






0 项目说明
基于网络爬虫的新闻采集和订阅系统的设计与实现
提示:适合用于课程设计或毕业设计,工作量达标,源码开放
1 项目说明
本系统利用网络爬虫我们可以做到对网络上的新闻网站进行定时定向的分析和采集,然后把采集到的数据进行去重,分类等操作后存入数据库,最后提供个性化的新闻订阅服务。考虑了如何应对网站的反爬虫策略,避免被网站封锁爬虫。在具体实现上会使用 Python 配合 scrapy 等框架来编写爬虫,采用特定的内容抽取算法来提取目标数据,最后使用 Django 加上 weui 来提供新闻订阅后台和新闻内容展示页,使用微信向用户推送信息。用户可以通过本系统订阅指定关键字,当爬虫系统爬取到了含有指定关键字的内容时会把新闻推送给用户。
2 系统需求
基于网络爬虫的新闻采集与订阅系统要实现新闻数据抓取,数据过滤,数据筛选,数据展示,新闻订阅,推送等服务和功能。
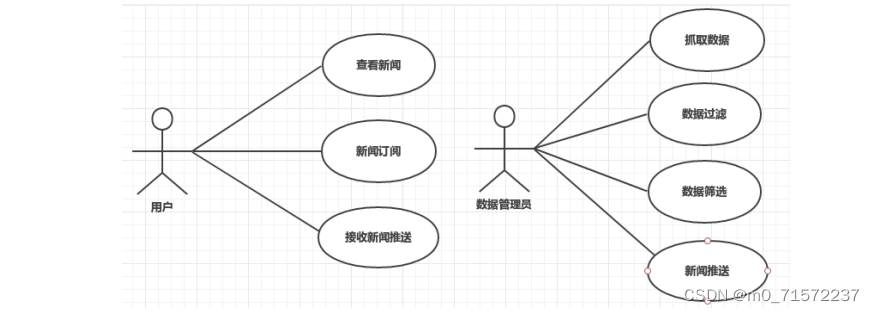
本系统主要用于以下几类人员:
数据管理员,完成数据的抓取,过滤与筛选,新闻的推送,以及本系统管理与维护等。
用户,在网页上进行新闻订阅,通过微信接收订阅新闻的推送,点击进入对应新闻展示页面等。
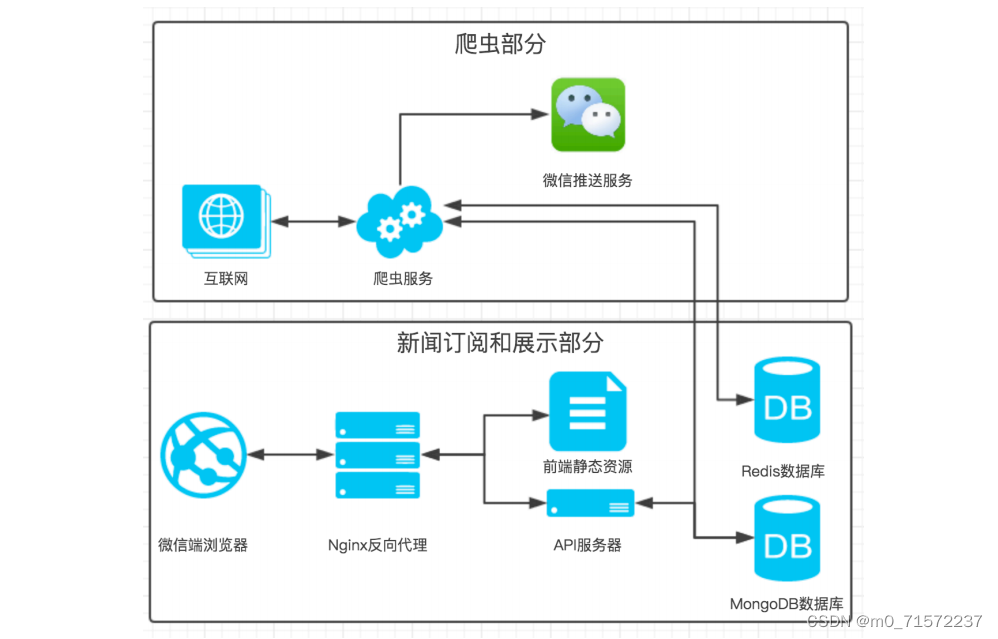
3 系统架构
本新闻采集与订阅系统分别由爬虫部分与新闻订阅和展示部分构成,在新闻订阅与展示部分采用基于 C/S 的架构,代码的组织方式为 MVC 三层结构,其中的三个层次分别为视图层(View )、控制器层(Controller)和模型层(Model)。代码整体采取前后端分离的方式,前端负责视图层,后端负责模型层和控制器层,客户端使用微信和网页实现, 前后端通讯使用 AJAX 交换 JSON 的方式。
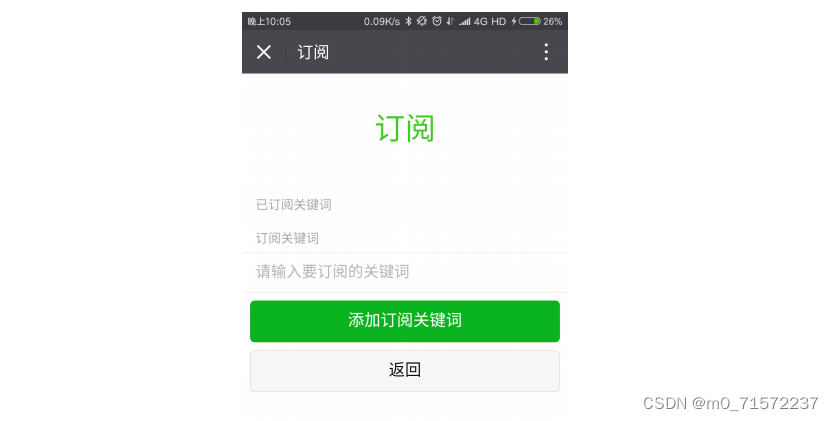
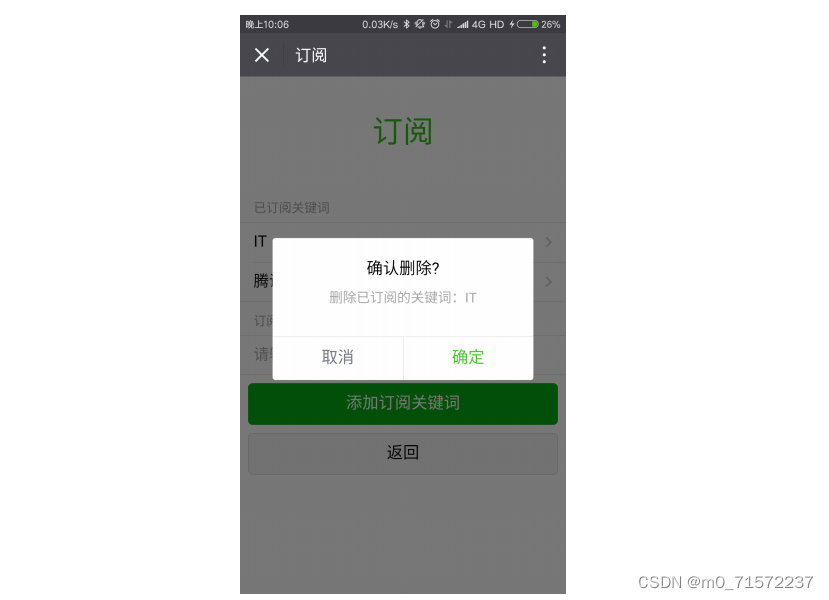
4 效果展示

