)
①fwrite
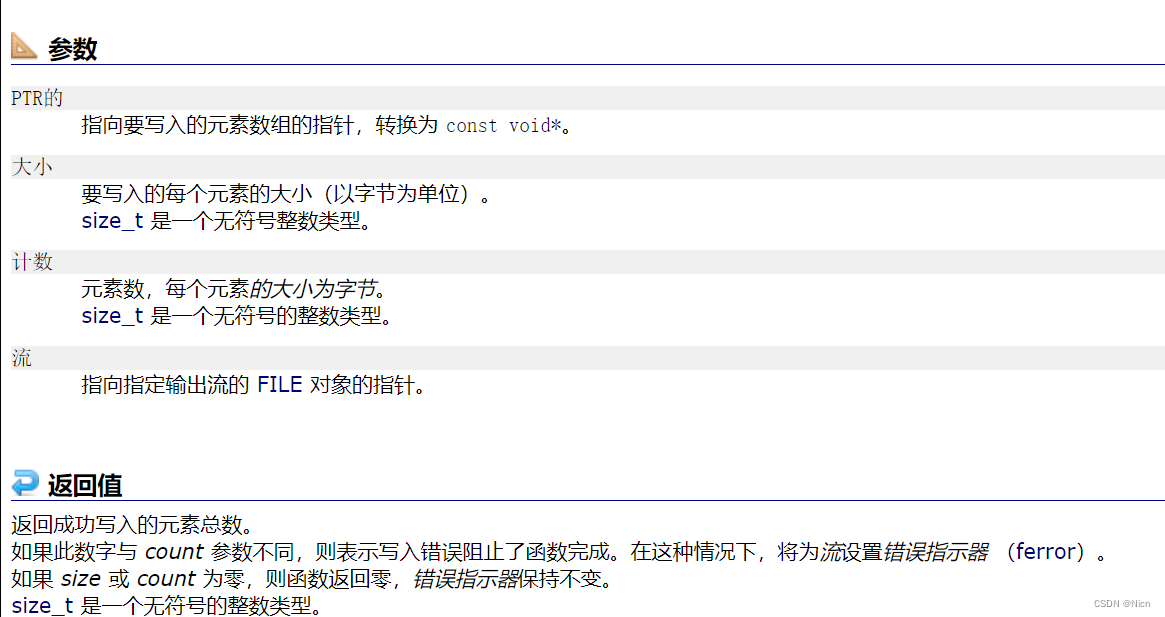
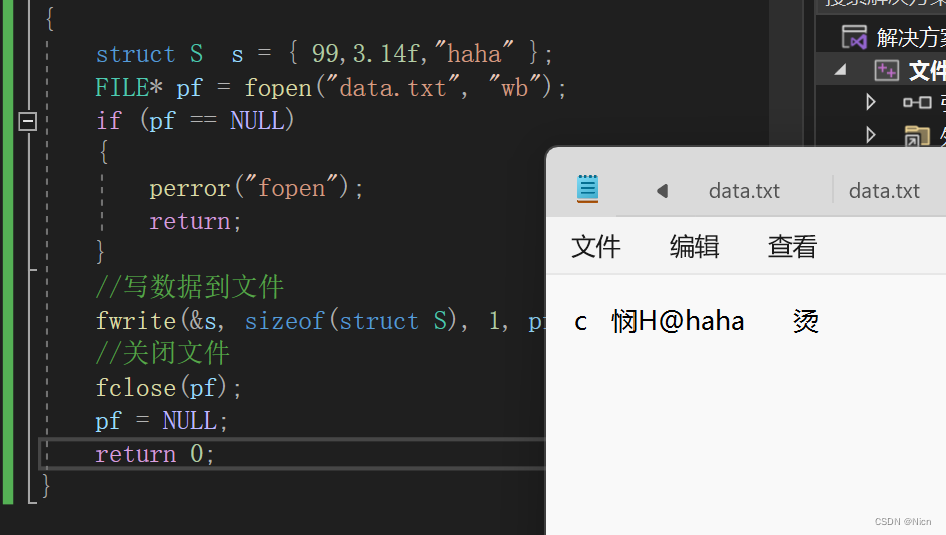
函数功能:从ptr指向的内存块里边,拷贝count个大小为size的数据到stream指向的流里面去
我们上手用代码了解一下:
运行我们看一下文件里面内容:
、
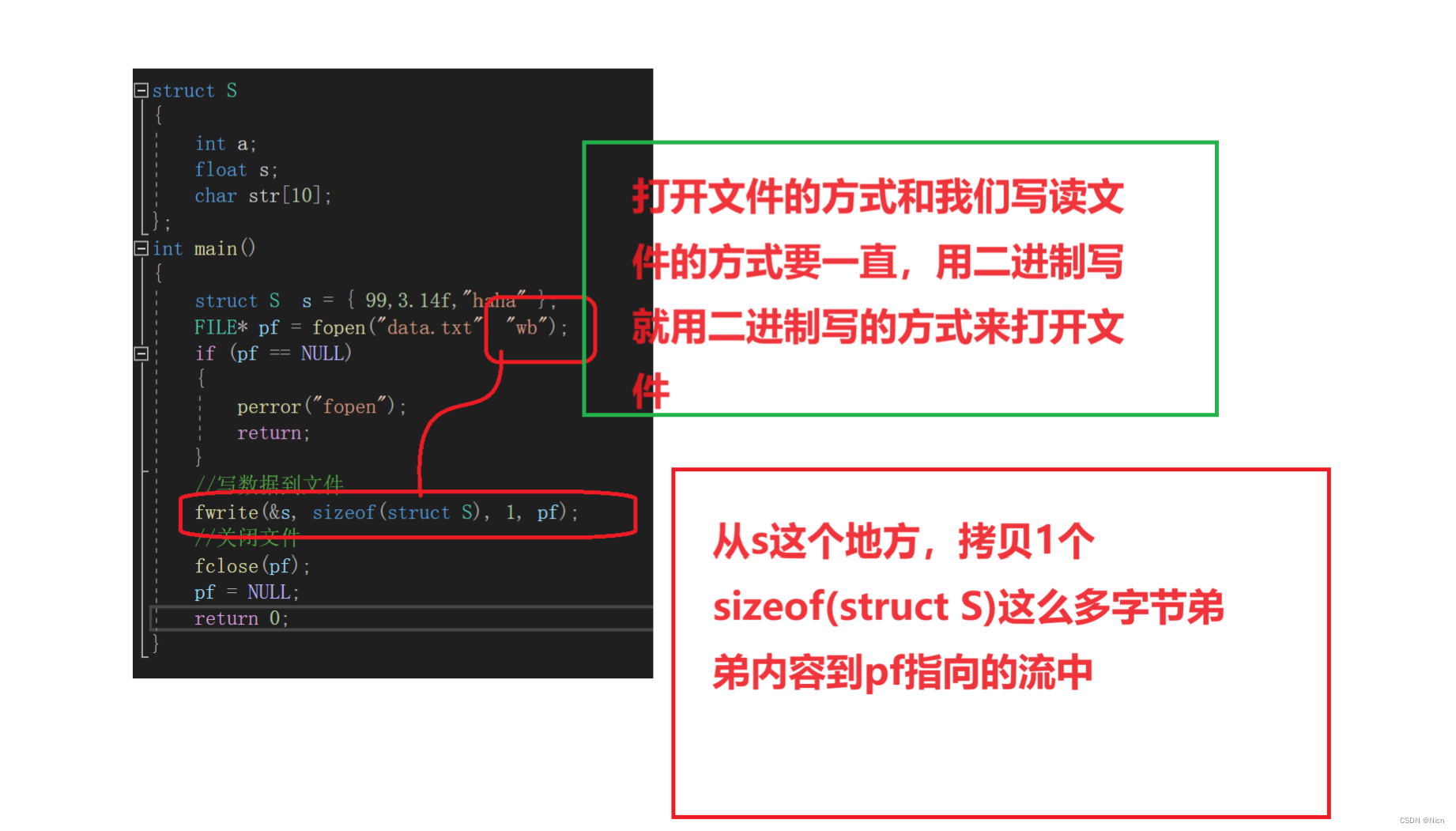
由于是二进制文件,所以人不可读。要用二进制方式读才可以栋,接下来我们就使用fread来读:

②fread
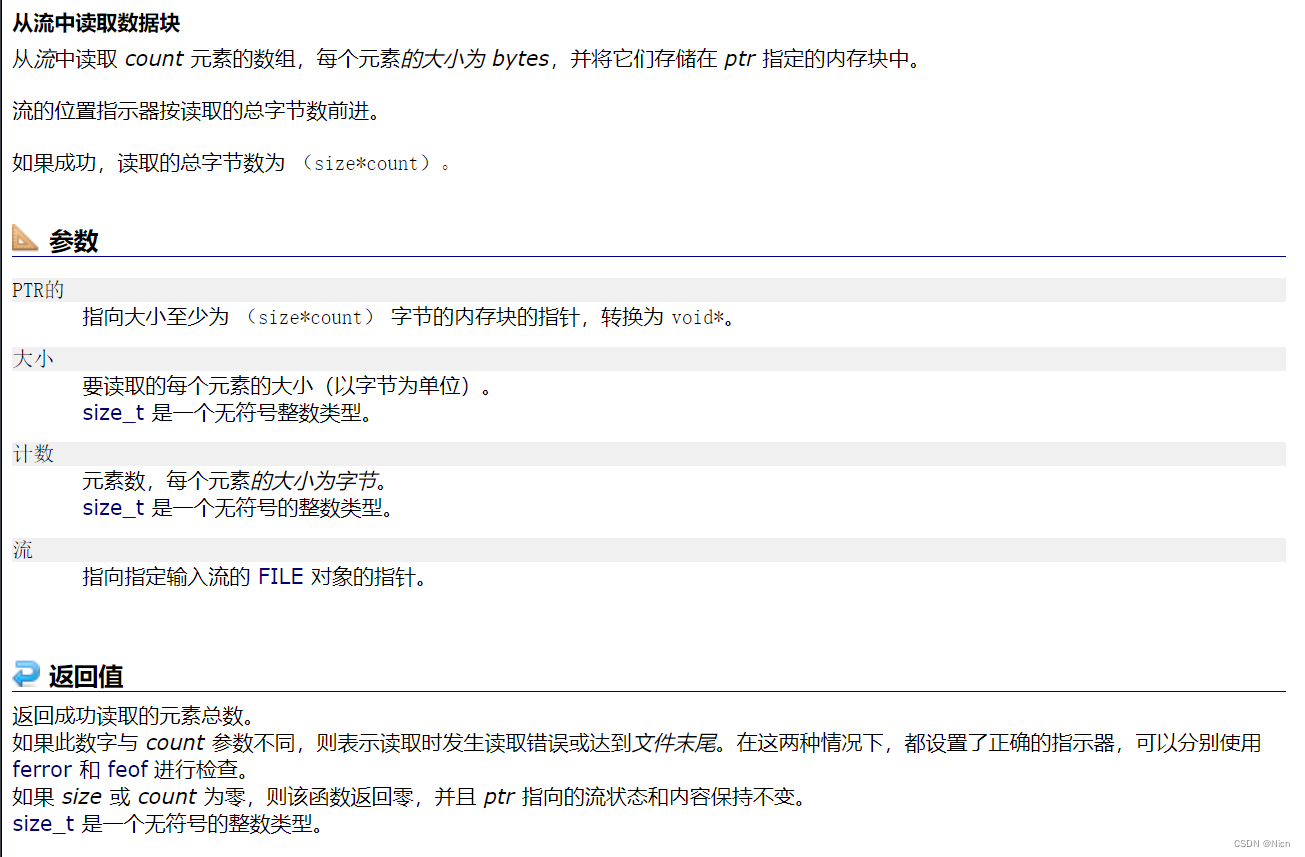
函数功能:从stream指向的流中,读取count个size的小的数据存放到ptr指向的空间中去
我们现在就用这个函数来读取我们上次用fwrite写入的数据:
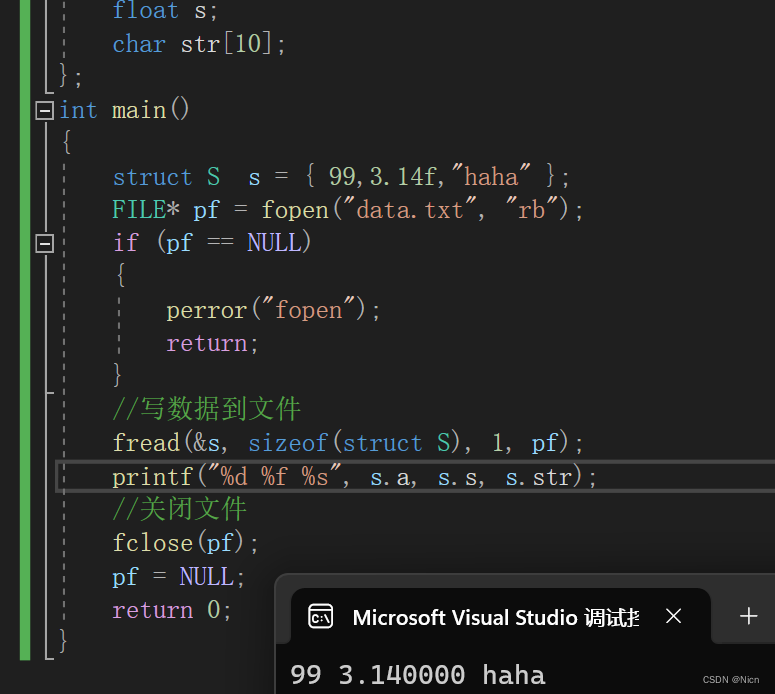
