






最近有一些其他想法,所以把原来的文章拿来重新整理一下。
工作中时不时会接触一些性能测试的内容,会做一些性能优化的工作。这里斗胆总结一下,主要是想看看自己对于应用系统性能的理解,主要体现在性能测试的基础概念,测试的方式方法,还有性能问题的测试的分析策略等。
内容更多是想表达一下自己对这个问题的思考方法,但顾名思义非专业,强调纯属自己的看法,切勿别被忽悠瘸了,如有不当之处,希望大家可以指正。
初识性能测试
性能测试主要就是测试一下系统在有压力访问下的表现,以便于了解系统在不同压力下的瓶颈,从而找到后续系统性能优化的方向,同时也是为了评估资源,在应急扩容时能够达到预期效果。
我记得2011年的双十一,京东举办卖书的活动,人太多结果系统就不行了,东哥说加三倍机器活动再搞一天,结果第二个还是被打脸了。这个事情说明,不是什么时候加机器就能解决问题的,特别是没针对瓶颈来解决的话,通常结果就是事倍工半,就是打脸。
说到性能测试,主要就是理解这么几个关键指标。
-
latency,延时,表现为响应时间,就是请求-响应的时间差,越小越好。
-
throughput,表现为TPS 就是每秒完成的事务数,简单的场景可以理解为完成多少次请求,反正就是越大越好。
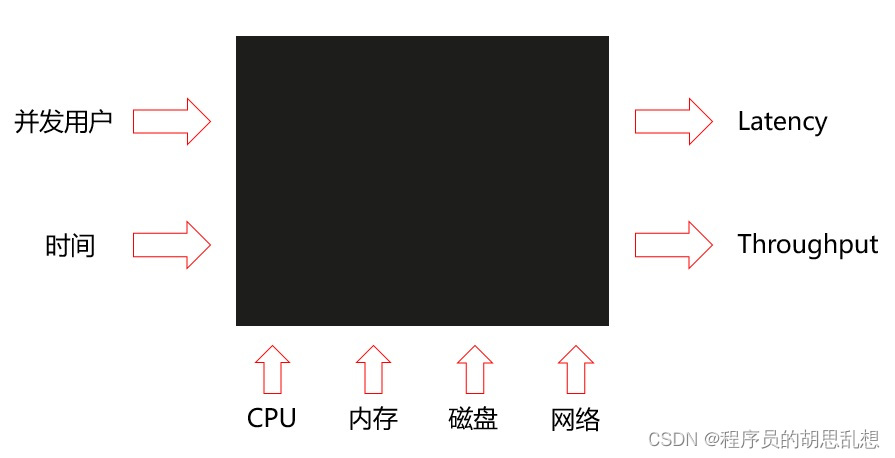
如上图,我们把系统想象成一个黑盒f,在一定的并发并发用户下,持续一段时间运行最终得到一个可以接受的lantency, 还有比较高的throughput。
我发现有些同学容易在压测目标上犯错误,特别是面对的是新建设的系统时,不断的加并发用户,达到一个最高的tps就完事。实际上我们的目标是想了解在可接受的响应时间内,达到最高的TPS. 当然这都是在一定资源的情况下达到的, 通常来说,响应时间会随着tps上涨而增加,并到了一定程度之后,响应时间增加的比较快,而tps出现下降。
所以,系统瓶颈通常出现在tps达到峰值之前。
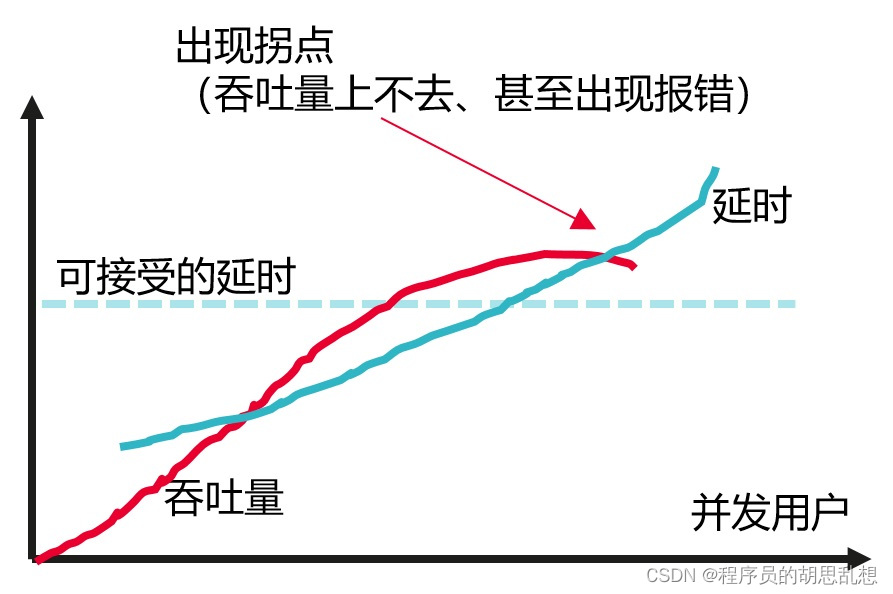
可以用一个简单的例子来类比,好比有一条高速路(系统),平时的时候,跑在路上的车多一些也没关系,一样很快(路上变化不大), 高速路使用效率高(可以通过更多车),但节假日车实在太多,虽然通过的车也很多,但就会感觉变堵变慢(路上明显多花时间), 甚至高速路变停车场,路上时间大幅度增加,通过的车反而少了。
在压测的过程中,还有一个并发用户的概念,他是用来模拟并发用的。这里就经常有个问题,我们想要达到一个目标TPS, 需要评估用多少并发用户的问题。要用多少并发用户,也是很多人犯错的地方,经常不看情况随意增加,这主要原因和前面的类似,就是过于关注tps造成的。这里还是要做个简单分析的,也不复杂,假设一次请求要100毫秒的响应时间,那么一个并发用户最多就能贡献10个tps。如果系统远没有达到瓶颈,那么增加用户,就能有很好的效果。例如增加到10个用户,就可以达到100tps, 实际上是不能做到完全线性的, 但是有这个趋势就好了,因为会消耗很多的资源在管理上了,例如资源竞争控制,垃圾回收等等,但是理想的情况就是这个衰减很慢。
可能还会注意到有个时间线,通常表现为一开始比较差,慢慢的上升直到性能数据相对稳定,这个主要原因是应用没有热身, 资源没有准备好应付大流量,常见的场景有代码JIT,各种缓存的数据预热等等。后面就会表现得比较平稳。但有时候存在下降的情况,或着毛刺,有可能的原因有:
