






本章介绍pdf自动化办公——pdfplumber的使用。本文由于特殊因素,本人觉得还有所欠缺,建议先看结尾。
目录
导入库及文件
import pdfplumber
file = pdfplumber.open(r"C:\Users\流光、月影\Desktop\pdfplumber.pdf")1. 获取页码
file.pages
print(file.pages)
输出页码。如果想要统计总页码数,可以使用 len函数。以下所有操作都基于此之上。
2. 获取一个页面上的一个表格
page.extract_table()
由于该文件为某学校的文件,这里就不提供文件及代码了,仅供截图,请原谅。
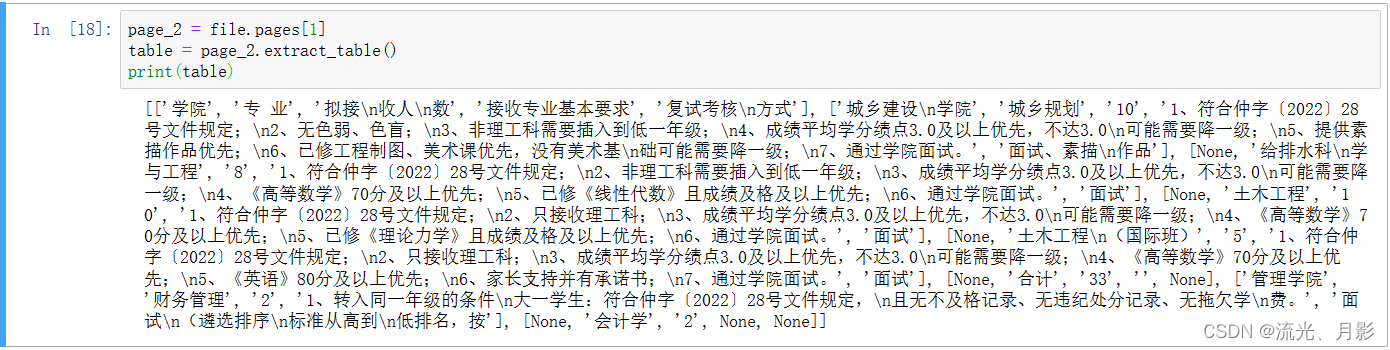
如果想要把该表转换成表格,可以通过pandas完成:
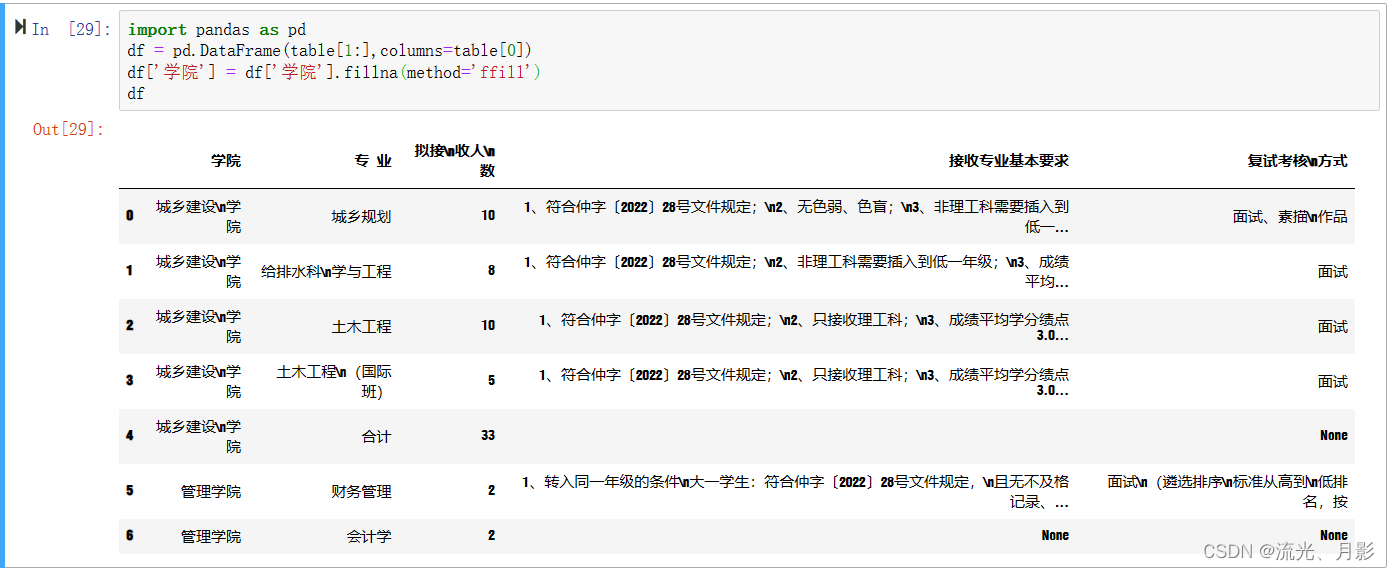
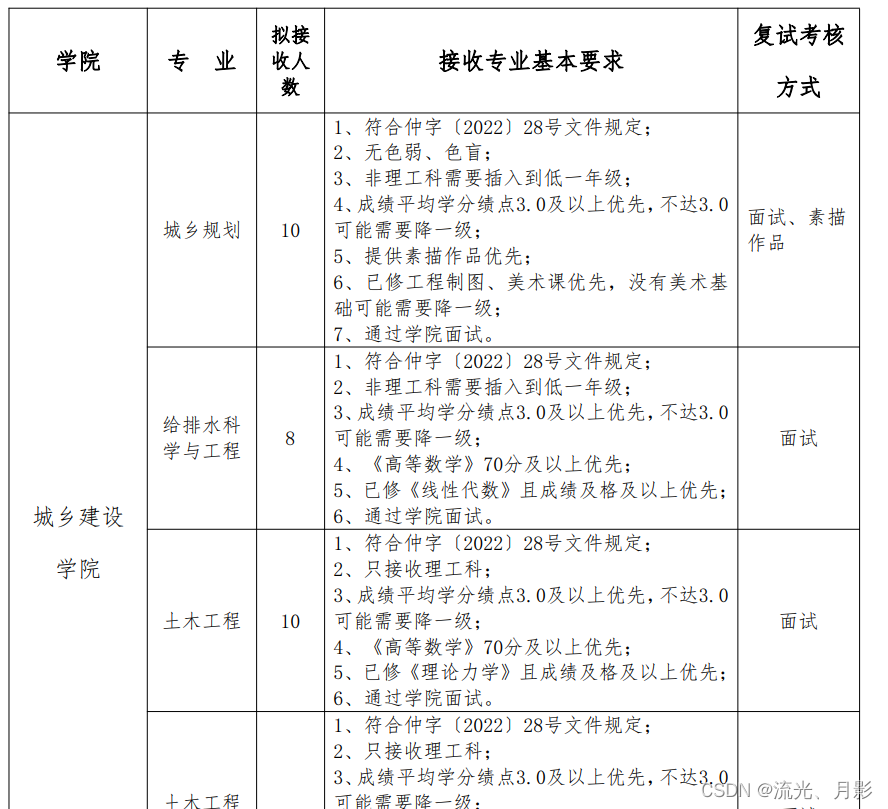
与原表并无多大区别。
3. 获取一个页面上的全部表格
page.extract_tables()
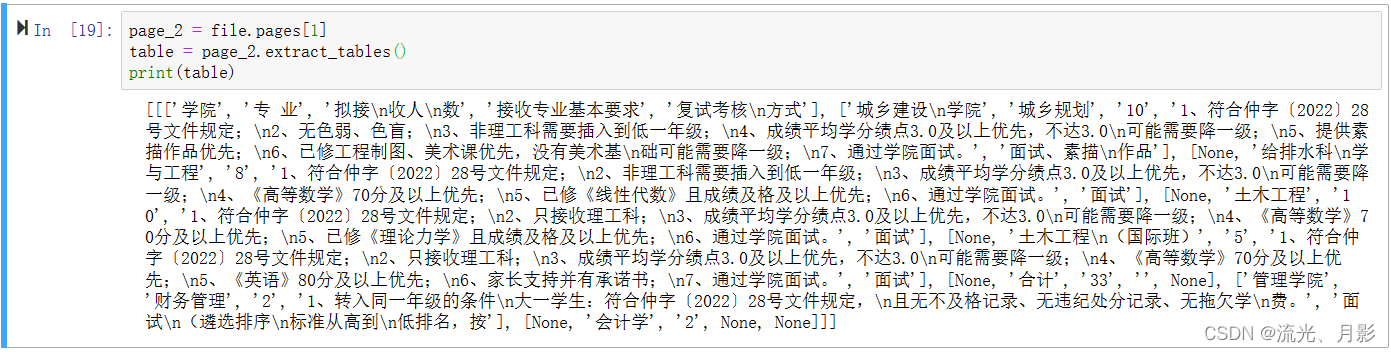