struct S { int a; float s; char str[10]; }; int main() { struct S s = { 99,3.14f,"haha" }; FILE* pf = fopen("data.txt", "rb"); if (pf == NULL) { perror("fopen"); return; } //写数据到文件 fread(&s, sizeof(struct S), 1, pf); printf("%d %f %s", s.a, s.s, s.str); //关闭文件 fclose(pf); pf = NULL; return 0; }

5. 文件的随机读写
想在文件的那个位置读就在那个位置读,想在文件的那个位置写就在文件的那个位置写,前提条件只要能定位到该随机位置。
5.1 fseek 函数
根据文件指针的位置和偏移量来定位文件指针。(就是移动我们的文件指针)
当打开文件时,文件指针是指向文件的起始位置的。
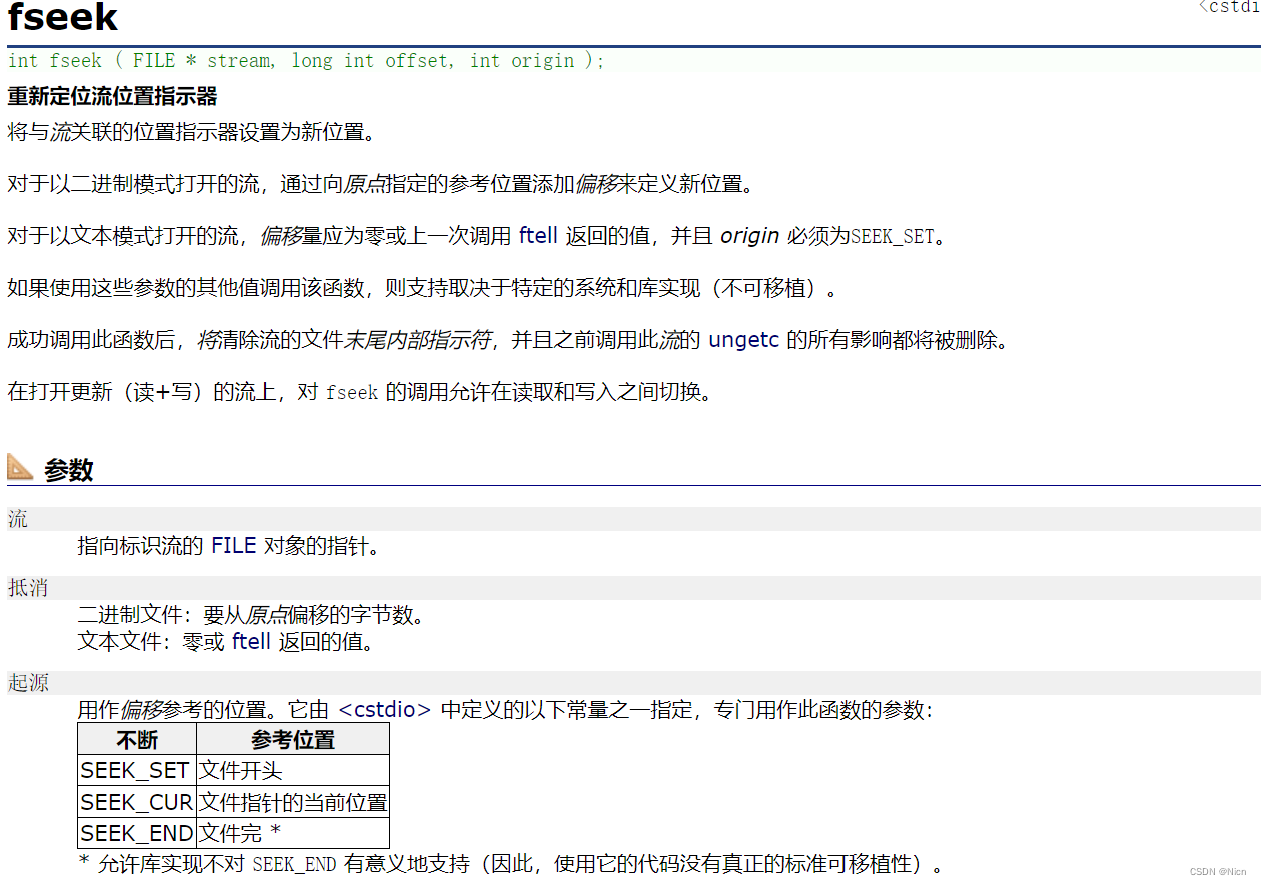
函数功能:根据文件指针的位置和偏移量来定位文件指针。
函数参数:第一个参数是目标流或者目标文件的指针
第二个参数是:偏移量