-
数据的大量堆积导致效率下滑,常见有日志空间不足,测试数据在数据库堆太多太快影响效率(例如主要体现在统计信息陈旧)。
-
缓存失效,例如同时失效这种情况,也会出现毛刺。
-
有其他任务影响,例如定时触发的一些任务。
即使tps比较平滑,也可能出现耗时有波动,只盯着平均耗时,这就是另外一个误区,平均耗时固然重要,但是波动过大或者经常有毛刺也可能有问题,所以也要观察一下90% 95%之类的耗时,看看偏差是否过大。
总体来说,要注意避免几个误区: 不要一上来就上大用户并发,不要只想着憋出最大tps,不要只关注平均耗时。
谈策略与思路
具体到了一个特定的系统或者特定的场景,就得先谈谈整体的策略思路上的几个要点。
了解部署架构
了解系统的部署,是我们在性能测试之前做的第一件事。特别是当你要解决问题的时候,如果对系统不了解,很容易就让问题描述给带偏了。系统是一个整体,但给你的信息通常是一个局部的信息,甚至是曲解过的信息。所以通常接到一个任务,我要从压测客户端到系统的各个环节都画一下图, 包括经常被忽略的反向代理、内部的服务交互情况、数据库、redis、第三方接口等等,明确一下压测用例的交互路径。在后续的性能测试中可以方便定界,当然如果熟悉系统架构加上调用链的支持,定界就更加容易。
按之前的经验,一来就被卷入细节,很容易走偏,推导结论的逻辑基础其实是不牢固的,做出的优化策略也很难完全靠谱。
认识性能基准
就像前面提到的,目标是对当前要测试的用例,会有一个性能表现心里打个底,无论你是想要增加并发用户,还是增加实例数,给一个推导的依据。
通常我是这样做的,用来估算一个基准值,就是一个并发用户正常可以达到什么程度,例如10tps,然后看能否达到增加用户TPS能增加的效果,例如5个能不能到50tps,随着TPS到顶的时候,再看看增加资源是否可以继续增加。
我们遇到常见的误区,就是一来就对着目标性能,直接就堆上一堆实例,行了一把过,不行继续堆,缺乏对系统变化的理解,例如延时怎么变化,TPS怎么变化,资源怎么变化。另外就是要有预期,例如加用户,预计能不能提升TPS,理由是什么,实际没效果也得脑补脑补。总之测试也是有一定目的性的,要么证明一些内容,要么否定一些内容。
确定优化方向
二八原则,根据整体的耗时占比,主要确定优先分析和优化的方向,假设固定到某一个服务,深入内部,好的方式还是日志, 如果有访问数据库,redis,业务处理的时间信息,再结合明显数据,相对容易就可以找到是调用过于频繁,还是单次过慢的问题。
这里常见的问题,就是压测中收集信息不足,经常是压测结束了,有些过程数据缺失无法判断,需要再来一遍。所以,压测前要想好哪些东西要记录,并确认好当前有没有记录,没有的怎么记录。
还有一个需要注意的地方,就是调优的时候避免一次改多处地方。有时候分析压测结果后,我会同时提几个可以优化的点,有些可能会效果明显,有些只是局部优化,有些可能只是锦上添花而已,设置可能是有相互影响的,在实操的时候,优化手段尽量不要一次用上,这样会让压测效果更好评估。
评估资源
当然系统的资源都不是无限制的,一般会是cpu、内存、磁盘、网络的消耗,这需要有一个平衡。最简单的看法,延时体现在什么,我们接到一个任务-干活-返回。其中干活就分为两个部分,真的在干活(计算),主要使用的cpu, 还有一部分是等待,表面上是怎么不消耗cpu的。而等待是普遍存在的,例如网络请求、文件读写等等,主要表现为io操作。