输出的内容相比于图2,首尾多了一个[]。我们可以看开头,一个[为一个列表(一行或一列);两个[[为一个面,相当于一个excel表格那样;三个[[[为多个面组成的三维结构,可表示多个面。这个案例一个面就相当于一个表。想要清楚地理解这个知识,需要有numpy和pandas基础。
4. 获取一个页面上全部文字
page.extract_text()

5. 获取当前页的页码
page.page_number 准确来说,是第几页,而不是页码,因为页码可以从任意页开始。
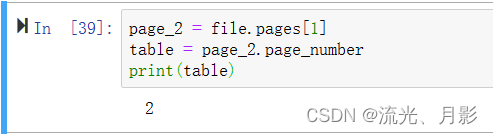
file.pages[1] 表示第2页( file.pages[0] 表示第1页)。
结尾
本文本人认为不够理想,因为没有给代码,但是由于文件的原因,可能不太方便,也不想带来任何麻烦,尽管可能没有,所以就不提供源文件了。由于没有源文件,提供代码感觉用处也不大,无法运行(看图的代码和输出分析可能更好)。如果浪费了大家时间,本人在这深深表示抱歉。
最后,记得关闭文件。如果是一个几个,问题不大,如果是几十个上百个,那要在每一个文件处理完后都要关闭,不然占用太多内存,影响运行效率。关闭文件代码如下:
file.close()














 137
137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