第三个参数很重要,是偏移的起始位置:当我们选取SEEk_SET的时候,偏移量从我们的文件开头来算
当我们选取SEEK_CUR的时候偏移量从我们当前文件指针的位置开始算
当我们选取SEEK_END的时候偏移量从我们的文件末尾算,此时传入的偏移量应该是负数
我们在代码中来举例子
我们现在文件中写入数据(方便大家理解)
然后我们目的想把我们文件中的f打印出来:
然后我们利用fseek函数将函数指针位置移动到我们的这个f的位置:
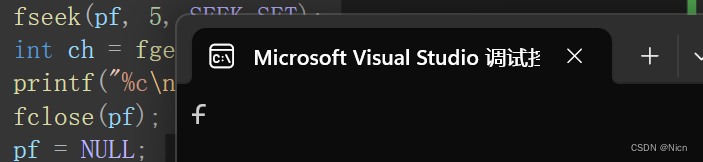
//我们定位文件指针指到f fseek(pf, 5, SEEK_SET);然后利用fgetc函数获取一个字符进行打印:
int main() { FILE* pf = fopen("data.txt", "r"); if (pf == NULL) { perror("fopen"); return; } //我们定位文件指针指到f fseek(pf, 5, SEEK_SET); int ch = fgetc(pf); printf("%c\n", ch); fclose(pf); pf = NULL; return 0; }