5 论文目录
目 录
第一章 引言…………………………………………… 1
1.1 项目的背景和意义 ……………………………………….1
1.2 研究开发现状分析…………………………………………1
1.2.1 个性化新闻服务现状 ……………………………….1
1.2.2 网络爬虫研究现状 …………………………………….2
1.2.3 项目的范围和预期结果 ……………………………2
1.3 论文结构简介 ………………………………………………3
第二章 技术与原理……………………………………… 4
2.1 技术选型 ………………………………………………….4
2.1.1 Python 语言介绍 ……………………………………4
2.1.2 Scrapy 框架介绍 ………………………………………4
2.1.3 Django 框架介绍 ……………………………………5
2.1.4 MongoDB 数据库介绍 ……………………………5
2.1.5 AJAX 介绍 ………………………………………………5
2.2 相关原理介绍 ………………………………………………6
2.2.1 网络爬虫介绍 ……………………………………………6
2.2.2 关键词提取技术 ……………………………………….6
2.2.3 智能推送技术 ……………………………………………7
第三章 系统需求分析…………………………………… 9
3.1 新闻订阅系统用例析取 …………………………………9
3.2 新闻订阅系统用例规约 ……………………………….9
3.2.1 新闻订阅………………………………………………9
3.2.2 新闻推送 ………………………………………………11
第四章 新闻采集与订阅系统的设计……………… 13
4.1 系统架构及原理 ………………………………………13
4.2 系统模块设计 ……………………………………………15
4.2.1 爬虫采集模块设计 …………………………………15
4.2.2 爬虫去重模块设计 …………………………………16
4.2.3 防反爬虫模块设计 …………………………………16
4.2.4 爬虫存储模块设计 …………………………………17
4.2.5 消息推送模块设计 …………………………………17
4.2.6 消息订阅与展示模块设计 ………………………17
4.3 数据库设计 ……………………………………………….18
第五章 新闻采集与订阅系统的实现……………… 19
5.1 系统框架实现 ……………………………………………19
5.2 爬虫采集模块实现 …………………………………….21
5.3 防反爬虫模块实现 …………………………………….22
5.4 爬虫存储模块实现 ………………………………………22
5.5 消息推送模块实现 …………………………………….23
5.6 消息订阅与展示模块实现 …………………………25
第六章 系统部署……………………………………… 30
6.1 部署机器概述 ……………………………………………30
6.2 配置环境 …………………………………………………30
6.3 系统运行 …………………………………………………31
第七章 总结与展望……………………………………. 33
7.1 总结 …………………………………………………….33
7.2 展望 …………………………………………………….33
参考文献 …………………………………………… 34
致谢 …………………………………………… 35
附录 …………………………………………… 36















 1124
1124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









