







01 背景
Lancer是B站的实时流式传输平台,承载全站服务端、客户端的数据上报/采集、传输、集成工作,秒级延迟,作为数仓入口是B站数据平台的生命线。目前每日峰值 5000w/s rps, 3PB/天, 4K+条流的数据同步能力。
服务如此大的数据规模,对产品的可靠性、可扩展性和可维护性提出了很高的要求。流式传输的实现是一个很有挑战的事情,聚焦快、准、稳的需求, Lancer整体演进经历了大管道模型、BU粒度管道模型、单流单作业模型三个阶段的演进,下面我们娓娓道来。
02 关键词说明
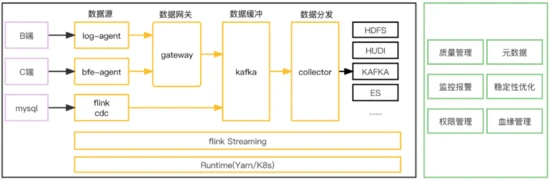
logid:每个业务方上报的数据流以logid进行标识,logid是数据在传输+集成过程中的元信息标识。
数据源:数据进入到lancer的入口,例如:log-agent,bfe-agent,flink cdc
lancer-gateway(数据网关):接收数据上报的网关。
数据缓冲层:也叫做内部kafka,用于解耦数据上报和数据分发。
lancer-collector(数据分发层):也叫做数据同步,可以根据实际场景完成不同端到端的数据同步。
03 技术演进
整个B站流式数据传输架构的演进大致经历了三个阶段。
3.1 架构V1.0-基于flume的
大管道数据传输架构(2019之前)
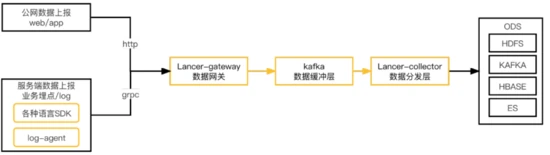
B站流式传输架构建立之初,数据流量和数据流条数相对较少,因此采用了全站的数据流混合在一个管道中进行处理,基于flume二次定制化的数据传输架构,架构如下:
-
整个架构从数据生成到落地分为:数据源、数据网关、数据缓冲、数据分发层。
-
数据上报端基本采用sdk的方式直接发送http和grpc请求上报。
-
数据网关lancer-gateway是基于flume二次迭代的数据网关,用于承载数据的上报,支持两种协议:http用于承载公网数据上报(web/app),grpc用于承载IDC内服务端数据上报。
-
数据缓冲层使用kafka实现,用于解耦数据上报和数据分发。
-
数据分发层lancer-collector同样是基于flume二次迭代的数据分发层,用于将数据从缓冲层同步到ODS。
v1.0架构在使用中暴露出一些的痛点:
1. 数据源端对于数据上报的可控性和容错性较差,例如:
-
数据网关故障情况下,数据源端缺少缓存能力,不能直接反压,存在数据丢失隐患。
-
重SDK:SDK中需要添加各种适配逻辑以应对上报异常情况
2. 整体架构是一个大管道模型,资源的划分和隔离不明确,整体维护成本高,自身故障隔离性差。
3. 基于flume二次迭代的一些缺陷:
-
逻辑复杂,性能差,我们需要的功能相对单一
-
hdfs分发场景,不支持exactly once语义,每次重启,会导致数据大量重复
3.2 架构V2.0-BU粒度的
管道化架构(2020-2021)
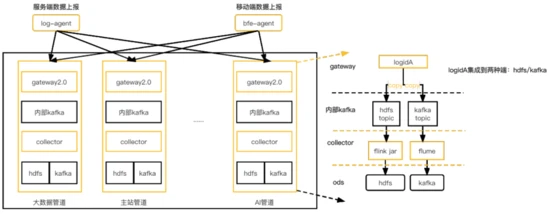
针对v1.0的缺陷,我们引入了架构v2.0,架构如下:
此架构的关键细节如下:
1. 强化了数据上报源端的边缘可控能力
-
服务器上部署log-agent承载服务端数据上报。
-
cdn上部署bfe-agent用于承载公网(web端、app端)数据上报。
-
log-agent/bfe-agent中集成数据缓冲、预聚合、流控、重试、降级等能力,数据上报sdk只需专注数据的生成和上报逻辑。