按照这两类资源的使用情况,通常分为io密集型,cpu密集型两类。例如我们常见的数据库,对两类资源都很高要求。一般的网站、管理系统, 属于io密集,内存数据库、缓存系统等,大多属于cpu密集。当然没有绝对的,需要根据实际情况来,优化也是朝着提高资源利用率的方向去。
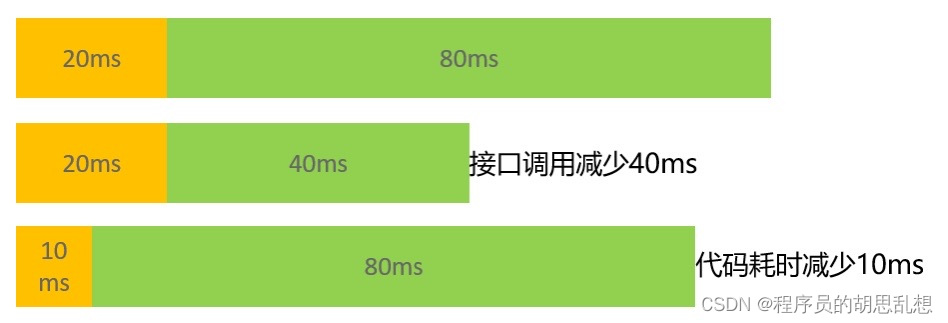
举个栗子,还是前面的100毫秒,假设有20毫秒用于cpu计算,80毫秒用于接口请求,那么无论优化程序算法,或着减少接口调用,都可以提升性能。
例如接口调用从80毫秒优化成40毫秒,明显延时就小了,TPS很容易就上去了。如果通过优化算法把CPU消耗从20毫秒变10毫秒, 看上去延时变化不大,但可以通过加大并发用户,也可以达到TPS增加的目的(可能瓶颈很快就到了接口调用那端)。
常见的资源类型
-
cpu
对CPU的查看,随着压测进展,一般有部分组件就会达到满负荷运行,吞吐量就上不去了,我们这种业务系统,通常就是把数据库打爆。如果有数据库耗时日志,就可以排查有没有高消耗SQL。如果除去外围接口,数据库发现消耗在代码上的时间比较多,就有可能是内部的代码效率问题, 分析方式主要以火焰图、打堆栈来分析,像arthars之类的工具也有一定办法。总体思路就是通过CPU采样的方式,看经常停留在哪些代码,这些通常就是问题。
-
内存
内存一般多多益善的。对于java应用来说,内存过大或者过小的影响主要体现在GC上,我们主要评估GC吞吐量和单次暂停时间, 评估工具可以用jstat,例如以10秒评估一次累计10次,看gc次数、总时间、最大暂停时间等。一般的问题在于,停顿时间过长会有毛刺现象, 吞吐量太低说明gc过于频繁。通常加大内存可以一定程度解决问题,但是还是要看看有没有大数据量的操作, 例如SQL返回大量数据,优化方式例如限制处理的数据量,对耗时对象进行池化的技术等等。真的出现OOM的话,可以用一些heapdump工具来分析。
-
网络
网络主要体现在延时上,延时一般和跨机房通讯距离有关,几毫秒到几十上百毫秒不等,如果延时过大或者远程调用次数过多,还是很影响体验的, 可以通过简单的ping,或者发起方和接收方的时间差来判断。但是网络延时主要影响响应时间, 但不代表非常影响压测吞吐量,网络带宽我们可以简单通过可以用一个收发一个大文件来评估。
-
磁盘
有时候磁盘I/O效率低也非常影响性能,特别是对数据库应用来说,可以通过iostat之类的工具来查看。对于普通的业务应用来说,主要就是日志的影响了,特别是大量的日志输出要注意采取Buffer方式。
总结
初稿躺在手机里边有段时间了,还是很粗糙,不过还是发出来把。
现代的软件系统越来越复杂,功能越来越多,性能也随越来越受到人们的关注。但是性能测试绝不只是Loadrunner或者JMeter之类的工具, 更需要理论结合实践,加深对系统的理解,让性能测试学习不停留在只是工具的学习。















 2596
2596











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