如果我们偏移起始位置应该是偏移-4位置得到我们的f,我们看一下,这里上面图上有误大家注意


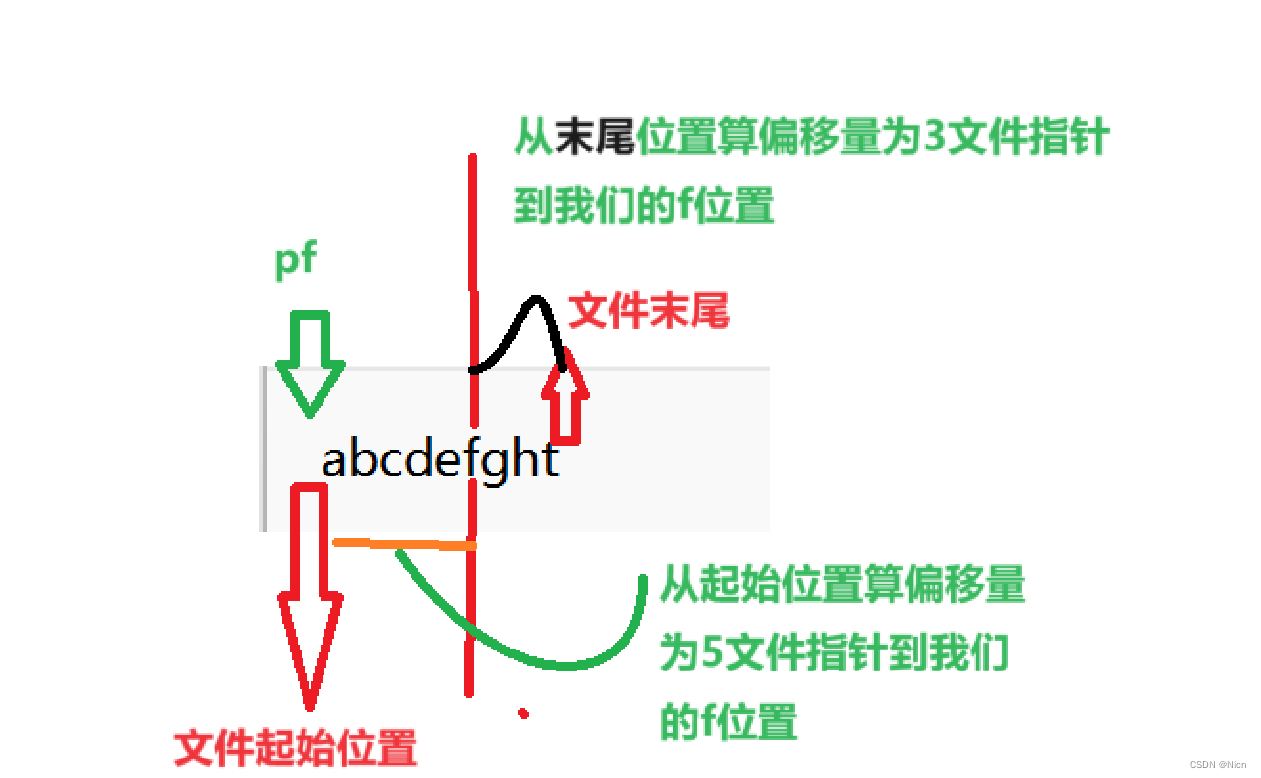
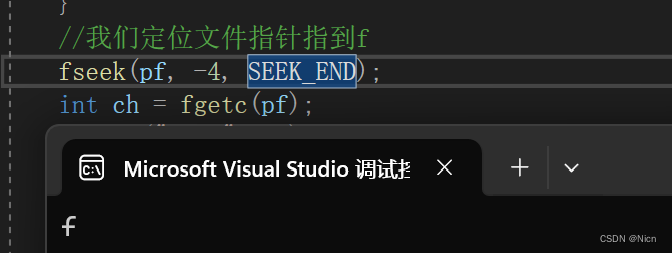
上述我们计算文件指针的偏移量是因为我们知道,而且数据内容也比较简单,如果我们数据负责呢或者我们也找不到指针在哪里了怎么弄,引入我们的ftel函数:
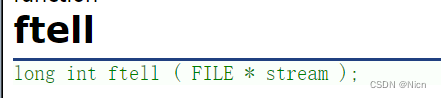
5.2 ftell
函数功能:返回文件指针相对于起始位置的偏移量
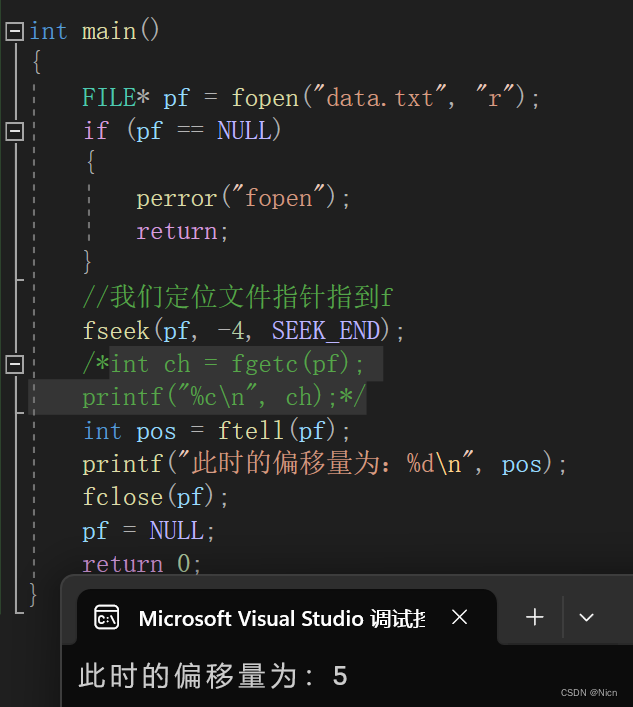
我们接着使用上面的代码,此时的指针应该指向f我们的偏移量应该是5,我们让ftell试一下。
这就是我们的ftell函数
5.3 rewind
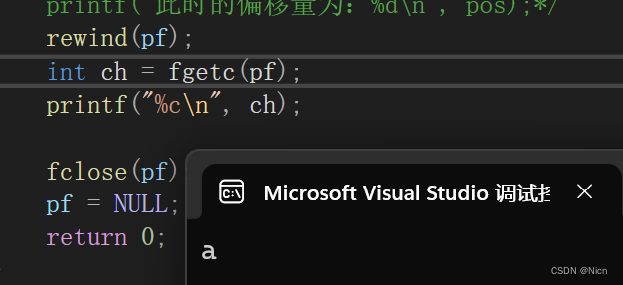
函数功能:让文件指针的位置回到文件的起始位置
我们继续使用上述代码,让指针回到我们起始位置打印a.