-
agent端基于logid的BU属性,将数据路由到不同的管道。
2. 数据管道以BU为粒度搭建,管道间资源隔离,每个管道包含整套独立的完整数据传输链路,并且数据管道支持基于airflow快速搭建。故障隔离做到BU级别。
3. 数据网关升级到自研lancer-gateway2.0,逻辑精简,支持流控反压,并且适配kafka failover, 基于k8s进行部署。
4. hdfs分发基于flink jar进行实现:支持exactly once语义保证。
V2.0架构相对于v1.0, 重点提升了数据上报边缘的可控力、BU粒度管道间的资源划分和隔离性。但是随着B站流式数据传输规模的快速增加,对数据传输的时效性、成本、质量也提出了越来越高的要求,V2.0也逐渐暴露出了一些缺陷:
1. logid级别隔离性差:
-
单个管道内部某个logid流量陡增,几倍甚至几十倍,依然会造成整个管道的数据分发延迟,
-
单个管道内分发层组件故障重启,例如:hdfs分发对应的flink jar作业挂掉重启,从checkpoint恢复,此管道内所有的logid的hdfs分发都会存在归档延迟隐患。
2. 网关是异步发送模型,极端情况下(组件崩溃),存在数据丢失风险。
3. ods层局部热点/故障影响放大
-
由于分发层一个作业同时分发多个logid,这种大作业模型更易受到ods层局部热点的影响,例如:hdfs某个datanode热点,会导致某个分发作业整体写阻塞,进而影响到此分发作业的其他logid, kafka分发同理。
-
hdfs单个文件块的所有副本失效,会导致对应分发任务整体挂掉重启。
4. hdfs小文件问题放大
- hdfs分发对应的flink jar作业为了保证吞吐,整体设置的并发度相对较大。因此对于管道内的所有logid,同一时刻都会打开并发度大小的文件数,对于流量低的logid,就会造成小文件数量变大的问题。
针对上述痛点,最直接的解决思路就是整体架构做进一步的隔离,以单logid为维度实现数据传输+分发。面临的挑战主要有以下几个方面:
-
如何保证全链路以logid为单位进行隔离,如何在资源使用可控的情况下合理控流并且保证数据流之间的隔离性
-
需要与外部系统进行大量的交互,如何适配外部系统的各种问题:局部热点、故障
-
集成作业的数量指数级增加,如何保障高性能、稳定性的同时并且高效的进行管理、运维、质量监控。
3.3 架构V3.0-基于Flink SQL的
单流单作业数据集成方案
在V3.0架构中,我们对整体传输链路进行了单作业单数据流隔离改造,并且基于Flink SQL支撑数据分发场景。架构如下:
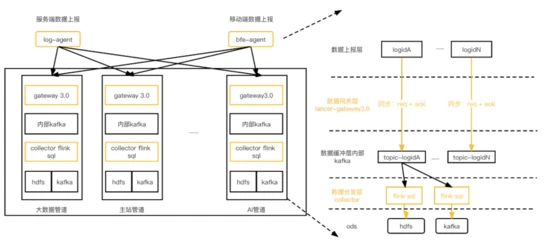
相比v2.0, 资源池容量管理上依然以BU为粒度,但是每个logid的传输和分发相互独立,互不影响。具体逻辑如下 :
-
agent:整体上报SDK和agent接收+发送逻辑按照logid进行隔离改造,logid间采集发送相互隔离。
-
lancer-gateway3.0:logid的请求处理之间相互隔离,当kafka发送受阻,直接反压给agent端,下面详细介绍。
-
数据缓冲层:每个logid对应一个独立的内部kafka topic,实现数据的缓冲。
-
数据分发层:分发层对每
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