6. 文件分类:文本文件和二进制文件
根据数据的组织形式,数据文件被称为文本文件或者二进制文件。
数据在内存中以二进制的形式存储,如果不加转换的输出到外存,就是二进制文件。
如果要求在外存上以ASCII码的形式存储,则需要在存储前转换。以ASCII字符的形式存储的文件就是文本文件。
数据在内存中存储 :字符一律以ASCII形式存储,数值型数据既可以用ASCII形式存储,也可以使用二进制形式存储。原因我们来举个例子:
有整数10000,如果以ASCII码的形式输出到磁盘,则磁盘中占用5个字节(每个字符一个字节),而 二进制形式输出,则在磁盘上只占4个字节。
我们可以来试一下:
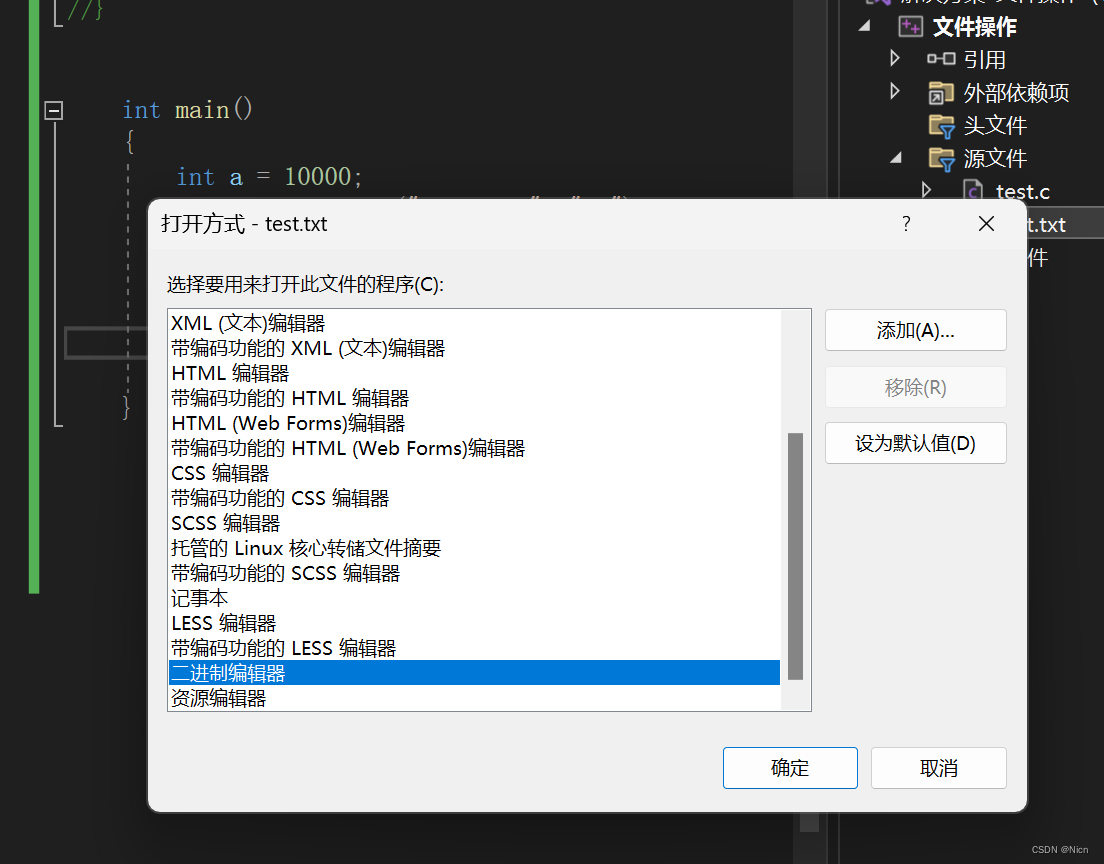
int main() { int a = 10000; FILE* pf = fopen("test.txt", "wb"); fwrite(&a, 4, 1, pf);//二进制的形式写到文件中 fclose(pf); pf = NULL; return 0; }添加现有项查看文件内容:使用二进制查看:
编辑器前面0是地址
发现确实如此
但是那种存储方式更省内存不确定。字符1只占一个字节,但是10000就占5个字节。

7. 文件读取结束的判定
我们需要判断文件读取是否结束。
7.1 被错误使用的feof
牢记:在文件读取过程中,不能用feof函数的返回值直接来判断文件的是否结束。
feof 的作用是:当文件读取结束的时候,判断是读取结束的原因是否是:遇到文件尾结束。 1. 文本文件读取是否结束,判断返回值是否为 EOF ( fgetc ),或者 NULL ( fgets )
例如:
fgetc 判断是否为 EOF .,是EOF就读取结束
fgets 判断返回值是否为 NULL .是NULL就读取结束
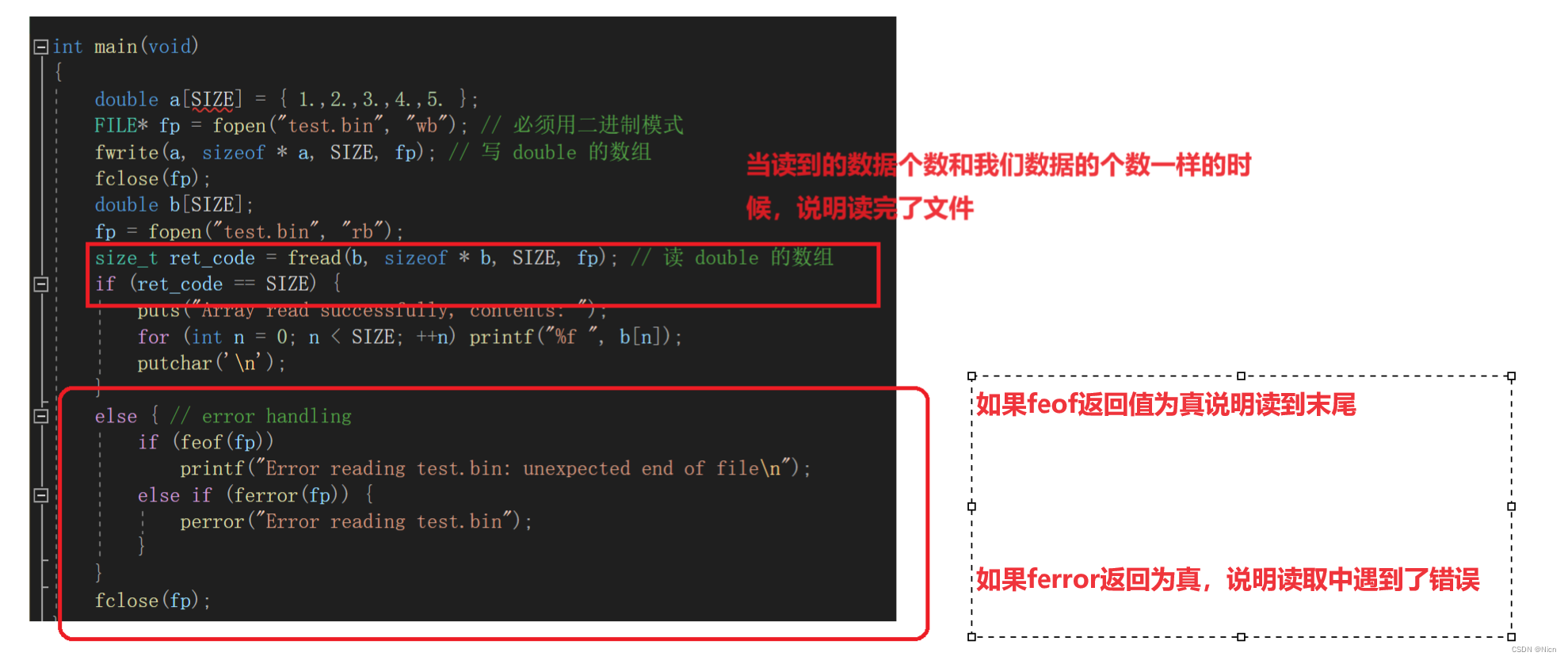
2. 二进制文件的读取结束判断,判断返回值是否小于实际要读的个数。
例如:
fread判断返回值是否小于实际要读的个数。
①例如:在文本文件中
②二进制文件中

8. 文件缓冲区
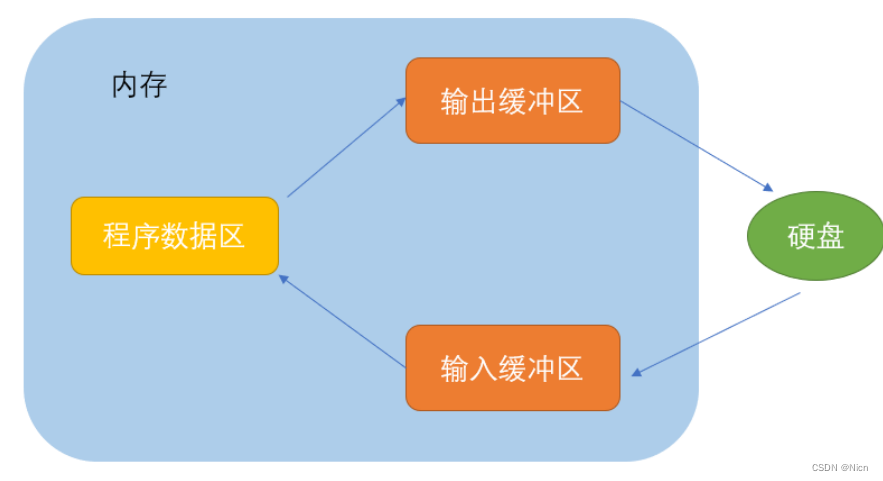
ANSIC 标准采用“缓冲文件系统”处理的数据文件的,所谓缓冲文件系统是指系统自动地在内存中为程序 中每一个正在使用的文件开辟一块“文件缓冲区”。从内存向磁盘输出数据会先送到内存中的缓冲区,装 满缓冲区后才一起送到磁盘上。如果从磁盘向计算机读入数据,则从磁盘文件中读取数据输入到内存缓 冲区(充满缓冲区),然后再从缓冲区逐个地将数据送到程序数据区(程序变量等)。缓冲区的大小根 据C编译系统决定的。
之所以存在是因为:如果每次送一个数据,就处理一下,那么程序做其他事的效率就会低下,那么这样会让处理更高效。
用代码举例:
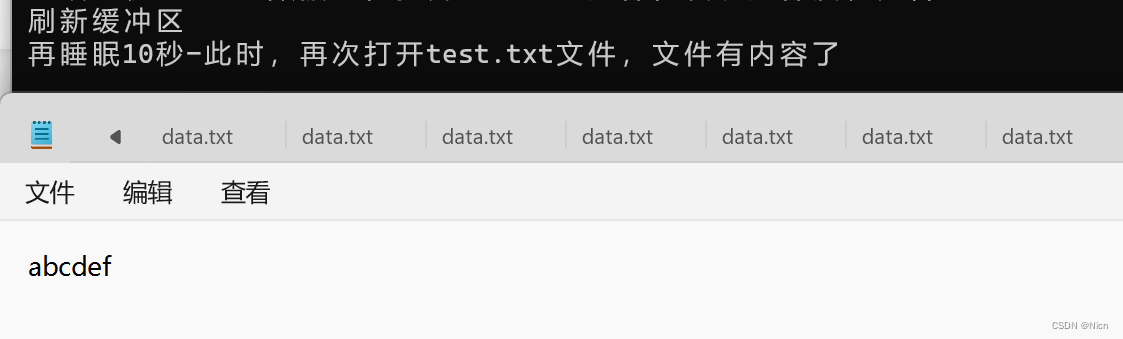
//VS2022 WIN11环境测试 int main() { FILE*pf = fopen("test.txt", "w"); fputs("abcdef", pf);//先将代码放在输出缓冲区 printf("睡眠10秒-已经写数据了,打开test.txt文件,发现文件没有内容\n"); Sleep(10000); printf("刷新缓冲区\n"); fflush(pf);//刷新缓冲区时,才将输出缓冲区的数据写到文件(磁盘) //注:fflush 在高版本的VS上不能使用了 printf("再睡眠10秒-此时,再次打开test.txt文件,文件有内容了\n"); Sleep(10000);//这里睡眠10s是为了防止认为所示fclose刷新的缓冲区 fclose(pf); //注:fclose在关闭文件的时候,也会刷新缓冲区 pf = NULL; return 0; }
所以确实存在缓冲区,fclose本身具有刷新缓冲区的功能。
缓冲区可以设置无缓冲,行缓冲等,大家可以多去了解了解。
这里可以得出一个结论: 因为有缓冲区的存在,C语言在操作文件的时候,需要做刷新缓冲区或者在文件操作结束的时候关闭文 件。 如果不做,可能导致读写文件的问题。

9.结语
以上就是本期的所有内容,知识含量蛮多,大家可以配合解释和原码运行理解。创作不易,大家如果觉得还可以的话,欢迎大家三连,有问题的地方欢迎大家指正,一起交流学习,一起成长,我是Nicn,正在c++方向前行的奋斗者,感谢大家的关注与喜欢。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









